To start off, let me say it again: I hate light pollution. I really, really hate it. I love the night sky where you look up and see thousands of stars, and constellations besides Ursa Major. As somebody said once, “You haven’t lived until you’ve seen your shadow by the light of the Milky Way”.
But, ahem, I live in a large city, and despite my attempts using star trackers, special filters, etc. you simply can’t escape it. So, whenever we go on vacation in the mountains, I’m trying to think if I an do a bit of astro-photography (not that I’m good at it).
Which bring me to our recent vacation up in the mountains. I was looking forward to it, until in the week before, when the weather prognosis was switching between snow, rain and overcast for the entire week. No actual day or night with clear skies, so… I didn’t take a tripod, I didn’t take a wide lens, and put night photography out of my mind.
Vacation itself was good, especially the quietness of the place, so I usually went to be early-ish and didn’t look outside. The weather was as forecasted - no new snow (but there was enough up in the mountains), but heavy clouds all the time, and the sun only showed itself for a few minutes at a time.
One night I was up a bit longer than usual, working on the laptop and being very annoyed by a buzzing sound. At first I thought maybe I was imagining it, but from time to time it was stopping briefly, so it was a real noise; I started hunting for the source. Not my laptop, not the fridge, not the TV… but it was getting stronger near the window. I open the door to the balcony, and… bam! Very loud noise, from the hotel nearby, where — at midnight — the pool was being cleaned. I look at the people doing the work, trying to estimate how long it’ll be until they finish, but it was looking like a long time.
Fortunately with the door closed the noise was not bad enough to impact my sleep, so I debate getting angry or just resigned, and since it was late, I just sigh, roll my eyes — not metaphorically, but actually roll my eyes and look up, and I can’t believe my eyes. Completely clear sky, no trace of clouds anywhere, and… stars. Lots of starts. I sit there, looking at the sky and enjoying the view, and I think to myself that it won’t look that nice on the camera, for sure. Especially without a real trip, and without a fast lens.
Nevertheless, I grab my camera and — just for kicks — take one handheld picture. To my surprise (and almost disbelief), blurry pixels aside, the photo does look like what I was seeing, so I grab my tiny tripod that I carried along, and (with only a 24-70 zoom lens), grab a photo. And another, and another and then I realise that if I can make the composition work, and find a good shutter speed, this can turn out a good picture.
I didn’t have a remote release, the tripod was not very stable and it cannot point the camera upwards (it’s basically an emergency tripod), so it was quite sub-optimal; still, I try multiple shots (different compositions, different shutter speeds); they look on the camera screen and on the phone pretty good, so just for safety I take a few more, and, very happy, go to bed.
Coming back from vacation, on the large monitor, it turns out that the first 28 out of the 30 pictures were either blurry or not well focused (as I was focusing manually), and the 29th was almost OK but still not very good. Only the last, the really last picture, was technically good and also composition-wise OK. Luck? Foresight? Don’t know, but it was worth deleting 28 pictures to get this one. One of my best night shots, despite being so unprepared…
Stars! Lots of stars! And mountains…
Of course, compared to other people’s pictures, this is not special. But for me, it will be a keepsake of how a real night sky should look like.
If you want to zoom in, higher resolution on flickr.
Technically, the challenges for the picture were two-fold:
fighting the shutter speed; the light was not the problem, but rather the tripod and lack of remote release: a short shutter speed will magnify tripod issues/movement from the release (although I was using delayed release on the camera), but will prevent star trails, and a long shutter speed will do the exact opposite; in the end, at the focal length I was using, I settled on a 5 second shutter speed.
composition: due to the presence of the mountains (which I couldn’t avoid by tilting the camera fully up), this was for me a difficult thing, since it’s more on the artistic side, which is… very subjective; in the end, this turned out fine (I think), but mostly because I took pictures from many different perspectives.
Next time when travelling by car, I’ll surely take a proper tripod ☺
To enable the asterisk user to load the certificate successfuly (it
doesn't permission to access to the certificates under /etc/letsencrypt/),
I copied it to the right directory:
The machine on which I run asterisk has a tricky Apache setup:
a webserver is running on port 80
port 80 is restricted to the local network
This meant that the certbot domain ownership checks would get blocked by the
firewall, and I couldn't open that port without exposing the private
webserver to the Internet.
So I ended up disabling the built-in certbot renewal mechanism:
And a new version of digest is now on CRAN will go to Debian shortly.
digest creates hash digests of arbitrary R objects (using the md5, sha-1, sha-256, sha-512, crc32, xxhash32, xxhash64, murmur32, spookyhash, and blake3 algorithms) permitting easy comparison of R language objects. It is a fairly widely-used package (currently listed at 896k monthly downloads, 279 direct reverse dependencies and 8057 indirect reverse dependencies, or just under half of CRAN) as many tasks may involve caching of objects for which it provides convenient general-purpose hash key generation.
This release brings two nice contributed updates. Dirk Schumacher added support for blake3 (though we could probably push this a little harder for performance, help welcome). Winston Chang benchmarked and tuned some of the key base R parts of the package. Last but not least I flipped the vignette to the lovely minidown, updated the Travis CI setup using bspm (as previously blogged about in r4 #30), and added a package website using Matertial for MkDocs.
Troubleshooting your audio input.
When doing video conferencing sometimes I hear the remote end not doing very well.
Especially when your friend tells you he bought a new mic
and it didn't sound well, they might be using the wrong
configuration on the OS and using the other mic, or they
might have a constant noise source in the room that affects
the video conferencing noise cancelling algorithms.
Yes, noise cancelling algorithms aren't perfect because detecting what is noise is heuristic and better to have low level of noise.
Here is the app.
I have a video to demonstrate.
It's a bit of a long shot, but maybe someone on Planet Debian or
elsewhere can help us reach the right people at Apple.
Starting with iOS 14, something apparently changed on the way
USB tethering (also called Personal Hotspot) is set up, which broke
it for people using Linux. The driver in use is ipheth, developped
in 2009 and
included in the Linux kernel in
2010.
The kernel driver negotiates over USB with the iOS device in
order to setup the link. The protocol used by both parties to
communicate don't really seemed documented publicly, and it seems
the protocol has evolved over time and iOS versions, and the Linux
driver hasn't been kept up to date. On macOS and Windows the driver
apparently comes with iTunes, and Apple engineers obviously know
how to communicate with iOS devices, so iOS 14 is supported just
fine.
There's an open
bug on libimobildevice (the set of userlands tools used to
communicate with iOS devices, although the update should be done in
the
kernel), with some debugging and communication logs between
Windows and an iOS device, but so far no real progress has been
done. The link is enabled, the host gets an IP from the device, can
ping the device IP and can even resolve name using the device DNS
resolver, but IP forwarding seems disabled, no packet goes farther
than the device itself.
That means a lot of people upgrading to iOS 14 will suddenly
lose USB tethering. While Wi-Fi and Bluetooth connection sharing
still works, it's still suboptimal, so it'd be nice to fix the
kernel driver and support the latest protocol used in iOS 14.
If someone knows the right contact (or the right way to contact
them) at Apple so we can have access to some kind of documentation
on the protocol and the state machine to use, please reach us
(either to the libimobile device bug or to my email address
below).
The Debian Janitor is an automated
system that commits fixes for (minor) issues in Debian packages that can be
fixed by software. It gradually started proposing merges in early
December. The first set of changes sent out ran lintian-brush on sid packages maintained in
Git. This post is part of a series about the progress of the
Janitor.
lintian-brush can currently fix about 150 different issues that lintian can
report, but that's still a small fraction of the more than thousand different
types of issue that lintian can detect.
If you're interested in contributing a fixer script to lintian-brush, there is now a guide
that describes all steps of the process:
how to identify lintian tags that are good candidates for automated fixing
creating test cases
writing the actual fixer
For more information about the Janitor's lintian-fixes efforts, see the landing page.
Mexico was one of the first countries in the world to set up a
national population registry in the late 1850s, as part of the
church-state separation that was for long years one of the national
sources of pride.
Forty four years ago, when I was born, keeping track of the population
was still mostly a manual task. When my parents registered me, my data
was stored in page 161 of book 22, year 1976, of the 20th Civil
Registration office in Mexico City. Faithful to the legal tradition,
everything is handwritten and specified in full. Because, why would
they write 1976.04.27 (or even 27 de abril de 1976) when they
could spell out día veintisiete de abril de mil novecientos setenta y
seis? Numbers seem to appear only for addresses.
So, the State had record of a child being born, and we knew where to
look if we came to need this information. But, many years later, a
very sensible tecnification happened: all records (after a certain
date, I guess) were digitized. Great news! I can now get my birth
certificate without moving from my desk, paying a quite reasonable fee
(~US$4). What’s there not to like?
Digitally certified and all! So great! But… But… Oh, there’s a
problem.
Of course… Making sense of the handwriting as you can see is
somewhat prone to failure. And I cannot blame anybody for failing to
understand the details of my record.
So, my mother’s first family name is Iszaevich. It was digitized as
Iszaerich. Fortunately, they do acknowledge some errors could have
made it into the process, and there is a process to report and
correct
errors.
What’s there not to like?
Oh — That they do their best to emulate a public office using online
tools. I followed some links in that link to get the address to
contact and yesterday night sent them the needed documents. Quite
immediately, I got an answer that… I must share with the world:
Yes, the mailing contact is in the @gmail.com domain. I could care
about them not using a @….gob.mx address, but I’ll let it slip. The
mail I got says (uppercase and all):
GOOD EVENING,
WE INFORM YOU THAT THE RECEPTION OF E-MAILS FOR REQUESTING
CORRECTIONS IN CERTIFICATES IS ONLY ACTIVE MONDAY THROUGH FRIDAY,
8:00 TO 15:00.
*IN CASE YOU SENT A MAIL OUTSIDE THE WORKING HOURS, IT WILL BE
AUTOMATICALLY DELETED BY THE SERVER*
CORDIAL GREETINGS,
I would only be half-surprised if they were paying the salary of
somebody to spend the wee hours of the night receiving and deleting
mails from their GMail account.
This release adds two functions. One was mentioned just days ago in a tweet by Nathan and is a reworked version of something Colin tweeted about a few weeks ago: a little data wrangling off the kewl rtweet to find maximally spammy accounts per search topic. In other words those who include more than ‘N’ hashtags for given search term. The other is something I, if memory serves, picked up a while back on one of the lists: a base R function to identify non-ASCII characters in a file. It is a C function that is not directly exported by and hence no accessible, so we put it here (with credits, of course). I mentioned it yesterday when announcing tidyCpp as I this C function was the starting point for the new tidyCpp wrapper around some C API of R functions.
The (very short) NEWS entry follows.
Changes in version 0.0.12 (2020-10-14)
New functions muteTweets and checkPackageAsciiCode.
I measured how long the most popular Linux distribution’s package manager take
to install small and large packages (the
ack(1p) source code search Perl script
and qemu, respectively).
Where required, my measurements include metadata updates such as transferring an
up-to-date package list. For me, requiring a metadata update is the more common
case, particularly on live systems or within Docker containers.
All measurements were taken on an Intel(R) Core(TM) i9-9900K CPU @ 3.60GHz
running Docker 1.13.1 on Linux 4.19, backed by a Samsung 970 Pro NVMe drive
boasting many hundreds of MB/s write performance. The machine is located in
Zürich and connected to the Internet with a 1 Gigabit fiber connection, so the
expected top download speed is ≈115 MB/s.
See Appendix C for details on the measurement method and command
outputs.
Measurements
Keep in mind that these are one-time measurements. They should be indicative of
actual performance, but your experience may vary.
The difference between the slowest and fastest package managers is 30x!
How can Alpine’s apk and Arch Linux’s pacman be an order of magnitude faster
than the rest? They are doing a lot less than the others, and more efficiently,
too.
Pain point: too much metadata
For example, Fedora transfers a lot more data than others because its main
package list is 60 MB (compressed!) alone. Compare that with Alpine’s 734 KB
APKINDEX.tar.gz.
Of course the extra metadata which Fedora provides helps some use case,
otherwise they hopefully would have removed it altogether. The amount of
metadata seems excessive for the use case of installing a single package, which
I consider the main use-case of an interactive package manager.
I expect any modern Linux distribution to only transfer absolutely required
data to complete my task.
Pain point: no concurrency
Because they need to sequence executing arbitrary package maintainer-provided
code (hooks and triggers), all tested package managers need to install packages
sequentially (one after the other) instead of concurrently (all at the same
time).
In my blog post “Can we do without hooks and
triggers?”, I outline that hooks and
triggers are not strictly necessary to build a working Linux distribution.
Thought experiment: further speed-ups
Strictly speaking, the only required feature of a package manager is to make
available the package contents so that the package can be used: a program can be
started, a kernel module can be loaded, etc.
By only implementing what’s needed for this feature, and nothing more, a package
manager could likely beat apk’s performance. It could, for example:
skip archive extraction by mounting file system images (like AppImage or snappy)
use compression which is light on CPU, as networks are fast (like apk)
skip fsync when it is safe to do so, i.e.:
package installations don’t modify system state
atomic package installation (e.g. an append-only package store)
automatically clean up the package store after crashes
As per the current landscape, there is no
distribution-scoped package manager which uses images and leaves out hooks and
triggers, not even in smaller Linux distributions.
I think that space is really interesting, as it uses a minimal design to achieve
significant real-world speed-ups.
I have explored this idea in much more detail, and am happy to talk more about
it in my post “Introducing the distri research linux distribution".
Appendix A: related work
There are a couple of recent developments going into the same direction:
NixOS’s Nix takes a little over 5s to fetch and unpack 15 MB.
% docker run -t -i nixos/nix
39e9186422ba:/# time sh -c 'nix-channel --update && nix-env -iA nixpkgs.ack'
unpacking channels...
created 1 symlinks in user environment
installing 'perl5.32.0-ack-3.3.1'
these paths will be fetched (15.55 MiB download, 85.51 MiB unpacked):
/nix/store/34l8jdg76kmwl1nbbq84r2gka0kw6rc8-perl5.32.0-ack-3.3.1-man
/nix/store/9df65igwjmf2wbw0gbrrgair6piqjgmi-glibc-2.31
/nix/store/9fd4pjaxpjyyxvvmxy43y392l7yvcwy1-perl5.32.0-File-Next-1.18
/nix/store/czc3c1apx55s37qx4vadqhn3fhikchxi-libunistring-0.9.10
/nix/store/dj6n505iqrk7srn96a27jfp3i0zgwa1l-acl-2.2.53
/nix/store/ifayp0kvijq0n4x0bv51iqrb0yzyz77g-perl-5.32.0
/nix/store/w9wc0d31p4z93cbgxijws03j5s2c4gyf-coreutils-8.31
/nix/store/xim9l8hym4iga6d4azam4m0k0p1nw2rm-libidn2-2.3.0
/nix/store/y7i47qjmf10i1ngpnsavv88zjagypycd-attr-2.4.48
/nix/store/z45mp61h51ksxz28gds5110rf3wmqpdc-perl5.32.0-ack-3.3.1
copying path '/nix/store/34l8jdg76kmwl1nbbq84r2gka0kw6rc8-perl5.32.0-ack-3.3.1-man' from 'https://cache.nixos.org'...
copying path '/nix/store/czc3c1apx55s37qx4vadqhn3fhikchxi-libunistring-0.9.10' from 'https://cache.nixos.org'...
copying path '/nix/store/9fd4pjaxpjyyxvvmxy43y392l7yvcwy1-perl5.32.0-File-Next-1.18' from 'https://cache.nixos.org'...
copying path '/nix/store/xim9l8hym4iga6d4azam4m0k0p1nw2rm-libidn2-2.3.0' from 'https://cache.nixos.org'...
copying path '/nix/store/9df65igwjmf2wbw0gbrrgair6piqjgmi-glibc-2.31' from 'https://cache.nixos.org'...
copying path '/nix/store/y7i47qjmf10i1ngpnsavv88zjagypycd-attr-2.4.48' from 'https://cache.nixos.org'...
copying path '/nix/store/dj6n505iqrk7srn96a27jfp3i0zgwa1l-acl-2.2.53' from 'https://cache.nixos.org'...
copying path '/nix/store/w9wc0d31p4z93cbgxijws03j5s2c4gyf-coreutils-8.31' from 'https://cache.nixos.org'...
copying path '/nix/store/ifayp0kvijq0n4x0bv51iqrb0yzyz77g-perl-5.32.0' from 'https://cache.nixos.org'...
copying path '/nix/store/z45mp61h51ksxz28gds5110rf3wmqpdc-perl5.32.0-ack-3.3.1' from 'https://cache.nixos.org'...
building '/nix/store/m0rl62grplq7w7k3zqhlcz2hs99y332l-user-environment.drv'...
created 49 symlinks in user environment
real 0m 5.60s
user 0m 3.21s
sys 0m 1.66s
Debian’s apt takes almost 10 seconds to fetch and unpack 16 MB.
% docker run -t -i debian:sid
root@1996bb94a2d1:/# time (apt update && apt install -y ack-grep)
Get:1 http://deb.debian.org/debian sid InRelease [146 kB]
Get:2 http://deb.debian.org/debian sid/main amd64 Packages [8400 kB]
Fetched 8546 kB in 1s (8088 kB/s)
[…]
The following NEW packages will be installed:
ack libfile-next-perl libgdbm-compat4 libgdbm6 libperl5.30 netbase perl perl-modules-5.30
0 upgraded, 8 newly installed, 0 to remove and 23 not upgraded.
Need to get 7341 kB of archives.
After this operation, 46.7 MB of additional disk space will be used.
[…]
real 0m9.544s
user 0m2.839s
sys 0m0.775s
Arch Linux’s pacman takes a little under 3s to fetch and unpack 6.5 MB.
% docker run -t -i archlinux/base
[root@9f6672688a64 /]# time (pacman -Sy && pacman -S --noconfirm ack)
:: Synchronizing package databases...
core 130.8 KiB 1090 KiB/s 00:00
extra 1655.8 KiB 3.48 MiB/s 00:00
community 5.2 MiB 6.11 MiB/s 00:01
resolving dependencies...
looking for conflicting packages...
Packages (2) perl-file-next-1.18-2 ack-3.4.0-1
Total Download Size: 0.07 MiB
Total Installed Size: 0.19 MiB
[…]
real 0m2.936s
user 0m0.375s
sys 0m0.160s
Alpine’s apk takes a little over 1 second to fetch and unpack 10 MB.
NixOS’s Nix takes almost 34s to fetch and unpack 180 MB.
% docker run -t -i nixos/nix
83971cf79f7e:/# time sh -c 'nix-channel --update && nix-env -iA nixpkgs.qemu'
unpacking channels...
created 1 symlinks in user environment
installing 'qemu-5.1.0'
these paths will be fetched (180.70 MiB download, 1146.92 MiB unpacked):
[…]
real 0m 33.64s
user 0m 16.96s
sys 0m 3.05s
Debian’s apt takes over 95 seconds to fetch and unpack 224 MB.
