Monday, 25 March 2019
Another Step to a Google-free Life

I watch a lot of YouTube videos. So much, that it starts to annoy me, how much of my free time I’m wasting by watching (admittedly very interesting) clips of a broad range of content creators.
Logging out of my Google account helped a little bit to keep my addiction at bay, as it appears to prevent the YouTube algorithm, which normally greets me with a broad set of perfectly selected videos from recognizing me. But then again I use Google to log in to one service or another, so it became annoying to log in and back out again all the time. At one point I decided to delete my YouTube history, which resulted in a very bad prediction of what videos I might like. This helped for a short amount of time, but the algorithm quickly returned to its merciless precision after a few days.
Today I decided, that its time to leave Google behind completely. My Google Mail account was used only for online shopping anyways, so I figured why not use a more privacy respecting service instead. Self-hosting was not an option for me, as I only have a residential IP address on my Raspberry Pi and also I heard that hosting a mail server is a huge pain.
A New Mail Account
So I created an account at the Berlin based service mailbox.org. They offer emails plus some cloud stuff like an office suite, storage etc., although I don’t think I’ll use any of the additional services (oh, they offer an XMPP account as well :P). The service is not free as in free beer as it costs 1â‚Ź per month, but that’s a fair price in my opinion. All in all it appears to be a good replacement for all the Google stuff.
As a next step, I went through the long list of all the websites and shops that I have accounts on, scouting for those services that are registered on my Google Mail address. All those mail settings had to be changed to the new account.
Mail Extensions
Bonus Tipp: Mailbox.org has support for so called Mail Extensions (or Plus Extensions, I’m not really sure how they are called). This means that you can create a folder in your inbox, lets say “fsfe”. Now you can change your mail address of your FSFE account to “username+fsfe@mailbox.org”. Mails from the FSFE will still go to your “username@mailbox.org” mail account, but they are automatically sorted into the fsfe inbox. This is useful not only to sort mails by sender, but also to find out, which of the many services you use messed up and leaked your mail address to those nasty spammers, so you can avoid that service in the future.
This trick also works for Google Mail by the way.
Deleting (most) the Google Services
The last step logically would be to finally delete my Google account. However, I’m not entirely sure if I really changed all the important services over to the new account, so I’ll keep it for a short period of time (a month or so) to see if any more important mails arrive.
However, I discovered that under the section “Delete Services or Account” you can see a list of all the services which are connected with your Google account. It is possible to partially delete those services, so I went ahead and deleted most of it, except Google Mail.
Additional Bonus Tipp: I use NewPipe on my phone, which is a free libre replacement for the YouTube app. It has a neat feature which lets you import your subscriptions from your YouTube account. That way I can still follow some of the creators, but in a more manual way (as I have to open the app on my phone, which I don’t often do). In my eyes, this is a good compromise 
I’m looking forward to go fully Google-free soon. I de-googled my phone ages ago, but for some reason I still held on to my Google account. This will be sorted out soon though!
De-Googling your Phone?
By the way, if you are looking to de-google your phone, Mike Kuketz has a great series of blog posts about that topic (in German though):
Happy Hacking!
Friday, 22 March 2019
How to create good SSH keys

A couple years back we wrote a guide on how to create good OpenPGP/GnuPG keys and now it is time to write a guide on SSH keys for much of the same reasons: SSH key algorithms have evolved in past years and the keys generated by the default OpenSSH settings a few years ago are no longer considered state-of-the-art. This guide is intended both for those completely new to SSH and to those who have already been using it for years and who want to make sure they are following the latest best practices.
Use OpenSSH 7 or later
Related to SSH keys there have been some relevant changes in versions 5.7, 6.5 and 7.0. Latest version is 7.9. You should be running at least 7.0. Current Debian stable (“Stretch”) shipped version 7.4 and for example Ubuntu 16.04 (“Xenial”) shipped 7.2, so nobody should be running on their laptop any later versions than these.
Generate Ed25519 keys
With a recent version of OpenSSH, simply run ssh-keygen -t ed25519. This will create a private and public key pair files at .ssh/id_ed25519 (and .pub) using the Ed25519 algorithm, which is considered state of the art. Elliptic curve algorithms in general are sleek and efficient and unlike the other well known elliptic curve algorithm ECDSA, this Ed25519 does not depend on any suspicious NIST defined constants. If you encounter a server that is very old and does not support Ed25519 keys, you might need to have a more traditinal RSA keypair. A strong 4k RSA key pair can be generated with ssh-keygen -b 4096. Hopefully you won’t need to ever do that.
Running ssh-keygen will prompt for a password. If your laptop is encrypted and well protected you can omit the password and gain some speed and convenience in your SSH commands.
Store the private key securely
Hopefully your laptop is well protected with full disk encryption etc and you can trust that nobody else than yourself has access to your /home/<username>/.ssh directory. Hopefully you also have securely stored encrypted backups of your laptop so that you can recover the .ssh directory if your laptop for any reason is lost or broken.
The SSH keyfiles are stored as armored ASCII, which means that you could even print them on paper and store the printed key in a real vault just to be extra sure you never loose your private key (.ssh/id_ed25519).
The public key is indeed designed to be public
The public key .ssh/id_ed25519.pubon the other hand is meant to be public. Here is mine for example:
~/.ssh$ cat id_ed25519.pub
ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAIMdBlrVoDupARk3pd1Q9sDImaGCxEalcFt7QTqBa36kH otto@XPS-13-9370You can find a lot of public SSH keys for example on Github using the URL https://github.com/<username>.keys. You may also want to check out the excellent Github SSH usage docs.
This public key is the one you will distribute to remote servers. Place them on the remote server in the .ssh/authorized_keys file. The servers you try to access will use the public key to create a challenge, and only your laptop that has the private key pair can solve that challenge, and thus authenticate that your connection to the server is authorized.
On Linux machines a shorthand to copy your SSH key to a remote server is to run ssh-copy-id remote.example.com. This will ask for a password on the first time, but once the key is in place, a SSH keys will be used instead and no password is asked anymore.
Best practices
Once you are familiar with SSH key usage basics, please adopt these policies:
- Disable password authentication on the SSH servers you control altogether. The less there are passwords, the less there as ones that can leak or be forgotten etc. For passwords less is indeed more. Only use keys for authentication on SSH connections.
- Use a separate key per client you SSH from. So don’t copy the private key from your laptop to another laptop for use in parallel. Each client system should have only one key, so in case a key leaks, you know which client system was compromised. If you stop using your old laptop and start using a new one it is naturally another case and then you can copy the key.
- Avoid chaining SSH connections. Any system that is used for chaining SSH connections incurs a potential man-in-the-middle situation.
- For the same reasons try to avoid X11 forwarding and agent forwarding. Consider putting these in your
.ssh/config:
Host *
ForwardX11 no
ForwardAgent noUsing ProxyCommand
You shouldn’t forward SSH agent (ssh -A), but it’s ok to use ProxyCommand or ProxyJump. You can permanently configure it in your .ssh/config like this:
Host backend.example.com
Hostname 1.2.3.4.
Port 23
ProxyCommand ssh bastion.example.com -W %h:%pStay vigilant
If running ssh remote.example.comyields some error messages, don’t ignore them! SSH has an opportunistic key model, which is convenient, but it also means that if you are confronted with warnings that the connection might be eavesdropped you should really take note and not proceed.
Monday, 18 March 2019
Dataspaces and Paging in L4Re
The experiments covered by my recent articles about filesystems and L4Re managed to lead me along another path in the past few weeks. I had defined a mechanism for providing access to files in a filesystem via a programming interface employing interprocess communication within the L4Re system. In doing so, I had defined calls or operations that would read from and write to a file, observing that some kind of “memory-mapped” file support might also be possible. At the time, I had no clear idea of how this would actually be made to work, however.
As can often be the case, once some kind of intellectual challenge emerges, it can become almost impossible to resist the urge to consider it and to formulate some kind of solution. Consequently, I started digging deeper into a number of things: dataspaces, pagers, page faults, and the communication that happens within L4Re via the kernel to support all of these things.
Dataspaces and Memory
Because the L4Re developers have put a lot of effort into making a system where one can compile a fairly portable program and probably expect it to work, matters like the allocation of memory within programs, the use of functions like malloc, and other things we take for granted need no special consideration in the context of describing general development for an L4Re-based system. In principle, if our program wants more memory for its own use, then the use of things like malloc will probably suffice. It is where we have other requirements that some of the L4Re abstractions become interesting.
In my previous efforts to support MIPS-based systems, these other requirements have included the need to access memory with a fixed and known location so that the hardware can be told about it, thus supporting things like framebuffers that retain stored data for presentation on a display device. But perhaps most commonly in a system like L4Re, it is the need to share memory between processes or tasks that causes us to look beyond traditional memory allocation techniques at what L4Re has to offer.
Indeed, the filesystem work so far employs what are known as dataspaces to allow filesystem servers and client applications to exchange larger quantities of information conveniently via shared buffers. First, the client requests a dataspace representing a region of memory. It then associates it with an address so that it may access the memory. Then, the client shares this with the server by sending it a reference to the dataspace (known as a capability) in a message.

Opening a file using shared memory containing file information
The kernel, in propagating the message and the capability, makes the dataspace available to the server so that both the client and the server may access the memory associated with the dataspace and that these accesses will just work without any further effort. At this level of sophistication we can get away with thinking of dataspaces as being blocks of memory that can be plugged into tasks. Upon obtaining access to such a block, reads and writes (or loads and stores) to addresses in the block will ultimately touch real memory locations.
Even in this simple scheme, there will be some address translation going on because each task has its own way of arranging its view of memory: its virtual address space. The virtual memory addresses used by a task may very well be different from the physical memory addresses indicating the actual memory locations involved in accesses.

An illustration of virtual memory corresponding to physical memory
Such address translation is at the heart of operating systems like those supported by the L4 family of microkernels. But the system will make sure that when a task tries to access a virtual address available to it, the access will be translated to a physical address and supported by some memory location.
Mapping and Paging
With some knowledge of the underlying hardware architecture, we can say that each task will need support from the kernel and the hardware to be able to treat its virtual address space as a way of accessing real memory locations. In my experiments with simple payloads to run on MIPS-based hardware, it was sufficient to define very simple tables that recorded correspondences between virtual and physical addresses. Processes or tasks would access memory addresses, and where the need arose to look up such a virtual address, the table would be consulted and the hardware configured to map the virtual address to a physical address.
Naturally, proper operating systems go much further than this, and systems built on L4 technologies go as far as to expose the mechanisms for normal programs to interact with. Instead of all decisions about how memory is mapped for each task being taken in the kernel, with the kernel being equipped with all the necessary policy and information, such decisions are delegated to entities known as pagers.
When a task needs an address translated, the kernel pushes the translation activity over to the designated pager for a decision to be made. And the event that demands an address translation is known as a page fault since it occurs when a task accesses a memory page that is not yet supported by a mapping to physical memory. Pagers are therefore present to receive page fault notifications and to respond in a way that causes the kernel to perform the necessary privileged actions to configure the hardware, this being one of the few responsibilities of the kernel.

The role of a pager in managing access to the contents of a dataspace
Treating a dataspace as an abstraction for memory accessed by a task or application, the designated pager for the dataspace acts as a dataspace manager, ensuring that memory accesses within the dataspace can be satisfied. If an access causes a page fault, the pager must act to provide a mapping for the accessed page, leaving the application mostly oblivious to the work going on to present the dataspace and its memory as a continuously present resource.
An Aside
It is rather interesting to consider the act of delegation in the context of processor architecture. It would seem to be fairly common that the memory management units provided by various architectures feature built-in support for consulting various forms of data structures describing the virtual memory layout of a process or task. So, when a memory access fails, the information about the actual memory address involved can be retrieved from such a predefined structure.
However, the MIPS architecture largely delegates such matters to software: a processor exception is raised when a “bad” virtual address is used, and the job of doing something about it falls immediately to a software routine. So, there seems to be some kind of parallel between processor architecture and operating system architecture, L4 taking a MIPS-like approach of eager delegation to a software component for increased flexibility and functionality.
Messages and Flexpages
So, the high-level view so far is as follows:
- Dataspaces represent regions of virtual memory
- Virtual memory is mapped to physical memory where the data actually resides
- When a virtual memory access cannot be satisfied, a page fault occurs
- Page faults are delivered to pagers (acting as dataspace managers) for resolution
- Pagers make data available and indicate the necessary mapping to satisfy the failing access
To get to the level of actual implementation, some familiarisation with other concepts is needed. Previously, my efforts have exposed me to the interprocess communications (IPC) central in L4Re as a microkernel-based system. I had even managed to gain some level of understanding around sending references or capabilities between processes or tasks. And it was apparent that this mechanism would be used to support paging.
Unfortunately, the main L4Re documentation does not seem to emphasise the actual message details or protocols involved in these fundamental activities. Instead, the library code is described in reference documentation with some additional explanation. However, some investigation of the code yielded some insights as to the kind of interfaces the existing dataspace implementations must support, and I also tracked down some message sending activities in various components.
When a page fault occurs, the first thing to know about it is the kernel because the fault occurs at the fundamental level of instruction execution, and it is the kernel’s job to deal with such low-level events in the first instance. Notification of the fault is then sent out of the kernel to the page fault handler for the affected task. The page fault handler then contacts the task’s pager to request a resolution to the problem.

Page fault handling in detail
In L4Re, this page fault handler is likely to be something called a region mapper (or perhaps a region manager), and so it is not completely surprising that the details of invoking the pager was located in some region mapper code. Putting together both halves of the interaction yielded the following details of the message:
- map: offset, hot spot, flags → flexpage
Here, the offset is the position of the failing memory access relative to the start of the dataspace; the flags describe the nature of the memory to be accessed. The “hot spot” and “flexpage” need slightly more explanation, the latter being an established term in L4 circles, the former being almost arbitrarily chosen and not particularly descriptive.
The term “flexpage” may have its public origins in the “Flexible-Sized Page-Objects” paper whose title describes the term. For our purposes, the significance of the term is that it allows for the consideration of memory pages in a range of sizes instead of merely considering a single system-wide page size. These sizes start at the smallest page size supported by the system (but not necessarily the absolute smallest supported by the hardware, but anyway…) and each successively larger size is double the size preceding it. For example:
- 4096 (212) bytes
- 8192 (213) bytes
- 16384 (214) bytes
- 32768 (215) bytes
- 65536 (216) bytes
- …
When a page fault occurs, the handler identifies a region of memory where the failing access is occurring. Although it could merely request that memory be made available for a single page (of the smallest size) in which the access is situated, there is the possibility that a larger amount of memory be made available that encompasses this access page. The flexpage involved in a map request represents such a region of memory, having a size not necessarily decided in advance, being made available to the affected task.
This brings us to the significance of the “hot spot” and some investigation into how the page fault handler and pager interact. I must admit that I find various educational materials to be a bit vague on this matter, at least with regard to explicitly describing the appropriate behaviour. Here, the flexpage paper was helpful in providing slightly different explanations, albeit employing the term “fraction” instead of “hot spot”.
Since the map request needs to indicate the constraints applying to the region in which the failing access occurs, without demanding a particular size of region and yet still providing enough useful information to the pager for the resulting flexpage to be useful, an efficient way is needed of describing the memory landscape in the affected task. This is apparently where the “hot spot” comes in. Consider a failing access in page #3 of a memory region in a task, with the memory available in the pager to satisfy the request being limited to two pages:

Mapping available memory to pages in a task experiencing a page fault
Here, the “hot spot” would reference page #3, and this information would be received by the pager. The significance of the “hot spot” appears to be the location of the failing access within a flexpage, and if the pager could provide it then a flexpage of four system pages would map precisely to the largest flexpage expected by the handler for the task.
However, with only two system pages to spare, the pager can only send a flexpage consisting of those two pages, the “hot spot” being localised in page #1 of the flexpage to be sent, and the base of this flexpage being the base of page #0. Fortunately, the handler is smart enough to fit this smaller flexpage onto the “receive window” by using the original “hot spot” information, mapping page #2Â in the receive window to page #0 of the received flexpage and thus mapping the access page #3 to page #1 of that flexpage.
So, the following seems to be considered and thus defined by the page fault handler:
- The largest flexpage that could be used to satisfy the failing access.
- The base of this flexpage.
- The page within this flexpage where the access occurs: the “hot spot”.
- The offset within the broader dataspace of the failing access, it indicating the data that would be expected in this page.
(Given this phrasing of the criteria, it becomes apparent that “flexpage offset” might be a better term than “hot spot”.)
With these things transferred to the pager using a map request, the pager’s considerations are as follows:
- How flexpages of different sizes may fit within the memory available to satisfy the request.
- The base of the most appropriate flexpage, where this might be the largest that fits within the available memory.
- The population of the available memory with data from the dataspace.
To respond to the request, the pager sends a special flexpage item in its response message. Consequently, this flexpage is mapped into the task’s address space, and the execution of the task may resume with the missing data now available.
Practicalities and Pitfalls
If the dataspace being provided by a pager were merely a contiguous region of memory containing the data, there would probably be little else to say on the matter, but in the above I hint at some other applications. In my example, the pager only uses a certain amount of memory with which it responds to map requests. Evidently, in providing a dataspace representing a larger region, the data would have to be brought in from elsewhere, which raises some other issues.
Firstly, if data is to be copied into the limited region of memory available for satisfying map requests, then the appropriate portion of the data needs to be selected. This is mostly a matter of identifying how the available memory pages correspond to the data, then copying the data into the pages so that the accessed location ultimately provides the expected data. It may also be the case that the amount of data available does not fill the available memory pages; this should cause the rest of those pages to be filled with zeros so that data cannot leak between map requests.
Secondly, if the available memory pages are to be used to satisfy the current map request, then what happens when we re-use them in each new map request? It turns out that the mappings made for previous requests remain active! So if a task traverses a sequence of pages, and if each successive page encountered in that traversal causes a page fault, then it will seem that new data is being made available in each of those pages. But if that task inspects the earlier pages, it will find that the newest data is exposed through those pages, too, banishing the data that we might have expected.
Of course, what is happening is that all of the mapped pages in the task’s dataspace now refer to the same collection of pages in the pager, these being dedicated to satisfying the latest map request. And so, they will all reflect the contents of those available memory pages as they currently are after this latest map request.

