14/06/2022-20/06/2022

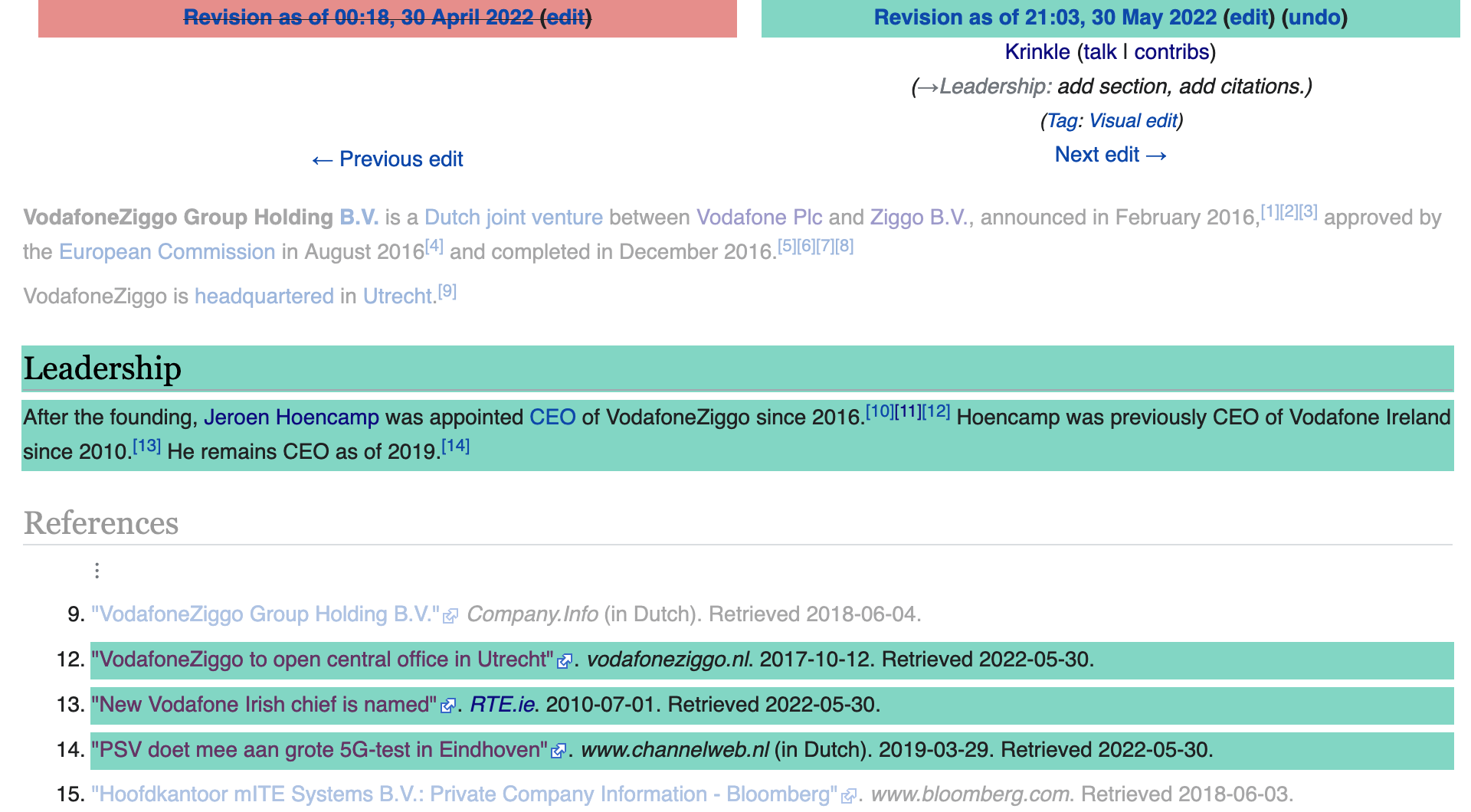
Osmose using open data in France and Spain now [1] © Osmose | map data © OpenStreetMap contributors
Breaking news
- The next OSMF Board meeting will take
place on
Thursday 30 June 2022, at 13:00 UTC via the OSMF video room
(which opens about 20 minutes before the meeting). The draft agenda
is
available on the wiki. The topics to be covered are:
- Treasurer’s report
- Updated membership prerequisites plan
- Consider directing the OWG to cut access off due to attribution
or other
legal policy reasons, if flagged by the LWG - OSM Carto
- OSM account creation API
- Advisory Board – monthly update
- Presentation by Mapbox Workers Union
- Guest comments or questions.