% docker run -t -i debian:sid
root@b7cc25a927ab:/# time (apt update && apt install -y qemu-system-x86)
Get:1 http://deb.debian.org/debian sid InRelease [146 kB]
Get:2 http://deb.debian.org/debian sid/main amd64 Packages [8400 kB]
Fetched 8546 kB in 1s (5998 kB/s)
[…]
Fetched 216 MB in 43s (5006 kB/s)
[…]
real 1m25.375s
user 0m29.163s
sys 0m12.835s
Arch Linux’s pacman takes almost 44s to fetch and unpack 142 MB.
% docker run -t -i archlinux/base
[root@58c78bda08e8 /]# time (pacman -Sy && pacman -S --noconfirm qemu)
:: Synchronizing package databases...
core 130.8 KiB 1055 KiB/s 00:00
extra 1655.8 KiB 3.70 MiB/s 00:00
community 5.2 MiB 7.89 MiB/s 00:01
[…]
Total Download Size: 135.46 MiB
Total Installed Size: 661.05 MiB
[…]
real 0m43.901s
user 0m4.980s
sys 0m2.615s
Alpine’s apk takes only about 2.4 seconds to fetch and unpack 26 MB.
% docker run -t -i alpine
/ # time apk add qemu-system-x86_64
fetch http://dl-cdn.alpinelinux.org/alpine/v3.10/main/x86_64/APKINDEX.tar.gz
fetch http://dl-cdn.alpinelinux.org/alpine/v3.10/community/x86_64/APKINDEX.tar.gz
[…]
OK: 78 MiB in 95 packages
real 0m 2.43s
user 0m 0.46s
sys 0m 0.09s
Appendix B: measurement details (2019)
ack
You can expand each of these:
Fedora’s dnf takes almost 30 seconds to fetch and unpack 107 MB.
% docker run -t -i nixos/nix
39e9186422ba:/# time sh -c 'nix-channel --update && nix-env -i perl5.28.2-ack-2.28'
unpacking channels...
created 2 symlinks in user environment
installing 'perl5.28.2-ack-2.28'
these paths will be fetched (14.91 MiB download, 80.83 MiB unpacked):
/nix/store/57iv2vch31v8plcjrk97lcw1zbwb2n9r-perl-5.28.2
/nix/store/89gi8cbp8l5sf0m8pgynp2mh1c6pk1gk-attr-2.4.48
/nix/store/gkrpl3k6s43fkg71n0269yq3p1f0al88-perl5.28.2-ack-2.28-man
/nix/store/iykxb0bmfjmi7s53kfg6pjbfpd8jmza6-glibc-2.27
/nix/store/k8lhqzpaaymshchz8ky3z4653h4kln9d-coreutils-8.31
/nix/store/svgkibi7105pm151prywndsgvmc4qvzs-acl-2.2.53
/nix/store/x4knf14z1p0ci72gl314i7vza93iy7yc-perl5.28.2-File-Next-1.16
/nix/store/zfj7ria2kwqzqj9dh91kj9kwsynxdfk0-perl5.28.2-ack-2.28
copying path '/nix/store/gkrpl3k6s43fkg71n0269yq3p1f0al88-perl5.28.2-ack-2.28-man' from 'https://cache.nixos.org'...
copying path '/nix/store/iykxb0bmfjmi7s53kfg6pjbfpd8jmza6-glibc-2.27' from 'https://cache.nixos.org'...
copying path '/nix/store/x4knf14z1p0ci72gl314i7vza93iy7yc-perl5.28.2-File-Next-1.16' from 'https://cache.nixos.org'...
copying path '/nix/store/89gi8cbp8l5sf0m8pgynp2mh1c6pk1gk-attr-2.4.48' from 'https://cache.nixos.org'...
copying path '/nix/store/svgkibi7105pm151prywndsgvmc4qvzs-acl-2.2.53' from 'https://cache.nixos.org'...
copying path '/nix/store/k8lhqzpaaymshchz8ky3z4653h4kln9d-coreutils-8.31' from 'https://cache.nixos.org'...
copying path '/nix/store/57iv2vch31v8plcjrk97lcw1zbwb2n9r-perl-5.28.2' from 'https://cache.nixos.org'...
copying path '/nix/store/zfj7ria2kwqzqj9dh91kj9kwsynxdfk0-perl5.28.2-ack-2.28' from 'https://cache.nixos.org'...
building '/nix/store/q3243sjg91x1m8ipl0sj5gjzpnbgxrqw-user-environment.drv'...
created 56 symlinks in user environment
real 0m 14.02s
user 0m 8.83s
sys 0m 2.69s
Debian’s apt takes almost 10 seconds to fetch and unpack 16 MB.
% docker run -t -i debian:sid
root@b7cc25a927ab:/# time (apt update && apt install -y ack-grep)
Get:1 http://cdn-fastly.deb.debian.org/debian sid InRelease [233 kB]
Get:2 http://cdn-fastly.deb.debian.org/debian sid/main amd64 Packages [8270 kB]
Fetched 8502 kB in 2s (4764 kB/s)
[…]
The following NEW packages will be installed:
ack ack-grep libfile-next-perl libgdbm-compat4 libgdbm5 libperl5.26 netbase perl perl-modules-5.26
The following packages will be upgraded:
perl-base
1 upgraded, 9 newly installed, 0 to remove and 60 not upgraded.
Need to get 8238 kB of archives.
After this operation, 42.3 MB of additional disk space will be used.
[…]
real 0m9.096s
user 0m2.616s
sys 0m0.441s
Arch Linux’s pacman takes a little over 3s to fetch and unpack 6.5 MB.
% docker run -t -i archlinux/base
[root@9604e4ae2367 /]# time (pacman -Sy && pacman -S --noconfirm ack)
:: Synchronizing package databases...
core 132.2 KiB 1033K/s 00:00
extra 1629.6 KiB 2.95M/s 00:01
community 4.9 MiB 5.75M/s 00:01
[…]
Total Download Size: 0.07 MiB
Total Installed Size: 0.19 MiB
[…]
real 0m3.354s
user 0m0.224s
sys 0m0.049s
Alpine’s apk takes only about 1 second to fetch and unpack 10 MB.
% docker run -t -i alpine
/ # time apk add ack
fetch http://dl-cdn.alpinelinux.org/alpine/v3.10/main/x86_64/APKINDEX.tar.gz
fetch http://dl-cdn.alpinelinux.org/alpine/v3.10/community/x86_64/APKINDEX.tar.gz
(1/4) Installing perl-file-next (1.16-r0)
(2/4) Installing libbz2 (1.0.6-r7)
(3/4) Installing perl (5.28.2-r1)
(4/4) Installing ack (3.0.0-r0)
Executing busybox-1.30.1-r2.trigger
OK: 44 MiB in 18 packages
real 0m 0.96s
user 0m 0.25s
sys 0m 0.07s
qemu
You can expand each of these:
Fedora’s dnf takes over a minute to fetch and unpack 266 MB.
% docker run -t -i nixos/nix
39e9186422ba:/# time sh -c 'nix-channel --update && nix-env -i qemu-4.0.0'
unpacking channels...
created 2 symlinks in user environment
installing 'qemu-4.0.0'
these paths will be fetched (262.18 MiB download, 1364.54 MiB unpacked):
[…]
real 0m 38.49s
user 0m 26.52s
sys 0m 4.43s
Debian’s apt takes 51 seconds to fetch and unpack 159 MB.
% docker run -t -i debian:sid
root@b7cc25a927ab:/# time (apt update && apt install -y qemu-system-x86)
Get:1 http://cdn-fastly.deb.debian.org/debian sid InRelease [149 kB]
Get:2 http://cdn-fastly.deb.debian.org/debian sid/main amd64 Packages [8426 kB]
Fetched 8574 kB in 1s (6716 kB/s)
[…]
Fetched 151 MB in 2s (64.6 MB/s)
[…]
real 0m51.583s
user 0m15.671s
sys 0m3.732s
Arch Linux’s pacman takes 1m2s to fetch and unpack 124 MB.
% docker run -t -i archlinux/base
[root@9604e4ae2367 /]# time (pacman -Sy && pacman -S --noconfirm qemu)
:: Synchronizing package databases...
core 132.2 KiB 751K/s 00:00
extra 1629.6 KiB 3.04M/s 00:01
community 4.9 MiB 6.16M/s 00:01
[…]
Total Download Size: 123.20 MiB
Total Installed Size: 587.84 MiB
[…]
real 1m2.475s
user 0m9.272s
sys 0m2.458s
Alpine’s apk takes only about 2.4 seconds to fetch and unpack 26 MB.
% docker run -t -i alpine
/ # time apk add qemu-system-x86_64
fetch http://dl-cdn.alpinelinux.org/alpine/v3.10/main/x86_64/APKINDEX.tar.gz
fetch http://dl-cdn.alpinelinux.org/alpine/v3.10/community/x86_64/APKINDEX.tar.gz
[…]
OK: 78 MiB in 95 packages
real 0m 2.43s
user 0m 0.46s
sys 0m 0.09s
Over the last year or so I have worked on a research linux distribution in my
spare time. It’s not a distribution for researchers (like Scientific
Linux), but my personal
playground project to research linux distribution development, i.e. try out
fresh ideas.
This article focuses on the package format and its advantages, but there is
more to distri, which I will cover in upcoming blog posts.
Frequently, I was noticing a large gap between the actual speed of an operation
(e.g. doing an update) and the possible speed based on back of the envelope
calculations. I wrote more about this in my blog post “Package managers are
slow”.
To me, this observation means that either there is potential to optimize the
package manager itself (e.g. apt), or what the system does is just too
complex. While I remember seeing some low-hanging fruit¹, through my work on
distri, I wanted to explore whether all the complexity we currently have in
Linux distributions such as Debian or Fedora is inherent to the problem space.
I have completed enough of the experiment to conclude that the complexity is not
inherent: I can build a Linux distribution for general-enough purposes which is
much less complex than existing ones.
① Those were low-hanging fruit from a user perspective. I’m not saying that
fixing them is easy in the technical sense; I know too little about apt’s code
base to make such a statement.
Key idea: packages are images, not archives
One key idea is to switch from using archives to using images for package
contents. Common package managers such as dpkg(1)
use tar(1)
archives with various compression
algorithms.
This idea is not novel: AppImage and
snappy also use
images, but only for individual, self-contained applications. distri however
uses images for distribution packages with dependencies. In particular, there is
no duplication of shared libraries in distri.
A nice side effect of using read-only image files is that applications are
immutable and can hence not be broken by accidental (or malicious!)
modification.
Key idea: separate hierarchies
Package contents are made available under a fully-qualified path. E.g., all
files provided by package zsh-amd64-5.6.2-3 are available under
/ro/zsh-amd64-5.6.2-3. The mountpoint /ro stands for read-only, which is
short yet descriptive.
Perhaps surprisingly, building software with custom prefix values of
e.g. /ro/zsh-amd64-5.6.2-3 is widely supported, thanks to:
Linux distributions, which build software with prefix set to /usr,
whereas FreeBSD (and the autotools default), which build with prefix set to
/usr/local.
Enthusiast users in corporate or research environments, who install software
into their home directories.
Because using a custom prefix is a common scenario, upstream awareness for
prefix-correctness is generally high, and the rarely required patch will be
quickly accepted.
Key idea: exchange directories
Software packages often exchange data by placing or locating files in well-known
directories. Here are just a few examples:
zsh(1)
locates executable programs via PATH components such as /bin
In distri, these locations are called exchange directories and are provided
via FUSE in /ro.
Exchange directories come in two different flavors:
global. The exchange directory, e.g. /ro/share, provides the union of the
share sub directory of all packages in the package store.
Global exchange directories are largely used for compatibility, see
below.
per-package. Useful for tight coupling: e.g. irssi(1)
does not provide any ABI guarantees, so plugins such as irssi-robustirc
can declare that they want
e.g. /ro/irssi-amd64-1.1.1-1/out/lib/irssi/modules to be a per-package
exchange directory and contain files from their lib/irssi/modules.
Search paths sometimes need to be fixed
Programs which use exchange directories sometimes use search paths to access
multiple exchange directories. In fact, the examples above were taken from gcc(1)
’s INCLUDEPATH, man(1)
’s MANPATH and zsh(1)
’s PATH. These are
prominent ones, but more examples are easy to find: zsh(1)
loads completion functions from its FPATH.
Some search path values are derived from --datadir=/ro/share and require no
further attention, but others might derive from
e.g. --prefix=/ro/zsh-amd64-5.6.2-3/out and need to be pointed to an exchange
directory via a specific command line flag.
FHS compatibility
Global exchange directories are used to make distri provide enough of the
Filesystem Hierarchy Standard
(FHS) that
third-party software largely just works. This includes a C development
environment.
I successfully ran a few programs from their binary packages such as Google
Chrome, Spotify, or Microsoft’s Visual Studio Code.
distri’s package manager is extremely fast. Its main bottleneck is typically the network link, even at high speed links (I tested with a 100 Gbps link).
Its speed comes largely from an architecture which allows the package manager to
do less work. Specifically:
Package images can be added atomically to the package store, so we can safely
skip fsync(2)
. Corruption will be cleaned up
automatically, and durability is not important: if an interactive
installation is interrupted, the user can just repeat it, as it will be fresh
on their mind.
Because all packages are co-installable thanks to separate hierarchies, there
are no conflicts at the package store level, and no dependency resolution (an
optimization problem requiring SAT
solving) is required at all.
In exchange directories, we resolve conflicts by selecting the package with the
highest monotonically increasing distri revision number.
distri proves that we can build a useful Linux distribution entirely without
hooks and triggers. Not having to
serialize hook execution allows us to download packages into the package
store with maximum concurrency.
Because we are using images instead of archives, we do not need to unpack
anything. This means installing a package is really just writing its package
image and metadata to the package store. Sequential writes are typically the
fastest kind of storage usage pattern.
Fast installation also make other use-cases more bearable, such as creating disk
images, be it for testing them in qemu(1)
, booting
them on real hardware from a USB drive, or for cloud providers such as Google
Cloud.
Fast package builder
Contrary to how distribution package builders are usually implemented, the
distri package builder does not actually install any packages into the build
environment.
Instead, distri makes available a filtered view of the package store (only
declared dependencies are available) at /ro in the build environment.
This means that even for large dependency trees, setting up a build environment
happens in a fraction of a second! Such a low latency really makes a difference
in how comfortable it is to iterate on distribution packages.
Package stores
In distri, package images are installed from a remote package store into the
local system package store /roimg, which backs the /ro mount.
A package store is implemented as a directory of package images and their
associated metadata files.
You can easily make available a package store by using distri export.
To provide a mirror for your local network, you can periodically distri update
from the package store you want to mirror, and then distri export your local
copy. Special tooling (e.g. debmirror in Debian) is not required because
distri install is atomic (and update uses install).
Producing derivatives is easy: just add your own packages to a copy of the
package store.
The package store is intentionally kept simple to manage and distribute. Its
files could be exchanged via peer-to-peer file systems, or synchronized from an
offline medium.
distri’s first release
distri works well enough to demonstrate the ideas explained above. I have
branched this state into branch
jackherer, distri’s first
release code name. This way, I can keep experimenting in the distri repository
without breaking your installation.
From the branch contents, our autobuilder creates:
Right now, distri is mainly a vehicle for my spare-time Linux distribution
research. I don’t recommend anyone use distri for anything but research, and
there are no medium-term plans of that changing. At the very least, please
contact me before basing anything serious on distri so that we can talk about
limitations and expectations.
I expect the distri project to live for as long as I have blog posts to publish,
and we’ll see what happens afterwards. Note that this is a hobby for me: I will
continue to explore, at my own pace, parts that I find interesting.
My hope is that established distributions might get a useful idea or two from
distri.
There’s more to come: subscribe to the distri feed
I don’t want to make this post too long, but there is much more!
Please subscribe to the following URL in your feed reader to get all posts about
distri:
One of the most awesome helpers I carry around in my ~/bin since
the early '00s is the
sanity.pl
script written by Andreas Gohr. It just recently came back to use
when I started to archive some awesome Corona enforced live
session music with youtube-dl.
Update:
Francois Marier pointed out that Debian contains the
detox
package, which has a similar functionality.
This is a follow-up from the blog post of Russel as seen here: https://etbe.coker.com.au/2020/10/13/first-try-gnocchi-statsd/. There’s a bunch of things he wrote which I unfortunately must say is inaccurate, and sometimes even completely wrong. It is my point of view that none of the reported bugs are helpful for anyone that understand Gnocchi and how to set it up. It’s however a terrible experience that Russell had, and I do understand why (and why it’s not his fault). I’m very much open on how to fix this on the packaging level, though some things aren’t IMO fixable. Here’s the details.
1/ The daemon startups
First of all, the most surprising thing is when Russell claimed that there’s no startup scripts for the Gnocchi daemons. In fact, they all come with both systemd and sysv-rc support:
# ls /lib/systemd/system/gnocchi-api.service /lib/systemd/system/gnocchi-api.service # /etc/init.d/gnocchi-api /etc/init.d/gnocchi-api
Russell then tried to start gnocchi-api without the good options that are set in the Debian scripts, and not surprisingly, this failed. Russell attempted to do what was in the upstream doc, which isn’t adapted to what we have in Debian (the upstream doc is probably completely outdated, as Gnocchi is unfortunately not very well maintained upstream).
The bug #972087 is therefore, IMO not valid.
2/ The database setup
By default for all things OpenStack in Debian, there are some debconf helpers using dbconfig-common to help users setup database for their services. This is clearly for beginners, but that doesn’t prevent from attempting to understand what you’re doing. That is, more specifically for Gnocchi, there are 2 databases: one for Gnocchi itself, and one for the indexer, which not necessarily is using the same backend. The Debian package already setups one database, but one has to do it manually for the indexer one. I’m sorry this isn’t well enough documented.
Now, if some package are supporting sqlite as a backend (since most things in OpenStack are using SQLAlchemy), it looks like Gnocchi doesn’t right now. This is IMO a bug upstream, rather than a bug in the package. However, I don’t think the Debian packages are to be blame here, as they simply offer a unified interface, and it’s up to the users to know what they are doing. SQLite is anyway not a production ready backend. I’m not sure if I should close #971996 without any action, or just try to disable the SQLite backend option of this package because it may be confusing.
3/ The metrics UUID
Russell then thinks the UUID should be set by default. This is probably right in a single server setup, however, this wouldn’t work setting-up a cluster, which is probably what most Gnocchi users will do. In this type of environment, the metrics UUID must be the same on the 3 servers, and setting-up a random (and therefore different) UUID on the 3 servers wouldn’t work. So I’m also tempted to just close #972092 without any action on my side.
4/ The coordination URL
Since Gnocchi is supposed to be setup with more than one server, as in OpenStack, having an HA setup is very common, then a backend for the coordination (ie: sharing the workload) must be set. This is done by setting an URL that tooz understand. The best coordinator being Zookeeper, something like this should be set by hand:
coordination_url=zookeeper://192.168.101.2:2181/
Here again, I don’t think the Debian package is to be blamed for not providing the automation. I would however accept contributions to fix this and provide the choice using debconf, however, users would still need to understand what’s going on, and setup something like Zookeeper (or redis, memcache, or any other backend supported by tooz) to act as coordinator.