The effect of mapping the same page repeatedly
One solution to this problem is to try and make the task forget the mappings for pages it has visited previously. I wondered if this could be done automatically, by sending a flexpage from the pager with a flag set to tell the kernel to invalidate prior mappings to the pager’s memory. After a time looking at the code, I ended up asking on the l4-hackers mailing list and getting a very helpful response that was exactly what I had been looking for!
There is, in fact, a special way of telling the kernel to “unmap” memory used by other tasks (l4_task_unmap), and it is this operation that I ended up using to invalidate the mappings previously sent to the task. Thus the task, upon backtracking to earlier pages, finds that the mappings from virtual addresses to the physical memory holding the latest data are absent once again, and page faults are needed to restore the data in those pages. The result is a form of multiplexing access to a resource via a limited region of memory.
Applications of Flexible Paging
Given the context of my investigations, it goes almost without saying that the origin of data in such a dataspace could be a file in a filesystem, but it could equally be anything that exposes data in some kind of backing store. And with this backing store not necessarily being an area of random access memory (RAM), we enter the realm of a more restrictive definition of paging where processes running in a system can themselves be partially resident in RAM and partially resident in some other kind of storage, with the latter portions being converted to the former by being fetched from wherever they reside, depending on the demands made on the system at any given point in time.
One observation worth making is that a dataspace does not need to be a dedicated component in the system in that it is not a separate and special kind of entity. Anything that is able to respond to the messages understood by dataspaces – the paging “protocol” – can provide dataspaces. A filesystem object can therefore act as a dataspace, exposing itself in a region of memory and responding to map requests that involve populating that region from the filesystem storage.
It is also worth mentioning that dataspaces and flexpages exist at different levels of abstraction. Dataspaces can be considered as control mechanisms for accessing regions of virtual memory, and the Fiasco.OC kernel does not appear to employ the term at all. Meanwhile, flexpages are abstractions for memory pages existing within or even independently of dataspaces. (If you wish, think of the frame of Banksy’s work “Love is in the Bin” as a dataspace, with the shredded pieces being flexpages that are mapped in and out.)
One can envisage more exotic forms of dataspace. Consider an image whose pixels need to be computed, like a ray-traced image, for instance. If it exposed those pixels as a dataspace, then a task reading from pages associated with that dataspace might cause computations to be initiated for an area of the image, with the task being suspended until those computations are performed and then being resumed with the pixel data ready to read, with all of this happening largely transparently.
I started this exercise out of somewhat idle curiosity, but it now makes me wonder whether I might introduce memory-mapped access to filesystem objects and then re-implement operations like reading and writing using this particular mechanism. Not being familiar with how systems like GNU/Linux provide these operations, I can only speculate as to whether similar decisions have been taken elsewhere.
But certainly, this exercise has been informative, even if certain aspects of it were frustrating. I hope that this account of my investigations proves useful to anyone else wondering about microkernel-based systems and L4Re in particular, especially if they too wish there were more discussion, reflection and collaboration on the design and implementation of software for these kinds of systems.
Sunday, 10 March 2019
Generate a random root password aka Ansible Password Plugin
I was suspicious with a cron entry on a new ubuntu server cloud vm, so I ended up to be looking on the logs.
Authentication token is no longer valid; new one required
After a quick internet search,
# chage -l root
Last password change : password must be changed
Password expires : password must be changed
Password inactive : password must be changed
Account expires : never
Minimum number of days between password change : 0
Maximum number of days between password change : 99999
Number of days of warning before password expires : 7due to the password must be changed on the root account, the cron entry does not run as it should.
This ephemeral image does not need to have a persistent known password, as the notes suggest, and it doesn’t! Even so, we should change to root password when creating the VM.
Ansible
Ansible have a password plugin that we can use with lookup.
TLDR; here is the task:
- name: Generate Random Password
user:
name: root
password: "{{ lookup('password','/dev/null encrypt=sha256_crypt length=32') }}"after ansible-playbook runs
# chage -l root
Last password change : Mar 10, 2019
Password expires : never
Password inactive : never
Account expires : never
Minimum number of days between password change : 0
Maximum number of days between password change : 99999
Number of days of warning before password expires : 7and cron entry now runs as it should.
Password Plugin
Let explain how password plugin works.
Lookup needs at-least two (2) variables, the plugin name and a file to store the output. Instead, we will use /dev/null not to persist the password to a file.
To begin with it, a test ansible playbook:
- hosts: localhost
gather_facts: False
connection: local
tasks:
- debug:
msg: "{{ lookup('password', '/dev/null') }}"
with_sequence: count=5Output:
ok: [localhost] => (item=1) => {
"msg": "dQaVE0XwWti,7HMUgq::"
}
ok: [localhost] => (item=2) => {
"msg": "aT3zqg.KjLwW89MrAApx"
}
ok: [localhost] => (item=3) => {
"msg": "4LBNn:fVw5GhXDWh6TnJ"
}
ok: [localhost] => (item=4) => {
"msg": "v273Hbox1rkQ3gx3Xi2G"
}
ok: [localhost] => (item=5) => {
"msg": "NlwzHoLj8S.Y8oUhcMv,"
}Length
In password plugin we can also use length variable:
msg: "{{ lookup('password', '/dev/null length=32') }}"
output:
ok: [localhost] => (item=1) => {
"msg": "4.PEb6ycosnyL.SN7jinPM:AC9w2iN_q"
}
ok: [localhost] => (item=2) => {
"msg": "s8L6ZU_Yzuu5yOk,ISM28npot4.KwQrE"
}
ok: [localhost] => (item=3) => {
"msg": "L9QvLyNTvpB6oQmcF8WVFy.7jE4Q1K-W"
}
ok: [localhost] => (item=4) => {
"msg": "6DMH8KqIL:kx0ngFe8:ri0lTK4hf,SWS"
}
ok: [localhost] => (item=5) => {
"msg": "ByW11i_66K_0mFJVB37Mq2,.fBflepP9"
}Characters
We can define a specific type of python string constants
- ascii_letters (ascii_lowercase and ascii_uppercase
- ascii_lowercase
- ascii_uppercase
- digits
- hexdigits
- letters (lowercase and uppercase)
- lowercase
- octdigits
- punctuation
- printable (digits, letters, punctuation and whitespace
- uppercase
- whitespace
eg.
msg: "{{ lookup('password', '/dev/null length=32 chars=ascii_lowercase') }}"
ok: [localhost] => (item=1) => {
"msg": "vwogvnpemtdobjetgbintcizjjgdyinm"
}
ok: [localhost] => (item=2) => {
"msg": "pjniysksnqlriqekqbstjihzgetyshmp"
}
ok: [localhost] => (item=3) => {
"msg": "gmeoeqncdhllsguorownqbynbvdusvtw"
}
ok: [localhost] => (item=4) => {
"msg": "xjluqbewjempjykoswypqlnvtywckrfx"
}
ok: [localhost] => (item=5) => {
"msg": "pijnjfcpjoldfuxhmyopbmgdmgdulkai"
}Encrypt
We can also define the encryption hash. Ansible uses passlib so the unix active encrypt hash algorithms are:
- passlib.hash.bcrypt - BCrypt
- passlib.hash.sha256_crypt - SHA-256 Crypt
- passlib.hash.sha512_crypt - SHA-512 Crypt
eg.
msg: "{{ lookup('password', '/dev/null length=32 chars=ascii_lowercase encrypt=sha512_crypt') }}"
ok: [localhost] => (item=1) => {
"msg": "$6$BR96lZqN$jy.CRVTJaubOo6QISUJ9tQdYa6P6tdmgRi1/NQKPxwX9/Plp.7qETuHEhIBTZDTxuFqcNfZKtotW5q4H0BPeN."
}
ok: [localhost] => (item=2) => {
"msg": "$6$ESf5xnWJ$cRyOuenCDovIp02W0eaBmmFpqLGGfz/K2jd1FOSVkY.Lsuo8Gz8oVGcEcDlUGWm5W/CIKzhS43xdm5pfWyCA4."
}
ok: [localhost] => (item=3) => {
"msg": "$6$pS08v7j3$M4mMPkTjSwElhpY1bkVL727BuMdhyl4IdkGM7Mq10jRxtCSrNlT4cAU3wHRVxmS7ZwZI14UwhEB6LzfOL6pM4/"
}
ok: [localhost] => (item=4) => {
"msg": "$6$m17q/zmR$JdogpVxY6MEV7nMKRot069YyYZN6g8GLqIbAE1cRLLkdDT3Qf.PImkgaZXDqm.2odmLN8R2ZMYEf0vzgt9PMP1"
}
ok: [localhost] => (item=5) => {
"msg": "$6$tafW6KuH$XOBJ6b8ORGRmRXHB.pfMkue56S/9NWvrY26s..fTaMzcxTbR6uQW1yuv2Uy1DhlOzrEyfFwvCQEhaK6MrFFye."
}
A look at Matrix.org’s OLM | MEGOLM encryption protocol
Everyone who knows and uses XMPP is probably aware of a new player in the game. Matrix.org is often recommended as a young, arising alternative to the aging protocol behind the Jabber ecosystem. However the founders do not see their product as a direct competitor to XMPP as their approach to the problem of message exchanging is quite different.
An open network for secure, decentralized communication.
matrix.org
During his talk at the FOSDEM in Brussels, matrix.org founder Matthew Hodgson roughly compared the concept of matrix to how git works. Instead of passing single messages between devices and servers, matrix is all about synchronization of a shared state. A chat room can be seen as a repository, which is shared between all servers of the participants. As a consequence communication in a chat room can go on, even when the server on which the room was created goes down, as the room simultaneously exists on all the other servers. Once the failed server comes back online, it synchronizes its state with the others and retrieves missed messages.
Olm, Megolm – What’s the deal?
Matrix introduced two different crypto protocols for end-to-end encryption. One is named Olm, which is used in one-to-one chats between two chat partners (this is not quite correct, see Updates for clarifying remarks). It can very well be compared to OMEMO, as it too is an adoption of the Signal Protocol by OpenWhisperSystems. However, due to some differences in the implementation Olm is not compatible with OMEMO although it shares the same cryptographic properties.
The other protocol goes by the name of Megolm and is used in group chats. Conceptually it deviates quite a bit from Olm and OMEMO, as it contains some modifications that make it more suitable for the multi-device use-case. However, those modifications alter its cryptographic properties.
Comparing Cryptographic Building Blocks
| Protocol | Olm | OMEMO (Signal) |
| IdentityKey | Curve25519 | X25519 |
| FingerprintKeyâ˝Âšâž | Ed25519 | none |
| PreKeys | Curve25519 | X25519 |
| SignedPreKeysâ˝Â˛âž | none | X25519 |
| Key Exchange Algorithmâ˝Âłâž | Triple Diffie-Hellman (3DH) | Extended Triple Diffie-Hellman (X3DH) |
| Ratcheting Algoritm | Double Ratchet | Double Ratchet |
- Signal uses a Curve X25519 IdentityKey, which is capable of both encrypting, as well as creating signatures using the XEdDSA signature scheme. Therefore no separate FingerprintKey is needed. Instead the fingerprint is derived from the IdentityKey. This is mostly a cosmetic difference, as one less key pair is required.
- Olm does not distinguish between the concepts of signed and unsigned PreKeys like the Signal protocol does. Instead it only uses one type of PreKey. However, those may be signed with the FingerprintKey upon upload to the server.
- OMEMO includes the SignedPreKey, as well as an unsigned PreKey in the handshake, while Olm only uses one PreKey. As a consequence, if the senders Olm IdentityKey gets compromised at some point, the very first few messages that are sent could possibly be decrypted.
In the end Olm and OMEMO are pretty comparable, apart from some simplifications made in the Olm protocol. Those do only marginally affect its security though (as far as I can tell as a layman).
Megolm
The similarities between OMEMO and Matrix’ encryption solution end when it comes to group chat encryption.
OMEMO does not treat chats with more than two parties any other than one-to-one chats. The sender simply has to manage a lot more keys and the amount of required trust decisions grows by a factor roughly equal to the number of chat participants.
Yep, this is a mess but luckily XMPP isn’t a very popular chat protocol so there are no large encrypted group chats ;P
So how does Matrix solve the issue?
When a user joins a group chat, they generate a session for that chat. This session consists of an Ed25519 SigningKey and a single ratchet which gets initialized randomly.
The public part of the signing key and the state of the ratchet are then shared with each participant of the group chat. This is done via an encrypted channel (using Olm encryption). Note, that this session is also shared between the devices of the user. Contrary to Olm, where every device has its own Olm session, there is only one Megolm session per user per group chat.
Whenever the user sends a message, the encryption key is generated by forwarding the ratchet and deriving a symmetric encryption key for the message from the ratchets output. Signing is done using the SigningKey.
Recipients of the message can decrypt it by forwarding their copy of the senders ratchet the same way the sender did, in order to retrieve the same encryption key. The signature is verified using the public SigningKey of the sender.
There are some pros and cons to this approach, which I briefly want to address.
First of all, you may find that this protocol is way less elegant compared to Olm/Omemo/Signal. It poses some obvious limitations and security issues. Most importantly, if an attacker gets access to the ratchet state of a user, they could decrypt any message that is sent from that point in time on. As there is no new randomness introduced, as is the case in the other protocols, the attacker can gain access by simply forwarding the ratchet thereby generating any decryption keys they need. The protocol defends against this by requiring the user to generate a new random session whenever a new user joins/leaves the room and/or a certain number of messages has been sent, whereby the window of possibly compromised messages gets limited to a smaller number. Still, this is equivalent to having a single key that decrypts multiple messages at once.
The Megolm specification lists a number of other caveats.
On the pro side of things, trust management has been simplified as the user basically just has to decide whether or not to trust each group member instead of each participating device – reducing the complexity from a multiple of n down to just n. Also, since there is no new randomness being introduced during ratchet forwarding, messages can be decrypted multiple times. As an effect devices do not need to store the decrypted messages. Knowledge of the session state(s) is sufficient to retrieve the message contents over and over again.
By sharing older session states with own devices it is also possible to read older messages on new devices. This is a feature that many users are missing badly from OMEMO.
On the other hand, if you really need true future secrecy on a message-by-message base and you cannot risk that an attacker may get access to more than one message at a time, you are probably better off taking the bitter pill going through the fingerprint mess and stick to normal Olm/OMEMO (see Updates for remarks on this statement).
Note: End-to-end encryption does not really make sense in big, especially public chat rooms, since an attacker could just simply join the room in order to get access to ongoing communication. Thanks to Florian Schmaus for pointing that out.
I hope I could give a good overview of the different encryption mechanisms in XMPP and Matrix. Hopefully I did not make any errors, but if you find mistakes, please let me know, so I can correct them asap
Happy Hacking!
Sources
- Olm – A Cryptographic Ratchet
- Megolm Group Ratchet
- Implementing End-to-End Encryption in Matrix clients
- OMEMO Encryption
- The Double Ratchet Algorithm
- Extended Triple Diffie-Hellman Key Exchange
Updates:
Thanks for Matthew Hodgson for pointing out, that Olm/OMEMO is also effectively using a symmetric ratchet when multiple consecutive messages are sent without the receiving device sending an answer. This can lead to loss of future secrecy as discussed in the OMEMO protocol audit.
Also thanks to Hubert Chathi for noting, that Megolm is also used in one-to-one chats, as matrix doesn’t have the same distinction between group and single chats. He also pointed out, that the security level of Megolm (the criteria for regenerating the session) can be configured on a per-chat basis.
Tuesday, 05 March 2019
Copyright Reform


Το Ευρωπαικό Κοινοβούλιο ετοιμάζει να ψηφίσει το τελικό κείμενο για την οδηγία "Πνευματικής Ιδιοκτησίας". Μέσα σε αυτή την οδηγία υπάρχουν δύο άρθρα που αν εγκριθούν θα αλλάξουν δραματικά τον χαρακτήρα του Internet. Προς το χειρότερο. Θα αλλάξει όχι μόνο ο τρόπος με το οποίο οι άνθρωποι το χρησιμοποιούν ως πλατφόρμα έκφρασης λόγου, αλλά θα επηρεάσεις αρνητικά ακόμα και τους ίδιους τους δημιουργούς, που υποτίθεται προσπαθεί να προστατέψει.
Παρακάτω είναι μια συνοπτική περίληψη των καταστροφικών συνεπειών, που θα γίνουν πραγματικότητα αν το Ευρωπαικό Κοινοβούλιο υπερψηφίσει την οδηγία.
Άρθρο 13: Φίλτρα περιεχομένου (Upload filters)
- Τα εμπορικά sites και εφαρμογές, όπου χρήστες αναρτούν περιεχόμενο, πρέπει να καταβάλουν κάθε προσπάθεια ώστε να έχουν αγοράσει εκ των προτέρων τις απαραίτητες άδειες για οτιδήποτε μπορεί να αναρτήσουν οι χρήστες τους. Αυτό πρακτικά σημαίνει το σύνολο της ανθρώπινης δημιουργίας που διέπεται από περιορισμούς πνευματικής ιδιοκτησίας. Είναι προφανές πως κάτι τέτοιο είναι αδύνατο να εφαρμοστεί τόσο τεχνικά, όσο και οικονομικά. Ειδικά για μικρές πλατφόρμες και υπηρεσίες.
- Επιπρόσθετα, τα περισσότερα sites θα πρέπει να κάνουν ό,τι είναι δυνατόν ώστε να αποτρέψουν την ανάρτηση περιεχομένου απ' τους χρήστες τους, για το οποίο δεν έχουν την άδεια του δημιουργού. Δεν θα έχουν άλλη επιλογή απ' το να εφαρμόσουν φίλτρα περιεχομένου, τα οποία είναι ακριβά και αναποτελεσματικά.
- Σε περίπτωση που ένα δικαστήριο κρίνει πως τα φίλτρα δεν είναι επαρκώς αυστηρά, τα sites θα είναι νομικά υπόλογα για τις παραβάσεις, σαν να τις έχουν διαπράξει τα ίδια. Αυτή η νομική απειλή θα οδηγήσει αρκετές υπηρεσίες να υπερβάλουν στην εφαρμογή των φίλτρων ώστε να παραμείνουν ασφαλή από διώξεις. Γεγονός που απειλεί την ελευθερία του λόγου στο διαδίκτυο.
- Το περιεχόμενο που θα αναρτούμε online δεν είναι πλέον άμεσα διαθέσιμο, σε πολλές περιπτώσεις, καθώς θα πρέπει πρώτα να εγκριθεί απ' τα παραπάνω φίλτρα.
- Αρκετές απ' τις υπηρεσίες που χρησιμοποιούμε σήμερα θα σταματήσουν να λειτουργούν εντός της ΕΕ, υπό το φόβο διώξεων για παράβαση της οδηγίας ή για τη μη-αυστηρή εφαρμογή της.
- Τα φίλτρα περιεχομένου θα βλάψουν και τους δημιουργούς. Διασκευές, reviews, memes και άλλες κατηγορίες περιεχομένου που βασίζονται σε copoyrighted υλικό θα μπλοκάρεται απ' τα φίλτρα.
- Θα είσαι ένοχος μέχρι να αποδείξεις το αντίθετο. Ακόμα κι αν το περιεχόμενό σου ανήκει, θα φέρεις το βάρος της απόδειξης όταν τα φίλτρα θα το μαρκάρουν λανθασμένα ως παράβαση πνευματικής ιδιοκτησίας.
- Θα επωφεληθούν οι μεγάλοι παίχτες της αγοράς, καθώς είναι οι μόνοι που μπορούν να αντέξουν οικονομικά την εφαρμογή της οδηγίας.
- Τελικώς λιγότερες νέες και καινοτόμες υπηρεσίες θα ξεκινούν εντός της ΕΕ, γιατί το κόστος εκκίνησης θα είναι δυσβάσταχτο.
Άρθρο 11: Φόρος συνδέσμων (Link tax)
- Η αναπαραγωγή ειδήσεων με παραπάνω από μία λέξη ή περισσότερο από μια πολύ σύντομη περιγραφή, θα απαιτεί σχετική άδεια. Αυτό πιθανότατα θα καλύψει και τις περιλήψεις (snippets) ειδήσεων που χρησιμοποιούνται κατά κόρον. Υπάρχει αρκετή ασάφεια ως προς το τι σημαίνει το "σύντομη περιγραφή", αλλά υπάρχει ο κίνδυνος να καταστεί νομικά επικίνδυνη η χρήση περιλήψεων με συνδέσμους.
- Δεν υπάρχουν εξαιρέσεις. Η οδηγία περιλαμβάνει ακόμα και ατομικές υπηρεσίες, μικρές ή μη-κερδοσκοπικές εταιρείες, blogs.
- Πολλοί θεωρούν πως η οδηγία θα δημιουργήσει έσοδα για τους ειδησεογραφικούς οργανισμούς από μεγάλες υπηρεσίες (πχ. Google News), που χρησιμοποιούν περιλήψεις άρθρων. Στην πράξη όμως, θα πλήξει τους μικρούς παίχτες (πχ. blogs) και οι μεγάλες υπηρεσίες πιθανότατα θα αναστείλουν τη λειτουργία τους στην ΕΕ αφαιρώντας απ' τα ειδησιογραφικά sites ακόμα και αυτή την κίνηση απ' τους συνδέσμους προς τα άρθρα τους.
- Τελικώς η εφαρμογή της οδηγίας θα περιορίσει τη ροή της πληροφορίας και της ενημέρωσης.
Τι μπορείς να κάνεις
Ενημέρωσε τους ευρωβουλευτές. Πολλοί εξ αυτών θα υπερψηφίσουν είτε από άγνοια είτε από κακή πληροφόρηση. Επισκέψου το saveyourinternet, όπου υπάρχουν σχετικά στοιχεία επικοινωνίας. Με κόκκινο χρώμα είναι οι ευρωβουλευτές που έχουν ταχθεί υπέρ της οδηγίας στο παρελθόν.
Βοήθησε να ενημερωθούν καλύτερα για τους κινδύνους της οδηγίας. Αν σε βοηθάει στην επικοινωνία, μπορείς να χρησιμοποιήσεις όσα αποσπάσματα επιθυμείς απ' το παρόν κείμενο είτε ακόμα και ολόκληρο το κείμενο.
Sunday, 03 March 2019
Scaling automation with ansible-pull
Ansible is a wonderful software to automatically configure your systems. The default mode of using ansible is Push Model.