Mapping
- ViriatoLusitano has updated
 >
>
 his very detailed and richly illustrated guide describing how to
integrate data from the National Institute of Statistics (INE) into
OSM, with names and georeferenced boundaries of different urban
agglomerations.
his very detailed and richly illustrated guide describing how to
integrate data from the National Institute of Statistics (INE) into
OSM, with names and georeferenced boundaries of different urban
agglomerations. - Anne-Karoline Distel made a short report on her mapping trip to North Wales.
- At this year’s SotM France conference,
Stéphane Péneau gave
 an
overview of street-level imagery, from hardware choice to file
management.
an
overview of street-level imagery, from hardware choice to file
management. - Requests have been made for comments on the
following proposals:
-
school=entranceto deprecate the use of the tagschool=entrance. exit=*to deprecateentrance=exit,entrance=emergency, andentrance=entrancein favour of clearer tags.- Emergency access and exits to address issues with the current tagging of these items.
-
aeroway=stopwayfor mapping the area beyond the runway that has a full-strength pavement able to support aircraft, which can be used for deceleration in the event of a rejected take-off. -
runway=displaced_thresholdfor mapping the part of a runway which can be used for take-off, but not landing. -
school:for=*a tag for schools to indicate what kinds of facilities are available for special needs students. -
information=qr_codefor tagging a QR code that provides information about a location of interest to tourists.
-
- Voting on the
pitch:net=*proposal, for indicating if a net is available at a sports pitch, is open until Saturday 2 July. - Voting on the following proposals has closed:
-
aeroway=aircraft_crossingto mark a point where the flow of traffic is impacted by crossing aircraft, was approved with 14 votes for, 0 votes against and 0 abstentions. -
substation=*to improve tagging of power substations and transformers mixing on the same node, was approved with 11 votes for, 1 vote against and 0 abstentions.
-
Community
- In the 133rd episode of the Geomob Podcast, Muki Haklay, Professor of Geoinformatics at UCL, an early adopter of combining geography with computer science and one of the earliest supporters of OpenStreetMap, is the guest. There is a discussion about extreme Citizen Science.
- Nathalie
Sidibé >
,
from OSM Mali, is now involved in another community: Wikipedia! Her
commitment to the Malian community, to open source data and of
course to OSM has already been featured in several profiles. Now
there is her full
biography >
and an initiative of the ‘Les
sans pagEs‘ >
women geographers project.
Imports
- Daniel Capilla provided
 >
an update about the import of Iberdrola charging stations for
electric vehicles in Malaga, which is now complete. The data is
available under an open licence from the Municipality of Malaga
(Spain). He maintains a corresponding
wiki page for the documentation and coordination of open data
imports.
>
an update about the import of Iberdrola charging stations for
electric vehicles in Malaga, which is now complete. The data is
available under an open licence from the Municipality of Malaga
(Spain). He maintains a corresponding
wiki page for the documentation and coordination of open data
imports.
Events
- YouthMappers UMSA, a recently opened chapter
of YouthMappers in Bolivia, tweeted
about
their first OpenStreetMap training activity on 22 June.
- Videos of the presentations at the SofM-Fr
2022 conference are now available
online. A
session listing for the conference, which was held 10 to 12 June in
Nantes, is available
>
on their website.
Education
- Anne-Karoline Distel explained in a new video how to add running trails to OpenStreetMap.
- Astrid Günther explained, in a tutorial, how she created vector tiles for a small area of Earth and hosts them herself.
OSM research
- Youjin Choe, a PhD student in Geomatics at the University of Melbourne, Australia, is looking for your advice on a potential focus group study on the design of the OSM changeset discussion interface. Her research topic is on the user conflict management process in online geospatial data communities (which has mixed components of GIS, HCI, and organisational management).
Maps
- Hub and spoke is a map that shows the 10 nearest airports to a given position.
- CipherBliss published
a
thematic map of places to eat based on OpenStreetMap,
‘Melting
Pot‘ >
.
Open Data
- [1] Osmose is now using open data to compare against OpenStreetMap data to find any missing roads or power lines in OSM. At present comparisons are made for power lines in France and highways in Spain.
Software
- The first version of ‘Organic
Maps’, a free and open source mobility map app for Android
and iOS, was released
 >
last June (2021). After more than 100,000 installations and one
year of intensive development work, the results and plans for the
future are presented.
>
last June (2021). After more than 100,000 installations and one
year of intensive development work, the results and plans for the
future are presented.
Programming
- The new OSM app OSM Go! is looking for translators and developers.