5/ The Debconf interface cannot replace a good documentation
… and there’s not so much I can do at my package maintainer level for this.
Russell, I’m really sorry for the bad user experience you had with Gnocchi. Now that you know a little big more about it, maybe you can have another go? Sure, the OpenStack telemetry system isn’t an easy to understand beast, but it’s IMO worth trying. And the recent versions can scale horizontally…
Note that since I am making a public website available over Tor, I do not
need the location of the website to be hidden and so I used the same
settings as
Cloudflare in their
public Tor proxy.
Also, I explicitly used the external IPv6 address of my server in the
configuration in order to prevent localhost
bypasses.
After restarting the Tor daemon to reload the configuration file:
and configured my Apache vhosts in /etc/apache2/sites-enabled/www.conf:
<VirtualHost *:443>
ServerName fmarier.org
ServerAlias ixrdj3iwwhkuau5tby5jh3a536a2rdhpbdbu6ldhng43r47kim7a3lid.onion
Protocols h2, http/1.1
Header set Onion-Location "http://ixrdj3iwwhkuau5tby5jh3a536a2rdhpbdbu6ldhng43r47kim7a3lid.onion%{REQUEST_URI}s"
Header set alt-svc 'h2="ixrdj3iwwhkuau5tby5jh3a536a2rdhpbdbu6ldhng43r47kim7a3lid.onion:443"; ma=315360000; persist=1'
Header add Strict-Transport-Security: "max-age=63072000"
Include /etc/fmarier-org/www-common.include
SSLEngine On
SSLCertificateFile /etc/letsencrypt/live/fmarier.org/fullchain.pem
SSLCertificateKeyFile /etc/letsencrypt/live/fmarier.org/privkey.pem
</VirtualHost>
<VirtualHost *:80>
ServerName fmarier.org
Redirect permanent / https://fmarier.org/
</VirtualHost>
<VirtualHost *:80>
ServerName ixrdj3iwwhkuau5tby5jh3a536a2rdhpbdbu6ldhng43r47kim7a3lid.onion
Include /etc/fmarier-org/www-common.include
</VirtualHost>
Note that /etc/fmarier-org/www-common.include contains all of the
configuration options that are common to both the HTTP and the HTTPS sites
(e.g. document root, caching headers, aliases, etc.).
$ whois 2a0b:f4c2:2::1
...
inet6num: 2a0b:f4c2::/40
netname: MK-TOR-EXIT
remarks: -----------------------------------
remarks: This network is used for Tor Exits.
remarks: We do not have any logs at all.
remarks: For more information please visit:
remarks: https://www.torproject.org
which indicates that the first request was not using the .onion
address.
A new package arrived on CRAN a few days ago. It offers a few headers files which wrap (parts) of the C API for R, but in a form that may be a little easier to use for C++ programmers. I have always liked how in Rcpp we offer good parts of the standalone R Math library in a namespace R::. While working recently with a particular C routine (for checking non-ASCII characters that will be part of the next version of the dang package which collecting various goodies in one place), I realized there may be value in collecting a few more such wrappers. So I started a few simple ones starting from simple examples.
Currently we have five headers defines.h, globals.h, internals.h, math.h, and shield.h. The first four each correpond to an R header file of the same or similar name, and the last one brings a simple yet effective alternative to PROTECT and UNPROTECT from Rcpp (in a slightly simplified way). None of the headers are “complete”, for internals.h in particular a lot more could be added (as I noticed today when experimenting with another source file that may be converted). All of the headers can be accessed with a simple #include <tidyCpp> (which, following another C++ convention, does not have a .h or .hpp suffix). And a the package ships these headers, packages desiring to use them only need LinkingTo: tidyCpp.
As usage examples, we (right now) have four files in the snippets/ directory of the package. Two of these, convolveExample.cpp and dimnamesExample.cpp both illustrate how one could change example code from Writing R Extensions. Then there are also a very simple defineExample.cpp and a shieldExample.cpp illustrating how much easier Shield() is compared to PROTECT and UNPROTECT.
Over time, I expect to add more definitions and wrappers. Feedback would be welcome—it seems to hit a nerve already as it currently has more stars than commits even though (prior to this post) I had yet to tweet or blog about it. Please post comments and suggestions at the GitHub repo.
Last weekend, Tim Burgess’s twitter listening party covered The Cure’s short, dark 1982 album “Pornography”. I realised I’d never actually played the record, which I picked up a couple of years ago from a shop in the Grainger Market which is sadly no longer there. It was quite a wallet-threatening shop so perhaps it’s a good thing it’s gone.
Monday was a dreary, rainy day which seemed the perfect excuse to put it on. It’s been long enough since I last listened to my CD copy of the album that there were a few nice surprises to rediscover. The closing title track sounded quite different to how I remembered it, with Robert Smith’s vocals buried deeper in the mix, but my memory might be mixing up a different session take.
Truly a fitting closing lyric for our current times: I must fight this sickness /
Find a cure
I've released version 1.0.0 of plocate, my faster locate(1)!
(Actually, I'm now at 1.0.2, after some minor fixes and
improvements.) It has a new build system, portability fixes,
man pages, support for case-insensitive searches (still quite fast),
basic and extended regex searches (as slow as mlocate)
and a few other options. The latter two were mostly to increase mlocate
compatibility, not because I think either is very widely used.
That, and supporting case-insensitive searches was an interesting
problem in its own right :-)
It now also has a small home page
with tarballs. And access() checking is also now asynchronous via io_uring
via a small trick (assuming Linux 5.6 or newer, it can run an
asynchronous statx() to prime the cache, all but guaranteeing
that the access() call itself won't lead to I/O), speeding up
certain searches on non-SSDs even more.
There's also a Debian package in NEW.
In short, plocate now has grown up, and it wants to be your
default locate. I've considered replacing mlocate's updatedb
as well, but it's honestly not a space I want to be in right
now; it involves so much munging with special cases caused
by filesystem restrictions and the likes.
Bug reports, distribution packages and all other feedback
welcome!
I’ve been investigating the options for tracking system statistics to diagnose performance problems. The idea is to track all sorts of data about the system (network use, disk IO, CPU, etc) and look for correlations at times of performance problems. DataDog is pretty good for this but expensive, it’s apparently based on or inspired by the Etsy Statsd. It’s claimed that the gnocchi-statsd is the best implementation of the protoco used by the Etsy Statsd, so I decided to install that.
I use Debian/Buster for this as that’s what I’m using for the hardware that runs KVM VMs. Here is what I did:
# it depends on a local MySQL database
apt -y install mariadb-server mariadb-client
# install the basic packages for gnocchi
apt -y install gnocchi-common python3-gnocchiclient gnocchi-statsd uuid
In the Debconf prompts I told it to “setup a database” and not to manage keystone_authtoken with debconf (because I’m not doing a full OpenStack installation).
This gave a non-working configuration as it didn’t configure the MySQL database for the [indexer] section and the sqlite database that was configured didn’t work for unknown reasons. I filed Debian bug #971996 about this [1]. To get this working you need to edit /etc/gnocchi/gnocchi.conf and change the url line in the [indexer] section to something like the following (where the password is taken from the [database] section).
Here’s an official page about how to operate Gnocchi [3]. The main thing I got from this was that the following commands need to be run from the command-line (I ran them as root in a VM for test purposes but would do so with minimum privs for a real deployment).
gnocchi-api
gnocchi-metricd
To communicate with Gnocchi you need the gnocchi-api program running, which uses the uwsgi program to provide the web interface by default. It seems that this was written for a version of uwsgi different than the one in Buster. I filed Debian bug #972087 with a patch to make it work with uwsgi [4]. Note that I didn’t get to the stage of an end to end test, I just got it to basically run without error.
After getting “gnocchi-api” running (in a terminal not as a daemon as Debian doesn’t seem to have a service file for it), I ran the client program “gnocchi” and then gave it the “status” command which failed (presumably due to the metrics daemon not running), but at least indicated that the client and the API could communicate.
Then I ran the “gnocchi-metricd” and got the following error:
2020-10-12 14:59:30,491 [9037] ERROR gnocchi.cli.metricd: Unexpected error during processing job
Traceback (most recent call last):
File "/usr/lib/python3/dist-packages/gnocchi/cli/metricd.py", line 87, in run
self._run_job()
File "/usr/lib/python3/dist-packages/gnocchi/cli/metricd.py", line 248, in _run_job
self.coord.update_capabilities(self.GROUP_ID, self.store.statistics)
File "/usr/lib/python3/dist-packages/tooz/coordination.py", line 592, in update_capabilities
raise tooz.NotImplemented
tooz.NotImplemented
At this stage I’ve had enough of gnocchi. I’ll give the Etsy Statsd a go next.
Update
Thomas has responded to this post [5]. At this stage I’m not really interested in giving Gnocchi another go. There’s still the issue of the indexer database which should be different from the main database somehow and sqlite (the config file default) doesn’t work.
I expect that if I was to persist with Gnocchi I would encounter more poorly described error messages from the code which either don’t have Google hits when I search for them or have Google hits to unanswered questions from 5+ years ago.
The Gnocchi systemd config files are in different packages to the programs, this confused me and I thought that there weren’t any systemd service files. I had expected that installing a package with a daemon binary would also get the systemd unit file to match.
The cluster features of Gnocchi are probably really good if you need that sort of thing. But if you have a small instance (EG a single VM server) then it’s not needed. Also one of the original design ideas of the Etsy Statsd was that UDP was used because data could just be dropped if there was a problem. I think for many situations the same concept could apply to the entire stats service.
If the other statsd programs don’t do what I need then I may give Gnocchi another go.
Welcome to gambaru.de. Here is my monthly report (+ the first week in October) that covers what I have been doing for Debian. If you’re interested in Java, Games and LTS topics, this might be interesting for you.
Debian Games
I spent most of the time this month to tackle remaining GCC 10 bugs in packages like nettoe, pcsxr, slimevolley (patch by Reiner Herrmann), openal-soft, slashem and alien-arena. I also investigated a build failure in gfpoken (#957271) and springlobby and finally uploaded a new revision of warzone2100 to address another FTBFS while building the PDF documentation.
and sponsored a new release of mgba for Ryan Tandy.
Debian Java
The focus was on two major packages this month, PDFsam, a tool to manipulate PDF files and Netbeans, one of the three well known Java IDEs. I basically updated every PDFsam related sejda dependency and packaged a new library libsejda-common-java, which is currently waiting in the NEW queue. As soon as this one has been approved, we should be able to see the latest release in Debian soon.
Unfortunately I came to the conclusion that maintaining Netbeans in Debian is no longer a viable solution. I have been the sole maintainer for the past five years and managed to package the basic Java IDE in Stretch. I also had a 98% ready package for Buster but there were some bugs that made it unfit for a stable release in my opinion. The truth is, it takes a lot of time to patch Netbeans, just to make the build system DFSG compliant and to build the IDE from source. We have never managed to provide more functionality than the basic Java IDE features too. Still, we had to maintain dozens of build-dependencies and there was a constant struggle to make everything work with just a single version of a library. While the Debian way works great for most common projects, it doesn’t scale very well for very complex ones like Java IDEs. Neither Eclipse nor Netbeans are really fully maintainable in Debian since they consist of hundreds of different jar files, even if the toolchain was perfect, it would require too much time to maintain all those Debian packages.
I voiced that sentiment on our debian-java mailinglist while also discussing the situation of complex server packages like Apache Solr. Similar to Netbeans it requires hundreds of jar files to get running. I believe our users are better served in those cases by using tools like flatpak for desktop packages or jdeb for server packages. The idea is to provide a Debian toolchain which would download a source package from upstream and then use jdeb to create a Debian package. Thus we could provide packages for very complex Java software again, although only via the Debian contrib distribution. The pros are: software is available as Debian packages and integrates well with your system and considerably less time is needed to maintain such packages: Cons: not available in Debian main, no security support, not checked for DFSG compliance.
Should we do that for all of our packages? No. This should really be limited to packages that otherwise would not be in Debian at all and are too complex to maintain, when even a whole team of normal contributors would struggle.
Finally the consequences were: the Netbeans IDE has been removed from Debian main but the Netbeans platform package, libnb-platform18-java, is up-to-date again just like visualvm, which depends on it.
I eventually filed a RFA for privacybadger. As I mentioned in my last post, the upstream maintainer would like to see regular updates in Debian stable but I don’t want to regularly contribute time for this task. If someone is ready for the job, let me know.
This was my 55. month as a paid contributor and I have been paid to work 31,75 hours on Debian LTS, a project started by Raphaël Hertzog. In that time I did the following:
Investigated and fixed a regression in squid3 when using the icap server. (#965012)
DLA-2394-1. Issued a security update for squid3 fixing 4 CVE.
DLA-2400-1. Issued a security update for activemq fixing 1 CVE.
DLA-2403-1. Issued a security update for rails fixing 1 CVE.
DLA-2404-1. Issued a security update for eclipse-wtp fixing 1 CVE.
DLA-2405-1. Issued a security update for httpcomponents-client fixing 1 CVE.
Triaged open CVE for guacamole-server and guacamole-client and prepared patches for CVE-2020-9498 and CVE-2020-9497.
Prepared patches for 7 CVE in libonig.
ELTS
Extended Long Term Support (ELTS) is a project led by Freexian to further extend the lifetime of Debian releases. It is not an official Debian project but all Debian users benefit from it without cost. The current ELTS release is Debian 8 „Jessie“. This was my 28. month and I have been paid to work 15 hours on ELTS.
ELA-291-1. Issued a security update for libproxy fixing 1 CVE.
ELA-294-1. Issued a security update for squid3 fixing 4 CVE.
ELA-295-1. Issued a security update for rails fixing 2 CVE.
ELA-296-1. Issued a security update for httpcomponents-client fixing 1 CVE.
I wanted to share Type design issue I hit recently with Striot.
Within StrIoT you define a stream-processing program, which is a series of
inter-connected operators, in terms of a trio of graph types:
The outer-most type is a higher-order type provided by the Graph library we
use: Graph a. This layer deals with all the topology concerns: what is
connected to what.
The next type we define in StrIoT: StreamVertex, which is used to replace
a in the above and make the concrete type Graph StreamVertex. Here we
define all the properties of the operators. For example: the parameters supplied
to the operator, and a unique vertexID integer that is unfortunately necessary.
We also define which operator type each node represents, with an
instance of the third type,
For some recent work I needed to define some additional properties for the
operators: properties that would be used in a M/M/1 model (Jackson network) to
represent the program do some cost modelling with. Initially we supplied this
additional information in completely separate instances of types: e.g. lists
of tuples, the first of a pair representing a vertexID, etc. This was mostly
fine for totally novel code, but where I had existing code paths that operated
in terms of Graph StreamVertex and now needed access to these parameters, it
would have meant refactoring a lot of code. So instead, I added these properties
directly to the types above.
Some properties are appropriate for all node types, e.g. mean average service time.
In that case, I added the parameter to the StreamVertex type:
data StreamVertex = StreamVertex
{ vertexId :: Int
…
, serviceTime:: Double
}
Other parameters were only applicable to certain node types. Mean average
arrival rate, for example., is only valid for Source node types;
selectivity is appropriate only for filter types. So, I added these to the
StreamOperator type:
This works pretty well, and most of the code paths that already exist did not
need to be updated in order for the model parameters to pass through to where
they are needed. But it was not a perfect solution, because I now had to modify
some other, unrelated code to account for the type changes.
Mostly this was test code: where I'd defined instances of Graph StreamVertex
to test something unrelated to the modelling work, I now had to add filter
selectivities and source arrival rates. This was tedious but mostly solved with
automatically with some editor macros.
One area though, that was a problem, was equality checks and pattern matching.
Before this change, I had a few areas of code like this
if Source == operator (head (vertexList sg))
…
if a /= b then… -- where a and b are instances of StreamOperator
I had to replace them with little helper routines like
cmpOps :: StreamOperator -> StreamOperator -> Bool
cmpOps (Filter _) (Filter _) = True
cmpOps (FilterAcc _) (FilterAcc _) = True
cmpOps x y = x == y
A similar problem was where I needed to synthesize a Filter, and I didn't care
about the selectivity, indeed, it was meaningless for the way I was using the type.
I have a higher-level function that handles "hoisting" an Operator through a Merge:
So, before, you have some operator occurring after a merge operation, and afterwards,
you have several instances of the operator on all of the input streams prior to the
Merge. Invoking it now looks like this
filterMerge = pushOp (Filter 0)
It works, the "0" is completely ignored, but the fact I have to provide it, and it's
unneeded, and there is no sensible value for it, is a bit annoying.
I think there's some interesting things to consider here about Type design, especially
when you have some aspects of a "thing" which are relevant only in some contexts and
not others.
The first time Linda Tirado came to the viral attention of the Internet
was in 2013 when she responded to a forum question: "Why do poor people do
things that seem so self-destructive?" Here are some excerpts from her
virally popular five-page response, which is included in the first
chapter:
I know how to cook. I had to take Home Ec. to graduate high school.
Most people on my level didn't. Broccoli is intimidating. You have
to have a working stove, and pots, and spices, and you'll have to do
the dishes no matter how tired you are or they'll attract bugs. It is
a huge new skill for a lot of people. That's not great, but it's
true. And if you fuck it up, you could make your family sick. We
have learned not to try too hard to be middle class. It never works
out well and always makes you feel worse for having tried and failed
yet again. Better not to try. It makes more sense to get food that
you know will be palatable and cheap and that keeps well. Junk food
is a pleasure that we are allowed to have; why would we give that up?
We have very few of them.
and
I smoke. It's expensive. It's also the best option. You see, I am
always, always exhausted. It's a stimulant. When I am too tired to
walk one more step, I can smoke and go for another hour. When I am
enraged and beaten down and incapable of accomplishing one more thing,
I can smoke and I feel a little better, just for a minute. It is the
only relaxation I am allowed. It is not a good decision, but it is
the only one that I have access to. It is the only thing I have found
that keeps me from collapsing or exploding.
This book is an expansion on that essay. It's an entry in a growing genre
of examinations of what it means to be poor in the United States in the
21st century. Unlike most of those examinations, it isn't written by an
outsider performing essentially anthropological field work. It's one of
the rare books written by someone who is herself poor and had the
combination of skill and viral fame required to get an opportunity to talk
about it in her own words.
I haven't had it worse than anyone else, and actually, that's kind of
the point. This is just what life is for roughly a third of the
country. We all handle it in our own ways, but we all work in the
same jobs, live in the same places, feel the same sense of never quite
catching up. We're not any happier about the exploding welfare rolls
than anyone else is, believe me. It's not like everyone grows up and
dreams of working two essentially meaningless part-time jobs while
collecting food stamps. It's just that there aren't many other
options for a lot of people.
I didn't find this book back in 2014 when it was published. I found it in
2020 during Tirado's second round of Internet fame: when the police shot
out her eye with "non-lethal" rounds while she was covering the George
Floyd protests as a photojournalist. In characteristic fashion, she
subsequently reached out to the other people who had been blinded by the
police, used her temporary fame to organize crowdfunded support for
others, and is planning on having "try again" tattooed over the scar.