That means from your box, and only using ssh + python, you can configure your flee of machines.
Ansible is imperative. You define tasks in your playbooks, roles and they will run in a serial manner on the remote machines. The task will first check if needs to run and otherwise it will skip the action. And although we can use conditional to skip actions, tasks will perform all checks. For that reason ansible seems slow instead of other configuration tools. Ansible runs in serial mode the tasks but in psedo-parallel mode against the remote servers, to increase the speed. But sometimes you need to gather_facts and that would cost in execution time. There are solutions to cache the ansible facts in a redis (in memory key:value db) but even then, you need to find a work-around to speed your deployments.
But there is an another way, the Pull Mode!
Useful Reading Materials
to learn more on the subject, you can start reading these two articles on ansible-pull.
Pull Mode
So here how it looks:
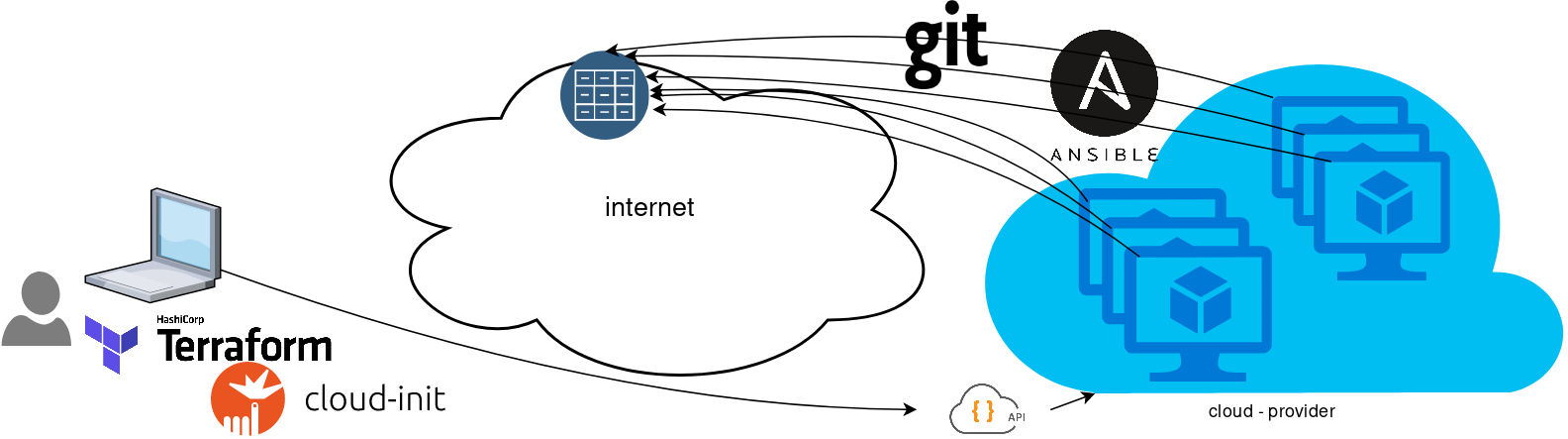
You will first notice, that your ansible repository is moved from you local machine to an online git repository. For me, this is GitLab. As my git repo is private, I have created a Read-Only, time-limit, Deploy Token.
With that scenario, our (ephemeral - or not) VMs will pull their ansible configuration from the git repo and run the tasks locally. I usually build my infrastructure with Terraform by HashiCorp and make advance of cloud-init to initiate their initial configuration.
Cloud-init
The tail of my user-data.yml looks pretty much like this:
...
# Install packages
packages:
- ansible
# Run ansible-pull
runcmd:
- ansible-pull -U https://gitlab+deploy-token-XXXXX:YYYYYYYY@gitlab.com/username/myrepo.git Playbook
You can either create a playbook named with the hostname of the remote server, eg. node1.yml or use the local.yml as the default playbook name.
Here is an example that will also put ansible-pull into a cron entry. This is very useful because it will check for any changes in the git repo every 15 minutes and run ansible again.
- hosts: localhost
tasks:
- name: Ensure ansible-pull is running every 15 minutes
cron:
name: "ansible-pull"
minute: "15"
job: "ansible-pull -U https://gitlab+deploy-token-XXXXX:YYYYYYYY@gitlab.com/username/myrepo.git &> /dev/null"
- name: Create a custom local vimrc file
lineinfile:
path: /etc/vim/vimrc.local
line: 'set modeline'
create: yes
- name: Remove "cloud-init" package
apt:
name: "cloud-init"
purge: yes
state: absent
- name: Remove useless packages from the cache
apt:
autoclean: yes
- name: Remove dependencies that are no longer required
apt:
autoremove: yes
# vim: sts=2 sw=2 ts=2 et
More Languages to the F-Droid Planet?
You may know about Planet F-Droid, a feed aggregator that aims to collect the blogs of many free Android projects in one place. Currently all of the registered blogs are written in English (as is this post, so if you know someone who might be concerned by the matter below and is not able to understand English, please feel free to translate for them).
Recently someone suggested that we should maybe create additional feeds for blogs in other languages. I’m not sure if there is interest in having support for more languages, so that’s why I want to ask you.
If you feel that Planet F-Droid should offer additional feeds for non-English blogs, please vote by thumbs up/down in the planets repository.
Happy Hacking!
Friday, 01 March 2019
Protect freedom on radio devices: raise your voice today!
We are facing a EU regulation which may make it impossible to install a custom piece of software on most radio decives like WiFi routers, smartphones and embedded devices. You can now give feedback on the most problematic part by Monday, 4 March. Please participate – it’s not hard!

In the EU Radio Equipment Directive (2014/53/EU) contains one highly dangerous article will cause many issues if implemented: Article 3(3)(i). It requires hardware manufacturers of most devices sending and receiving radio signals to implement a barrier that disallows installing software which has not been certified by the manufacturer. That means, that for installing an alternative operating system on a router, mobile phone or any other radio-capable device, the manufacturer of this device has to assess its conformity.
[R]adio equipment [shall support] certain features in order to ensure that software can only be loaded into the radio equipment where the compliance of the combination of the radio equipment and software has been demonstrated.
Article 3(3)(i) of the Radio Equipment Directive 2014/53/EU
That flips the responsibility of radio conformity by 180°. In the past, you as the one who changed the software on a device have been responsible to make sure that you don’t break any applicable regulations like frequency and signal strength. Now, the manufacturers have to prevent you from doing something wrong (or right?). That further takes away freedom to control our technology. More information here by the FSFE.
The European Commission has installed an Expert Group to come up with a list of classes of devices which are supposed to be affected by the said article. Unfortunately, as it seems, the recommendation by this group is to put highly diffuse device categories like „Software Defined Radio“ and „Internet of Things“ under the scope of this regulation.
Get active today
But there is something you can do! The European Commission has officially opened a feedback period. Everyone, individuals, companies and organisations, can provide statements on their proposed plans. All you need to participate is an EU Login account, and you can hide your name from the public list of received feedback. A summary, the impact assessment, already received feedback, and the actual feedback form is available here.
To help you word your feedback, here’s a list of some of the most important disadvantages for user freedom I see (there is a more detailed list by the FSFE):
- Free Software: To control technology, you have to be able to control the software. This only is possible with Free and Open Source Software. So if you want to have a transparent and trustworthy device, you need to make the software running on it Free Software. But any device affected by Article 3(3)(i) will only allow the installation of software authorised by the manufacturer. It is unlikely that a manufacturer will certify all the available software for your device which suits your needs. Having these gatekeepers with their particular interests will make using Free Software on radio devices hard.
- Security: Radio equipment like smartphones, routers, or smart home devices are highly sensitive parts of our lives. Unfortunately, many manufacturers sacrifice security for lower costs. For many devices there is better software which protects data and still offers equal or even better functionality. If such manufacturers do not even care for security, will they even allow running other (Free and Open Source) software on their products?
- Fair competition: If you don’t like a certain product, you can use another one from a different manufacturer. If you don’t find any device suiting your requirements, you can (help) establish a new competitor that e.g. enables user freedom. But Article 3(3)(i) favours huge enterprises as it forces companies to install software barriers and do certification of additional software. For example, a small and medium-sized manufacturer of wifi routers cannot certify all available Free Software operating systems. Also, companies bundling their own software with third-party hardware will have a really hard time. On the other hand, large companies which don’t want users to use any other software than their own will profit from this threshold.
- Community services: Volunteer initiatives like Freifunk depend on hardware which they can use with their own software for their charity causes. They were able to create innovative solutions with limited resources.
- Sustainability: No updates available any more for your smartphone or router? From a security perspective, there are only two options: Flash another firmware which still recieves updates, or throw the whole device away. From an environmental perspective, the first solution is much better obviously. But will manufacturers still certify alternative firmware for devices they want to get rid of? I doubt so…
There will surely be more, so please make your points in your individual feedback. It will send a signal to the European Commission that there are people who care about freedom on radio devices. It’s only a few minutes work to avoid legal barriers that will worsen your and others‘ lives for years.
Thank you!
Tuesday, 26 February 2019
TIL: Browsers ignore Expires header on reload

This may have been obvious, but I’ve just learned that browsers ignore Expires header when the user manually reloads the page (as in by pressing F5 or choosing Reload option).
I’ve run into this when testing how Firefox treats pages which ‘never’ expire. To my surprise, the browser made requests for files it had a fresh copy of in its cache. To see behaviour much more representative of the experience of a returning user, one should select the address bar (Alt+D does the trick) and then press Return to navigate to the current page again. Hitting Reload is more akin, though not exactly the same, to the first visit.
Of course, all of the above applies to the max-age directive of the Cache-Control header as well.
Moral of the story? Make sure you test the actual real-life scenarios before making any decisions.
Saturday, 23 February 2019
An argument for the existence of non-binary gender identities
So there’s a thought I’ve been having lately. The idea that some people identify as neither male nor female has become more mainstream over the past few years. And I assume like a lot of people, I’ve struggled with giving those people a place within my own concept and experience of gender. So I’d taken the accepting-but-condescending view of “yeah whatever, do what makes you happy, I just don’t understand it”. That stance is sufficient for making the lives of those people nicer, but what really makes the lives of those people nicer is if they feel understood and believed.
And I think I finally grok it within my own understanding of what gender is. I want to share this, but it requires already being on board with a few things:
Gender is a social construct, in so much as it can only be understood by humans within social contexts. It is different from biological sex, but possibly informed by it. Some people understand gender to be bad because it is a social construct, but I am not one of those people.
Transgender people exist. This mostly goes without saying, but it needs saying. Some people, somehow, are inclined towards a gender that does not match with their sex.
Trans women are women. Trans men are men. There are a lot of arguments for this—just pick your poison for which one you like best. I am personally convinced by performativism, or the Intrinsic Inclination model suggested by Julia Serano.
Intersex people exist. This also goes without saying. Some people are born neither male nor female, either because their genetics are different, or because their genitals are different.
The last point is especially important. As you do, I was thinking about intersex people a few weeks ago, and I wondered what gender they might identify as. What usually happens is that they gravitate towards either binary choice, and that is fine. But I wondered then, what if they do not? What if they identify along the same lines of their sex: somewhere in between?
I could not find a single good argument that might explain why they couldn’t. Even a gender essentialist might be convinced that an intersex person has every right to identify somewhere in between in line with their physical sex. So if there is room for an “intersex” gender identity, then that must necessarily mean that gender is a spectrum.
And if gender is a spectrum, and we agree that the gender identities of trans people are valid even though they do not match their sex, then that must necessarily mean that the gender identities of non-binary people are also valid. Otherwise you end up in a strange situation where only intersex people are allowed to identify as non-binary, which is equally as restricting as saying that only cis men are allowed to identify as men.
I am half-certain that I am making some incorrect leaps in logic here or there, and I am not academically well-read on the topic, but this reasoning helped me a lot with at least giving the existence of a non-binary gender identity a place within my own framework of how gender works. And I hope it helps others too.
Open Call: carpenter for children’s playground in refugee camp Greece
On of the members of the Designers With Refugees community, which is part of innovation lab Latra, shared the following open call:
Subject: My quest for a compassionate Carpenter
Dear reader,
I wanted to grab your attention for the following. Finally, after weeks of being in contact with different people and organisations, I settled with a new project on Lesvos.
Refugee 4 Refugees together with Infinitum Limits is setting up a new project, called Mandala, right next to the Olive Grove and camp Moria. A field of +/†4000 m2 will be transformed into a child friendly space, offering education, sports and play activities, with the aim to create a safe space.
I will go there with a small team to help out in the design and build activities from half of March to the end of May. At the moment I am with a civil engineer and another architecture student, but I’m still looking for a fairly skilled carpenter to strengthen the team for any amount of time in above period, on site! I’m able to offer free accommodation.
Would you all like to consider whether this could apply on you or someone you know well that would openâ€minded for this? It would mean a lot tome to find someone!
Also if you’re not a carpenter but would like to learn more, contact me! 
WhatsApp: 0613332421
Email: *protected email*
The information is also available for download as PDF.
Thursday, 21 February 2019
ArchLinux WSL
This article will show how to install Arch Linux in Windows 10 under Windows Subsystem for Linux.
WSL
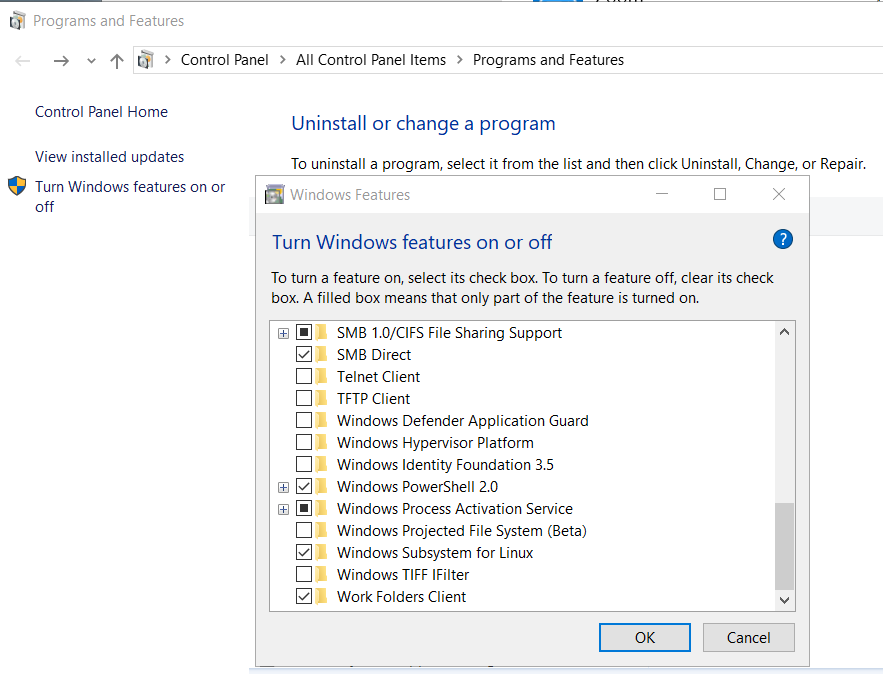
Prerequisite is to have enabled WSL on your Win10 and already reboot your machine.
You can enable WSL :
- Windows Settings
- Apps
- Apps & features
- Related settings -> Programs and Features (bottom)
- Turn Windows features on or off (left)
Store
After rebooting your Win10, you can use Microsoft Store to install a Linux distribution like Ubuntu. Archlinux is not an official supported linux distribution thus this guide !
Launcher
The easiest way to install Archlinux (or any Linux distro) is to download the wsldl from github. This project provides a generic Launcher.exe and any rootfs as source base. First thing is to rename Launcher.exe to Archlinux.exe.
ebal@myworklaptop:~$ mkdir -pv Archlinux
mkdir: created directory 'Archlinux'
ebal@myworklaptop:~$ cd Archlinux/
ebal@myworklaptop:~/Archlinux$ curl -sL -o Archlinux.exe https://github.com/yuk7/wsldl/releases/download/18122700/Launcher.exe
ebal@myworklaptop:~/Archlinux$ ls -l
total 320
-rw-rw-rw- 1 ebal ebal 143147 Feb 21 20:40 Archlinux.exe
RootFS
Next step is to download the latest archlinux root filesystem and create a new rootfs.tar.gz archive file, as wsldl uses this type.
ebal@myworklaptop:~/Archlinux$ curl -sLO http://ftp.otenet.gr/linux/archlinux/iso/latest/archlinux-bootstrap-2019.02.01-x86_64.tar.gz
ebal@myworklaptop:~/Archlinux$ ls -l
total 147392
-rw-rw-rw- 1 ebal ebal 143147 Feb 21 20:40 Archlinux.exe
-rw-rw-rw- 1 ebal ebal 149030552 Feb 21 20:42 archlinux-bootstrap-2019.02.01-x86_64.tar.gz
ebal@myworklaptop:~/Archlinux$ sudo tar xf archlinux-bootstrap-2019.02.01-x86_64.tar.gz
ebal@myworklaptop:~/Archlinux$ cd root.x86_64/
ebal@myworklaptop:~/Archlinux/root.x86_64$ ls
README bin boot dev etc home lib lib64 mnt opt proc root run sbin srv sys tmp usr var
ebal@myworklaptop:~/Archlinux/root.x86_64$ sudo tar czf rootfs.tar.gz .
tar: .: file changed as we read it
ebal@myworklaptop:~/Archlinux/root.x86_64$ ls
README bin boot dev etc home lib lib64 mnt opt proc root rootfs.tar.gz run sbin srv sys tmp usr var
ebal@myworklaptop:~/Archlinux/root.x86_64$ du -sh rootfs.tar.gz
144M rootfs.tar.gz
ebal@myworklaptop:~/Archlinux/root.x86_64$ sudo mv rootfs.tar.gz ../
ebal@myworklaptop:~/Archlinux/root.x86_64$ cd ..
ebal@myworklaptop:~/Archlinux$ ls
Archlinux.exe archlinux-bootstrap-2019.02.01-x86_64.tar.gz root.x86_64 rootfs.tar.gz
ebal@myworklaptop:~/Archlinux$
ebal@myworklaptop:~/Archlinux$ ls
Archlinux.exe rootfs.tar.gz
ebal@myworklaptop:~$ mv Archlinux/ /mnt/c/Users/EvaggelosBalaskas/Downloads/ArchlinuxWSL
ebal@myworklaptop:~$As you can see, I do a little clean up and I move the directory under windows filesystem.
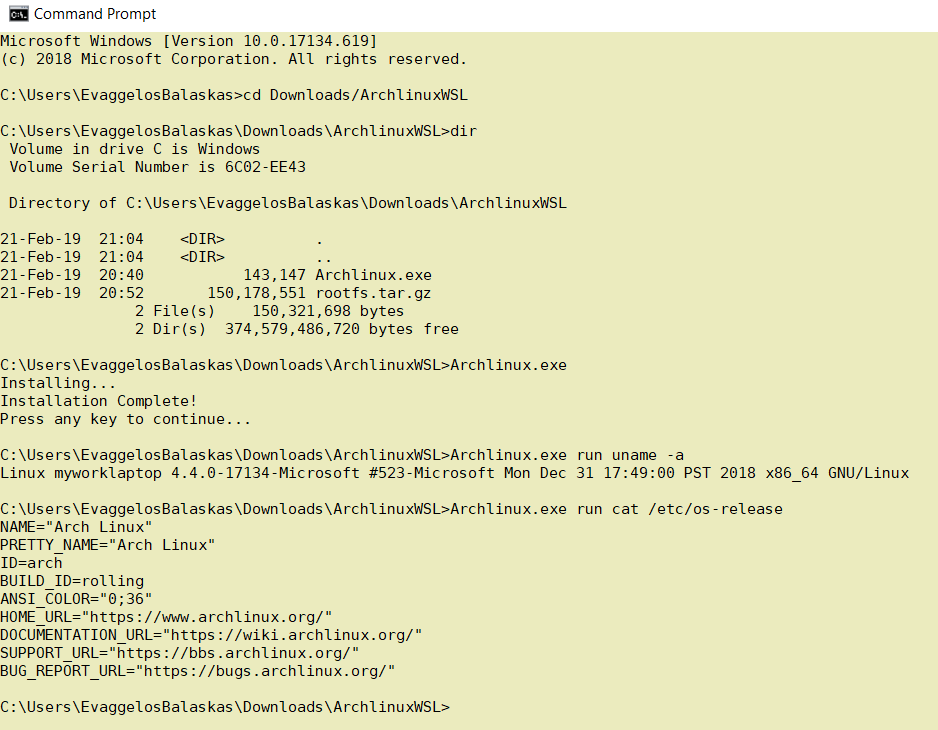
Install & Verify
Microsoft Windows [Version 10.0.17134.619]
(c) 2018 Microsoft Corporation. All rights reserved.
C:UsersEvaggelosBalaskas>cd Downloads/ArchlinuxWSL
C:UsersEvaggelosBalaskasDownloadsArchlinuxWSL>dir
Volume in drive C is Windows
Volume Serial Number is 6C02-EE43
Directory of C:UsersEvaggelosBalaskasDownloadsArchlinuxWSL
21-Feb-19 21:04 <DIR> .
21-Feb-19 21:04 <DIR> ..
21-Feb-19 20:40 143,147 Archlinux.exe
21-Feb-19 20:52 150,178,551 rootfs.tar.gz
2 File(s) 150,321,698 bytes
2 Dir(s) 374,579,486,720 bytes free
C:UsersEvaggelosBalaskasDownloadsArchlinuxWSL>Archlinux.exe
Installing...
Installation Complete!
Press any key to continue...
C:UsersEvaggelosBalaskasDownloadsArchlinuxWSL>Archlinux.exe run uname -a
Linux myworklaptop 4.4.0-17134-Microsoft #523-Microsoft Mon Dec 31 17:49:00 PST 2018 x86_64 GNU/Linux
C:UsersEvaggelosBalaskasDownloadsArchlinuxWSL>Archlinux.exe run cat /etc/os-release
NAME="Arch Linux"
PRETTY_NAME="Arch Linux"
ID=arch
BUILD_ID=rolling
ANSI_COLOR="0;36"
HOME_URL="https://www.archlinux.org/"
DOCUMENTATION_URL="https://wiki.archlinux.org/"
SUPPORT_URL="https://bbs.archlinux.org/"
BUG_REPORT_URL="https://bugs.archlinux.org/"
C:UsersEvaggelosBalaskasDownloadsArchlinuxWSL>Archlinux.exe run bash
[root@myworklaptop ArchlinuxWSL]#
[root@myworklaptop ArchlinuxWSL]# exit
Archlinux
C:UsersEvaggelosBalaskasDownloadsArchlinuxWSL>Archlinux.exe run bash
[root@myworklaptop ArchlinuxWSL]#
[root@myworklaptop ArchlinuxWSL]# date
Thu Feb 21 21:41:41 STD 2019Remember, archlinux by default does not have any configuration. So you need to configure this instance !
Here are some basic configuration:
[root@myworklaptop ArchlinuxWSL]# echo nameserver 8.8.8.8 > /etc/resolv.conf
[root@myworklaptop ArchlinuxWSL]# cat > /etc/pacman.d/mirrorlist <<EOF
Server = http://ftp.otenet.gr/linux/archlinux/$repo/os/$arch
EOF
[root@myworklaptop ArchlinuxWSL]# pacman-key --init
[root@myworklaptop ArchlinuxWSL]# pacman-key --populate
[root@myworklaptop ArchlinuxWSL]# pacman -Syyyou are pretty much ready to use archlinux inside your windows 10 !!
Remove
You can remove Archlinux by simple:
Archlinux.exe clean
Default User
There is a simple way to use Archlinux within Windows Subsystem for Linux , by connecting with a default user.
But before configure ArchWSL, we need to create this user inside the archlinux instance:
[root@myworklaptop ArchWSL]# useradd -g 374 -u 374 ebal
[root@myworklaptop ArchWSL]# id ebal
uid=374(ebal) gid=374(ebal) groups=374(ebal)
[root@myworklaptop ArchWSL]# cp -rav /etc/skel/ /home/ebal
'/etc/skel/' -> '/home/ebal'
'/etc/skel/.bashrc' -> '/home/ebal/.bashrc'
'/etc/skel/.bash_profile' -> '/home/ebal/.bash_profile'
'/etc/skel/.bash_logout' -> '/home/ebal/.bash_logout'
chown -R ebal:ebal /home/ebal/then exit the linux app and run:
> Archlinux.exe config --default-user ebaland try to login again:
> Archlinux.exe run bash
[ebal@myworklaptop ArchWSL]$
[ebal@myworklaptop ArchWSL]$ cd ~
ebal@myworklaptop ~$ pwd -P
/home/ebal
Wednesday, 20 February 2019
I am up to no good.
I am a user of “the darknet”. I use Tor to secure my communications from curious eyes. At the latest since Edward Snowden’s leaks we know, that this might be a good idea. There are many other valid, legal use-cases for using Tor. Circumventing censorship is one of them.
But German state secretary GĂźnter Krings (49, CDU) believes something else. Certainly he “understand[s], that the darknet may have a use in autocratic systems, but in my opinion there is no legitimate use for it in a free, open democracy. Whoever uses the darknet is usually up to no good.”
GĂźnter Krings should know, that Tor is only capable to reliably anonymize users traffic, if enough “noise” is being generated. That is the case if many users use Tor, so that those who really depend their life on it can blend in with the masses. Shamed be he, who thinks evil of it.
I’d like to know, if Krings ever thought about the fact that maybe, just maybe an open, free democracy is the only political system that is even capable to tolerate “the darknet”. Forbidding its use would only bring us one step closer to becoming said autocratic system.
Instead of trying to ban our democratic people from using tor, we should celebrate the fact that we are a democracy that can afford having citizens who can avoid surveillance and that have access to uncensored information.
Integrating libext2fs with a Filesystem Framework
Given the content covered by my previous articles, there probably doesn’t seem to be too much that needs saying about the topic covered by this article. Previously, I described the work involved in building libext2fs for L4Re and testing the library, and I described a framework for separating filesystem providers from programs that want to use files. But, as always, there are plenty of little details, detours and learning experiences that help to make the tale longer than it otherwise might have been.
Although this file access framework sounds intimidating, it is always worth remembering that the only exotic thing about the software being written is that it needs to request system resources and to communicate with other programs. That can be tricky in itself in many programming environments, and I have certainly spent enough time trying to figure out how to use the types and functions provided by the many L4Re libraries so that these operations may actually work.
But in the end, these are programs that are run just like any other. We aren’t building things into the kernel and having to conform to a particularly restricted environment. And although it can still be tiresome to have to debug things, particularly interprocess communication (IPC) problems, many familiar techniques for debugging and inspecting program behaviour remain available to us.
A Quick Translation
The test program I had written for libext2fs simply opened a file located in the “rom” filesystem, exposed it to libext2fs, and performed operations to extract content. In my framework, I had directed my attention towards opening and reading files, so it made sense to concentrate on providing this functionality in a filesystem server or “provider”.