Releases
- Version 17.1 of the Android OSM editor Vespucci has been released.
- With version StreetComplete v45.0-alpha1 Tobias Zwick introduced the new overlays functionality.
Did you know …
- … that there are apps out there helping you find windy roads? Curvature, Calimoto and Kurviger are just some examples.
- … the MapCSS style for special highlighting of bicycle infrastructure in JOSM?
- … HistOSM.org, which renders historical features exclusively?
- … the Japanese local chapter of OSMF,
OSMFJ, maintains a tile
server and also offers a vector tile download service (via user
smellman)? More details are on the wiki
 >
.
>
.
OSM in the media
- OpenStreetMap
featured >
(see
video ) ) in an
overview of a wide range of modern mapping technologies in a
segment on the France24 news
channel. The OSM examples were: participative mapping in Africa
(3m17s); and,
Grab’s use of OSM in South-East Asia (4m10s), which allows them,
unlike other map providers, to take into account the reality of
Asia with rainy seasons and a lot of narrow roads. Other topics
include Apple’s 3-D visualisation of Las Vegas, 360 degree
image capture, indoor mapping and geoblocking.
Other “geo” things
- Matthew Maganga wrote, in ArchDaily, about the inequalities created through modern mapping methods and especially Google StreetView.
- Google Earth blogged about how they process Copernicus Sentinel-2 satellite images daily to create a current and historical land cover data set.
- Saman Bemel Benrud, an early Mapbox employee, looked back at the 12 years he worked at the company and describes how it changed over time – leading to a failed attempt to found a union, which was part of the reason he left the company last year.
- Canada and Denmark had a decades long land dispute, called the Whisky War, over an uninhabited Arctic island between Nunavut and Greenland. Following an agreement to divide control of Hans Island / Tartupaluk / ᑕᕐᑐᐸᓗᒃ, Canada now has a land border with a second country after the United States. Note that Canada also shares a maritime border with a second European country (France) near Newfoundland (second because Greenland is a constituent country of the Kingdom of Denmark).
Upcoming Events
| Where | What | Online | When | Country |
|---|---|---|---|---|
| Arlon | EPN d’Arlon – Atelier ouvert OpenStreetMap –
Contribution |
2022-06-28 |  |
|
| Hlavní město Praha | MSF Missing Maps CZ Mapathon 2022 #2 | Prague, KPMG office (Florenc) |
2022-06-28 | |
| City of New York | A Synesthete’s Atlas (Brooklyn, NY) |
2022-06-29 |  |
|
| Roma | Incontro dei mappatori romani e laziali |
2022-06-29 |  |
|
| [Online] OpenStreetMap Foundation board of Directors –
public videomeeting |
2022-06-30 | |||
| Washington | A Synesthete’s Atlas (Washington, DC) |
2022-07-01 | |
|
| Essen | 17. OSM-FOSSGIS-Communitytreffen |
2022-07-01 – 2022-07-03 |  |
|
| OSM Africa July Mapathon: Map Liberia |
2022-07-01 | |||
| OSMF Engineering Working Group meeting |
2022-07-04 | |||
| 臺北市 | OpenStreetMap x Wikidata Taipei #42 |
2022-07-04 |  |
|
| San Jose | South Bay Map Night |
✓ | 2022-07-06 | |
| London | Missing Maps London Mapathon |
2022-07-05 |  |
|
| Berlin | OSM-Verkehrswende #37 (Online) |
✓ | 2022-07-05 | |
| Salt Lake City | OSM Utah Monthly Meetup |
2022-07-07 | |
|
| Fremantle | Social Mapping Sunday: Fremantle |
2022-07-10 |  |
|
| München | Münchner OSM-Treffen |
2022-07-12 | |
|
| 20095 | Hamburger Mappertreffen |
2022-07-12 | |
|
| Landau an der Isar | Virtuelles Niederbayern-Treffen |
✓ | 2022-07-12 | |
| Salt Lake City | OSM Utah Monthly Meetup |
2022-07-14 | |
Note:
If you like to see your event here, please put it into the OSM calendar. Only data which is there,
will appear in weeklyOSM.
This weeklyOSM was produced by Lejun, Nordpfeil, PierZen, SK53, SeverinGeo, Strubbl, Supaplex, TheSwavu, YoViajo, derFred.





















 >
>


















 /
/











{kind=link}
{kind=link}
{kind=link}
_LCCN2014686695.jpg){kind=link}
{kind=link}