That will give you a feel for the style of this book. Tirado is blunt,
opinionated, honest, and full speed ahead. It feels weird to call this
book delightful since it's fundamentally about the degree to which the
United States is failing a huge group of its citizens and making their
lives miserable, but there is something so refreshing and clear-headed
about Tirado's willingness to tell you the straight truth about her life.
It's empathy delivered with the subtlety of a brick, but also with about
as much self-pity as a brick. Tirado is not interested in making you feel
sorry for her; she's interested in you paying attention.
I don't get much of my own time, and I am vicious about protecting
it. For the most part, I am paid to pretend that I am inhuman, paid
to cater to both the reasonable and unreasonable demands of the
general public. So when I'm off work, feel free to go fuck yourself.
The times that I am off work, awake, and not taking care of life's
details are few and far between. It's the only time I have any
autonomy. I do not choose to waste that precious time worrying about
how you feel. Worrying about you is something they pay me for; I
don't work for free.
If you've read other books on this topic (Emily Guendelsberger's
On the Clock is still the best of those
I've read), you probably won't get many new facts from Hand to
Mouth. I think this book is less important for the policy specifics than
it is for who is writing it (someone who is living that life and can be
honest about it) and the depth of emotional specifics that Tirado brings
to the description. If you have never been poor, you will learn the
details of what life is like, but more significantly you'll get a feel for
how Tirado feels about it, and while this is one individual perspective
(as Tirado stresses, including the fact that, as a white person, there are
other aspects of poverty she's not experienced), I think that perspective
is incredibly valuable.
That said, Hand to Mouth provides even more reinforcement of the
importance of universal medical care, the absurdity of not including
dental care in even some of the more progressive policy proposals, and the
difficulties in the way of universal medical care even if we solve the
basic coverage problem. Tirado has significant dental problems due to
unrepaired damage from a car accident, and her account reinforces my
belief that we woefully underestimate how important good dental care is to
quality of life. But providing universal insurance or access is only the
start of the problem.
There is a price point for good health in America, and I have rarely
been able to meet it. I choose not to pursue treatment if it will
cost me more than it will gain me, and my cost-benefit is done in more
than dollars. I have to think of whether I can afford any potential
treatment emotionally, financially, and timewise. I have to sort out
whether I can afford to change my life enough to make any treatment
worth it — I've been told by more than one therapist that I'd be fine
if I simply reduced the amount of stress in my life. It's true,
albeit unhelpful. Doctors are fans of telling you to sleep and eat
properly, as though that were a thing one can simply do.
That excerpt also illustrates one of the best qualities of this book. So
much writing about "the poor" treats them as an abstract problem that the
implicitly not-poor audience needs to solve, and this leads rather
directly to the endless moralizing as "we" attempt to solve that problem
by telling poor people what they need to do. Tirado is unremitting in
fighting for her own agency. She has a shitty set of options, but within
those options she makes her own decisions. She wants better options and
more space in which to choose them, which I think is a much more
productive way to frame the moral argument than the endless hand-wringing
over how to help "those poor people."
This is so much of why I support universal basic income. Just give people
money. It's not all of the solution — UBI doesn't solve the problem of
universal medical care, and we desperately need to find a way to make work
less awful — but it's the most effective thing we can do immediately.
Poor people are, if anything, much better at making consequential
financial decisions than rich people because they have so much more
practice. Bad decisions are less often due to bad decision-making than
bad options and the balancing of objectives that those of us who are not
poor don't understand.
Hand to Mouth is short, clear, refreshing, bracing, and, as you
might have noticed, very quotable. I think there are other books in this
genre that offer more breadth or policy insight, but none that have the
same feel of someone cutting through the bullshit of lazy beliefs and
laying down some truth. If any of the above excerpts sound like the sort
of book you would enjoy reading, pick this one up.
More than a month has passed since my last KDE/Plasma for Debian update, but things are progressing nicely.
OBS packages
On the OBS side, I have updated the KDE Apps to 20.08.2, and the KDE Frameworks to 5.75. Especially the update of apps brings in at least a critical security fix.
Concerning the soon to be released Plasma 5.20, packages are more or less ready, but as reported here we have to wait for Qt 5.15 to be uploaded to unstable, which is also planned in the near future.
Debian main packages
Uploads of Plasma 5.19.4 to Debian/experimental are processing nicely, more than half the packages are already done, and the rest is ready to go. What holds us back is the NEW queue, as usual.
We (Scarlett, Patrick, me) hope to have everything through NEW and in experimental as soon as possible, followed by an upload of probably Plasma 5.19.5 to Debian/unstable.
Thanks also to Lisandro for accepting me into the Salsa Qt/KDE team.
This month for our book club Daniel, Lars, Vince and I read Hardcoded secrets, unverified tokens, and other common JWT mistakes which wasn’t quite what we’d thought when it was picked. We had been expecting an analysis of JSON web tokens themselves as several us had been working in the area and had noticed various talk about problems with the standard but instead the article is more a discussion of the use of semgrep to find and fix common issues, using issues with JWT as examples.
We therefore started off with a bit of a discussion of JWT, concluding that the underlying specification was basically fine given the problem to be solved but that as with any security related technology there were plenty of potential pitfalls in implementation and that sadly many of the libraries implementing the specification make it far too easy to make mistakes such as those covered by the article through their interface design and defaults. For example interfaces that allow interchangable use of public keys and shared keys are error prone, as is is making it easy to access unauthenticated data from tokens without clearly flagging that it is unauthenticated. We agreed that the wide range of JWT implementations available and successfully interoperating with each other is a sign that JWT is getting something right in providing a specification that is clear and implementable.
Moving on to semgrep we were all very enthusiastic about the technology, language independent semantic matching with a good set of rules for a range of languages available. Those of us who work on the Linux kernel were familiar with semantic matching and patching as implemented by Coccinelle which has been used quite successfully for years to both avoiding bad patterns in code and making tree wide changes, as demonstrated by the article it is a powerful technique. We were impressed by the multi-language support and approachability of semgrep, with tools like their web editor seeming particularly helpful for people getting started with the tool, especially in conjunction with the wide range of examples available.
This was a good discussion (including the tangential discussions of quality problems we had all faced dealing with software over the years, depressing though those can be) and semgrep was a great tool to learn about, I know I’m going to be using it for some of my projects.
Last year, my intent had been to post monthy updates with details of the F/LOSS
contributions I had made during the previous month. I wanted to do this as a
way to summarize and reflect on what I had done, and also to hopefully
motivate me to do more.
Fast forward, and it's been over a year since my last blog post. So much for
those plans.
I won't go into specific detail about the F/LOSS contributions I've made in the
past year. This isn't meant to be a "catch-up" post, per se. It's more of an
acknowledgement that I didn't do what I set out to do, as well as something
of a reset to enable me to continue blogging (or not) as I see fit.
So, to summarize those contributions:
As expected, most of my contributions were to projects that I regularly
contribute to, like Debian, Apache Axis2/C, or PasswordSafe.
There were also some one-off contributions to projects that I use but am not
actively involved in, such as log4cxx or PyKAN.
There was also a third category of contributions that are a bit of a special
case. I made some pseudonymous contributions to a F/LOSS project that I did
not want to tie to my public identity. I hope to write more about that
situation in a future post.
All in all, I'm pretty happy with the contributions I've made in the
past year. Historically, my F/LOSS activity had been somewhat sporadic,
sometimes with months passing in between contributions. But looking through
my notes from the past year, it appears that I made contributions every single
month, with no skipped months. Of course, I would have liked to have done more,
but I consider the improvement in consistency to be a solid win.
As for the blog, well... Judging by the most recent year-long gap (as well as
the gaps before that), I'm not likely to start regularly writing posts anytime
soon. But then again, if sporadic F/LOSS contribtutions can turn into
regular F/LOSS contributions, then maybe sporadic blog posts can turn into
regular blog posts, too. Time will tell.
Salsa CI aims at improving the Debian packaging lifecycle by delivering
Continuous Integration fully compatible with Debian packaging.
The main Salsa CI's project is the
pipeline, that builds
packages and run different tests after every git push to Salsa.
The pipeline makes it possible to have a quick and early feedback about any
issues the new changes may have created or solved, without the need to upload
to the archive.
All of the pipeline jobs run on amd64 architecture, but the Salsa CI Team has
recently added support to build packages also on i386 architecture.
This work started during the Salsa CI Sprint at DebConf20 after the
"Where is Salsa CI right now" talk,
and required different changes at the core of pipeline to make it possible.
For more details, this is the related merge request:
https://salsa.debian.org/salsa-ci-team/pipeline/-/merge_requests/256
If you have any questions, you can contact the Salsa CI Team at the #salsaci
channel on irc.oftc.net
So, a bit more thank 18 months ago, I started a new adventure.
After a few flights with a friend of mine in a Robin DR400 and
Jodel aircrafts, I enlisted in a local flight club at the Lognes
airfield (LFPL), and started a Pilot Private License training. A
PPL is an international flight license for non commercial
operations. Associated with a qualification like the SEP (Single
Engine Piston), it enables you to fly basically anywhere in the
world (or at least anywhere where French is spoken by the air
traffic controllers) with passengers, under Visual Flight Rules
(VFR).
A bit like with cars, training has two parts, theoretical and
practical, both validated in a test. You don't have to pass the
theoretical test before starting the practical training, and it's
actually recommended to do both in parallel, especially since
nowadays most of the theoretical training is done online (you still
have to do 10h of in-person courses before taking the test).
So in March 2019 I started both trainings. Theoretical training is
divided in various domains, like regulations, flight mechanics,
meteorology, human factors etc. and you can obviously train in
parallel. Practical is more sequential and starts with basic flight
training (turns, climbs, descents), then take-off, then landing
configuration, then landing itself. All of that obviously with a
flight instructor sitting next to you (you're on the left seat but
the FI is the “pilot in command”). You then start doing circuit
patterns, meaning you take off, do a circuit around the airfield,
then land on the runway you just took off. Usually you actually
don't do a complete landing but rather touch and go, and do it
again in order to have more and more landing training.
Once you know how to take-off, do a pattern and land when
everything is OK, you start practicing (still with your flight
instructor aboard) various failures: especially engine failures at
take off, but also flaps failure and stuff like that, all that
while still doing patterns and practicing landings. At one point,
the flight instructor deems you ready: he exits the plane, and you
start your first solo flight: engine tests, take off, one pattern,
landing.
For me practical training was done in an Aquila AT-01/A210, which
is a small 2-seater. It's really light (it can actually be used as
an ultralight), empty weight is a bit above 500kg and max weight is
750. It doesn't go really fast (it cruises at around 100 knots, 185
km/h) but it's nice to fly. As it's really lightweight the wind
really shakes it though and it can be a bit hard to land because it
really glides very well (with a lift-to-drag ratio at 14). I tried
to fly a lot in the beginning, so the basic flight training was
done in about 6 months and 23 flight hours. At that point my
instructor stepped out of the plane and I did my first solo flight.
Everything actually went just fine, because we did repeat a lot
before that, so it wasn't even that scary. I guess I will remember
my whole life, as people said, but it was pretty uneventful,
although the controller did scold me a little because when taxiing
back to the parking I misunderstood the instructions and didn't
stop where asked (no runway incursion though).
After the first solo flight, you keep practicing patterns and solo
flights every once in a while, and start doing cross-country
flights: you're not restricted to the local airfields (LFPL, LFAI,
LFPK) but start planning trips to more remote airports, about 30-40
minutes away (for me it was Moret/LFPU, Troyes/LFQB,
Pontoise/LFPT). Cross country flights requires you to plan the
route (draw it on the map, and write a navigation log so you know
what to do when in flight), but also check the weather, relevant
information, especially NOTAMs - Notice To Air Men (I hope someone
rename those Notice to Air Crews at one point), estimate the fuel
needed etc. For me, flight preparation time was between once and
twice the flight time. Early flight preparation is completed on the
day by last-minute checks, especially for weather. During the
briefing (with the flight instructor at first, but for the test
with the flight examiner and later with yourself) you check in turn
every bit of information to decide if you're GO or not for the
flight. As a lot of things in aviation, safety is really paramount
here.
Once you've practiced cross country flight a bit, you start
learning what to do in case of failures during a non-local flights,
for example an engine failure in a middle of nowhere, when you have
to chose a proper field to land, or a radio failure. And again when
you're ready for it (and in case of my local club, once you pass
your theoretical exam) you go for cross-country solo flights (of
the 10h of solo flight required for taking the test, 5h should be
done in cross-country flights). I went again to Troyes (LFQB), then
Dijon-Darois (LFGI) and did a three-legs flight to Chalons-Ecury
(LFQK) and Pont sur Yonne (LFGO).
And just after that, when I was starting to feel ready for the
test, COVID-19 lockdown happened, grounding everyone for a few
months. Even after it was over, I felt a bit rusty and had to take
some more training. I finally took the test in the beginning of
summer, but the first attempt wasn't good enough: I was really
stressed, and maybe not completely ready actually. So a bit more
training during summer, and finally in September I took the final
test part, which was successful this time.
After some paperwork, a new, shiny, Pilot Private License arrived
at my door.
And now that I can fly basically when I want, the autumn is finally
here with bad weather all day long, so actually planning real
flights is a bit tricky. For now I'm still flying solo on familiar
trips, but at some point I should be able to bring a passenger with
me (on the Aquila) and at some point migrate to a four-seaters like
the DR400, ubiquitous in France.
I grew up riding bikes with my friends, but I didn't keep it up once I went to
University. A couple of my friends persevered and are really good riders, even
building careers on their love of riding.
I bought a mountain bike in 2006 (a sort of "first pay cheque" treat after
changing roles) but didn't really ride it all that often until this year. Once
Lockdown began, I started going for early morning rides in order to get some
fresh air and exercise.
Once I'd got into doing that I decided it was finally time to buy a new bike.
I knew I wanted something more like a "hybrid" than a mountain bike but apart
from that I was clueless. I couldn't even name the top manufacturers.
Ross Burton—a friend from the Debian
community—suggested I take a look at Cotic, a small
UK-based manufacturer based in the peak district. Specifically their
Escapade
gravel bike. (A gravel bike, it turns out, is kind-of like a hybrid.)
My new Cotic Escapade
I did some due diligence, looked at some other options, put together a
spreadsheet etc but the Escapade was the clear winner. During the project I
arranged to have a socially distant cup of tea with my childhood friend Dan,
now a professional bike mechanic, who by coincidence arrived on his own Cotic
Escapade. It definitely seemed to tick all the boxes. I just needed to agonise
over the colour choices: Metallic Orange (a Cotic staple) or a Grey with some
subtle purple undertones. I was leaning towards the Grey, but ended up plumping
for the Orange.
I could just cover it under Red Hat UK’s cycle to work scheme. I’m very pleased
our HR dept is continuing to support the scheme, in these times when they also
forbid me from travelling to the office.
And so here we are. I’m very pleased with it! Perhaps I'll write more about
riding, or post some pictures, going forward.
One of the points Flanigan makes in her piece “Seat Belt Mandates and Paternalism” is that we’re conditioned to use seat belts from a very early age. It’s a thing we internalize and build into our understanding of the world. People feel bad when they don’t wear a seat belt.(1) They’re unsettled. They feel unsafe. They feel like they’re doing something wrong.
Masks have started to fit into this model as well. Not wearing a mask feels wrong. An acquaintance shared a story of crying after realizing they had left the house without a mask. For some people, mask wearing has been deeply internalized.
We have regular COVID tests at NYU. Every other week I spit into a tube and then am told whether I am safe or sick. This allows me to hang out with my friends more confident than I would feel otherwise. This allows me to be closer to people than I would be otherwise. It also means that if I got sick, I would know, even if I was asymptomatic. If this happened, I would need to tell my friends. I would trace the places I’ve been, the people I’ve seen, and admit to them that I got sick. I would feel shame because something I did put me in that position.
There were (are?) calls to market mask wearing and COVID protection with the same techniques we use around sex: wear protection, get tested, think before you act, ask consent before touching, be honest and open with the people around you about your risk factors.
This is effective, at least among a swath of the population, but COVID has effectively become another STD. It’s a socially transmitted disease that we have tabooified into creating shame in people who have it.
The problem with this is, of course, that COVID isn’t treatable in the same way syphilis and chlamydia are. Still, I would ask whether people don’t report, or get tested, or even wear masks, because of shame? In some communities, wearing a mask is a sign that you’re sick. It’s stigmatizing.(2)
I think talking about COVID the way we talk about sex is not the right approach because, in my experience, the ways I learned about sex were everything from factually wrong to deeply harmful. If what we’re doing doesn’t work, what does?
(1) Yes, I know not everyone.
(2) Many men who don’t wear masks cite it as feeling emasculating, rather than stigmatizing.
A new RcppSimdJson release arrived on CRAN yesterday bringing along the simdjson 0.5.0 release that happened a few weeks.
RcppSimdJson wraps the fantastic and genuinely impressive simdjson library by Daniel Lemire and collaborators. Via very clever algorithmic engineering to obtain largely branch-free code, coupled with modern C++ and newer compiler instructions, it results in parsing gigabytes of JSON parsed per second which is quite mindboggling. The best-case performance is ‘faster than CPU speed’ as use of parallel SIMD instructions and careful branch avoidance can lead to less than one cpu cycle per byte parsed; see the video of the talk by Daniel Lemire at QCon (also voted best talk).
Beside the upstream update, not too much happened to our package itself since 0.1.1 though Brandon did help one user to seriously speed up his JSON processing. The (this time very short) NEWS entry follows.
Here is the first QSoas quiz ! I recently measured several identical spectra in a row to evaluate the noise of the setup, and so I wanted to average all the spectra and also determine the standard deviation in the absorbances. Averaging the spectra can simply be done taking advantage of the average command:
QSoas> load Spectrum*.dat /flags=spectra
QSoas> average flagged:spectra
However, average does not provide means to make standard deviations, it just takes the average of all but the X column. I wanted to add this feature, but I realized there are already at least two distinct ways to do that...
One that relies simply on average and on apply-formula, and which requires that you remember how to compute standard deviations.
One that is a little more involved, that requires more data manipulation (take a look at contract for instance) and relies on the fact that you can use statistics in apply-formula (and in particular you can use y_stddev to refer to the standard deviation of \(y\)), but which does not require you to know exactly how to compute standard deviations.
To help you, I've added the result in Average.dat. The figure below shows a zoom on the data superimposed to the average (bonus points to find how to display this light red area that corresponds to the standard deviation !).
I will post the answer later. In the meantime, feel free to post your own solutions or attempts, hacks, and so on !
About QSoas
QSoas is a powerful open source data analysis program that focuses on flexibility and powerful fitting capacities. It is released under the GNU General Public License. It is described in Fourmond, Anal. Chem., 2016, 88 (10), pp 5050–5052. Current version is 2.2. You can download its source code or buy precompiled versions for MacOS and Windows there.