Accessing a filesystem server employing a "rom" file for the data
The user of the framework (shielded from the details by a client library) would request the opening of a file (thus obtaining a file descriptor able to communicate with a dedicated resource object) and then read from the file (causing communication with the resource object and some transfers of data). These operations, previously done in a single program employing libext2fs directly, would now require collaboration by two separate programs.
So, I would need to insert the appropriate code in the right places in my filesystem server and its objects to open a filesystem, search for a file of the given name, and to provide the file data. For the first of these, the test program was doing something like this in the main function:
retval = ext2fs_open(devname, EXT2_FLAG_RW, 0, 0, unix_io_manager, &fs);
In the main function of the filesystem server program, something similar needs to be done. A reference to the filesystem (fs) is then passed to the server object for it to use:
Fs_server server_obj(fs, devname);
When a request is made to open a file, the filesystem server needs to locate the file just as the test program needed to. The code to achieve this is tedious, employing the ext2fs_lookup function and traversing the directory hierarchy. Ultimately, something like this needs to be done to obtain a structure for accessing the file contents:
retval = ext2fs_file_open(_fs, ino_file, ext2flags, &file);
Here, the _fs variable is our reference in the server object to the filesystem structure, the ino_file variable refers to the place in the filesystem where the file is found (the inode), some flags indicate things like whether we are reading and/or writing, and a supplied file variable is set upon the successful opening of the file. In the filesystem server, we want to create a specific object to conduct access to the file:
Fs_object *obj = new Fs_object(file, EXT2_I_SIZE(&inode_file), fsobj, irq);
Here, this resource object is initialised with the file access structure, an indication of the file size, something encapsulating the state of the communication between client and server, and the IRQ object needed for cleaning up (as described in the last article). Meanwhile, in the resource object, the read operation is supported by a pair of libext2fs functions:
ext2fs_file_lseek(_file, _obj.position, EXT2_SEEK_SET, 0); ext2fs_file_read(_file, _obj.buffer, to_transfer, &read);
These don’t appear next to each other in the actual code, but the first call is used to seek to the indicated position in the file, this having been specified by the client. The second call appears in a loop to read into a buffer an indicated amount of data, returning the amount that was actually read.
In summary, the work done by a collection of function calls appearing together in a single function is now spread out over three places in the filesystem server program:
- The initialisation is done in the main function as the server starts up
- The locating and opening of a file in the filesystem is done in the general filesystem server object
- Reading and writing is done in the file-specific resource object
After initialisation, the performance of each part of the work only occurs upon receiving a distinct kind of message from a client program, of which more details are given below.
The Client Library
Although we cannot yet use the familiar C library functions for accessing files (fopen, fread, fwrite, fclose, and so on), we can employ functions that try to be as friendly. Thus, the following form of program may be used:
char buffer[80];
file_descriptor_t *desc = client_open("test.txt", O_RDONLY);
available = client_read(desc, buffer, 80);
if (available)
fwrite((void *) buffer, sizeof(char), available, stdout); /* using existing fwrite function */
client_close(desc);
As noted above, the existing fwrite function in L4Re may be used to write file data out to the console. Ultimately, we would want our modified version of the function to be doing this job.
These client library functions resemble lower-level C library functions such as open, read, write, close, and so on. By targeting this particular level of functionality, it is hoped that much of the logic in functions like fopen can be preserved, this logic having to deal with things like mode strings (“r”, “r+”, “w”, and so on) which have little to do with the actual job of transmitting file content around the system.
In order to do their work, the client library functions need to send and receive IPC messages, or at least need to get other functions to deal with this particular work. My approach has been to write a layer of functions that only deals with messaging and that hides the L4-specific details from the rest of the code.
This lower-level layer of functions allows us to treat interprocess interactions like normal function calls, and in this framework those calls would have the following signatures, with the inputs arriving at the server and the outputs arriving back at the client:
- fs_open: flags, buffer → file size, resource object
- fs_flush: (no parameters) → (no return values)
- fs_read: position → available
- fs_write: position, available → written, file size
The responsibilities of the client library functions can be summarised as follows:
- client_open: allocate memory for the buffer, obtain a server reference (“capability”) from the program’s environment
- client_close: deallocate the allocated resources
- client_flush: invoke fs_flush with any available data, resetting the buffer status
- client_read: provide data to the caller from its buffer, invoking fs_read whenever the buffer is empty
- client_write: commit data from the caller into the buffer, invoking fs_write whenever the buffer is full, also flushing the buffer when appropriate
The lack of a fs_close function might seem surprising, but as described in the previous article, the server process is designed to receive a notification when the client process discards a reference to the resource object dedicated to a particular file. So in client_close, we should be able to merely throw away the things acquired by client_open, and the system together with the server will hopefully handle the consequences.
Switching the Backend
Using a conventional file as the repository for file content is convenient, but since the aim is to replace the existing filesystem mechanisms, it would seem necessary to try and get libext2fs to use other ways of accessing the underlying storage. Previously, my considerations had led me to provide a “block” storage layer underneath the filesystem layer. So it made sense to investigate how libext2fs might communicate with a “block server” or “block device” in order to read and write raw filesystem data.

Employing a separate server to provide filesystem data
Changing the way libext2fs accesses its storage sounds like an ominous task, but fortunately some thought has evidently gone into accommodating different storage types and platforms. Indeed, the library code includes support for things like DOS and Windows, with this functionality evidently being used by various applications on those platforms (or, these days, the latter one, at least) to provide some kind of file browser support for ext2-family filesystems.
The kind of component involved in providing this variety of support is known as an “I/O manager”, and the one that we have been using is known as the “Unix” I/O manager, this employing POSIX or standard C library calls to access files and devices. Now, this may have been adequate until now, but with the requirement that we use the replacement IPC mechanisms to access a block server, we need to consider how a different kind of I/O manager might be implemented to use the client library functions instead of the C library functions.
This exercise turned out to be relatively straightforward and perhaps a little less work than envisaged once the requirements of initialising an io_channel object had been understood, this involving the allocation of memory and the population of a structure to indicate things like the block size, error status, and so on. Beyond this, the principal operations needing support are as follows:
- open: initialises the io_channel and calls client_open
- close: calls client_close
- set block size: sets the block size for transfers, something that gets done at various points in the opening of a filesystem
- read block: calls client_seek and client_read to obtain data from the block server
- write block: calls client_seek and client_write to commit data to the block server
It should be noted that the block server largely acts like a single-file filesystem, so the same interface supported by the filesystem server is also supported by the block server. This is how we get away with using the client libraries.
Meanwhile, in the filesystem server code, the only changes required are to declare the new I/O manager, implemented in a separate library package, and to use it instead of the previous one:
retval = ext2fs_open(devname, ext2flags, 0, 0, blockserver_io_manager, &fs);
The Final Trick
By pushing use of the “rom” filesystem further down in the system, use of the new file access mechanisms can be introduced and tested, with the only “unauthentic” aspect of the arrangement being that a parallel set of file access functions is being used instead of the conventional ones. The only thing left to do would be to change the C library to incorporate the new style of file access, probably by incorporating the client library internally, thus switching the C library away from its previous method of accessing files.
With the conventional file abstractions reimplemented, access to files would go via the virtual filesystem and hopefully end up encountering block devices that are able to serve up the needed data directly. And ultimately, we could end up switching back to using the Unix I/O manager with libext2fs.

Introducing the new IPC mechanisms at the C library level
Changing things so drastically would also force us to think about maintaining access to the “rom” filesystem through the revised architecture, at least at first, because it happens to provide a very convenient way of getting access to data for use as storage. We could try and implement storage hardware support in order to get round this problem, but that probably isn’t convenient – or would be a distraction – when running L4Re on Fiasco.OC-UX as a kind of hosted version of the software.
Indeed, tackling the C library is probably too much of a challenge at this early stage. Fortunately, there are plenty of other issues to be considered first, with the use of non-standard file access functions being only a minor inconvenience in the broader scheme of things. For instance, how are permissions and user identities to be managed? What about concurrent access to the filesystem? And what mechanisms would need to be provided for grafting filesystems onto a larger virtual filesystem hierarchy? I hope to try and discuss some of these things in future articles.
Sunday, 17 February 2019
Setting up Tor hidden service
Anyone can think of myriad reasons to run a Tor hidden service. Surely many unsavoury endeavours spring to mind but of course, there are as many noble ones. There are also various pragmatic causes like circumventing lousy NATs. Me? I just wanted to play around with my router.
Configuring a hidden service is actually straightforward so to make things more interesting, this article will cover configuring a hidden service on a Turris Omnia router with the help of Linux Containers to maximise isolation of components. While some steps will be Omnia-specific, most translate easily to other systems, so this post may be applicable regardless of the distribution used.
External drive
Turris Omnia uses an eMMC as its root device which, on the count of it being soldered onto the board, is hard to replace. To mitigate the risk of it wearing off, data can be saved onto external storage instead. The router comes with mSATA slot and USB ports. Either can be used to attach a drive. In addition, mPCIE SATA controller is included in the NAS version of the router and can be added to regular versions.
No matter how additional storage is attached, it can be mounted under /srv directory which is where many applications will store their data. This is a completely adequate solution but there’s also a more… exciting alternative: making the router boot from the external drive. The upside is that the eMMC will never wear off. The downside is that it won’t work with a storage device attached through a SATA controller.
First, access to the router’s serial console needs to be established. Any USB to UART connector—such as TTL-232R-RPI or something PL2303-based—should work. If pinout of the converter isn’t documented, it’s usually enough to open it and look at the labels printed on its PCB.  On Omnia’s side, UART header is located between LEDs and brightness button. Starting from the side close to the LEDs, the pins are ground, RX, TX and usually unused +3.3V.
On Omnia’s side, UART header is located between LEDs and brightness button. Starting from the side close to the LEDs, the pins are ground, RX, TX and usually unused +3.3V.
{kind=link}
Once the connection to the serial console is established, configuring the router to boot from an external drive is as easy as grabbing Omnia’s medkit and following official instructions. One thing to consider is that /dev/sda1 name is unstable so rather than root=/dev/sda1 kernel argument advocated by the official method it’s better to use partition UUID. For MBR partition tables, it is composed of disk identifier and partition number which can both be obtained from the output of fdisk -l.
# fdisk -l /dev/sda Disk /dev/sda: 55.9 GiB, 60022480896 bytes, 117231408 sectors Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disklabel type: dos Disk identifier: 0xe17eb372 Device Boot Start End Sectors Size Id Type /dev/sda1 2048 117231407 117229360 55.9G 83 Linux
For example, if the disk identifier is e17eb372 (as shown in listing above), root=PARTUUID=e17eb372-01 should be used instead of root=/dev/sda1 when setting bootloader’s bootargs variable. If the time ever comes to replace the disk, the identifier of a new drive can be set to match the original using fdisk’s expert mode.
Linux Containers
To improve isolation between components, it’s a good idea to take advantage of Linux Containers (LXC). On Omnia, LXC utilities are installed in the Updater section of Foris interface. The installation procedure will differ on other systems and their documentation should be consulted.
Web server
| Local network | 192.168.1.0/24 |
|---|---|
| Gateway & DNS | 192.168.1.1 |
| Web server host | 192.168.1.80 |
This article will use a web server as an example of hidden service’s back-end, but one should remember that anything accepting TCP connections can be used: SSH server, IRC bouncer and SOCKS proxy are all valid candidates.
First, a new container is needed. Because alpine is a lightweight, security-oriented Linux distribution it is a good choice for container’s base image. To make things easier, it will be configured with static IP of 192.168.1.80 with 192.168.1.1 default gateway and DNS server.
[turris]# lxc-create -n www -P /srv/lxc -t download -- \
-d Alpine -r Edge -a "$(uname -m)"
[turris]# cat >/srv/lxc/www/rootfs/etc/network/interfaces \
<<EOF
auto eth0
iface eth0 inet static
address 192.168.1.80
netmask 255.255.255.0
gateway 192.168.1.1
hostname \$(hostname)
EOF
[turris]# echo nameserver 192.168.1.1 \
>/srv/lxc/www/rootfs/etc/resolv.conf
[turris]# lxc-start -n www
[turris]# lxc-attach -n www
[www]# apk add lighttpd logrotate
[www]# rc-update add lighttpd
[www]# rc-service lighttpd start
[www]# exitAt this point, 192.168.1.80 should lead to ‘It works’ web page. Since the HTTP server does not need to make any outgoing connections, the image can (should) have network traffic restricted with the following rules:
[turris]# opkg install iptables-mod-extra
[turris]# lxc-attach -n www
[www]# apk add iptables
# Allow incoming connections from LAN only
[www]# iptables -A INPUT -s 192.168.1.0/16 -j ACCEPT
[www]# iptables -A INPUT -m state --state NEW -j DROP
# Don’t allow any forwarding
[www]# iptables -P FORWARD DROP
# Let root resolve domain names
[www]# iptables -A OUTPUT -d 192.168.1.1 -p udp --dport 53 \
-m owner --uid-owner 0 -j ACCEPT
[www]# iptables -A OUTPUT -d 192.168.1.1 -p tcp --dport 53 \
-m owner --uid-owner 0 -j ACCEPT
# Don’t allow initiating connections to LAN
[www]# iptables -A OUTPUT -d 192.168.1.0/16 -m state --state NEW -j DROP
[www]# iptables -A OUTPUT -d 192.168.1.0/16 -j ACCEPT
# Allow only root to talk to the Internet
[www]# iptables -A OUTPUT -m owner --uid-owner 0 -j ACCEPT
[www]# iptables -P OUTPUT DROP
# Store and apply the rules on each boot
[www]# rc-update add iptables
[www]# /etc/init.d/iptables save
[www]# exitTor
The next step is setting up Tor. Like before, it’s going to run inside of a container to maximise isolation. However, this time the image will be using dynamic IP since its address won’t be hard-coded anywhere.
[turris]# lxc-create -n tor -P /srv/lxc -t download -- \
-d Alpine -r Edge -a "$(uname -m)"
[turris]# lxc-start -n tor
[turris]# lxc-attach -n tor
[tor]# apk add tor logrotate
[tor]# cat >/etc/tor/torrc <<EOF
User tor
SOCKSPort 0
SOCKSPolicy reject *
ExitRelay 0
ExitPolicy reject *:*
Log notice file /var/log/tor/notices.log
DataDirectory /var/lib/tor
HiddenServiceDir /var/lib/tor/hidden
HiddenServiceVersion 3
HiddenServicePort 80 192.168.1.80:80
EOF
[tor]# rc-update add tor
[tor]# rc-service tor start
[tor]# exitOnce Tor is started, it’ll automatically generate keys for the hidden service and save its .onion address in /var/lib/tor/hidden-site/hostname file (or /srv/lxc/tor/rootfs/var/lib/tor/hidden-site/hostname if acessing it from outside of the container).
At this point, everything should work. The web server should be accessible via its local address as well as through its .onion address.
To finish up with the container, firewall rules need to be created. Tor needs to be able to talk to the Internet and to the web server but does not need to connect to any other hosts on the local network nor accept any incoming connections. This can be codified with the following instructions:
[turris]# opkg install iptables-mod-extra [turris]# lxc-attach -n tor [tor]# apk add iptables # Disallow incoming connections [tor]# iptables -A INPUT -m state --state NEW -j DROP # Don’t allow any forwarding [tor]# iptables -P FORWARD DROP # Allow talking to local DNS [tor]# iptables -A OUTPUT -d 192.168.1.1 -p udp --dport 53 -j ACCEPT [tor]# iptables -A OUTPUT -d 192.168.1.1 -p tcp --dport 53 -j ACCEPT # and the web server that’s being hidden # iptables -A OUTPUT -d 192.168.1.80 -p tcp --dport 80 -j ACCEPT # but no other host in LAN. # iptables -A OUTPUT -d 192.168.1.0/16 -j DROP # Store and apply the rules on each boot [tor]# rc-update add iptables [tor]# /etc/init.d/iptables save [tor]# exit
Making containers start at boot
The final thing to do is make both containers start when the router boots. Otherwise, the hidden service will stop working as soon as host reboots. In Omnia this is done by editing /etc/config/lxc-auto file to contain the following:
config container option name www config container option name tor
Security considerations
While setting up a hidden service is trivial, making it secure is another matter. It’s not inconceivable that some servers may be tricked to leak information about their external IP. Perhaps an FTP server is made to make an active data connection over the Internet. Maybe an HTTP server displays its external address in error pages. Not to mention arbitrary command execution exploits which could be used to make simple requests over the Internet. Restricting service’s back-end access to the Internet (as has been done in this article) or configuring it to only ever use Tor circuits is one defence.
It’s also important to keep in mind that Tor relays report all their bandwidth publicly. In other words, if a process providing a hidden service is also running as a relay, it is theoretically possible to locate the service by issuing requests to it and observing transfer reported by the relay. As such, a Tor relay shouldn’t be run on an instance which is also providing a hidden service.
Security of the service is beyond the scope of this article (especially as in my case privacy is not of paramount importance) so the reader is encouraged to do their own due diligence.
Thursday, 14 February 2019
The world’s most advanced UNICs of Organizers