I don’t have to mention that 2020 is a special year, so all the normal race plan was out the window, and I was very happy and fortunate to be able to do even one race. And only delayed 3 weeks to write this race report :/ So, here’s the story ☺
Preparing for the race
Because it was a special year, and everything was crazy, I actually managed to do more sports than usual, at least up to end of July. So my fitness, and even body weight, was relatively fine, so I subscribed to the mid-distance race (official numbers: 78km distance, 1570 meters altitude), and then off it went to a proper summer vacation — in a hotel, even.
And while I did do some bike rides during that vacation, from then on my training regime went… just off? I did train, I did ride, I did get significant PRs, but it didn’t “click” anymore. Plus, due to—well, actually not sure what, work or coffee or something—my sleep regime also got completely ruined…
On top of that, I didn’t think about the fact that the race was going to be mid-September, and that high up in the mountains, the weather could have be bad enough (I mean, in 2018 the weather was really bad even in August…) such that I’d need to seriously think about clothing.
Race week
I arrive in Scuol two days before the race, very tired (I think I got only 6 hours of sleep the night before), and definitely not in a good shape. I was feeling bad enough that I was not quite sure I was going to race. At least weather was OK, such that normal summer clothing would suffice. But the race info was mentioning dangerous segments, to be very careful, etc. etc. so I was quite anxious.
Note 1: my wife says, this was not the first time, and likely not the last time that two days before the race I feel like quitting. And as I’m currently on-and-off reading the interesting “The Brave Athlete: Calm the Fuck Down and Rise to the Occasion” book (by Lesley Paterson and Simon Marshall; it’s an interesting book, not sure if I recommend it or not), I am beginning to think that this is my reaction to races where I have “overshot” my usual distance. Or, in general, races where I fear the altitude gain. Not quite sure, but I think it is indeed the actual cause.
So I spend Thursday evening feeling unwell, and thinking I’ll see how Friday goes. Friday comes, and having slept reasonably well entire night, I pick up my race number, then I take another nap in the afternoon - in total, I’ve slept around 13 hours that day. So I felt much better, and was looking forward to the race.
Saturday morning comes, I manage to wake up early, and get ready in time; almost didn’t panic at all that I’m going to be late.
Note 2: my wife also says that this is the usual way I behave. Hence, it must be most of it a mental issue, rather than real physical one ☺
Race
I reach the train station in time, I get on the train, and by the time the train reached Zernez, I fully calm down. There was am entire hour wait though before the race, and it was quite chilly. Of course I didn’t bring anything beside what I was wearing, relying on temperature getting better later in the day.
During the wait, there were two interesting things happening.
First, we actually got there (in Zernez) before the first people from the long distance passed by, both men and women. Seeing them pass by was cool, thinking they already had ~1’200m altitude in just 30-ish kilometres.
The second thing was, as this was the middle and not the shortest distance, the people in the group looked differently than in previous years. More precisely, they were looking very fit, and I was feeling… fat. Well, I am overweight, so it was expected, but I was feeling it even more than usual. I think only one or two in ten people were looking as fit as me or less… And of course, the pictures post-race show me even less “fit-looking” than I thought. Ah, self-deception is a sweet thing…
And yes, we all had to wear masks, up until the last minute. It was interesting, but not actually annoying - and small enough price for being able to race!
Then the race starts, and as opposed to many other years, it starts slow. I didn’t feel that rush of people starting fast, it was… reasonable?
First part of the race (good)
Thus started the first part of the race, on a new route that I was unfamiliar with. There was not too much climbing, to be honest, and there was some tricky single-trail through the woods, with lots of the roots. I actually had to get off the bike and push it, since it was too difficult to pedal uphill on that path. Other than that, I was managing so far to adjust my efforts well enough that my usual problems related to climbing (lower back pain) didn’t yet appear, even as the overall climbed meters were increasing. I was quite happy at that, and had lots of reserves. To my (pleasant) surprise, two positive things happened:
I was never alone, a sign that I wasn’t too far back.
I was passing/being passed by people, both on climbs but also on descents! It’s rare, but I did overtake a few people on a difficult trail downhill.
With all the back and forth, a few people became familiar (or at least their kit), and it was fun seeing who is better uphill vs. downhill.
And second part (not so good)
I finally get to (around) S-chanf, on a very nice but small descent, and on flat roads, and start the normal route for the short race. Something was off though - I knew from past years that these last ~47km have around 700-800m altitude, but I had already done around 1000m. So the promised 1571m were likely to be off, by at least 100-150m. I set myself a new target of 1700m, and adjust my efforts based on that.
And then, like clockwork on the 3:00:00 mark, the route exited the forest, the sun got out of the clouds, and the temperature started to increase from 16-17°C to 26°+, with peaks of 31°C. I’m not joking: at 2:58:43, temp was 16°, at 3:00:00, it was 18°, at 3:05:45, it was 26°. Heat and climbing are my two nemeses, and after having a pretty good race for the first 3 hours and almost exactly 1200m of climbing, I started feeling quite miserable.
Well, it was not all bad. There were some nice stretches of flat, where I knew I can pedal strongly and keep up with other people, until my chain dropped, so I had to stop, re-set it, and lose 2 minutes. Sigh.
But, at least, I was familiar with this race, or so I thought. I completely mis-remembered the last ~20km as a two-punch climb, Guarda and Ftan, whereas it is actually a three-punch one: Guarda, Ardez, and only then Ftan. Doesn’t help that Ardez has the nice ruins that I was remembering and which threw me off.
The saddest part of the day was here, on one of the last climbs - not sure if to Guarda or to Arddez, where a guy overtakes me, and tells me he’s glad he finally caught up with me, he almost got me five or six times (!), but I always managed to break off. Always, until now. Now, this was sad (I was huffing and puffing like a steam locomotive now), but also positive, as I never had that before. One good, one bad?
And of course, it was more than 1’700m altitude, it was 1’816m. And the descent to Scuol shorter and it didn’t end as usual with the small but sharp climb which I just love, due to Covid changes.
But, I finished, and without any actual issues, and no dangerous segments as far as I saw. I was anxious for no good reason…
Conclusion (or confusion?)
So this race was interesting: three hours (to the minute) in which I went 43.5km, climbed 1200m, felt great, and was able to push and push. And then the second part, only ~32km, climbed only 600m, but which felt quite miserable.
I don’t know if it was mainly heat, mainly my body giving up after that much climbing (or time?), or both. But it’s clear that I can’t reliably race for more than around these numbers: 3 hours, ~1000+m altitude, in >20°C temperature.
One thing that I managed to achieve though: except due to the technically complex trail at the beginning where I pushed the bike, I did not ever stop and push the bike uphill because I was too tired. Instead, I managed (badly) to do the switch sitting/standing as much as I could motivate myself, and thus continue pushing uphill. This is an achievement for me, since mentally it’s oh so easy to stop and push the bike, so I was quite glad.
As to the race results, they were quite atrocious:
age category (men), 38 out of 52 finishers, 4h54m, with first finisher doing 3h09m, so 50% slower (!)
overall (men), 138 out of 173 finishers, with first finisher 2h53m.
These results clearly don’t align with my feeling of a good first half of the race, so either it was purely subjective, or maybe in this special year, only really strong people registered for the race, or something else…
One positive aspect though, compared to most other years, was the consistency of my placement (age and overall):
Zuoz: 38 / 141
S-Chanf: 39 / 141
Zernez: 39 / 141
Guarda: 38 / 138
Ftan: 38 / 138
(“next” - whatever this is): 38 / 138
Finish: 38 / 138
So despite all my ranting above, and all the stats I’m pulling out of my own race, it looks like my position in the race was fully settled in the really first part, and I didn’t gain nor lose practically anything afterwards. I did dip one place but then gained it back (on the climb to Guarda, even).
The split times (per-segment rankings) are a bit more variable, and show that I was actually fast on the climbs but losing speed on the descents, which I really don’t understand anymore:
Zernez-Zuoz (unclear type): 38 / 141
Zuoz-S-Chanf (unclear type): 40 / 141
S-Chanf-Zernez (mostly downhill): 39 / 143
Zernez-Guarda (mostly uphill): 37 / 136
Guarda-Ftan (mostly uphill): 37 / 131
Ftan-Scuol (mostly downhill): 43 / 156
The difference at the end is striking. I’m visually matching the map positions to km and then use VeloViewer for computing the altitude gain, but Zernez to Guarda is 420m altitude, and Guarda to Ftan is 200m altitude gain, and yet on both, I was faster than my final place, and by quite a few places on overall, only to lose that on the descent (Ftan-Scuol), and by a large margin.
So, amongst all the confusion here, I think the story overall is:
indeed I was quite fit for me, so the climbs were better than my place in the race (if that makes sense).
however, I’m not actually good at climbing nor fit (watts/kg), so I’m still way back in the pack (oops!).
and I do suck at descending, both me (skills) and possible my bike setup as well (too high tyre pressure, etc.) so I lose even more time here…
As usual, the final take-away points are: lose the extra weight that is not needed, get better skills, get better core to be better at climbing.
I’ll finish here with one pic, taken in Guarda (4 hours into the race, more or less):
This month I accepted 278 packages and rejected 58. The overall number of packages that got accepted was 304.
Debian LTS
This was my seventy-fifth month that I did some work for the Debian LTS initiative, started by Raphael Hertzog at Freexian.
This month my all in all workload has been 19.75h. During that time I did LTS uploads of:
[DLA 2382-1] curl security update for one CVE
[DLA 2383-1] nfdump security update for two CVEs
[DLA 2384-1] yaws security update for two CVEs
I also started to work on new issues of qemu but had to learn that most of the patches I found have not yet been approved by upstream. So I moved on to python3.5 and cimg. The latter is basically just a header file and I had to find its reverse dependencies to check whether all of them can still be built with the new cimg package. This is still WIP and I hope to upload new versions soon.
Last but not least I did some days of frontdesk duties.
Debian ELTS
This month was the twenty seventh ELTS month.
During my allocated time I uploaded:
ELA-284-1 for curl
ELA-288-1 for libxrender
ELA-289-1 for python3.4
Like in LTS, I also started to work on qemu and encountered the same problems as in LTS above.
When building the new python packages for ELTS and LTS, I used the same VM and encountered memory problems that resulted in random tests failing. This was really annoying as I spent some time just chasing the wind. So up to now only the LTS package got an update and the ELTS one has to wait for October.
Last but not least I did some days of frontdesk duties.
Other stuff
This month I only uploaded some packages to fix bugs:
Welcome to the September 2020 report from the Reproducible Builds project. In our monthly reports, we attempt to summarise the things that we have been up to over the past month, but if you are interested in contributing to the project, please visit our main website.
This month, the Reproducible Builds project was pleased to announce a donation from Amateur Radio Digital Communications (ARDC) in support of its goals. ARDC’s contribution will propel the Reproducible Builds project’s efforts in ensuring the future health, security and sustainability of our increasingly digital society. Amateur Radio Digital Communications (ARDC) is a non-profit which was formed to further research and experimentation with digital communications using radio, with a goal of advancing the state of the art of amateur radio and to educate radio operators in these techniques. You can view the full announcement as well as more information about ARDC on their website.
The Threema privacy and security-oriented messaging application announced that “within the next months”, their apps “will become fully open source, supporting reproducible builds”:
This is to say that anyone will be able to independently review Threema’s security and verify that the published source code corresponds to the downloaded app.
The previous year has seen great progress in Arch Linux to get reproducible builds in the hands of the users and developers. In this talk we will explore the current tooling that allows users to reproduce packages, the rebuilder software that has been written to check packages and the current issues in this space.
During the Reproducible Builds summit in Marrakesh, GNU Guix, NixOS and Debian were able to produce a bit-for-bit identical binary when building GNU Mes, despite using three different major versions of GCC. Since the summit, additional work resulted in a bit-for-bit identical Mes binary using tcc and this month, a fuller update was posted by the individuals involved.
Last month, an issue was identified where a large number of Debian .buildinfo build certificates had been ‘tainted’ on the official Debian build servers, as these environments had files underneath the /usr/local/sbin directory to prevent the execution of system services during package builds. However, this month, Aurelien Jarno and Wouter Verhelst fixed this issue in varying ways, resulting in a special policy-rcd-declarative-deny-all package.
diffoscope is our in-depth and content-aware diff utility that can not only locate and diagnose reproducibility issues, it provides human-readable diffs of all kinds too.
In September, Chris Lamb made the following changes to diffoscope, including preparing and uploading versions 159 and 160 to Debian:
New features:
Show “ordering differences” only in strings(1) output by applying the ordering check to all differences across the codebase. […]
Bug fixes:
Mark some PGP tests that they require pgpdump, and check that the associated binary is actually installed before attempting to run it. (#969753)
Don’t raise exceptions when cleaning up after guestfs cleanup failure. […]
Ensure we check FALLBACK_FILE_EXTENSION_SUFFIX, otherwise we run pgpdump against all files that are recognised by file(1) as data. […]
Codebase improvements:
Add some documentation for the EXTERNAL_TOOLS dictionary. […]
Abstract out a variable we use a couple of times. […]
Also include the general news in our RSS feed […] and drop including weekly reports from the RSS feed (they are never shown now that we have over 10 items) […].
Update ordering and location of various news and links to tarballs, etc. […][…][…]
In addition, Holger Levsen re-added the documentation link to the top-level navigation […] and documented that the jekyll-polyglot package is required […]. Lastly, diffoscope.org and reproducible-builds.org were transferred to Software Freedom Conservancy. Many thanks to Brett Smith from Conservancy, Jérémy Bobbio (lunar) and Holger Levsen for their help with transferring and to Mattia Rizzolo for initiating this.
Upstream patches
The Reproducible Builds project detects, dissects and attempts to fix as many currently-unreproducible packages as possible. We endeavour to send all of our patches upstream where appropriate. This month, we wrote a large number of these patches, including:
The Reproducible Builds project operates a Jenkins-based testing framework to power tests.reproducible-builds.org. This month, Holger Levsen made the following changes:
Highlight important bad conditions in colour. […][…]
Add support for detecting more problems, including Jenkins shutdown issues […], failure to upgrade Arch Linux packages […], kernels with wrong permissions […], etc.
Misc:
Delete old schroot sessions after 2 days, not 3. […]
In addition, stefan0xC fixed a query for unknown results in the handling of Arch Linux packages […] and Mattia Rizzolo updated the template that notifies maintainers by email of their newly-unreproducible packages to ensure that it did not get caught in junk/spam folders […]. Finally, build node maintenance was performed by Holger Levsen […][…][…][…], Mattia Rizzolo […][…] and Vagrant Cascadian […][…][…].
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
As normal, probably of direct interest only to California residents and
apologies to everyone else since my hand-rolled blog software doesn't do
cut tags. I'm only going to cover propositions, since the state-wide
elections aren't very interesting and I both don't have strong opinions
about the local elections and would guess that almost no one cares.
See the voter guide for the full
details on each proposition.
Propositions 16 through 19 were put on the ballot by the legislature and
thus were written as well as our regular laws. The remaining propositions
are initiatives, which means I default to voting against them because
they're usually poorly-written crap.
Proposition 14: NO. I reluctantly supported the original
proposition to fund stem cell research with state bonds because it was in
the middle of the George W. Bush administration and his weird obsession
with ending stem cell research. It seemed worth the cost to maintain the
research, and I don't regret doing this. But since then we've reached a
compromise on ongoing research, and this proposition looks a lot more like
pork spending than investment.
I am in favor of government support of basic research, but I think that's
best done by a single grant institution that can pursue a coherent agenda.
The federal government, when sane, does a decent job of this, and the
California agency created by the previous proposition looks dodgy. The
support for this proposition also comes primarily from research
institutions that benefit from it. On top of that, there are way higher
priorities right now for public investment than a very specific and
limited type of medical research that isn't even the most important type
of medical research to do right now. There is nothing magic about stem
cells other than the fact that they make a certain type of Republican lose
their minds. It's time to stop funding this specific research specially
and roll it into general basic research funding.
Proposition 15: YES. Yes to anything that repeals Proposition 13
in whole or in part. Repealing it for commercial and industrial real
estate is a good first step. A rare exception in my general rule to vote
against initiatives.
Proposition 16: YES. Reverses a bad law to outlaw affirmative
action in California. I am in favor of actual reparations, so I am of
course in favor of this, which is far, far more mild.
Proposition 17: YES. Restores voting rights to felons after
completion of their sentence. I think it's inexcusable that any US
citizen cannot vote, including people who are currently incarcerated, so
of course I'm in favor of this more mild measure. (You may notice a
theme.) When we say everyone should be able to vote, that should mean
literally everyone.
Proposition 18: YES. Allows 17-year-olds to vote in California
(but not federal) elections in some specific circumstances. I'm generally
in favor of lowering the voting age, and this seems inoffensive. (And the
arguments against it are stupid.)
Proposition 19: YES. This is a complicated legislative
compromise around property tax that strengthens property tax limits for
seniors moving within California while removing exemptions against
increases for inherited real estate not used as a primary home. Some
progressives are opposed to this because it doesn't go far enough and
increases exemptions for seniors. I agree that those exemptions aren't
needed and shouldn't be added, but closing the inheritance loophole is
huge and worth this compromise. It's a tepid improvement for the somewhat
better, but it's still worth approving (and was written by the
legislature, so it's somewhat better written than the typical initiative).
Proposition 20: NO. Another pile of "anyone who has ever
committed a crime deserves to be treated as subhuman" bullshit. Typical
harsher sentences and harsher parole nonsense. No to everything like
this, always.
Proposition 21: YES. This is my other exception of voting for an
initiative, and that's because the California state legislature is
completely incapable of dealing with any housing problem.
This is a proposition that overhauls an ill-conceived state-wide
restriction on how rent control can be handled. The problem with rent
control is that a sane solution to housing problems in this state requires
both rent control and massive new construction, and we only get the former
and not the latter because the NIMBYism is endemic. (There's a pile of
NIMBY crap on my local ballot this year.) I would much rather be
approving those things together, because either of them alone makes things
worse for a lot of people. So yes, the opponents of this proposition are
right: it will make the housing crisis worse, because everyone refuses to
deal with the supply side.
That said, we need rent control as part of a humane solution, and the
current state-wide rules are bad. For example, they disallow rent control
on every property newer than a certain date that's forever fixed. This
initiative replaces that with a much saner 15-year rolling window for
maximizing profit, which is a better balance.
I hate voting for this because the legislature should have done their job
and passed comprehensive housing reform. But since they didn't, this is
part of what they should have passed, and I'll vote for it. Particularly
since it's opposed by all the huge commercial landlords.
Proposition 22: NO. The "exclude Uber and Lyft from labor law"
proposition, which is just as bullshit as it sounds. They're spending all
of their venture capital spamming the crap out of everyone in the state to
try to get this passed by lying about it. Just stunningly evil companies.
If your business model requires exploiting labor, get a better business
model.
Proposition 23: NO. So, this is another mess. It appears to be
part of some unionization fight between dialysis clinic employees and the
for-profit dialysis clinics. I hate everything about this situation,
starting from the fact that we have such a thing as for-profit dialysis
clinics, which is a crime against humanity.
But this proposition requires some very dodgy things, such as having a
doctor on staff at every clinic for... reasons? This is very reminiscent
of the bullshit laws about abortion clinics, which are designed to make it
more expensive to operate a clinic for no justifiable reason. I'm happy
to believe there is a bit more justification here, but this sort of
regulation is tricky and should be done by the legislature in a normal
law-making process. Medical regulation by initiative is just a horrible
idea in every way. So while I am doubtless politically on the side of the
proponents of the proposition, this is the wrong tool. Take it to the
legislature.
Proposition 24: NO. A deceptively-written supposed consumer
privacy law written by tech companies that actually weakens consumer
privacy in some critical ways that are profitable for them. No thanks,
without even getting to the point that this sort of thing shouldn't be
done by initiative.
Proposition 25: YES. Yes, we should eliminate cash bail, which
is essentially imprisoning people for being poor. No, this doesn't create
a system of government profiling; judges already set bail and can revoke
bail for flight risks. (This is not legislation by initiative; the state
government already passed this law, but we have a dumb law that lets
people oppose legislative action via initiative, so we have to vote to
approve the law that our representatives already passed and that should
have already gone into effect.)
I'm mirroring and reworking a large Git repository with git filter-branch (conversion ETA: 20h), and I was wondering how to use --state-branch which is supposed to speed-up later updates, or split a large conversion in several updates.
The documentation is pretty terse, the option can produce weird results (like an identity mapping that breaks all later updates, or calling the expensive tree-filter but discarding the results), wrappers are convoluted, but I got something to work so I'll share
The main point is: run the initial script and the later updates in the same configuration, which means the target branch needs to be reset to the upstream branch each time, before it's rewritten again by filter-branch. In other words, don't re-run it on the rewritten branch, nor attempt some complex merge/cherry-pick.
Updates restart from scratch but only take a few seconds to skim through all the already-rewritten commits, and maintain a stable history.
Note that if the process is interrupted, the state-branch isn't modified, so it's not a stop/resume feature. If you want to split a lenghty conversion, you could simulate multiple upstream updates by checking out successive points in history (e.g. per year using $(git rev-list -1 --before='2020-01-01 00:00:00Z')).
--state-branch isn't meant to rewrite in reverse chronological order either, because all commit ids would constantly change. Still, you can rewrite only the recent history for a quick discardable test.
Be cautious when using/deleting rewritten branches, especially during early tests, because Git tends to save them to multiple places which may desync (e.g. .git/refs/heads/, .git/logs/refs/, .git/packed-refs). Also remember to delete the state-branch between different tests. Last, note the unique temporary directory -d to avoid ruining concurrent tests ^_^'
I was assigned 16 hours of work by Freexian's Debian LTS initiative
and carried over 9.75 hours from August. I only worked 8.25 hours
this month, and will return excess hours to the pool.
I attended and participated in the LTS team meeting on the 24th.
I updated linux-4.19 to include the changes in the buster point
release, and issued
DLA-2385-1.
I began work on an update to the linux (Linux 4.9 kernel) package.
Yesterday I got a fresh new Pixel 4a, to replace my dying OnePlus 6.
The OnePlus had developed some faults over time: It repeatedly loses connection to the AP and the network, and it got a bunch of scratches and scuffs from falling on various surfaces without any protection over the past year.
Why get a Pixel?
Camera: OnePlus focuses on stuffing as many sensors as it can into a phone, rather than a good main sensor, resulting in pictures that are mediocre blurry messes - the dreaded oil painting effect.
Pixel have some of the best camera in the smartphone world. Sure, other hardware is far more capable, but the Pixels manage consistent results, so you need to take less pictures because they don’t come out blurry half the time, and the post processing is so good that the pictures you get are just great. Other phones can shoot better pictures, sure - on a tripod.
Security updates: Pixels provide 3 years of monthly updates, with security updates being published on the 5th of each month. OnePlus only provides updates every 2 months, and then the updates they do release are almost a month out of date, not counting that they are only 1st-of-month patches, meaning vendor blob updates included in the 5th-of-month updates are even a month older. Given that all my banking runs on the phone, I don’t want it to be constantly behind.
Feature updates: Of course, Pixels also get Beta Android releases and the newest Android release faster than any other phone, which is advantageous for Android development and being nerdy.
Size and weight: OnePlus phones keep getting bigger and bigger. By today’s standards, the OnePlus 6 at 6.18" and 177g is a small an lightweight device. Their latest phone, the Nord, has 6.44" and weighs 184g, the OnePlus 8 comes in at 180g with a 6.55" display. This is becoming unwieldy. Eschewing glass and aluminium for plastic, the Pixel 4a comes in at 144g.
First impressions
Accessories
The Pixel 4a comes in a small box with a charger, USB-C to USB-C cable, a USB-OTG adapter, sim tray ejector. No pre-installed screen protector or bumper are provided, as we’ve grown accustomed to from Chinese manufacturers like OnePlus or Xiaomi. The sim tray ejector has a circular end instead of the standard oval one - I assume so it looks like the ‘o’ in Google?
Google sells you fabric cases for 45€. That seems a bit excessive, although I like that a lot of it is recycled.
Haptics
Coming from a 6.18" phablet, the Pixel 4a with its 5.81" feels tiny. In fact, it’s so tiny my thumb and my index finger can touch while holding it. Cute! Bezels are a bit bigger, resulting in slightly less screen to body. The bottom chin is probably impracticably small, this was already a problem on the OnePlus 6, but this one is even smaller. Oh well, form over function.
The buttons on the side are very loud and clicky. As is the vibration motor. I wonder if this Pixel thinks it’s a Model M. It just feels great.
The plastic back feels really good, it’s that sort of high quality smooth plastic you used to see on those high-end Nokia devices.
The finger print reader, is super fast. Setup just takes a few seconds per finger, and it works reliably. Other phones (OnePlus 6, Mi A1/A2) take like half a minute or a minute to set up.
Software
The software - stock Android 11 - is fairly similar to OnePlus' OxygenOS. It’s a clean experience, without a ton of added bloatware (even OnePlus now ships Facebook out of box, eww). It’s cleaner than OxygenOS in some way - there are no duplicate photos apps, for example. On the other hand, it also has quite a bunch of Google stuff I could not care less about like YT Music. To be fair, those are minor noise once all 130 apps were transferred from the old phone.
There are various things I miss coming from OnePlus such as off-screen gestures, network transfer rate indicator in quick settings, or a circular battery icon. But the Pixel has an always on display, which is kind of nice. Most of the cool Pixel features, like call screening or live transcriptions are unfortunately not available in Germany.
The display is set to display the same amount of content as my 6.18" OnePlus 6 did, so everything is a bit tinier. This usually takes me a week or two to adjust too, and then when I look at the OnePlus again I’ll be like “Oh the font is huge”, but right now, it feels a bit small on the Pixel.
You can configure three colour profiles for the Pixel 4a: Natural, Boosted, and Adaptive. I have mine set to adaptive. I’d love to see stock Android learn what OnePlus has here: the ability to adjust the colour temperature manually, as I prefer to keep my devices closer to 5500K than 6500K, as I feel it’s a bit easier on the eyes. Or well, just give me the ability to load a ICM profile (though, I’d need to calibrate the screen then - work!).
Migration experience
Restoring the apps from my old phone only restore settings for a few handful out of 130, which is disappointing. I had to spent an hour or two logging in to all the other apps, and I had to fiddle far too long with openScale to get it to take its data over. It’s a mystery to me why people do not allow their apps to be backed up, especially something innocent like a weight tracking app. One of my banking apps restored its logins, which I did not really like. KeePass2Android settings were restored as well, but at least the key file was not restored.
I did not opt in to restoring my device settings, as I feel that restoring device settings when changing manufactures is bound to mess up some things. For example, I remember people migrating to OnePlus phones and getting their old DND schedule without any way to change it, because OnePlus had hidden the DND stuff. I assume that’s the reason some accounts, like my work GSuite account were not migrated (it said it would migrate accounts during setup).
I’ve setup Bitwarden as my auto-fill service, so I could login into most of my apps and websites using the stored credentials. I found that often that did not work. Like Chrome does autofill fine once, but if I then want to autofill again, I have to kill and restart it, otherwise I don’t get the auto-fill menu. Other apps did not allow any auto-fill at all, and only gave me the option to copy and paste. Yikes - auto-fill on Android still needs a lot of work.
Performance
It hangs a bit sometimes, but this was likely due to me having set 2 million iterations on my Bitwarden KDF and using Bitwarden a lot, and then opening up all 130 apps to log into them which overwhelmed the phone a bit. Apart from that, it does not feel worse than the OnePlus 6 which was to be expected, given that the benchmarks only show a slight loss in performance.
Photos do take a few seconds to process after taking them, which is annoying, but understandable given how much Google relies on computation to provide decent pictures.
Audio
The Pixel has dual speakers, with the earpiece delivering a tiny sound and the bottom firing speaker doing most of the work. Still, it’s better than just having the bottom firing speaker, as it does provide a more immersive experience. Bass makes this thing vibrate a lot. It does not feel like a resonance sort of thing, but you can feel the bass in your hands. I’ve never had this before, and it will take some time getting used to.
Final thoughts
This is a boring phone. There’s no wow factor at all. It’s neither huge, nor does it have high-res 48 or 64 MP cameras, nor does it have a ton of sensors. But everything it does, it does well. It does not pretend to be a flagship like its competition, it doesn’t want to wow you, it just wants to be the perfect phone for you. The build is solid, the buttons make you think of a Model M, the camera is one of the best in any smartphone, and you of course get the latest updates before anyone else. It does not feel like a “only 350€” phone, but yet it is. 128GB storage is plenty, 1080p resolution is plenty, 12.2MP is … you guessed it, plenty.
The same applies to the other two Pixel phones - the 4a 5G and 5. Neither are particularly exciting phones, and I personally find it hard to justify spending 620€ on the Pixel 5 when the Pixel 4a does job for me, but the 4a 5G might appeal to users looking for larger phones. As to 5G, I wouldn’t get much use out of it, seeing as its not available anywhere I am. Because I’m on Vodafone. If you have a Telekom contract or live outside of Germany, you might just have good 5G coverage already and it might make sense to get a 5G phone rather than sticking to the budget choice.
Outlook
The big question for me is whether I’ll be able to adjust to the smaller display. I now have a tablet, so I’m less often using the phone (which my hands thank me for), which means that a smaller phone is probably a good call.
Oh while we’re talking about calls - I only have a data-only SIM in it, so I could not test calling. I’m transferring to a new phone contract this month, and I’ll give it a go then. This will be the first time I get VoLTE and WiFi calling, although it is Vodafone, so quality might just be worse than Telekom on 2G, who knows. A big shoutout to congstar for letting me cancel with a simple button click, and to @vodafoneservice on twitter for quickly setting up my benefits of additional 5GB per month and 10€ discount for being an existing cable customer.
I’m also looking forward to playing around with the camera (especially night sight), and eSIM. And I’m getting a case from China, which was handed over to the Airline on Sep 17 according to Aliexpress, so I guess it should arrive in the next weeks. Oh, and screen protector is not here yet, so I can’t really judge the screen quality much, as I still have the factory protection film on it, and that’s just a blurry mess - but good enough for setting it up. Please Google, pre-apply a screen protector on future phones and include a simple bumper case.
I might report back in two weeks when I have spent some more time with the device.
While I grew up, right from the childhood itself, the sky was always an intriguing view. The Stars, the Moon, the Eclipses; were all fascinating.
As a child, in my region, religion and culture; the mythology also built up stories around it. Lunar Eclipses have a story of its own. During Solar Eclipses, parents still insist that we do not go out. And to be done with the food eating before/after the eclipse.
Then there’s the Hindu Astrology part, which claims its own theories and drags in mythology along. For example, you’ll still find the Hindu Astrology making recommendations to follow certain practices with the planets, to get auspicious personal results. As far as I know, other religions too have similar beliefs about the planets.
As a child, we are told the Moon to be addressed as an Uncle (चंदा मामा). There’s also a rhyme around it, that many of us must have heard.
Fast-forward to today, as I grew, so did some of my understanding. It is fascinating how mankind has achieved so much understanding of our surrounding. You could go through the documentaries on Mars Exploration, for example; to see how the rovers are providing invaluable data.
As a mere individual, there’s a limit to what one can achieve. But the questions flow in free.
Is there life beyond us
What’s out there in the sky
Why is all this the way it is
Hobby
The very first step, for me, for every such curiosity, has been to do the ground work, with the resources I have. To study on the subject. I have done this all my life. For example, I started into the Software domain as: A curiosity => A Hobby => A profession
Same was the case with some of the other hobbies, equally difficult as Astronomy, that I developed a liking for. Just did the ground work, studied on those topics and then applied the knowledge to further improve it and build up some experience.
And star gazing came in no different. As a complete noob, had to start with the A B C on the subject of Astronomy. Familiarize myself with the usual terms. As so on…
PS: Do keep in mind that not all hobbies have a successful end. For example, I always craved to be good with graphic designing, image processing and the likes, where I’ve always failed. Never was able to keep myself motivated enough. Similar was my experience when trying to learn playing a musical instrument. Just didn’t work out for me, then.
There’s also a phase in it, where you fail and then learn from the failures and proceed further, and then eventually succeed. But we all like to talk about the successes. :-)
Astronomy
So far, my impression has been that this topic/domain will not suit most of the people. While the initial attraction may be strong, given the complexity and perseverance that Astronomy requires, most people would lose interest in it very soon.
Then there’s the realization factor. If one goes with an expectation to get quick results, they may get disappointed. It isn’t like a point and shoot device that’d give you results on the spot.
There’s also the expectation side of things. If you are a person more accustomed to taking pretty selfies, which always come right because the phone manufacturer does heavy processing on the images to ensure that you get to see the pretty fake self, for the most of the times; then star gazing with telescopes could be a frustrating experience altogether. What you get to see in the images on the internet will be very different than what you’d be able to see with your eyes and your basic telescope.
There’s also the cost aspect. The more powerful (and expensive) your telescope, the better your view.
And all things aside, it still may get you lose interest, after you’ve done all the ground work and spent a good chunk of money on it. Simply because the object you are gazing at is more a still image, which can quickly get boring for many.
On the other hand, if none of the things obstruct, then the domain of Astronomy can be quite fascinating. It is a continuous learning domain (reminds me of CI in our software field these days). It is just the beginning for us here, and we hope to have a lasting experience in it.
The Internet
I have been indebted to the internet right from the beginning. The internet is what helped me be able to achieve all I wanted. It is one field with no boundaries. If there is a will, there is a way; and often times, the internet is the way.
I learnt computers over the internet.
Learnt more about gardening and plants over the internet
Learnt more about fish care-taking over the internet
And many many more things.
Some of the communities over the internet are a great way to participation. They bridge the age gap, the regional gap and many more.
For my Astronomy need, I was glad to see so many active communities, with great participants, on the internet.
Telescope
While there are multiple options to start star gazing, I chose to start with a telescope. But as someone completely new to this domain, there was a long way to go. And to add to that, the real life: work + family
I spent a good 12+ months reading up on the different types of telescopes, what they are, their differences, their costs, their practical availability etc.
The good thing is that the market has offerings for everything. From a very basic binocular to a fully automatic Maksutov-Cassegrain scope. It all would depend on your budget.
Automatic vs Manual
To make it easy for the users, the market has multiple options in the offering. One could opt-in for a cheap, basic and manually operated telescope; which would require the user to do a lot of ground study. On the other hand, users also have the option of automatic telescopes which do the hard work of locating and tracking the planetary objects.
Either option aside, the end result of how much you’ll be able to observe the sky, still depends on many many more factors: Enthusiasm over time, Light Pollution, Clear Skies, Timing etc.
PS: The planetary objects move at a steady pace. Objects you lock into your view now will be gone out of the FOV in just a matter of minutes.
My Telescope
After spending so much of the time reading up on types of telescopes, my conclusion was that a scope with high aperture and focal length was the way to go forward. This made me shorten the list to Dobsonians. But the Dobsonians aren’t a very cheap telescope, whether manual or automatic.
My final decision made me acquire a 6" Dobsonian Telescope. It is a Newtonian Reflecting Telescope with a 1200mm focal length and 150mm diameter.
Another thing about this subject is that most of the stuff you do in Astronomy; right from the telescope selection, to installation, to star gazing; most of it is DIY, so your mileage may vary with the end result and experience.
For me, installation wasn’t very difficult. I was able to assemble the base Dobsonian mount and the scope in around 2 hours. But the installation manual, I had been provided with, was very brief. I ended up with one module in the mount wrongly fit, which I was able to fix later, with the help of online forums.
Dobsonian Mount
In this image you can see that the side facing out, where the handle will go, is wrong. If fit this way, the handle will not withstand any weight at all.
Correct Panel Side
The right fix of the handle base board. In this image, the handle is on the other side that I’m holding. Because the initial fit put in some damage to the engineered wood, I fixed it up by sealing with some adhesive.
With that, this is what my final telescope looks like.
Final Telescope
Clear Skies
While the telescope was ready, the skies were not. For almost next 10 days, we had no clear skies at all. All I could do was wait. Wait so much that I had forgotten to check on the skies. Luckily, my wife noticed clear skies this week for a single day. Clear enough that we could try out our telescope for the very first time.
Me posing for a shot
Telescope
As I said earlier, in my opinion, it takes a lot of patience and perseverance on this subject. And most of the things here are DIY.
To start with, we targeted the Moon. Because it is easy. I pointed the scope to the moon, then looked into the finder scope to center it, and then looked through the eyepiece. And blank. Nothing out there. Turns out, the finder scope and the viewer’s angle weren’t aligned. This is common and the first DIY step, when you plan to use your telescope for viewing.
Since our first attempt was unplanned and just random because we luckily spotted that the skies were clear, we weren’t prepared for this. Lucky enough, mapping the difference in the alignment, in the head, is not very difficult.
After a couple of minutes, I could make out the point in the finder scope, where the object if projected, would show proper in the viewer.
With that done, it was just mesmerizing to see the Moon, in a bit more detail, than what I’ve seen all these years of my life.
Moon
Moon
Moon
Moon
The images are not exactly what we saw with our eyes. The view was much more vivid than these pictures. But as a first timer, I really wanted to capture this first moment of a closer view of the Moon.
In the whole process; that of ground work studying about telescopes, installation of the telescope, astronomy basics and many other things; the most difficult part in this entire journey, was to point my phone to the viewing eyepiece, to get a shot of the object. This requirement just introduced me to astrophotography.
And then, Dobsonians aren’t the best model for astrophotography, to what I’ve learnt so far. Hopefully, I’ll find my ways to do some DIY astrophotography with the tools I have. Or extend my arsenal over time.
But overall, we’ve been very pleased with the subject of Astronomy. It is a different feel altogether and we’re glad to have forayed into it.
Recently I've been writing a couple of simple compilers, which take input in a particular format and generate assembly language output. This output can then be piped through gcc to generate a native executable.