I recently began using Emacs Org mode, a tool for keeping notes, maintaining TODO lists, planning projects, and authoring documents with a fast and effective plain-text system.
Since I am a cosplayer I was looking for a repacement for Cosplanner, a non-free Android app. When I was still using Android, I once installed Cosplanner and found out that it has many nasty features. So I deleted my copy. Unlike Cosplanner, Orgmode uses a human readable text format that you can read with any text editor. This allows the user to store an Orgmode file in a git repository that can be synced between devices.
Emacs was written by Richard Stallman as part of the GNU Operating System. GNU is a Unix-compatible system that respects the users freedom. Todays GNU comes mainly in form of a GNU/Linux distribution, but the Hurd (GNU’s Kernel) still exists. The Guix System Distribution is one of those, it is often called the Emacs of Distros. There are many text editors, but Emacs is probably the worlds most advanced one.

I Love Free Software Day 2019
Free Software is a substantial part of my life. I got introduced to it by my computer science teacher in middle school, however back then I wasn’t paying that much attention to the ethics behind it and rather focused on the fact that it was gratis and new to me.
Using GNU/Linux on a school computer wasn’t really fun for me, as the user interface was not really my taste (I’m sorry KDE). It was only when I got so annoyed from the fact that my copy of Windows XP was 32 bit only and that I was supposed to pay the full price again for a 64 bit license, that I deleted Windows completely and installed Ubuntu on my computer – only to reinstall Windows again a few weeks later though. But the first contact was made.
Back then I was still mostly focused on cool features rather than on the meaning of free software. Someday however, I watched the talk by Richard Stallman and started to read more about what software freedom really is. At this point I was learning how to use blender on Ubuntu to create animations and only rarely booted into Windows. But when I did, it suddenly felt oddly wrong. I realized that I couldn’t truly trust my computer. This time I tried harder to get rid of Windows.
Someone once said that you only feel your shackles when you try to move. I think the same goes for free software. Once you realize what free software is and what rights it grants you (what rights you really have), you start to feel uncomfortable if you’re suddenly denied those rights.
And that’s why I love free software! It gives you back the control over your machine. It’s something that you can trust, as there are no secrets kept from you (except if the program is written in Haskell and uses monads :P).
My favorite free software projects for this years I love free software day are the document digitization and management tool paperwork, the alternative Mastodon/Pleroma interface Halcyon and the WordPress ActivityPub Plugin. These are projects that I discovered in 2018/2019 and that truly amazed me.
I already wrote two blog posts about paperwork and the fediverse / the ActivityPub plugin earlier, so I’ll focus mainly on Halcyon today. Feel free to give those other posts a read though!
I’m a really big fan of the fediverse and Mastodon in particular, but I dislike Mastodon’s current interface (two complaints about user interfaces in one post? Mimimi…). In my opinion Mastodons column interface doesn’t really give enough space to the content and is not very intuitive. Halcyon is a web client which acts as an alternative interface to your Mastodon/Pleroma account. Visually it closely resembles the Twitter UI which I quite like.

As a plus, it is way easier to get people to move from Twitter to the fediverse by providing them with a familiar interface 
There are some public instances of Halcyon available, which you can use to try out Halcyon for yourselves, however in the long run I recommend you to self-host it, as you have to enter your account details in order to use it. Hosting it doesn’t take much more than a simple Raspberry Pi as it’s really light weight.
I know that a huge number of free software projects is developed by volunteers in their free time. Most of them don’t get any monetary compensation for their work and people often take this for granted. Additionally, a lot of the feedback developers get from their users is when things don’t work out or break.
(Not only) today is a chance to give some positive feedback and a huge Thank You to the developers of the software that makes your life easier!
Happy Hacking!
Wednesday, 13 February 2019
Some Attention to Detail
I spent some time recently looking at my Python-like language, Lichen, and its toolchain. Although my focus was on improving support for floating point numbers and arithmetic, of which more may need to be written in a future article, I ended up noticing a few things that needed correcting and had escaped my attention. One of these probably goes a long way to solving a mystery raised in a previous article.
The investigation into floating point support necessitated some scrutiny of the way floating point numbers are allocated when compiled Lichen programs are run. CPython – the C language implementation of a virtual machine for the Python language – has various strategies for reserving memory for floating point numbers, this not being particularly surprising given what it does for integers, as we previously saw. What bothered me was how much time was being spent allocating space for numbers needed to store computation results.
I spent quite a bit of time looking at the run-time support code for compiled programs, trying different strategies to “preallocate” number instances and other things, but it was when I was considering various other optimisation strategies and running generated programs in the GNU debugger (gdb) that I happened to notice something about the type definitions that are generated for instances. For example, here is what a tuple instance type looks like:
typedef struct {
const __table * table;
__pos pos;
__attr attrs[__csize___builtins___tuple_tuple];
} __obj___builtins___tuple_tuple;
And here is what it should look like:
typedef struct {
const __table * table;
__pos pos;
__attr attrs[__isize___builtins___tuple_tuple];
} __obj___builtins___tuple_tuple;
Naturally, I will excuse you for not necessarily noticing the crucial difference, but it is the size of the attrs array, this defining the attributes that are available via each instance of the tuple type. And here, I had used a constant prefixed with “__csize” meaning class size, as opposed to “__isize” meaning instance size. With so many things to think about when finishing off my toolchain, I had accidentally presented the wrong kind of value to the code generating these type definitions.
So, what was going to happen was that instances were going to be given the wrong number of attributes: a potentially catastrophic fault! But it is in the case of types like the tuple where things get more interesting than that. Such types tend to have lots of methods associated with them, and these methods are, of course, stored as class attributes.
Meanwhile, tuple instances are likely to have far fewer attributes, and even when the tuple data is considered, since tuples frequently have few elements, such instances are also likely to be far smaller than the size of the tuple class’s structure. Indeed, the following definitions are more or less indicative of the sizes of the tuple class and of tuple instances:
__csize___builtins___tuple_tuple = 36 __isize___builtins___tuple_tuple = 2
And I had noticed this because, for some reason unknown to me at the time but obviously known to me now, floating point numbers were being allocated using far more space than I thought appropriate. Here are some definitions of interest:
__csize___builtins___float_float = 43 __isize___builtins___float_float = 1
Evidently, something was very wrong until I noticed my simple mistake: that in the code generating the definitions for program types, I had accidentally used the wrong constant for instance attribute arrays. Fixing this meant that the memory allocator probably only needed to find 16 bytes or so, as opposed to maybe 186 bytes, for each number!
Returning to tuples, though, it becomes interesting to see what effect this fix has on the performance of the benchmark previously discussed. We had previously seen that a program using tuples was inexplicably far slower than one employing objects to represent the same data. But with this unnecessary allocation occurring, it seems possible that this might have been making some extra work for the allocator and garbage collector.
Here is a table of measurements from running the benchmark before and after the fix had been applied:
| Program Version | Time | Maximum Memory Usage |
|---|---|---|
| Tuples | 24s | 122M |
| Objects | 15s | 54M |
| Tuples (fixed) | 17s | 30M |
| Objects (fixed) | 13s | 30M |
Although there is still a benefit to using objects to model data in Lichen as opposed to keeping such data in tuples, the benefit is not as pronounced as before, with the memory usage now clearly comparable as we would expect. With this fix applied, both versions of the benchmark are even faster than they were before, but it is especially gratifying that the object-based version is now ten times faster when compiled with the Lichen toolchain than the same program run by the CPython virtual machine.
Tuesday, 12 February 2019
Filesystem Abstractions for L4Re
In my previous posts, I discussed the possibility of using “real world” filesystems in L4Re, initially considering the nature of code to access an ext2-based filesystem using the library known as libext2fs, then getting some of that code working within L4Re itself. Having previously investigated the nature of abstractions for providing filesystems and file objects to applications, it was inevitable that I would now want to incorporate libext2fs into those abstractions and to try and access files residing in an ext2 filesystem using those abstractions.
It should be remembered that L4Re already provides a framework for filesystem access, known as Vfs or “virtual file system”. This appears to be the way the standard file access functions are supported, with the “rom” part of the filesystem hierarchy being supported by a “namespace filesystem” library that understands the way that the deployed payload modules are made available as files. To support other kinds of filesystem, other libraries must apparently be registered and made available to programs.
Although I am sure that the developers of the existing Vfs framework are highly competent, I found the mechanisms difficult to follow and quite unlike what I expected, which was to see a clear separation between programs accessing files and other programs providing those files. Indeed, this is what one sees when looking at other systems such as Minix 3 and its virtual filesystem. I must also admit that I became tired of having to dig into the code to understand the abstractions in order to supplement the reference documentation for the Vfs framework in L4Re.
An Alternative Framework
It might be too soon to label what I have done as a framework, but at the very least I needed to decide upon a few mechanisms to implement an alternative approach to providing file-like abstractions to programs within L4Re. There were a few essential characteristics to be incorporated:
- A way of requesting access to a named file
- The provision of objects maintaining the state of access to an opened file
- The transmission of file content to file readers and from file writers
- A way of cleaning up when programs are no longer accessing files
One characteristic that I did want to uphold in any solution was to make programs largely oblivious to the nature of the accessed filesystems. They would navigate a virtual filesystem hierarchy, just as one does in Unix-like systems, with certain directories acting as gateways to devices exposing potentially different filesystems with superficially similar semantics.
Requesting File Access
In a system like L4Re, with notions of clients and servers already prevalent, it seems natural to support a mechanism for requesting access to files that sees a client – a program wanting to access a file – delegating the task of locating that file to a server. How the server performs this task may be as simple or as complicated as we wish, depending on what kind of architecture we choose to support. In an operating system with a “monolithic” kernel, like GNU/Linux, we also see such delegation occurring, with the kernel being the entity having to support the necessary wiring up of filesystems contributing to the virtual filesystem.
So, it makes sense to support an “open” system call just like in other operating systems. The difference here, however, is that since L4Re is a microkernel-based environment, both the caller and the target of the call are mere programs, with the kernel only getting involved to route the call or message between the programs concerned. We would first need to make sure that the program accessing files has a reference (known as a “capability”) to another program that provides a filesystem and can respond to this “open” message. This wiring up of programs is a task for the system’s configuration file, as featured in some of my previous articles.
We may now consider what the filesystem-providing program or filesystem “server” needs to do when receiving an “open” message. Let us consider the failure to find the requested file: the filesystem server would, in such an event, probably just return a response indicating failure without any real need to do anything else. It is in the case of a successful lookup that the response to the caller or client needs some more consideration: the server could indicate success, but what is the client going to do with such information? And how should the server then facilitate further access to the file itself?
Providing Objects for File Access
It becomes gradually clearer that the filesystem server will need to allocate some resources for the client to conduct its activities, to hold information read from the filesystem itself and to hold data sent for writing back to the opened file. The server could manage this within a single abstraction and support a range of different operations, accommodating not only requests to open files but also operations on the opened files themselves. However, this might make the abstraction complicated and also raise issues around things like concurrency.
What if this server object ends up being so busy that while waiting for reading or writing operations to complete on a file for one program, it leaves other programs queuing up to ask about or gain access to other files? It all starts to sound like another kind of abstraction would be beneficial for access to specific files for specific clients. Consequently, we end up with an arrangement like this:

Accessing a filesystem and a resource
When a filesystem server receives an “open” message and locates a file, it allocates a separate object to act as a contact point for subsequent access to that file. This leaves the filesystem object free to service other requests, with these separate resource objects dealing with the needs of the programs wanting to read from and write to each individual file.
The underlying mechanisms by which a separate resource object is created and exposed are as follows:
- The instantiation of an object in the filesystem server program holding the details of the accessed file.
- The creation of a new thread of execution in which the object will run. This permits it to handle incoming messages concurrently with the filesystem object.
- The creation of an “IPC gate” for the thread. This effectively exposes the object to the wider environment as what often appears to be known as a “kernel object” (rather confusingly, but it simply means that the kernel is aware of it and has to do some housekeeping for it).
Once activated, the thread created for the resource is dedicated to listening for incoming messages and handling them, invoking methods on the resource object as a proxy for the client sending those messages to achieve the same effect.
Transmitting File Content
Although we have looked at how files manifest themselves and may be referenced, the matter of obtaining their contents has not been examined too closely so far. A program might be able to obtain a reference to a resource object and to send it messages and receive responses, but this is not likely to be sufficient for transferring content to and from the file. The reason for this is that the messages sent between programs – or processes, since this is how we usually call programs that are running – are deliberately limited in size.
Thus, another way of exchanging this data is needed. In a situation where we are reading from a file, what we would most likely want to see is a read operation populate some memory for us in our process. Indeed, in a system like GNU/Linux, I imagine that the Linux kernel shuttles the file data from the filesystem module responsible to an area of memory that it has reserved and exposed to the process. In a microkernel-based system, things have to be done more “collaboratively”.
The answer, it would seem to me, is to have dedicated memory that is shared between processes. Fortunately, and arguably unsurprisingly, L4Re provides an abstraction known as a “dataspace” that provides the foundation for such sharing. My approach, then, involves requesting a dataspace to act as a conduit for data, making the dataspace available to the file-accessing client and the file-providing server object, and then having a protocol to notify each other about data being sent in each direction.
I considered whether it would be most appropriate for the client to request the memory or whether the server should do so, eventually concluding that the client could decide how much space it would want as a buffer, handing this over to the server to use to whatever extent it could. A benefit of doing things this way is that the client may communicate initialisation details when it contacts the server, and so it becomes possible to transfer a filesystem path – the location of a file from the root of the filesystem hierarchy – without it being limited to the size of an interprocess message.
Opening a file using a path written to shared memory
So, the “open” message references the newly-created dataspace, and the filesystem server reads the path written to the dataspace’s memory so that it may use it to locate the requested file. The dataspace is not retained by the filesystem object but is instead passed to the resource object which will then share the memory with the application or client. As described above, a reference to the resource object is returned in the response to the “open” message.
It is worthwhile to consider the act of reading from a file exposed in this way. Although both client (the application in the above diagram) and server (resource object) should be able to access the shared “buffer”, it would not be a good idea to let them do so freely. Instead, their roles should be defined by the protocol employed for communication with one another. For a simple synchronous approach it would look like this:

Reading data from a resource via a shared buffer
Here, upon the application or client invoking the “read” operation (in other words, sending the “read” message) on the resource object, the resource is able to take control of the buffer, obtaining data from the file and writing it to the buffer memory. When it is done, its reply or response needs to indicate the updated state of the buffer so that the client will know how much data there is available, potentially amongst other things of interest.
Cleaning Up
Many of us will be familiar with the workflow of opening, reading and writing, and closing files. This final activity is essential not only for our own programs but also for the system, so that it does not tie up resources for activities that are no longer taking place. In the filesystem server, for the resource object, a “close” operation can be provided that causes the allocated memory to be freed and the resource object to be discarded.
However, merely providing a “close” operation does not guarantee that a program would use it, and we would not want a situation where a program exits or crashes without having invoked this operation, leaving the server holding resources that it cannot safely discard. We therefore need a way of cleaning up after a program regardless of whether it sees the need to do so itself.
In my earliest experiments with L4Re on the MIPS Creator CI20, I had previously encountered the use of interrupt request (IRQ) objects, in that case signalling hardware-initiated events such as the pressing of physical switches. But I also knew that the IRQ abstraction is employed more widely in L4Re to allow programs to participate in activities that would normally be the responsibility of the kernel in a monolithic architecture. It made me wonder whether there might be interrupts communicating the termination of a process that could then be used to clean up afterwards.
One area of interest is that concerning the “IPC gate” mentioned above. This provides the channel through which messages are delivered to a particular running program, and up to this point, we have considered how a resource object has its own IPC gate for the delivery of messages intended for it. But it also turns out that we can also enable notifications with regard to the status of the IPC gate via the same mechanism.
By creating an IRQ object and associating it with a thread as the “deletion IRQ”, when the kernel decides that the IPC gate is no longer needed, this IRQ will be delivered. And the kernel will make this decision when nothing in the system needs to use the IPC gate any more. Since the IPC gate was only created to service messages from a single client, it is precisely when that client terminates that the kernel will realise that the IPC gate has no other users.

Resource deletion upon the termination of a client
To enable this to actually work, however, a little trick is required: the server must indicate that it is ready to dispose of the IPC gate whenever necessary, doing so by decreasing the “reference count” which tracks how many things in the system are using the IPC gate. So this is what happens:
- The IPC gate is created for the resource thread, and its details are passed to the client, exposing the resource object.
- An IRQ object is bound to the thread and associated with the IPC gate deletion event.
- The server decreases its reference count, relinquishing the IPC gate and allowing its eventual destruction.
- The client and server communicate as desired.
- Upon the client terminating, the kernel disassociates the client from the IPC gate, decreasing the reference count.
- The kernel notices that the reference count is zero and sends an IRQ telling the server about the impending IPC gate deletion.
- The resource thread in the server deallocates the resource object and terminates.
- The IPC gate is deleted.
Using the “gate label”, the thread handling communications for the resource object is able to distinguish between the interrupt condition and normal messages from the client. Consequently, it is able to invoke the appropriate cleaning up routine, to discard the resource object, and to terminate the thread. Hopefully, with this approach, resource objects will no longer be hanging around long after their clients have disappeared.
Other Approaches
Another approach to providing file content did also occur to me, and I wondered whether this might have been a component of the “namespace filesystem” in L4Re. One technique for accessing files involves mapping the entire file into memory using a “mmap” function. This could be supported by requesting a dataspace of a suitable size, but only choosing to populate a region of it initially.
The file-accessing program would attempt to access the memory associated with the file, and upon straying outside the populated region, some kind of “fault” would occur. A filesystem server would have the job of handling this fault, fetching more data, allocating more memory pages, mapping them into the file’s memory area, and disposing of unwanted pages, potentially writing modified pages to the appropriate parts of the file.
In effect, the filesystem server would act as a pager, as far as I can tell, and I believe it to be the case that Moe – the root task – acts in such a way to provide the “rom” files from the deployed payload modules. Currently, I don’t find it particularly obvious from the documentation how I might implement a pager, and I imagine that if I choose to support such things, I will end up having to trawl the code for hints on how it might be done.
Client Library Functions
To present a relatively convenient interface to programs wanting to use files, some client library functions need to be provided. The intention with these is to support the traditional C library paradigms and for these functions to behave like those that C programmers are generally familiar with. This means performing interprocess communications using the “open”, “read”, “write”, “close” and other messages when necessary, hiding the act of sending such messages from the library user.
The details of such a client library are probably best left to another article. With some kind of mechanism in place for accessing files, it becomes a matter of experimentation to see what the demands of the different operations are, and how they may be tuned to reduce the need for interactions with server objects, hopefully allowing file-accessing programs to operate efficiently.
The next article on this topic is likely to consider the integration of libext2fs with this effort, along with the library functionality required to exercise and test it. And it will hopefully be able to report some real experiences of accessing ext2-resident files in relatively understandable programs.
Monday, 11 February 2019
FSFE Planet has been refurbished
If you are reading these lines, you are already accessing the brand-new planet of the FSFE. While Bjรถrn, Coordinator of Team Germany, has largely improved the design in late 2017, we tackled many underlying issues this time.
So what has changed under the hood?
- The whole system runs in a Docker container now, with all code accessible on our Git. Yes, Docker has drawbacks, but in this case it eases maintenance for our volunteers and makes contributions to design and code very simple.
- The old planet ran on a very old Debian server which had issues with modern TLS versions. This basically erased a few blogs from the planet whose webservers do not support older encryption standards.
- The design has been improved once more. It now more closely aligns to the design of our main page fsfe.org and feels more natively to use and browse.
- Many blogs which were not accessible any more have been removed, and those which redirected to other URLs have been updated accordingly.
So with the migration to the new system you will probably find a few new blogs and unread posts in your RSS feeds now. So please do not be confused about it but look forward to even more useful and interesting bits from the FSFE community!
On this occasion I would like to thank Michael and Vincent for their contributions to the code, and the useful feedback from various people in the FSFE’s community. If you have ideas how to further improve our planet, please open an issue in the Git repository or write an email to us.
Saturday, 09 February 2019
Java: String↔char[]
Do you recall when I decided to abuse Go’s run-time and play with string↔[]byte conversion? Fun times… I wonder if we could do the same to Java?
To remind ourselves of the ‘problem’, strings in Java are immutable but because Java has no concept of ownership or const keyword (can we move the industry to Rust already?) to make true on that promise, Java run-time has to make a defensive copy each time a new string is created or when string’s characters are returned.
Alas, do not despair! There is another way (exception handling elided for brevity):
private static Field getValueField() {
final Field field = String.class.getDeclaredField("value");
field.setAccessible(true);
/* Test that it works. */
final char[] chars = new char[]{'F', 'o', 'o'};
final String string = new String();
field.set(string, chars);
if (string.equals("Foo") && field.get(string) == chars) {
return field;
}
throw new UnsupportedOperationException(
"UnsafeString not supported by the run-time");
}
private final static Field valueField = getValueField();
public static String fromChars(final char[] chars) {
final String string = new String();
valueField.set(string, chars);
return string;
}
public static char[] toChars(final String string) {
return (char[]) valueField.get(string);
}However. There is a twist…
Benchmarks
Benchmarks shouldn’t surprise anyone:
| Argument length | UnsafeString::fromChars [ns] | String::new [ns] | |
|---|---|---|---|
| 0 | 13.92 | 4.97 | 0.37✕ |
| 1 | 13.98 | 8.07 | 0.58✕ |
| 3 | 14.07 | 8.07 | 0.57✕ |
| 4 | 14.06 | 8.09 | 0.58✕ |
| 10 | 14.15 | 9.25 | 0.65✕ |
| 33 | 14.23 | 12.54 | 0.88✕ |
| 100 | 14.12 | 29.68 | 2.10✕ |
| 10000 | 14.17 | 2937.98 | 207.33✕ |
| 1000000 | 14.04 | 319440.00 | 22754.73✕ |
| Argument length | UnsafeString::toChars [ns] | String::toCharArray [ns] | |
|---|---|---|---|
| 0 | 5.79 | 4.64 | 0.80✕ |
| 1 | 5.13 | 9.17 | 1.79✕ |
| 3 | 5.57 | 9.08 | 1.63✕ |
| 4 | 5.13 | 9.13 | 1.78✕ |
| 10 | 5.67 | 10.47 | 1.85✕ |
| 33 | 5.49 | 13.03 | 2.37✕ |
| 100 | 5.11 | 29.38 | 5.75✕ |
| 10000 | 5.12 | 2950.88 | 575.79✕ |
| 1000000 | 5.15 | 318074.00 | 61728.38✕ |
The unsafe variant takes roughly the same amount of time regardless of the size of the argument while safe variant scales linearly. Interestingly, because reflection is slow, safe call is faster for short strings.
The code including tests and benchmarks can be found in the java-unsafe-string repository.
If the benchmarks aren’t surprising, what’s up with the twist then?
Java 6
While we’re on the subject of messing with the Java’s String object it might be good to mention the above code won’t work in Java 6 and earlier versions.
Until Java 7u6, String::substring created objects which shared character array with the ‘parent’ string. This had some advantages – the operation was constant time and constant memory operation – but could lead to memory leaks (if the base string got garbage collected its entire contents would remain in memory even if the substring needed just a small portion of it) and complicated the String class (by requiring offset and length fields).
In the end, the implementation has been changed and strings now own the entire character array. Interestingly, the ‘trigger’ for the change was the introduction of (now removed) new hashing algorithm for strings. Whatever the case, the code presented here won’t work before Java 7u6.
But wait, this is still not the twist I’ve promised. ;)
Java 9
The above benchmarks were run on Java 8 and by now probably everyone and their dog knows that this particular version’s support has ended. Let’s jump to the next LTS version, Java 11:
$ javac com/mina86/unsafe/*.java &&
echo && java -version && echo &&
java com.mina86.unsafe.UnsafeStringBenchmark
openjdk version "11.0.2" 2019-01-15
OpenJDK Runtime Environment (build 11.0.2+9-Debian-3)
OpenJDK 64-Bit Server VM (build 11.0.2+9-Debian-3, mixed mode, sharing)
Testing safe implementation: ........................... done, all ok
+ safe::fromChars/0 : 1194602409 ops in 1731473175 ns: 1.44941 ns/op
+ safe::fromChars/1 : 204060009 ops in 1622419993 ns: 7.95070 ns/op
+ safe::fromChars/3 : 312337323 ops in 2857745803 ns: 9.14955 ns/op
+ safe::fromChars/4 : 124336092 ops in 2170864835 ns: 17.4597 ns/op
+ safe::fromChars/10 : 306122448 ops in 2816903678 ns: 9.20189 ns/op
+ safe::fromChars/33 : 172483182 ops in 1914933095 ns: 11.1021 ns/op
+ safe::fromChars/100 : 103099869 ops in 2107079434 ns: 20.4373 ns/op
+ safe::fromChars/10000 : 661688 ops in 1031572901 ns: 1559.00 ns/op
+ safe::fromChars/1000000: 4397 ops in 1002248806 ns: 227939 ns/op
+ safe::toChars/0 : 280731006 ops in 2171809870 ns: 7.73627 ns/op
+ safe::toChars/1 : 273448179 ops in 2172255240 ns: 7.94394 ns/op
+ safe::toChars/3 : 284117814 ops in 2760800696 ns: 9.71710 ns/op
+ safe::toChars/4 : 240143619 ops in 2666941237 ns: 11.1056 ns/op
+ safe::toChars/10 : 234594930 ops in 2264769324 ns: 9.65396 ns/op
+ safe::toChars/33 : 205747203 ops in 2952933911 ns: 14.3522 ns/op
+ safe::toChars/100 : 94298106 ops in 2873368834 ns: 30.4711 ns/op
+ safe::toChars/10000 : 357551 ops in 1046061057 ns: 2925.63 ns/op
+ safe::toChars/1000000: 9012 ops in 2813949290 ns: 312245 ns/opSo far so good. The times are a bit noisier though the creation of an empty string seemed to be optimised. Let’s see how unsafe version compares.
WARNING: An illegal reflective access operation has occurred WARNING: Illegal reflective access by com.mina86.unsafe.UnsafeStringImpl (file:/home/mpn/code/unsafe-str/) to field java.lang.String.value WARNING: Please consider reporting this to the maintainers of com.mina86.unsafe.UnsafeStringImpl WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations WARNING: All illegal access operations will be denied in a future release java.lang.IllegalArgumentException: Can not set final [B field java.lang.String.value to [C at java.base/jdk.internal.reflect.UnsafeFieldAccessorImpl.throwSetIllegalArgumentException(UnsafeFieldAccessorImpl.java:167) at java.base/jdk.internal.reflect.UnsafeFieldAccessorImpl.throwSetIllegalArgumentException(UnsafeFieldAccessorImpl.java:171) at java.base/jdk.internal.reflect.UnsafeQualifiedObjectFieldAccessorImpl.set(UnsafeQualifiedObjectFieldAccessorImpl.java:83) at java.base/java.lang.reflect.Field.set(Field.java:780) at com.mina86.unsafe.UnsafeStringImpl.makeUnsafeMaybe(UnsafeStringImpl.java:19) at com.mina86.unsafe.UnsafeStringBenchmark.main(UnsafeStringBenchmark.java:15) Testing unsafe implementation: unsupported by the run-time
How’s that for a twist? Uh? I overhyped the twist, you say? Well… Dumbledore dies!
On a serious note though, yes, starting with Java 9, Oracle started locking down internal APIs making some low-level optimisations no longer possible, so as you move from Java 8 remember to check any libraries which achieve high performance by messing around Java’s internals.
Thursday, 07 February 2019
Privacy-preserving monitoring of an anonymity network (FOSDEM 2019)

This is a transcript of a talk I gave at FOSDEM 2019 in the Monitoring and Observability devroom about the work of Tor Metrics.
Direct links:
Producing this transcript was more work than I had anticipated it would be, and I’ve done this in my free time, so if you find it useful then please do let me know otherwise I probably won’t be doing this again.

I’ll start off by letting you know who I am. Generally this is a different audience for me but I’m hoping that there are some things that we can share here. I work for Tor Project. I work in a team that is currently formed of two people on monitoring the health of the Tor network and performing privacy-preserving measurement of it. Before Tor, I worked on active Internet measurement in an academic environment but I’ve been volunteering with Tor Project since 2015. If you want to contact me afterwards, my email address, or if you want to follow me on the Fediverse there is my WebFinger ID.

So what is Tor? I guess most people have heard of Tor but maybe they don’t know so much about it. Tor is quite a few things, it’s a community of people. We have a paid staff of approximately 47, the number keeps going up but 47 last time I looked. We also have hundereds of volunteer developers that contribute code and we also have relay operators that help to run the Tor network, academics and a lot of people involved organising the community locally. We are registered in the US as a non-profit organisation and the two main things that really come out of Tor Project are the open source software that runs the Tor network and the network itself which is open for anyone to use.

Currently there are an estimated average 2,000,000 users per day. This is estimated and I’ll get to why we don’t have exact numbers.

Most people when they are using Tor will use Tor Browser. This is a bundle of Firefox and a Tor client set up in such a way that it is easy for users to use safely.

When you are using Tor Browser your traffic is proxied through three relays. With a VPN there is only one server in the middle and that server can see either side. It is knows who you are and where you are going so they can spy on you just as your ISP could before. The first step in setting up a Tor connection is that the client needs to know where all of those relays are so it downloads a list of all the relays from a directory server. We’re going to call that directory server Dave. Our user Alice talks to Dave to get a list of the relays that are available.

In the second step, the Tor client forms a circuit through the relays and connects finally to the website that Alice would like to talk to, in this case Bob.

If Alice later decides they want to talk to Jane, they will form a different path through the relays.

We know a lot about these relays. Because the relays need to be public knowledge for people to be able to use them, we can count them quite well. Over time we can see how many relays there are that are announcing themselves and we also have the bridges which are a seperate topic but these are special purpose relays.

Because we have to connect to the relays we know their IP addresses and we know if they have IPv4 or IPv6 addresses so as we want to get better IPv6 support in the Tor network we can track this and see how the network is evolving.

Because we have the IP addresses we can combine those IP addresses with GeoIP databases and that can tell us what country those relays are in with some degree of accuracy. Recently we have written up a blog post about monitoring the diversity of the Tor network. The Tor network is not very useful if all of the relays are in the same datacenter.

We also perform active measurement of these relays so we really analyse these relays because this is where we put a lot of the trust in the Tor network. It is distributed between multiple relays but if all of the relays are malicious then the network is not very useful. We make sure that we’re monitoring its diversity and the relays come in different sizes so we want to know are the big relays spread out or are there just a lot of small relays inflating the absolute counts of relays in a location.
When we look at these two graphs, we can see that the number of relays in Russia is about 250 at the moment but when we look at the top 5 by the actual bandwidth they contribute to the network they drop off and Sweden takes Russia’s place in the top 5 contributing around 4% of the capacity.

The Tor Metrics team, as I mentioned we are two people, and we care about measuring and analysing things in the Tor network. There are 3 or 4 repetitive contributors and then occasionally people will come along with patches or perform a one-off analysis of our data.

We use this data for lots of different use cases. One of which is detecting censorship so if websites are blocked in a country, people may turn to Tor in order to access those websites. In other cases, Tor itself might be censored and then we see a drop in Tor users and then we also see we a rise in the use of the special purpose bridge relays that can be used to circumvent censorship. We can interpret the data in that way.
We can detect attacks against the network. If we suddenly see a huge rise in the number of relays then we can suspect that OK maybe there is something malicious going on here and we can deal with that. We can evaluate effects on how performance changes when we make changes to the software. We have recently made changes to an internal scheduler and the idea there is to reduce congestion at relays and from our metrics we can say we have a good idea that this is working.
Probably one of the more important aspects is being able to take this data and make the case for a more private and secure Internet, not just from a position of I think we should do this, I think it’s the right thing, but here is data and here is facts that cannot be so easily disputed.

We only handle public non-sensitive data. Each analysis goes through a rigorous review and discussion process before publication.

As you might imagine the goals of privacy and anonymity network doesn’t lend itself to easy data gathering and extensive monitoring of the network. The Research Safety Board if you are interested in doing research on Tor or attempting to collect data through Tor can offer advice on how to do that safely. Often this is used by academics that want to study Tor but also the Metrics Team has used it on occasion where we want to get second opinions on deploying new measurements.

What we try and do is follow three key principles: data minimalisation, source aggregation, and transparency.

The first one of these is quite simple and I think with GDPR probably is something people need to think about more even if you don’t have an anonymity network. Having large amounts of data that you don’t have an active use for is a liability and something to be avoided. Given a dataset and given an infinite amount of time that dataset is going to get leaked. The probability increases as you go along. We want to make sure that we are collecting as little detail as possible to answer the questions that we have.

When we collect data we want to aggregate it as soon as we can to make sure that sensitive data exists for as little time as possible. This means usually in the Tor relays themselves before they even report information back to Tor Metrics. They will be aggregating data and then we will aggregate the aggregates. This can also include adding noise, binning values. All of these things can help to protect the individual.

And then being as transparent as possible about our processes so that our users are not surprised when they find out we are doing something, relay operators are not surprised, and academics have a chance to say whoa that’s not good maybe you should think about this.

The example that I’m going to talk about is counting unique users. Users of the Tor network would not expect that we are storing their IP address or anything like this. They come to Tor because they want the anonymity properties. So the easy way, the traditional web analytics, keep a list of the IP addresses and count up the uniques and then you have an idea of the unique users. You could do this and combine with a GeoIP database and get unique users per country and these things. We can’t do this.

So we measure indirectly and in 2010 we produced a technical report on a number of different ways we could do this.

It comes back to Alice talking to Dave. Because every client needs to have a complete view of the entire Tor network, we know that each client will fetch the directory approximately 10 times a day. By measuring how many directory fetches there are we can get an idea of the number of concurrent users there are of the Tor network.

Relays don’t store IP addresses at all, they count the number of directory requests and then those directory requests are reported to a central location. We don’t know how long an average session is so we can’t say we had so many unique users but we can say concurrently we had so many users on average. We get to see trends but we don’t get the exact number.

So here is what our graph looks like. At the moment we have the average 2,000,000 concurrent Tor users. The first peak may have been an attempted attack, as with the second peak. Often things happen and we don’t have full context for them but we can see when things are going wrong and we can also see when things are back to normal afterwards.

This is in a class of problems called the count-distinct problem and these are our methods from 2010 but since then there has been other work in this space.

One example is HyperLogLog. I’m not going to explain this in detail but I’m going to give a high-level overview. Imagine you have a bitfield and you initialise all of these bits to zero. You take an IP address, you take a hash of the IP address, and you look for the position of the leftmost one. How many zeros were there at the start of that string? Say it was 3, you set the third bit in your bitfield. At the end you have a series of ones and zeros and you can get from this to an estimate of the total number that there are.
Every time you set a bit there is 50% chance that that bit would be set given the number of distinct items. (And then 50% chance of that 50% for the second bit, and so on…) There is a very complicated proof in the paper that I don’t have time to go through here but this is one example that actually turns out to be quite accurate for counting unique things.
This was designed for very large datasets where you don’t have enough RAM to keep everything in memory. We have a variant on this problem where even keep 2 IP addresses in memory would, for us, be a very large dataset. We can use this to avoid storing even small datasets.


Private Set-Union Cardinality is another example. In this one you can look at distributed databases and find unique counts within those. Unfortunately this currently requires far too much RAM to actually do the computation for us to use this but over time these methods are evolving and should become feasible, hopefully soon.

And then moving on from just count-distinct, the aggregation of counters. We have counters such as how much bandwidth has been used in the Tor network. We want to aggregate these but we don’t want to release the individual relay counts. We are looking at using a method called PrivCount that allows us to get the aggregate total bandwidth used while keeping the individual relay bandwidth counters secret.

And then there are similar schemes to this, RAPPOR and PROCHLO from Google and Prio that Mozilla have written a blog post about are similar technologies. All of the links here in the slides and are in the page on the FOSDEM schedule so don’t worry about writing these down.