Of course there's always the nagging thought that relying upon gcc (or nasm) is a bit of a cheat. So I wondered how hard is it to write an assembler? Something that would take assembly-language program and generate a native (ELF) binary?
And the answer is "It isn't hard, it is just tedious".
I found some code to generate an ELF binary, and after that assembling simple instructions was pretty simple. I remember from my assembly-language days that the encoding of instructions can be pretty much handled by tables, but I've not yet gone into that.
(Specifically there are instructions like "add rax, rcx", and the encoding specifies the source/destination registers - with different forms for various sized immediates.)
Anyway I hacked up a simple assembler, it can compile a.out from this input:
.hello DB "Hello, world\n"
.goodbye DB "Goodbye, world\n"
mov rdx, 13 ;; write this many characters
mov rcx, hello ;; starting at the string
mov rbx, 1 ;; output is STDOUT
mov rax, 4 ;; sys_write
int 0x80 ;; syscall
mov rdx, 15 ;; write this many characters
mov rcx, goodbye ;; starting at the string
mov rax, 4 ;; sys_write
mov rbx, 1 ;; output is STDOUT
int 0x80 ;; syscall
xor rbx, rbx ;; exit-code is 0
xor rax, rax ;; syscall will be 1 - so set to xero, then increase
inc rax ;;
int 0x80 ;; syscall
The obvious omission is support for "JMP", "JMP_NZ", etc. That's painful because jumps are encoded with relative offsets. For the moment if you want to jump:
push foo ; "jmp foo" - indirectly.
ret
:bar
nop ; Nothing happens
mov rbx,33 ; first syscall argument: exit code
mov rax,1 ; system call number (sys_exit)
int 0x80 ; call kernel
:foo
push bar ; "jmp bar" - indirectly.
ret
I'll update to add some more instructions, and see if I can use it to handle the output I generate from a couple of other tools. If so that's a win, if not then it was a fun learning experience:
tl;dr: Do not configure Mailman to replace the mail domains in From: headers. Instead, try out my small new program which can make your Mailman transparent, so that DKIM signatures survive.
Background and narrative
DKIM
NB: This explanation is going to be somewhat simplified. I am going to gloss over some details and make some slightly approximate statements.
DKIM is a new anti-spoofing mechanism for Internet email, intended to help fight spam. DKIM, paired with the DMARC policy system, has been remarkably successful at stemming the flood of joe-job spams. As usually deployed, DKIM works like this:
When a message is originally sent, the author's MUA sends it to the MTA for their From: domain for outward delivery. The From: domain mailserver calculates a cryptographic signature of the message, and puts the signature in the headers of the message.
Obviously not the whole message can be signed, since at the very least additional headers need to be added in transit, and sometimes headers need to be modified too. The signing MTA gets to decide what parts of the message are covered by the signature: they nominate the header fields that are covered by the signature, and specify how to handle the body.
A recipient MTA looks up the public key for the From: domain in the DNS, and checks the signature. If the signature doesn't match, depending on policy (originator's policy, in the DNS, and recipient's policy of course), typically the message will be treated as spam.
The originating site has a lot of control over what happens in practice. They get to publish a formal (DMARC) policy in the DNS which advises recipients what they should do with mails claiming to be from their site. As mentioned, they can say which headers are covered by the signature - including the ability to sign the absence of a particular headers - so they can control which headers downstreams can get away with adding or modifying. And they can set a normalisation policy, which controls how precisely the message must match the one that they sent.
Mailman
Mailman is, of course, the extremely popular mailing list manager. There are a lot of things to like about it. I choose to run it myself not just because it's popular but also because it provides a relatively competent web UI and a relatively competent email (un)subscription interfaces, decent bounce handling, and a pretty good set of moderation and posting access controls.
The Xen Project mailing lists also run on mailman. Recently we had some difficulties with messages sent by Citrix staff (including myself), to Xen mailing lists, being treated as spam. Recipient mail systems were saying the DKIM signatures were invalid.
This was in fact true. Citrix has chosen a fairly strict DKIM policy; in particular, they have chosen "simple" normalisation - meaning that signed message headers must precisely match in syntax as well as in a semantic sense. Examining the the failing-DKIM messages showed that this was definitely a factor.
Applying my Opinions about email
My Bayesian priors tend to suggest that a mail problem involving corporate email is the fault of the corporate email. However in this case that doesn't seem true to me.
My starting point is that I think mail systems should not not modify messages unnecessarily. None of the DKIM-breaking modifications made by Mailman seemed necessary to me. I have on previous occasions gone to corporate IT and requested quite firmly that things I felt were broken should be changed. But it seemed wrong to go to corporate IT and ask them to change their published DKIM/DMARC policy to accomodate a behaviour in Mailman which I didn't agree with myself. I felt that instead I shoud put (with my Xen Project hat on) my own house in order.
Getting Mailman not to modify messages
So, I needed our Mailman to stop modifying the headers. I needed it to not even reformat them. A brief look at the source code to Mailman showed that this was not going to be so easy. Mailman has a lot of features whose very purpose is to modify messages.
Personally, as I say, I don't much like these features. I think the subject line tags, CC list manipulations, and so on, are a nuisance and not really Proper. But they are definitely part of why Mailman has become so popular and I can definitely see why the Mailman authors have done things this way. But these features mean Mailman has to disassemble incoming messages, and then reassemble them again on output. It is very difficult to do that and still faithfully reassemble the original headers byte-for-byte in the case where nothing actually wanted to modify them. There are existing bug reports[1][2][3][4]; I can see why they are still open.
Rejected approach: From:-mangling
This situation is hardly unique to the Xen lists. Many other have struggled with it. The best that seems to have been come up with so far is to turn on a new Mailman feature which rewrites the From: header of the messages that go through it, to contain the list's domain name instead of the originator's.
I think this is really pretty nasty. It breaks normal use of email, such as reply-to-author. It is having Mailman do additional mangling of the message in order to solve the problems caused by other undesirable manglings!
Solution!
As you can see, I asked myself: I want Mailman not modify messages at all; how can I get it to do that? Given the existing structure of Mailman - with a lot of message-modifying functionality - that would really mean adding a bypass mode. It would have to spot, presumably depending on config settings, that messages were not to be edited; and then, it would avoid disassembling and reassembling the message at at all, and bypass the message modification stages. The message would still have to be parsed of course - it's just that the copy send out ought to be pretty much the incoming message.
When I put it to myself like that I had a thought: couldn't I implement this outside Mailman? What if I took a copy of every incoming message, and then post-process Mailman's output to restore the original?
It turns out that this is quite easy and works rather well!
outflank-mailman
outflank-mailman is a 233-line script, plus documentation, installation instructions, etc.
It is designed to run from your MTA, on all messages going into, and coming from, Mailman. On input, it saves a copy of the message in a sqlite database, and leaves a note in a new Outflank-Mailman-Id header. On output, it does some checks, finds the original message, and then combines the original incoming message with carefully-selected headers from the version that Mailman decided should be sent.
This was deployed for the Xen Project lists on Tuesday morning and it seems to be working well so far.
If you administer Mailman lists, and fancy some new software to address this problem, please do try it out.
Matters arising - Mail filtering, DKIM
Overall I think DKIM is a helpful contribution to the fight against spam (unlike SPF, which is fundamentally misdirected and also broken). Spam is an extremely serious problem; most receiving mail servers experience more attempts to deliver spam than real mail, by orders of magnitude. But DKIM is not without downsides.
Inherent in the design of anything like DKIM is that arbitrary modification of messages by list servers is no longer possible. In principle it might be possible to design a system which tolerated modifications reasonable for mailing lists but it would be quite complicated and have to somehow not tolerate similar modifications in other contexts.
So DKIM means that lists can no longer add those unsubscribe footers to mailing list messages. The "new way" (RFC2369, July 1998), to do this is with the List-Unsubscribe header. Hopefully a good MUA will be able to deal with unsubscription semiautomatically, and I think by now an adequate MUA should at least display these headers by default.
Sender:
There are implications for recipient-side filtering too. The "traditional" correct way to spot mailing list mail was to look for Resent-To:, which can be added without breaking DKIM; the "new" (RFC2919, March 2001) correct way is List-Id:, likewise fine. But during the initial deployment of outflank-mailman I discovered that many subscribers were detecting that a message was list traffic by looking at the Sender: header. I'm told that some mail systems (apparently Microsoft's included) make it inconvenient to filter on List-Id.
Really, I think a mailing list ought not to be modifying Sender:. Given Sender:'s original definition and semantics, there might well be reasonable reasons for a mailing list posting to have different From: and and then the original Sender: ought not to be lost. And a mailing list's operation does not fit well into the original definition of Sender:. I suspect that list software likes to put in Sender mostly for historical reasons; notably, a long time ago it was not uncommon for broken mail systems to send bounces to the Sender: header rather than the envelope sender (SMTP MAIL FROM).
DKIM makes this more of a problem. Unfortunately the DKIM specifications are vague about what headers one should sign, but they pretty much definitely include Sender: if it is present, and some materials encourage signing the absence of Sender:. The latter is Exim's default configuration when DKIM-signing is enabled.
Franky there seems little excuse for systems to not readily support and encourage filtering on List-Id, 20 years later, but I don't want to make life hard for my users. For now we are running a compromise configuration: if there wasn't a Sender: in the original, take Mailman's added one. This will result in (i) misfiltering for some messages whose poster put in a Sender:, and (ii) DKIM failures for messages whose originating system signed the absence of a Sender:. I'm going to mine the db for some stats after it's been deployed for a week or so, to see which of these problems is worst and decide what to do about it.
Mail routing
For DKIM to work, messages being sent From: a particular mail domain must go through a system trusted by that domain, so they can be signed.
Most users tend to do this anyway: their mail provider gives them an IMAP server and an authenticated SMTP submission server, and they configure those details in their MUA. The MUA has a notion of "accounts" and according to the user's selection for an outgoing message, connects to the authenticated submission service (usually using TLS over the global internet).
Trad unix systems where messages are sent using the local sendmail or localhost SMTP submission (perhaps by automated systems, or perhaps by human users) are fine too. The smarthost can do the DKIM signing.
But this solution is awkward for a user of a trad MUA in what I'll call "alias account" setups: where a user has an address at a mail domain belonging to different people to the system on which they run their MUA (perhaps even several such aliases for different hats). Traditionally this worked by the mail domain forwarding incoming the mail, and the user simply self-declaring their identity at the alias domain. Without DKIM there is nothing stopping anyone self-declaring their own From: line.
If DKIM is to be enabled for such a user (preventing people forging mail as that user), the user will have to somehow arrange that their trad unix MUA's outbound mail stream goes via their mail alias provider. For a single-user sending unix system this can be done with tolerably complex configuration in an MTA like Exim. For shared systems this gets more awkward and might require some hairy shell scripting etc.
edited 2020-10-01 21:22 and 21:35 and -02 10:50 +0100 to fix typos and 21:28 to linkify "my small program" in the tl;dr
Already october. I tried moving to vscode from emacs but I have so far only installed the editor.
emacs is my workflow engine, so it's hard to migrate everything.
In September, the monthly sponsored hours were split evenly among contributors depending on their max availability - I was assigned 19.75h for LTS (out of my 30 max; all done) and 20h for ELTS (out of my 20 max; all done).
ELTS - Jessie
qemu: jessie triage: finish work started in August
libdbi-perl: global triage: clarifications, confirm incomplete and attempt to get upstream action, request new CVE following discussion with security team
I haven’t done one of these in a while, so let’s see how it goes.
Debian
The Community Team has been busy. We’re planning a sprint to work on a bigger writing project and have some tough discussions that need to happen.
I personally have only worked on one incident, but we’ve had a few others come in.
I’m attempting to step down from the Outreach team, which is more work than I thought it would be. I had a very complicated relationship with the Outreach team. When no one else was there to take on making sure we did GSoC and Outreachy, I stepped up. It wasn’t really what I wanted to be doing, but it’s important. I’m glad to have more time to focus on other things that feel more aligned with what I’m trying to work on right now.
GNOME
In addition to, you know, work, I joined the Code of Conduct Committee. Always a good time! Rosanna and I presented at GNOME Onboard Africa Virtual about the GNOME CoC. It was super fun!
Digital Autonomy
Karen and I did an interview on FLOSS Weekly with Doc Searls and Dan Lynch. Super fun! I’ve been doing some more writing, which I still hope to publish soon, and a lot of organization on it. I’m also in the process of investigating some funding, as there are a few things we’d like to do that come with price tags. Separately, I started working on a video to explain the Principles. I’m excited!
Misc
I started a call that meets every other week where we talk about Code of Conduct stuff. Good peeps. Into it.
Harrow the Ninth is a direct sequel to Gideon the Ninth and under absolutely no circumstances should you
start reading here. You would be so lost. If you plan on reading this
series, read the books as closely together as you can so that you can
remember the details of the previous book. You may still resort to
re-reading or searching through parts of the previous book as you go.
Muir is doing some complex structural work with Harrow the Ninth,
so it's hard to know how much to say about it without spoiling some aspect
of it for someone. I think it's safe to say this much: As advertised by
the title, we do get a protagonist switch to Harrowhark. However, unlike
Gideon the Ninth, it's not a single linear story. The storyline
that picks up after the conclusion of Gideon is interwoven with
apparent flashbacks retelling the story of the previous book from
Harrowhark's perspective. Or at least it might have been the story of the
previous book, except that Ortus is Harrowhark's cavalier, Gideon does not
appear, and other divergences from the story we previously read become
obvious early on.
(You can see why memory of Gideon the Ninth is important.)
Oh, and one of those storylines is written in the second person. Unlike
some books that use this as a gimmick, this is
for reasons that are eventually justified and partly explained in the
story, but it's another example of the narrative complexity. Harrow
the Ninth is dropping a lot of clues (and later revelations) in both
story events and story structure, many of which are likely to upend reader
expectations from the first book.
I have rarely read a novel that is this good at fulfilling the tricky role
of the second book of a trilogy. Gideon the Ninth was, at least on
the surface, a highly entertaining, linear, and relatively straightforward
escape room mystery, set against a dying-world SF background that was more
hinted at than fleshed out. Harrow the Ninth revisits and
reinterprets that book in ways that add significant depth without feeling
artificial. Bits of scenery in the first book take on new meaning and
intention. Characters we saw only in passing get a much larger role (and
Abigail is worth the wait). And we get a whole ton of answers: about the
God Emperor, about Lyctors, about the world, about Gideon and Harrowhark's
own pasts and backgrounds, and about the locked tomb that is at the center
of the Ninth House. But there is still more than enough for a third book,
including a truly intriguing triple cliffhanger ending. Harrow the
Ninth is both satisfying in its own right and raises new questions that
I'm desperate to see answered in the third book.
Also, to respond to my earlier self on setting, this world is not a
Warhammer 40K universe, no matter how much it may have appeared in
the glimpses we got in Gideon. The God Emperor appears directly in
this book and was not at all what I was expecting, if perhaps even more
disturbing. Muir is intentionally playing against type, drawing a sharp
contrast between the God Emperor and the dramatic goth feel of the rest of
the universe and many of the characters, and it's creepily effective and
goes in a much different ethical direction than I had thought. (That
said, I will warn that properly untangling the ethical dilemmas of this
universe is clearly left to the third book.)
I mentioned in my review of Gideon the
Ninth that I was happy to see more SF pulling unapologetically from
fanfic. I'm going to keep beating that drum in this review in part
because I think the influence may be less obvious to the uninitiated.
Harrow the Ninth is playing with voice, structure, memory, and
chronology in ways that I suspect the average reader unfamiliar with
fanfic may associate more with literary fiction, but they would be wrongly
underestimating fanfic if they did so. If anything, the callouts to
fanfic are even clearer. There are three classic fanfic alternate
universe premises that appear in passing, the story relies on the reader's
ability to hold a canonical narrative and an alternate narrative in mind
simultaneously, and the genre inspiration was obvious enough to me that
about halfway through the novel I correctly guessed one of the fanfic
universes in which Muir has written. (I'm not naming it here since I
think it's a bit of a spoiler.)
And of course there's the irreverence. There are some structural reasons
why the narrative voice isn't quite as good as Gideon the Ninth at
the start, but rest assured that Muir makes up for that by the end of the
book. My favorite scenes in the series so far happen at the end of
Harrow the Ninth: world-building, revelations, crunchy metaphysics,
and irreverent snark all woven beautifully together. Muir has her
characters use Internet meme references like teenagers, which is a
beautiful bit of characterization because they are teenagers. In a
world that's heavy on viscera, skeletons, death, and horrific monsters,
it's a much needed contrast and a central part of how the characters show
defiance and courage. I don't think this will work for everyone, but it
very much works for me. There's a Twitter meme reference late in the book
that had me laughing out loud in delight.
Harrow the Ninth is an almost perfect second book, in that if you
liked Gideon the Ninth, you will probably love Harrow the
Ninth and it will make you like Gideon the Ninth even more. It
does have one major flaw, though: pacing.
This was also my major complaint about Gideon, primarily around the
ending. I think Harrow the Ninth is a bit better, but the problem
has a different shape. The start of the book is a strong "what the hell
is going on" experience, which is very effective, and the revelations are
worth the build-up once they start happening. In between, though, the
story drags on a bit too long. Harrow is sick and nauseated at the start
of the book for rather longer than I wanted to read about, there is one
too many Lyctor banquets than I think were necessary to establish the
characters, and I think there's a touch too much wandering the halls.
Muir also interwove two narrative threads and tried to bring them to a
conclusion at the same time, but I think she had more material for one
than the other. There are moments near the end of the book where one
thread is producing all the payoff revelations the reader has been waiting
for, and the other thread is following another interminable and rather
uninteresting fight scene. You don't want your reader saying "argh, no"
each time you cut away to the other scene. It's better than Gideon
the Ninth, where the last fifth of the book is mostly a running battle
that went on way longer than it needed to, but I still wish Muir had
tightened the story throughout and balanced the two threads so that we
could stay with the most interesting one when it mattered.
That said, I mostly noticed the pacing issues in retrospect and in talking
about them with a friend who was more annoyed than I was. In the moment,
there was so much going on here, so many new things to think about, and so
much added depth that I devoured Harrow the Ninth over the course
of two days and then spent the next day talking to other people who had
read it, trading theories about what happened and what will happen in the
third book. It was the most enjoyable reading experience I've had so far
this year.
Gideon the Ninth was fun; Harrow the Ninth was both fun and
on the verge of turning this series into something truly great. I can
hardly wait for Alecto the Ninth (which doesn't yet have a release
date, argh).
As with Gideon the Ninth, content warning for lots and lots of
gore, rather too detailed descriptions of people's skeletons,
restructuring bits of the body that shouldn't be restructured, and more
about bone than you ever wanted to know.
Plasma 5.20 is going to be one absolutely massive release! More features, more fixes for longstanding bugs, more improvements to the user interface!
There are lots of new features mentioned in the release announcement, I like in particular the ability that settings changed from the default can now be highlighted.
I have been providing builds of KDE related packages since quite some time now, see everything posted under the KDE tag. In the last days I have prepared Debian packages for Plasma 5.19.90 on OBS, for now only targeting Debian/experimental and amd64 architecture.