Finally, I’m looking at putting together some guidelines for performing safe measurement on the Internet. This is targetted primarily at academics but also if people wanted to apply this to analytics platforms or monitoring of anything that has users and you want to respect those users’ privacy then there could be some techniques in here that are applicable.
Ok. So that’s all I have if there are any questions?
Q: I have a question about how many users have to be honest so that the network stays secure and private, or relays?
A: At the moment when we are collecting statistics we can see – so as I showed earlier the active measurement – we know how much bandwidth a relay can cope with and then we do some load balancing so we have an idea of what fraction of traffic should go to each relay and if one relay is expecting a certain level of traffic and it has wildly different statistics to another relay then we can say that relay is cheating. There isn’t really any incentive to do this and it’s something we can detect quite easily but we are also working on more robust metrics going forward to avoid this being a point where it could be attacked.
Q: A few days ago I heard that with Tor Metrics you are between 2 and 8 million users but you don’t really know in detail what the real numbers are? Can you talk about the variance and which number is more accurate?
A: The 8 million number comes from the PrivCount paper and they did a small study where they looked at unique IP address over a day where we look at concurrent users. There are two different measurements. What we can say is that we know for certain that there are between 2 million and 25 million unique users per day but we’re not sure where in there we fall and 8 million is a reasonable-ish number but also they measured IP addresses and some countries use a lot of NAT so it could be more than 8 million. It’s tricky but we see the trends.
Q: Your presentation actually implies that you are able to collect more private data than you are doing. It says that the only thing preventing you from collecting private user data is the team’s good will and good intentions. Have I got it wrong? Are there any possibilities for the Tor Project team to collect some private user data?
A: Tor Project does not run the relays. We write the code but there individual relay operators that run the relays and if we were to release code that suddenly collecting lots of private data people would realise and they wouldn’t run that code. There is a step between the development and it being deployed. I think that it’s possible other people could write that code and then run those relays but if they started to run enough relays that it looked suspicious then people would ask questions there too, so there is a distributed trust model with the relays.
Q: You talk about privacy preserving monitoring, but also a couple of years ago we learned that the NSA was able to monitor relays and learn which user was connecting to relays so is there also research to make it so Tor users cannot be targetted for using a relay and never being able to be monitored.
A: Yes, there is! There is a lot of research in this area and one of them is through obfuscation techniques where you can make your traffic look like something else. They are called pluggable transports and they can make your traffic look like all sorts of things.
Wednesday, 06 February 2019
KDE Applications 19.04 Schedule finalized

It is available at the usual place https://community.kde.org/Schedules/Applications/19.04_Release_Schedule
Dependency freeze is March 14 and Feature Freeze a week after that, make sure you start finishing your stuff!
Tuesday, 05 February 2019
Using ext2 Filesystems with L4Re
Previously, I described my initial investigations into libext2fs and the development of programs to access and populate ext2/3/4 filesystems. With a program written and now successfully using libext2fs in my normal GNU/Linux environment, the next step appeared to be the task of getting this library to work within the L4Re system. The following steps were envisaged:
- Figuring out the code that would be needed, this hopefully being supportable within L4Re.
- Introducing the software as a package within L4Re.
- Discovering the configuration required to build the code for L4Re.
- Actually generating a library file.
- Testing the library with a program.
This process is not properly completed in that I do not yet have a good way of integrating with the L4Re configuration and using its details to configure the libext2fs code. I felt somewhat lazy with regard to reconciling the use of autotools with the rather different approach taken to build L4Re, which is somewhat reminiscent of things like Buildroot and OpenWrt in certain respects.
So, instead, I built the Debian package from source in my normal environment, grabbed the config.h file that was produced, and proceeded to use it with a vastly simplified Makefile arrangement, also in my normal environment, until I was comfortable with building the library. Indeed, this exercise of simplified building also let me consider which portions of the libext2fs distribution would really be needed for my purposes. I did not really fancy having to struggle to build files that would ultimately be superfluous.
Still, as I noted, this work isn’t finished. However, it is useful to document what I have done so far so that I can subsequently describe other, more definitive, work.
Making a Package
With a library that seemed to work with the archiving program, written to populate filesystems for eventual deployment, I then set about formulating this simplified library distribution as a package within L4Re. This involves a few things:
- Structuring the files so that the build system may process them.
- Persuading the build system to install things in places for other packages to find.
- Formulating the appropriate definitions to build the source files (and thus producing the right compiler and linker invocations).
The Package Structure
Currently, I have the following arrangement inside the pkg/libext2fs directory:
include include/libblkid include/libe2p include/libet include/libext2fs include/libsupport include/libuuid lib lib/libblkid lib/libe2p lib/libet lib/libext2fs lib/libsupport lib/libuuid
To follow L4Re conventions, public header files have been moved into the include hierarchy. This breaks assumptions in the code, with header files being referenced without a prefix (like “ext2fs”, “et”, “e2p”, and so on) in some places, but being referenced with such a prefix in others. The original build system for the code gets away with this by using the “ext2fs” and other prefixes as the directory names containing the code for the different libraries. It then indicates the parent “lib” directory of these directories as the place to start looking for headers.
But I thought it worthwhile to try and map out the header usage and distinguish between public and private headers. At the very least, it helps me to establish the relationships between the different components involved. And I may end up splitting the different components into their own packages, requiring some formalisation of their interactions.
Meanwhile, I defined a Control file to indicate what the package provides:
provides: libblkid libe2p libet libext2fs libsupport libuuid
This appears to be used in dependency resolution, causing the package to be built if another package requires one of the named entities in its own Control file.
Header File Locations
In each include subdirectory (such as include/libext2fs) is a Makefile indicating a couple of things, the following being used for libext2fs:
PKGNAME = libext2fs CONTRIB_HEADERS = 1
The effect of this is to install the headers into a include/contrib/libext2fs directory in the build output.
In the corresponding lib subdirectory (which is lib/libext2fs), the following seems to be needed:
CONTRIB_INCDIR = libext2fs
Hopefully, with this, other packages can depend on libext2fs and have the headers made available to it by an include statement like this:
#include <ext2fs/ext2fs.h>
(The ext2fs prefix is provided by a directory inside include/libext2fs.)
Otherwise, headers may end up being put in a special “l4″ hierarchy, and then code would need changing to look something like this:
#include <l4/ext2fs/ext2fs.h>
So, avoiding this and having the original naming seems to be the benefit of the “contrib” settings, as far as I can tell.
Defining Build Files
The Makefile in each specific lib subdirectory employs the usual L4Re build system definitions:
TARGET = libext2fs.a libext2fs.so PC_FILENAME = libext2fs
The latter of these is used to identify the build products so that the appropriate compiler and linker options can be retrieved by the build system when this library is required by another. Here, PC is short for “package config” but the notion of “package” is different from that otherwise used in this article: it just refers to the specific library being built in this case.
An important aspect related to “package config” involves the requirements or dependencies of this library. These are specified as follows for libext2fs:
REQUIRES_LIBS = libet libe2p
We saw these things in the Control file. By indicating these other libraries, the compiler and linker options to find and use these other libraries will be brought in when something else requires libext2fs. This should help to prevent build failures caused by missing headers or libraries, and it should also permit more concise declarations of requirements by allowing those declarations to omit libet and libe2p in this case.
Meanwhile, the actual source files are listed using a SRC_C definition, and the PRIVATE_INCDIR definition lists the different paths to be used to search for header files within this package. Moving the header files around complicates this latter definition substantially.
There are other complications with libext2fs, notably the building of a tool that generates a file to be used when building the library itself. I will try and return to this matter at some point and figure out a way of doing this within the build system. Such generation of binaries for use in build processes can be problematic, particularly if there is some kind of assumption that the build system is the same as the target system, but such assumptions are probably not being made here.
Building the Library
Fortunately, the build system mostly takes care of everything else, and a command like this should see the package being built and libraries produced:
make O=mybuild S=pkg/libext2fs
The “S” option is a real time saver, and I wish I had made more use of it before. Use of the “V” option can be helpful in debugging command options, since the normal output is abridged:
make O=mybuild S=pkg/libext2fs V=1
I will admit that since certain header files are not provided by L4Re, a degree of editing of the config.h file was required. Things like HAVE_LINUX_FD_H, indicating the availability of Linux-specific headers, needed to be removed.
Testing the Library
An appropriate program for testing the library is really not much different from one used in a GNU/Linux environment. Indeed, I just took some code from my existing program that lists a directory inside a filesystem image. Since L4Re should provide enough of a POSIX-like environment to support such unambitious programs, practically no changes were needed and no special header files were included.
A suitable Makefile is needed, of course, but the examples package in L4Re provides plenty of guidance. The most important part is this, however:
REQUIRES_LIBS = libext2fs
A Control file requiring libext2fs is actually not necessary for an example in the examples hierarchy, it would seem, but such a file would otherwise be advisible. The above library requirements pull in the necessary compiler and linker flags from the “package config” universe. (It also means that the libext2fs headers are augmented by the libe2p and libet headers, as defined in the required libraries for libext2fs itself.)
As always, deploying requires a suitable configuration description and a list of modules to be deployed. The former looks like this:
local L4 = require("L4");
local l = L4.default_loader;
l:startv({
log = { "ext2fstest", "g" },
},
"rom/ex_ext2fstest", "rom/ext2fstest.fs", "/");
The interesting part is right at the end: a program called ex_ext2fstest is run with two arguments: the name of a file containing a filesystem image, and the directory inside that image that we want the program to show us. Here, we will be using the built-in “rom” filesystem in L4Re to serve up the data that we will be decoding with libext2fs in the program. In effect, we use one filesystem to bootstrap access to another!
Since the “rom” filesystem is merely a way of exposing modules as files, the filesystem image therefore needs to be made available as a module in the module list provided in the conf/modules.list file, the appropriate section starting off like this:
entry ext2fstest roottask moe rom/ext2fstest.cfg module ext2fstest.cfg module ext2fstest.fs module l4re module ned module ex_ext2fstest # plus lots of library modules
All these experiments are being conducted with L4Re running on the UX configuration of Fiasco.OC, meaning that the system runs on top of GNU/Linux: a sort of “user mode L4″. Running the set of modules for the above test is a matter of running something like this:
make O=mybuild ux E=ext2fstest
This produces a lot of output and then some “logged” output for the test program:
ext2fste| Opened rom/ext2fstest.fs. ext2fste| / ext2fste| drwxr-xr-x- 0 0 1024 . ext2fste| drwxr-xr-x- 0 0 1024 .. ext2fste| drwx------- 0 0 12288 lost+found ext2fste| -rw-r--r--- 1000 1000 11449 e2access.c ext2fste| -rw-r--r--- 1000 1000 1768 file.c ext2fste| -rw-r--r--- 1000 1000 1221 format.c ext2fste| -rw-r--r--- 1000 1000 6504 image.c ext2fste| -rw-r--r--- 1000 1000 1510 path.c
It really isn’t much to look at, but this indicates that we have managed to access an ext2 filesystem within L4Re using a program that calls the libext2fs library functions. If nothing else, the possibility of porting a library to L4Re and using it has been demonstrated.
But we want to do more than that, of course. The next step is to provide access to an ext2 filesystem via a general interface that hides the specific nature of the filesystem, one that separates the work into a different program from those wanting to access files. To do so involves integrating this effort into my existing filesystem framework, then attempting to re-use a generic file-accessing program to obtain its data from ext2-resident files. Such activities will probably form the basis of the next article on this topic.
Sunday, 03 February 2019
Calculating sRGB↔XYZ matrix
I’ve recently found myself in need of an sRGB↔XYZ transformation matrix expressed to the maximum possible precision. Sources on the Internet typically limit the precision to just a few decimal places so I've decided to do the calculations by myself.
What we’re looking for is a 3-by-3 matrix \(M\) which, when multiplied by red, green and blue coördinates of a colour, produces its XYZ coördinates. In other words, a change of basis matrix from a space whose basis vectors are sRGB’s primary colours: $$ M = \begin{bmatrix} X_r & X_g & Y_b \\ Y_r & Y_g & Y_b \\ Z_r & Z_g & Z_b \end{bmatrix} $$
Derivation
sRGB primary colours are defined in IEC 61966 standard (and also Rec. 709 document which is 170 francs cheaper) as a pair of x and y values (i.e. chromaticity coördinates). Converting them to XYZ space is simple: \(X = x Y / y\) and \(Z = (1 - x - y) Y / y,\) but leaves luminocity (the Y value) undefined.
| \(\langle x, y\rangle\) | \(\langle X, Y, Z\rangle\) | |
|---|---|---|
| Red | \(\langle 0.64, 0.33\rangle\) | \(\langle 64 Y_r / 33, \; Y_r, \; Y_r / 11\rangle\) |
| Green | \(\langle 0.30, 0.60\rangle\) | \(\langle Y_g / 2, \; Y_g, \; Y_g / 6\rangle\) |
| Blue | \(\langle 0.15, 0.06\rangle\) | \(\langle 5 Y_b / 2, \; Y_b, \; 79 Y_b / 6\rangle\) |
| White (D65) | \(\langle 0.31271, 0.32902\rangle\) | \(\langle 31271 Y_w / 32902, \; Y_w, \; 35827 Y_w / 32902\rangle\) |
That’s where reference white point comes into play. Its coördinates in linear RGB space, \(\langle 1, 1, 1 \rangle,\) can be plugged into the change of basis formula to yield the following equation: $$ \begin{bmatrix} X_w \\ Y_w \\ Z_w \end{bmatrix} = \begin{bmatrix} X_r & X_g & X_b \\ Y_r & Y_g & Y_b \\ Z_r & Z_g & Z_b \end{bmatrix} \begin{bmatrix} 1 \\ 1 \\ 1 \end{bmatrix} $$
For each colour \(c\) (including white), \(X_c\) and \(Z_c\) can be expressed as a product of a known quantity and \(Y_c\) (see table above). Furthermore, by definition of a white point, \(Y_w = 1.\) At this point luminocities of the primary colours are the only unknowns. To isolate them, let’s define \(X'_c = X_c / Y_c\) and \(Z'_c = Z_c / Y_c\) and see where that leads us: $$ \begin{align} \begin{bmatrix} X_w \\ Y_w \\ Z_w \end{bmatrix} &= \begin{bmatrix} X_r & X_g & X_b \\ Y_r & Y_g & Y_b \\ Z_r & Z_g & Z_b \end{bmatrix} \begin{bmatrix} 1 \\ 1 \\ 1 \end{bmatrix} \\ &= \begin{bmatrix} X'_r Y_r & X'_g Y_g & X'_b Y_b \\ Y_r & Y_g & Y_b \\ Z'_r Y_r & Z'_g Y_g & Z'_b Y_b \end{bmatrix} \begin{bmatrix} 1 \\ 1 \\ 1 \end{bmatrix} \\ &= \begin{bmatrix} X'_r & X'_g & X'_b \\ 1 & 1 & 1 \\ Z'_r & Z'_g & Z'_b \end{bmatrix} \begin{bmatrix} Y_r & 0 & 0 \\ 0 & Y_g & 0 \\ 0 & 0 & Y_b \end{bmatrix} \begin{bmatrix} 1 \\ 1 \\ 1 \end{bmatrix} \\ &= \begin{bmatrix} X'_r & X'_g & X'_b \\ 1 & 1 & 1 \\ Z'_r & Z'_g & Z'_b \end{bmatrix} \begin{bmatrix} Y_r \\ Y_g \\ Y_b \end{bmatrix} \\ \\ \begin{bmatrix} Y_r \\ Y_g \\ Y_b \end{bmatrix} &= \begin{bmatrix} X'_r & X'_g & X'_b \\ 1 & 1 & 1 \\ Z'_r & Z'_g & Z'_b \end{bmatrix}^{-1} \begin{bmatrix} X_w \\ Y_w \\ Z_w \end{bmatrix} \end{align} $$
All quantities on the right-hand side are known therefore \([Y_r Y_g Y_b]^T\) can be computed. Let’s tidy things up into a final formula.
Final formula
Given chromaticity of primary colours of an RGB space (\(\langle x_r, y_r \rangle,\) \(\langle x_g, y_g \rangle\) and \(\langle x_b, y_b \rangle\)) and its reference white point (\(\langle x_w, y_w \rangle\)), the matrix for converting linear RGB coördinates to XYZ is: $$ M = \begin{bmatrix} X'_r Y_r & X'_g Y_g & X'_b Y_b \\ Y_r & Y_g & Y_b \\ Z'_r Y_r & Z'_g Y_g & Z'_b Y_b \end{bmatrix} $$
which can also be written as \(M = M' \times \mathrm{diag}(Y_r, Y_g, Y_b)\) where: $$\begin{align} & M' = \begin{bmatrix} X'_r & X'_g & X'_b \\ 1 & 1 & 1 \\ Z'_r & Z'_g & Z'_b \end{bmatrix}\!\!, \\ \\ & \left. \begin{array}{l} X'_c = x_c / y_c \\ Z'_c = (1 - x_c - y_c) / y_c \end{array} \right\} \textrm{ for each colour } c, \\ \\ & \begin{bmatrix} Y_r \\ Y_g \\ Y_b \end{bmatrix} = M'^{-1} \begin{bmatrix} X_w \\ Y_w \\ Z_w \end{bmatrix} \textrm{ and} \\ \\ & \begin{bmatrix} X_w \\ Y_w \\ Z_w \end{bmatrix} = \begin{bmatrix} x_w / y_w \\ 1 \\ (1 - x_w - y_w) / y_w \end{bmatrix}\!\!. \end{align} $$
Matrix converting coördinates in the opposite direction is the inverse of \(M,\) i.e. \(M^{-1}\).
Implementation
Having theoretical part covered, it’s time to put the equations into practice, which brings up a question of language to use. With unlimited-precision integers and rational numbers arithmetic already implementation, Python is particularly good choice as it will allow all calculations to be done without rounding. Implementation begins with an overview of the algorithm:
Chromaticity = collections.namedtuple('Chromaticity', 'x y')
def calculate_rgb_matrix(primaries, white):
M_prime = (tuple(c.x / c.y for c in primaries),
tuple(1 for _ in primaries),
tuple((1 - c.x - c.y) / c.y for c in primaries))
W = (white.x / white.y, 1, (1 - white.x - white.y) / white.y)
Y = mul_matrix_by_column(inverse_3x3_matrix(M_prime), W)
return mul_matrix_by_diag(M_prime, Y)The function first constructs \(M'\) matrix and \(W = [X_w Y_w Z_w]^T\) column which are used to calculate \([Y_r Y_g Y_b]^T\) using \(M'^{-1} W\) formula. With that computed, the function returns \(M' \times \mathrm{diag}(Y_r, Y_g, Y_b)\) which is the transform matrix.
All operations on matrices are delegated to separate functions. Since the matrices the code deals with are small there is no need to optimise any of the algorithms and instead the most straightforward matrix multiplication algorithms are chosen:
def mul_matrix_by_column(matrix, column):
return tuple(
sum(row[i] * column[i] for i in range(len(row)))
for row in matrix)
def mul_matrix_by_diag(matrix, column):
return tuple(
tuple(row[c] * column[c] for c in range(len(column)))
for row in matrix)Only the function inverting a 3-by-3 matrix is somewhat more complex:
def inverse_3x3_matrix(matrix):
def cofactor(row, col):
minor = [matrix[r][c]
for r in (0, 1, 2) if r != row
for c in (0, 1, 2) if c != col]
a, b, c, d = minor
det_minor = a * d - b * c
return det_minor if (row ^ col) & 1 == 0 else -det_minor
comatrix = tuple(
tuple(cofactor(row, col) for col in (0, 1, 2))
for row in (0, 1, 2))
det = sum(matrix[0][col] * comatrix[0][col] for col in (0, 1, 2))
return tuple(
tuple(comatrix[col][row] / det for col in (0, 1, 2))
for row in (0, 1, 2))It first constructs matrix of cofactors of the input (i.e. comatrix). Because function’s argument is always a 3-by-3 matrix, each minor’s determinant can be trivially calculated using \(\bigl|\begin{smallmatrix} a & b \\ c & d \end{smallmatrix}\bigr| = a d - b c\) formula. Once the comatrix is constructed, calculating determinant of the input matrix and its inverse becomes just a matter of executing a few loops.
The above code works for any RGB system. To get result for sRGB its sRGB’s primaries and white point chromaticities need to me passed:
def calculate_srgb_matrix():
primaries = (Chromaticity(fractions.Fraction(64, 100),
fractions.Fraction(33, 100)),
Chromaticity(fractions.Fraction(30, 100),
fractions.Fraction(60, 100)),
Chromaticity(fractions.Fraction(15, 100),
fractions.Fraction( 6, 100)))
white = Chromaticity(fractions.Fraction(31271, 100000),
fractions.Fraction(32902, 100000))
return calculate_rgb_matrix(primaries, white)Full implementation with other bells and whistles can be found inside of ansi_colours repository.
Saturday, 02 February 2019
Brussels Day 1 and 2
Day one and two of my stay in Brussels are over. I really enjoyed the discussions I had at the XMPP Standards Foundation Summit which was held in the impressive Cisco office building in Diegem. It’s always nice to meet all the faces behind those ominous nicknames that you only interact with through text chats for the rest of the year. Getting to know them personally is always exciting.
A lot of work has been done to improve the XMPP ecosystem and the protocols that make up its skeleton. For me it was the first time ever to hold a presentation in English, which – in the end – did not turn out as bad as I expected – I guess 
I love how highly internationally the XSF Summit and FOSDEM events are. As people from over the world we get together and even though we are working on different projects and systems, we all have very similar goals. It’s refreshing to see a different mind set and hear some different positions and arguments.
I’ve got the feeling that this post is turning into some sort of humanitarian advertisement and sleep is a scarce commodity, so I’m going to bed now to get a snatch.
Tuesday, 29 January 2019
Filesystem Familiarisation
I previously noted that accessing filesystems would be a component in my work with microkernel-based systems, and towards the end of last year I began an exercise in developing a simple “toy” filesystem that could hold file-like entities. Combining this with some L4Re-based components that implement seemingly reasonable mechanisms for providing access to files, I was able to write simple test programs that open and access these files.
The starting point for all this was the observation that a normal system file – that is, something stored in the filesystem in my GNU/Linux environment – can be treated like an archive containing multiple files and therefore be regarded as providing a filesystem itself. Such a file can then be embedded in a payload providing a L4Re system by specifying it as a “module” in conf/modules.list for a particular payload entry:
module image_root.fs
Since L4Re provides a rudimentary “rom” filesystem that exposes the modules embedded in the payload, I could open this “toy” filesystem module as a file within L4Re using the normal file access functions.
fp = fopen("rom/image_root.fs", "r");
And with that, I could then use my own functions to access the files stored within. Some additional effort went into exposing file access via interprocess communication, which forms the basis of those mechanisms mentioned above, those mechanisms being needed if such filesystems are to be generally usable in the broader environment rather than by just a single program.
Preparing Filesystems
The first step in any such work is surely to devise how a filesystem is to be represented. Then, code must be written to access the filesystem, firstly to write files and directories to it, and then to be able to perform the necessary task of reading that file and directory information back out. At some point, an actual filesystem image needs to be prepared, and here it helps a lot if a convenient tool can be developed to speed up testing and further development.
I won’t dwell on the “toy” representation I used, mostly because it was merely chosen to let me explore the mechanisms and interfaces to be provided as L4Re components. The intention was always to switch to a “real world” filesystem and to use that instead. But in order to avoid being overwhelmed with learning about existing filesystems alongside learning about L4Re and developing file access mechanisms, I chose some very simple representations that I thought might resemble “real world” filesystems sufficiently enough to make the exercise realistic.
With the basic proof of concept somewhat validated, my attentions have now turned to “real world” filesystems, and here some interesting observations can be made about tools and libraries. If you were to ask someone about how they might prepare a filesystem, particularly a GNU/Linux user, it would be unsurprising to me if they suggested preparing a file…
dd if=/dev/zero of=image_root.fs bs=1024 count=1 seek=$SIZE_IN_KB
…then a filesystem in the file…
/sbin/mkfs.ext2 image_root.fs
…and then mounting it as follows:
sudo mount image_root.fs $MOUNTPOINT
Here, an ext2 filesystem is prepared in a normal system file, and then the operating system is asked to mount the filesystem and to expose it via a mountpoint, this being a directory in the general hierarchy of files and filesystems. But this last step requires special privileges and for the kernel to get involved, and yet all we are doing is accessing a file with the data inside it stored in a particular way. So why is there not a more straightforward, unprivileged way of writing data to that file in the required format?
Indeed, other projects of mine have needed to initialise filesystems, and such mounting operations have been a necessary aspect of those, given the apparent shortage of other methods. It really seemed that filesystems and kernel mechanisms were bound to each other, requiring us to always get the kernel involved. But it turns out that there are other solutions.
A History Lesson
I am reminded of the mtools suite of programs for accessing floppy disks. Once upon a time, when I was in my first year of university studies, practically all of our class’s programming was performed on a collection of DECstations. Although networked, each of these also provided a floppy drive capable of supporting 2.88MB disks: an uncommon sight, for me at least, with the availability of media and compatibility concerns dictating the use of 720KB and 1.44MB disks instead.
Presumably, within the Ultrix environment we were using, normal users were granted access to the floppy drive when logged in. With a disk inserted, mtools could then be used to access the disk as one big file, interpreting the contents and presenting the user with a view onto files and directories. Of course, mtools exposes a DOS-like interface to the disk, with DOS-like commands providing DOS-like output, and it does not attempt to integrate the contents of a disk within the general Unix filesystem hierarchy.
Indeed, the mechanisms of integrating such foreign data into the general filesystem hierarchy are denied to mere programs, this being a motivation for pursuing alternative operating system architectures like GNU Hurd which support such integration. But the point here is that filesystems – in this example, DOS-based filesystems on floppy disks – can readily be interpreted with the appropriate tools and without “operator” privileges.
Decoding Filesystem Data
Since filesystems are really just data structures encoded in storage, there should really be no magic involved in decoding and accessing them. After all, the code in the Linux kernel and in other operating system kernels has to do just that, and these things are just programs that happen to run under certain special conditions. So it would make sense if some of the knowledge encoded in these kernels had been extracted and made available as library code for other purposes. After all, it might come in useful elsewhere.
Fortunately, it is likely that such library code is already installed on your system, at least if you are using the ext2 family of filesystems. A search for some common utilities can be informative in this respect. Here is a query being issued for the appropriate filesystem checking utility on a Debian system:
$ dpkg -S e2fsck e2fsprogs: /usr/share/man/man5/e2fsck.conf.5.gz e2fsprogs: /sbin/e2fsck e2fsprogs: /usr/share/man/man8/e2fsck.8.gz
And for the filesystem initialisation utility mentioned above:
$ dpkg -S mkfs.ext2 e2fsprogs: /sbin/mkfs.ext2 e2fsprogs: /usr/share/man/man8/mkfs.ext2.8.gz
The e2fsprogs package itself depends on a package called libext2fs2 – or e2fslibs on earlier distribution versions – and ultimately one discovers that these tools and their libraries are provided by a software distribution, e2fsprogs, whose aim is to provide programs and libraries for general access to the ext2/3/4 filesystem format. So it turns out to be possible and indeed feasible to write programs accessing filesystems without needing to make use of code residing in some kernel or other.
Tooling Up
Had I bothered to investigate further, I might have discovered another useful package. Running one or both of the following commands on a Debian system lets us see which other packages make use of the library functionality of e2fsprogs:
apt-cache rdepends e2fslibs apt-cache rdepends libext2fs2
Amongst those listed is e2tools which offers a suite of commands resembling those provided by mtools, albeit with a Unix flavour instead of a DOS flavour. Investigating this, I discovered that these tools inherit somewhat from the utilities provided by e2fsprogs, particularly the debugfs utility.
However, investigating e2fsprogs by myself gave me a chance to become familiar with the details of libext2fs and how the different utilities managed to use it. Since it is not always obvious to me how the library should be used, and I find myself missing some good documentation for it, the more program code I can find to demonstrate its use, the better.
For my purposes, accessing individual files and directories is not particularly interesting: I really just want to treat an ext2 filesystem like an archive when preparing my L4Re payload; it is only within L4Re that I actually want to access individual things. Outside L4Re, having an equivalent to the tar command, but with the output being a filesystem image instead of a tar file, would be most useful for me. For example:
e2archive --create image_root.fs $ROOTFS
Currently, this can be made to populate a filesystem for eventual deployment, although the breadth of support for the filesystem features is rather limited. It is possible that I might adopt e2tools as the basis of this archiving program, given that it is merely a shell script that calls another program. Then again, it might be useful to gain direct experience with libext2fs for my other activities.
Future Directions
And so, in the GNU/Linux environment, the creation of such archives has been the focus of my experiments. Meanwhile, I need to develop library functions to support filesystem operations within L4Re, which means writing code to support things like file descriptor abstractions and the appropriate functions for accessing and manipulating files and directories. The basics of some of this is already done for the “toy” filesystem, but it will be a matter of figuring out which libext2fs functions and abstractions need to be used to achieve the same thing for ext2 and its derivatives.
Hopefully, once I can demonstrate file access via the same interprocess communications mechanisms, I can then make a start in replacing the existing conventional file access functions with versions that use my mechanisms instead of those provided in L4Re. This will most likely involve work on the C library support in L4Re, which is a daunting prospect, but some familiarity with that is probably beneficial if a more ambitious project to replace the C library is to be undertaken.
But if I can just manage to get the dynamic linker to be able to read shared libraries from an ext2 filesystem, then a rather satisfying milestone will have been reached. And this will then motivate work to support storage devices on various hardware platforms of interest, permitting the hosting of filesystems and giving those systems some potential as L4Re-based general-purpose computing devices, too.
Monday, 28 January 2019
WordPress Anti Spam Measures using Fail2ban
I recently got really excited when I noticed, that the number of page views on my blog suddenly sky-rocketed from around 70 to over 300! What brought me back down to earth was the fact, that I also received around 120 spam comments on that single day. Luckily all of those were reliably caught by Antispam Bee.

Still, it would be nice to have accurate statistics about page views and those stupid spam requests distort the number of views. Also I’d like to fight spam with tooth and nail, so simply filtering out the comments is not enough for me.
That’s why I did some research and found out about the plugin WP Fail2Ban Redux, which allows logging of spammed comments for integration with the famous fail2ban tool. The plugin does not come with a settings page, so any settings and options have to be defined in the wp-config.php. In my case it was sufficient to just add the following setting:
/path/to/wordpress/wp-config.php
define('ANTISPAM_BEE_LOG_FILE', '/var/log/spam.log');
Now, whenever Antispam Bee classifies a comment as spam, the IP of the author is logged in the given log file.
Now all I need it to configure fail2ban to read host names from that file and to swing that ban hammer!
/etc/fail2ban/filter.d/antispambee.conf
[INCLUDES]
# Read common prefixes. If any customizations available -- read them from
# common.local
before = common.conf
[Definition]
_daemon = wp
failregex = ^%(__prefix_line)s comment for post.* from host= marked as spam$
/etc/fail2ban/jail.local
[antispambee]
enabled = true
filter = antispambee
logpath = /var/log/spam.log
bantime = 21600
maxretry = 1
port = http,https
Now whenever a spammer leaves a “comment” on my blog, its IP is written in the spam.log file where it is picked up by fail2ban, which results in a 6 hour ban for that IP.

Update:

Tuesday, 22 January 2019
Some Ideas for 2019
Well, after my last article moaning about having wishes and goals while ignoring the preconditions for, and contributing factors in, the realisation of such wishes and goals, I thought I might as well be constructive and post some ideas I could imagine working on this year. It would be a bonus to get paid to work on such things, but I don’t hold out too much hope in that regard.
In a way, this is to make up for not writing an article summarising what I managed to look at in 2018. But then again, it can be a bit wearing to have to read through people’s catalogues of work even if I do try and make my own more approachable and not just list tons of work items, which is what one tends to see on a monthly basis in other channels.
In any case, 2018 saw a fair amount of personal focus on the L4Re ecosystem, as one can tell from looking at my article history. Having dabbled with L4Re and Fiasco.OC a bit in 2017 with the MIPS Creator CI20, I finally confronted certain aspects of the software and got it working on various devices, which had been something of an ambition for at least a couple of years. I also got back into looking at PIC32 hardware and software experiments, tidying up and building on earlier work, and I keep nudging along my Python-like language and toolchain, Lichen.
Anyway, here are a few ideas I have been having for supporting a general strategy of building flexible, sustainable and secure computing environments that respect the end-user. Such respect not being limited to software freedom, but also extending to things like privacy, affordability and longevity that are often disregarded in the narrow focus on only one set of end-user rights.
Building a General-Purpose System with L4Re
Apart from writing unfinished articles about supporting hardware devices on the Ben NanoNote and Letux 400, I also spent some time last year considering the mechanisms supporting filesystems in L4Re. For an outsider like myself, the picture isn’t particularly clear, but the mechanisms don’t really seem particularly well documented, and I am not convinced that the filesystem support is what people might expect from a microkernel-based system.
Like L4Re’s device support, the way filesystems are made available to tasks appears to use libraries extensively, whereas I would expect more use of individual programs, with interprocess messages and shared memory being employed to move the data around. To evaluate my expectations, I have been writing programs that operate in such a way, employing a “toy” filesystem to test the viability of such an approach. The plan is to make use of libext2fs to expose ext2/3/4 filesystems to L4Re components, then to try and replace the existing file access mechanisms with ones that access these file-serving components.
It is unfortunate that systems like these no longer seem to get much attention from the wider Free Software community. There was once a project to port GNU Hurd to L4-family microkernels, but with the state of the art having seemingly been regarded as insufficient or inappropriate, the focus drifted off onto other things, and now there doesn’t seem to be much appetite to resume such work. Even the existing Hurd implementation doesn’t get that much interest these days, either. And yet there are plenty of technical, social and practical reasons for not just settling for using the Linux kernel and systems based on it for every last application and device.
Extending Hardware Support within L4Re
It is all very well developing filesystem support, but there also has to be support for the things that provide the storage on which those filesystems reside. This is something I didn’t bother to look at when getting L4Re working on various devices because the priority was to have something to show, meaning that the display had to work, along with testing and demonstrating other well-understood peripherals, with the keyboard or keypad being something that could be supported with relative ease and then used to demonstrate other aspects of the solution.
It seems perverse that one must implement support for SD or microSD card storage all over again when the software being run is already being loaded from such storage, but this is rather like the way that “live CD” versions of GNU/Linux would load an environment directly from a CD, yet an installed version of such an environment might not have the capability to access the CD drive. Still, this is an unavoidable step along the path to make a practical system.
It might also be nice to make the CI20 support a bit better. Although a device notionally supported by L4Re, various missing pieces of hardware support needed to be added, and the HDMI output capability remains unavailable. Here, the mystery hardware left undocumented by the datasheet happens to be used in other chipsets and has been supported in the Linux kernel for many of them for quite some time. Hopefully, the exercise will not be too frustrating.
Another device that might be a good candidate for L4Re is the Efika MX Smartbook. Although having a modest specification by today’s bloated-Web and pointless-eye-candy standards, it has a nice keyboard (with a more sensible layout than the irritating HP Elitebook, as I recently discovered) and is several times more powerful than the Letux 400. My brother, David, has already investigated certain aspects of the hardware, and it might make the basis of a nice portable system. And since support in Linux and other more commonly-used technologies has been left to rot, why not look into developing a more lasting alternative?
Reviving Mail-Based Communication
It is tiresome to see the continuing neglect of the health of e-mail, despite it being used as the bedrock of the Internet’s activities, while proprietary and predatory social media platforms enjoy undeserved attention and promotion in mass media and in society at large. Governmental and corporate negligence mean that the average person is subjected to an array of undesirable, disturbing and generally unwanted communications from chancers and criminals through their e-mail accounts which, if it had ever happened to the same degree with postal mail, would have seen people routinely arrested and convicted for their activities.
It is tempting to think that “they” do not want “us” to have a more reliable form of mail-based communication because that would involve things like encryption and digital signatures. Even when these things are deemed necessary, they always seem to be rolled out as part of a special service that hosts “our” encryption and signing keys for us, through which we must go to access our messages. It is, I suppose, yet another example of the abandonment of common infrastructure: that when something better is needed, effort and attention is siphoned off from the “commons” and ploughed into something separate that might make someone a bit of money.
There are certainly challenges involved in making e-mail better, with any discussion of managing identities, vouching for and recognising correspondents, and the management of keys most likely to lead to dispute about the “best” way of doing things. But in the end, we probably find ourselves pursuing perfect solutions that do everything whilst proprietary competitors just focus on doing a handful of things effectively. So I envisage turning this around and evaluating whether a more limited form of mail-based communication can be done in the way that most people would need.
I did look fairly recently at a selection of different projects seeking to advise and support people on providing their own e-mail infrastructure. That is perhaps worth an article in its own right. And on the subject of mail-based communication, I hope to look a bit more at imip-agent again after neglecting it for so long.
Sustaining a Python Alternative
One motivation for developing my Python-like language and toolchain, Lichen, was to explore ways in which Python might have been developed to better suit my own needs and preferences. Although I still use Python extensively, I remain mindful of the need to write conservative, uncomplicated code without the kind of needless tricks and flourishes that Python’s expanding feature set can tempt the developer with, and thus I almost always consider the possibility of being able to use the Lichen toolchain with my projects one day.
Lichen may still be a proof of concept, but there has been work done on gradually pushing it towards being genuinely usable. I spent some time considering the way floating point numbers might be represented, and this raised some interesting issues around how they might be stored within instances. Like the tuple performance optimisations, I hope to introduce floating point support into the established feature set of Lichen and hopefully offer decent-enough performance, with the latter aspect being yet another path of investigation this year.
Documenting and Publishing
A continuing worry I have is whether I should still be running MoinMoin sites or even sites derived from MoinMoin “export dumps” for published information that is merely static. I have spent some time developing a parsing and formatting tool to generate static content from Moin content, thus avoiding running Moin altogether and also avoiding having to run a script acting as a URL-preserving front-end to exported Moin content (which is unfortunately required because of how the “export dump” seems to work).
Currently, this tool supports HTML and Moin output, the latter to test the parsing activity, with Graphviz content rendered as inline SVG or in other supported formats (although inline SVG is really what you want). Some macros are supported, but I need to add support for others, like the search macros which are useful for generating page listings. Themes are also supported, but I need to make sure that things like tables of contents – already supported with a macro – can be styled appropriately.
Already, I can generate the bulk of my existing project documentation, and the aim here is to be able to focus on improving that documentation, particularly for things like Lichen that really need explanations to be written before I need to start reviewing the code from scratch as if I were a total newcomer to the work. I have also considered using this tool as the basis for a decentralised wiki solution, but that can probably wait for a while given how many other things I have said I want to do!
Anything More?
There are probably other things that are worth looking at, but these are perhaps the ones I feel are most pressing. It could be said that pursuing all these at once would spread me and my efforts very thin, but I tend to cycle through projects periodically and hope that I can catch up with what I was previously doing, hence the mention above of documenting my work.
I wonder how much other people think about the year ahead, whether it is a productive and ultimately rewarding exercise to state aspirations and goals in this kind of way. New Year’s resolutions are a familiar practice, of course, but here I make no promises!
Nevertheless, a belated Happy New Year to anyone still reading! I hope we can all pursue our objectives enthusiastically over the year ahead and make a real and positive difference to computing, its users and to our societies.
Planet FSFE (en):  RSS 2.0 | Atom |
RSS 2.0 | Atom |  FOAF |
FOAF | 
/var/log/fsfe/flx » planet-en
Albrechts Blog
Alessandro at FSFE » English
Alessandro's blog
Alina Mierlus - Building the Freedom » English
Andrea Scarpino's blog
André Ockers on Free Software
Being Fellow #952 of FSFE » English
Bela's Internship Blog
Bernhard's Blog
Bits from the Basement
Blog of Martin Husovec
Blog » English
Blog – Think. Innovation.
Bobulate
Brian Gough's Notes
Chris Woolfrey -- FSFE UK Team Member
Ciarán's free software notes
Colors of Noise - Entries tagged planetfsfe
Communicating freely
Daniel Martí's blog
David Boddie - Updates (Full Articles)
ENOWITTYNAME
English Planet – Dreierlei
English on Björn Schießle - I came for the code but stayed for the freedom
English – Max's weblog
Escape to freedom
Evaggelos Balaskas - System Engineer
FSFE Fellowship Vienna » English
FSFE interviews its Fellows
Fellowship News
Florian Snows Blog » en
Frederik Gladhorn (fregl) » FSFE
Free Software & Digital Rights Noosphere
Free Software with a Female touch
Free Software –
Free Software – Frank Karlitschek_
Free Software – hesa's Weblog
Free as LIBRE
Free speech is better than free beer » English
Free, Easy and Others
From Out There
Giacomo Poderi
Green Eggs and Ham
Handhelds, Linux and Heroes
HennR's FSFE blog
Henri Bergius
Hook’s Humble Homepage
Hugo - FSFE planet
Inductive Bias
Jelle Hermsen » English
Jens Lechtenbörger » English
Karsten on Free Software
Losca
MHO
Mario Fux
Martin's notes - English
Matej's blog » FSFE
Matthias Kirschner's Web log - fsfe
Michael Clemens
Myriam's blog
Mäh?
Nice blog
Nico Rikken » fsfe
Nicolas Jean's FSFE blog » English
Nikos Roussos - opensource
PB's blog » en
Paul Boddie's Free Software-related blog » English
Planet FSFE on Iain R. Learmonth
Po angielsku — mina86.com
Posts - Carmen Bianca Bakker
Posts on Hannes Hauswedell's homepage
Pressreview
Ramblings of a sysadmin (Posts about planet-fsfe)
Rekado
Repentinus » English
Riccardo (ruphy) Iaconelli - blog
Saint's Log
Seravo
TSDgeos' blog
Tarin Gamberini
Technology – Intuitionistically Uncertain
The Girl Who Wasn't There » English
The trunk
Thib's Fellowship Blog » fsfe
Thinking out loud » English
Thomas Løcke Being Incoherent
Told to blog - Entries tagged fsfe
Tonnerre Lombard
Torsten's FSFE blog » english
Viktor's notes » English
Vitaly Repin. Software engineer's blog
Weblog
Weblog
Weblog
Weblog
Weblog
Weblog
With/in the FSFE » English
a fellowship ahead
agger's Free Software blog
anna.morris's blog
ayers's blog
bb's blog
blog
drdanzs blog » freesoftware
egnun's blog » FreeSoftware
english – Davide Giunchi
foss – vanitasvitae's blog
free software blog
freedom bits
gollo's blog » English
julia.e.klein's blog
marc0s on Free Software
mkesper's blog » English
pichel's blog
polina's blog
rieper|blog » en
softmetz' anglophone Free Software blog
stargrave's blog
tobias_platen's blog
tolld's blog
wkossen's blog
yahuxo's blog