These packages require Qt 5.15, which is only available in the experimental suite, and there is no way to simply update to Qt 5.15 since all Qt related packages need to be recompiled. So as long as Qt 5.15 doesn’t hit unstable, I cannot really run these packages on my main machine, but I tried a clean Debian virtual machine installing only Plasma 5.19.90 and depending packages, plus some more for a pleasant desktop experience. This worked out quite well, the VM runs Plasma 5.19.90.
Well, bottom line, as soon as we have Qt 5.15 in Debian/unstable, we are also ready for Plasma 5.20!
This month I started working on ways to make hosting access easier for Debian Developers. I also did some work and planning for the MiniDebConf Online Gaming Edition that we’ll likely announce within the next 1-2 days. Just a bunch of content that needs to be fixed and a registration bug then I think we’ll be ready to send out the call for proposals.
In the meantime, here’s my package uploads and sponsoring for September:
2020-09-07: Upload package calamares (3.2.30-1) to Debian unstable.
2020-09-07: Upload package gnome-shell-extension-dash-to-panel (39-1) to Debian unstable.
2020-09-08: Upload package gnome-shell-extension-draw-on-your-screen (6.2-1) to Debian unstable.
2020-09-08: Sponsor package sqlobject (3.8.0+dfsg-2) for Debian unstable (Python team request).
2020-09-08: Sponsor package bidict (0.21.0-1) for Debian unstable (Python team request).
2020-09-11: Upload package catimg (2.7.0-1) to Debian unstable.
2020-09-16: Sponsor package gamemode (1.6-1) for Debian unstable (Games team request).
Respond to queries from Debian users and developers on the mailing lists and IRC
Sponsors
The gensim, cython-blis, python-preshed, pytest-rerunfailures, morfessor, nmslib, visdom and pyemd work was sponsored by my employer.
All other work was done on a volunteer basis.
Since announcing plocate,
a number of major and minor improvements have happened, and despite its
prototype status, I've basically stopped using mlocate entirely now.
First of all, the database building now uses 90% less RAM, so if you had
issues with plocate-build OOM-ing before, you're unlikely to see that happening anymore.
Second, while plocate was always lightning-fast on SSDs or with everything
in cache, that isn't always the situation for everyone. It's so annoying
having a tool usually be instant, and then suddenly have a 300 ms hiccup
just because you searched for something rare. To get that case
right, real work had to be done; I couldn't just mmap up the index anymore
and search randomly around in it.
Long story short, mmap is out, and io_uring
is in. (This requires Linux 5.1 or later and liburing; if you don't have
either, it will transparently fall back to synchronous I/O. It will still
be faster than before, but not nearly as good.) I've been itching to try
io_uring for a while now, and this was suddenly the perfect opportunity.
Not because I needed more efficient I/O (in fact, I believe I drive it
fairly inefficiently, with lots of syscalls), but because it allows to run
asynchronous I/O without the pain of threads or old-style aio. It's unusual
in that I haven't heard of anyone else doing io_uring specifically to
gain better performance on non-SSDs; usually, it's about driving NVMe
drives or large amounts of sockets more efficiently.
plocate needs a fair amount of gather reads; e.g., if you search for
“plocate”, it needs to go to disk and fetch disk offsets for the posting
lists “plo”, “loc”, “oca”, “cat” and “ate”; and most likely, it will be needing all five of them.
io_uring allows me to blast off a bunch of reads at once, having the kernel
to reorder them as it sees fit; with some luck from the elevator
algorithm, I'll get all of them in one revolution of the disk, instead of
reading the first one and discovering the disk head had already passed the
spot where the second one was.
(After that, it needs to look at the offsets and actually get the posting lists,
which can then be decoded and intersected. This work can be partially
overlapped with the positions.)
Similar optimizations exist for reading the actual filenames.
All in all, this reduces long-tail latency significantly; it's hard to
benchmark cold-cache behavior faithfully (drop_caches doesn't actually
always drop all the caches, it seems), but generally, a typical cold-cache
query on my machine seems to go from 200–400 to 40–60 ms.
There's one part left that is synchronous; once a file is found,
plocate needs to go call access() to check that you're actually allowed
to see it. (Exercise: Run a timing attack against mlocate or plocate
to figure out which files exist on the system that you are not allowed
to see.) io_uring doesn't support access() as a system call yet;
I managed to sort-of fudge it by running a statx() asynchronously,
which then populates the dentry cache enough that synchronous access()
on the same directory is fast, but it didn't seem to help actual query
times. I guess that in a typical query (as opposed to “plocate a/b”,
which will give random results all over the disk), you hit only a few
directories anyway, and then you're just at the mercy of the latency
distribution of getting that metadata. And you still get the overlap
with the loads of the file name list, so it's not fully synchronous.
plocate also now no longer crashes if you run it without a pattern :-)
Get it at https://git.sesse.net/?p=plocate.
There still is no real release. You will need to regenerate your plocate.db,
as the file format has changed to allow for fewer seeks.
Here’s my (twelfth) monthly update about the activities I’ve done in the F/L/OSS world.
Debian
This was my 21st month of contributing to Debian.
I became a DM in late March last year and a DD last Christmas! \o/
I’ve been busy with my undergraduation stuff but I still squeezed out some time for the regular Debian work.
Here are the following things I did in Debian this month:
Sponsored trace-cmd for Sudip, ruby-asset-sync for Nilesh, and mariadb-mysql-kbs for William.
RuboCop::Packaging - Helping the Debian Ruby team! \o/
This Google Summer of Code, I worked on writing a linter that could flag offenses for lines of code
that are very troublesome for Debian maintainers while trying to package and maintain Ruby libraries and applications!
Whilst the GSoC period is over, I’ve been working on improving that tool and have extended that linter to now “auto-correct” these offenses
by itself! \o/
You can now just use the -A flag and you’re done! Boom! The ultimate game-changer!
I’ve also spent a considerable amount of time in raising awareness about this and in more general sense, about downstream maintenance.
As a result, I raised a bunch of PRs which got really good response. I got all of the 20 PRs merged upstream,
fixing these issues.
Debian (E)LTS
Debian Long Term Support (LTS) is a project to extend the lifetime of all Debian stable releases to (at least) 5 years. Debian LTS is not handled by the Debian security team, but by a separate group of volunteers and companies interested in making it a success.
And Debian Extended LTS (ELTS) is its sister project, extending support to the Jessie release (+2 years after LTS support).
This was my twelfth month as a Debian LTS and third month as a Debian ELTS paid contributor.
I was assigned 19.75 hours for LTS and 15.00 hours for ELTS and worked on the following things:
(for LTS, I over-worked for 11 hours last month on the survey so only had 8.75 hours this month!)
LTS CVE Fixes and Announcements:
Issued DLA 2362-1, fixing CVE-2020-11984, for uwsgi.
For Debian 9 Stretch, these problems have been fixed in version 2.0.14+20161117-3+deb9u3.
Issued DLA 2363-1, fixing CVE-2020-17446, for asyncpg.
For Debian 9 Stretch, these problems have been fixed in version 0.8.4-1+deb9u1.
Issued ELA 274-1, fixing CVE-2020-11984, for uwsgi.
For Debian 8 Jessie, these problems have been fixed in version 2.0.7-1+deb8u3.
Issued ELA 275-1, fixing CVE-2020-14363, for libx11.
For Debian 8 Jessie, these problems have been fixed in version 2:1.6.2-3+deb8u4.
Issued ELA 278-1, fixing CVE-2020-8184, for ruby-rack.
For Debian 8 Jessie, these problems have been fixed in version 1.5.2-3+deb8u4.
Also worked on updating the version of clamAV from v0.101.5 to v0.102.4.
This was a bit tricky package to work on since it involved an ABI/API change and was more or less a transition.
Super thanks to Emilio for his invaluable help and him taking over the package, finishing, and uploading it in the end.
Other (E)LTS Work:
Front-desk duty from 31-08 to 06-09 and from 28-09 onward for both LTS and ELTS.
I keep forgetting how to make presentations. I had a list of tools in
a wiki from a previous job, but that's now private and I don't see why
I shouldn't share this (even if for myself!).
So here it is. What's your favorite presentation tool?
Tips
if you have some text to present, outline keywords so that you
can present your subject without reading every word
ideally, don't read from your slides - they are there to help
people follow, not for people to read
even better: make your slides pretty with only a few words, or
don't make slides at all
I'm currently using Pandoc with PDF input (with a trip through LaTeX)
for most slides, because PDFs are more reliable and portable than web
pages. I've also used Libreoffice, Pinpoint, and S5 (through RST) in
the past. I miss Pinpoint, too bad that it died.
Another option I have seriously considered is just generate a series
of images with good resolution, hopefully matching the resolution (or
at least aspect ratio) of the output device. Then you flip through a
series of images one by one. In that case, any of those image viewers
(not an exhaustive list) would work:
Update: it turns out I already wrote a somewhat similar thing when I
did a recent presentation. If you're into rants, you might enjoy the
README file accompanying the Kubecon rant presentation. TL;DR:
"makes me want to scream" and "yet another unsolved problem space,
sigh" (refering to "display images full-screen" specifically).
Running new hardware is always fun.
The problems are endless.
The solutions not so much.
So I've got a brand new ThinkPad X13 AMD.
It features an AMD Ryzen 5 PRO 4650U, 16GB of RAM and a 256GB NVME SSD.
The internal type identifier is 20UF.
It runs the latest firmware as of today with version 1.09.
So far I found two problems with it:
It refuses to boot my Debian image with Secure Boot enabled.
It produces ACPI errors on every key press on the internal keyboard.
Disable Secure Boot
The system silently fails to boot a signed shim and grub from an USB thumb drive.
I used on of the Debian Cloud images, which should properly work in this setup and do on my other systems.
The only fix I found was to disable Secure Boot alltogether.
Select Linux in firmware
Running a Linux 5.8 with default firmware setting produces ACPI errors on each key press.
ACPI BIOS Error (bug): Could not resolve symbol [\_SB.PCI0.GPP3], AE_NOT_FOUND (20200528/psargs-330)ACPI Error: Aborting method \_SB.GPIO._EVT due to previous error (AE_NOT_FOUND) (20200528/psparse-529)
This can be "fixed" by setting a strategic setting inside the firmware: Config > Power > Sleep State to Linux
Here is my monthly update covering what I have been doing in the free software world during September 2020 (previous month):
Updated my tickle-me-email library (which implements Getting Things Done (GTD)-like behaviours in IMAP inboxes) to support adding 'TODO' entries as read or unread based on a runtime configuration parameter. [...]
As part of my role of being the assistant Secretary of the Open Source Initiative and a board director of Software in the Public Interest, I attended their respective monthly meetings and participated in various licensing and other discussions occurring on the internet as well as the usual internal discussions, etc. I participated in the OSI's inaugural State of the Source conference and began the 'onboarding' of a new project to SPI.
One of the original promises of open source software is that distributed peer review and transparency of process results in enhanced end-user security. However, whilst anyone may inspect the source code of free and open source software for malicious flaws, almost all software today is distributed as pre-compiled binaries. This allows nefarious third-parties to compromise systems by injecting malicious code into ostensibly secure software during the various compilation and distribution processes.
The motivation behind the Reproducible Builds effort is to ensure no flaws have been introduced during this compilation process by promising identical results are always generated from a given source, thus allowing multiple third-parties to come to a consensus on whether a build was compromised.
The project is proud to be a member project of the Software Freedom Conservancy. Conservancy acts as a corporate umbrella allowing projects to operate as non-profit initiatives without managing their own corporate structure. If you like the work of the Conservancy or the Reproducible Builds project, please consider becoming an official supporter.
Also include the general news in our RSS feed [...] and drop including weekly reports from the RSS feed (they are never shown now that we have over 10 items) [...].
Update ordering and location of various news and links to tarballs, etc. [...][...][...]
For Lintian, the static analysis tool for Debian packages, I uploaded versions 2.93.0, 2.94.0, 2.95.0 & 2.96.0 (not counting uploads to the backports repositories), as well as:
Frontdesk duties, responding to user/developer questions, reviewing others' packages, attending our monthly IRC meeting, participating in mailing list discussions, etc.
Issued DLA 2368-1 for grunt to fix an arbitrary code execution
vulnerability due to the unsafe loading of YAML documents.
Issued DLA 2370-1 and ELA-281-1 for the python-pip Python package installer to fix a directory traversal attack where arbitrary local files (eg. /root/.ssh/authorized_keys) could be overridden.
Issued DLA 2372-1 and ELA-282-1 to prevent a denial of service attack in libproxy, a library to make applications HTTP proxy-aware.
Issued DLA 2374-1 for the gnome-shell component of the GNOME desktop. In certain configurations, when logging out of an account, the password box from the login dialog could reappear with the password visible in plaintext.
Issued DLA 2380-1 for ruby-gon, a library to send/convert data to
Javascript from Ruby applications, to prevent cross-site scripting (XSS) vulnerabilities.
You can find out more about the project via the following video:
Before and during FOSDEM 2020, I agreed with the people (developers, supporters, managers) of the UBports Foundation to package the Unity8 Operating Environment for Debian. Since 27th Feb 2020, Unity8 has now become Lomiri.
Recent Uploads to Debian related to Lomiri
Over the past 4 months I worked on the following bits and pieces regarding Lomiri in Debian:
Work on lomiri-app-launch (Debian packaging, upstream work, upload to Debian)
Fork lomiri-url-dispatcher from url-dispatcher (upstream work)
Upload lomiri-url-dispatcher to Debian
Fork out suru-icon-theme and make it its own upstream project
Package and upload suru-icon-theme to Debian
First glance at lomiri-ui-toolkit (currently FTBFS, needs to be revisited)
Update of Mir (1.7.0 -> 1.8.0) in Debian
Fix net-cpp FTBFS in Debian
Fix FTBFS in gsettings-qt.
Fix FTBFS in mir (support of binary-only and arch-indep-only builds)
Coordinate with Marius Gripsgard and Robert Tari on shift over from Ubuntu Indicator to Ayatana Indicators
Upload ayatana-indicator-* (and libraries) to Debian (new upstream releases)
Package and upload to Debian: qmenumodel (still in Debian's NEW queue)
Package and upload to Debian: ayatana-indicator-sound
Symbol-Updates (various packages) for non-standard architectures
Fix FTBFS of qtpim-opensource-src in Debian since Qt5.14 had landed in unstable
Fix FTBFS on non-standard architectures of qtsystems, qtpim and qtfeedback
Fix wlcs in Debian (for non-standard architectures), more Symbol-Updates (esp. for the mir DEB package)
Symbol-Updates (mir, fix upstream tinkering with debian/libmiral3.symbols)
Fix FTBFS in lomiri-url-dispatcher against Debian unstable, file merge request upstream
Upstream release of qtmir 0.6.1 (via merge request)
Improve check_whitespace.py script as used in lomiri-api to ignore debian/ subfolder
Upstream release of lomiri-api 0.1.1 and upload to Debian unstable.
The next two big projects / packages ahead are lomiri-ui-toolkit and qtmir.
Credits
Many big thanks go to Marius and Dalton for their work on the UBports project and being always available for questions, feedback, etc.
Thanks to Ratchanan Srirattanamet for providing some of his time for debugging some non-thread safe unit tests (currently unsure, what package we actually looked at...).
Thanks for Florian Leeber for being my point of contact for topcis regarding my cooperation with the UBports Foundation.
Previous Posts about my Debian UBports Team Efforts
When building route filters with bgpq4 or bgpq3, the speed of
rr.ntt.net or whois.radb.net can be a bottleneck. Updating many
filters may take several tens of minutes, depending on the load:
$time bgpq4 -h whois.radb.net AS-HURRICANE | wc -l
9098691.96s user 0.15s system 2% cpu 1:17.64 total$time bgpq4 -h rr.ntt.net AS-HURRICANE | wc -l
9278651.86s user 0.08s system 12% cpu 14.098 total
A possible solution is to run your own IRRd instance in your
network, mirroring the main routing registries. A close
alternative is to bundle IRRd with all the data in a
ready-to-use Docker image. This also has the advantage of easy
integration into a Docker-based CI/CD pipeline.
$ git clone https://github.com/vincentbernat/irrd-legacy.git -b blade/master
$cd irrd-legacy
$ docker build . -t irrd-snapshot:latest
[…]Successfully built 58c3e83a1d18Successfully tagged irrd-snapshot:latest$ docker container run --rm --detach --publish=43:43 irrd-snapshot
4879cfe7413075a0c217089dcac91ed356424c6b88808d8fcb01dc00eafcc8c7$time bgpq4 -h localhost AS-HURRICANE | wc -l
9041371.72s user 0.11s system 96% cpu 1.881 total
assembling the final container with the result of the two previous stages.
The second stage fetches the databases used by rr.ntt.net:
NTTCOM, RADB, RIPE, ALTDB, BELL, LEVEL3, RGNET, APNIC, JPIRR, ARIN,
BBOI, TC, AFRINIC, ARIN-WHOIS, and REGISTROBR. However, it misses
RPKI.2 Feel free to adapt!
The image can be scheduled to be rebuilt daily or weekly, depending on
your needs. The repository includes a .gitlab-ci.yaml
file automating the build and triggering the compilation
of all filters by your CI/CD upon success.
Instead of using the latest version of IRRd, the image
relies on an older version that does not require a PostgreSQL
instance and uses flat files instead. ↩︎
Unlike the others, the RPKI database is built from the
published RPKI ROAs. They can be retrieved with rpki-client and
transformed into RPSL objects to be imported in IRRd. ↩︎
 Stars! Lots of stars! And mountains…
Stars! Lots of stars! And mountains…








 Like
Like 




 github activity october 2013 to october 2014
github activity october 2013 to october 2014
 github activity october 2014 to october 2015
github activity october 2014 to october 2015
 github activity october 2015 to october 2016
github activity october 2015 to october 2016
 github activity october 2016 to october 2017
github activity october 2016 to october 2017
 github activity october 2017 to october 2018
github activity october 2017 to october 2018
 github activity october 2018 to october 2019
github activity october 2018 to october 2019
 github activity october 2018 to october 2019
github activity october 2018 to october 2019







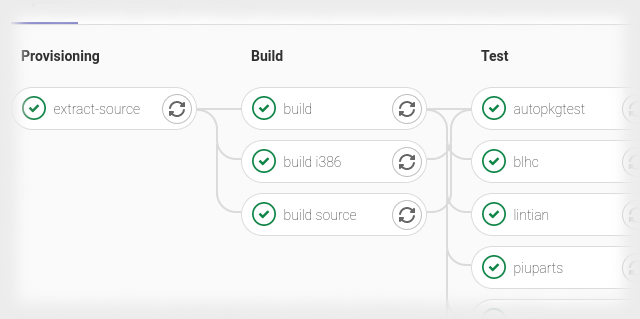

















































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}