
In the usual ‘circuit model’ of quantum computation, we have a fixed number of qubits, {q1, q2, …, qn}, and allow quantum gates to act on these qubits. The diagram below shows a Toffoli gate on the left, and an equivalent circuit of simpler gates on the right:

These diagrams represent qubits as horizontal lines (so there are 3 qubits in the circuit above), and the operations are applied from left to right. The circuit has 6 controlled-NOT gates (each acting on an ordered pair of qubits) and 9 single-qubit gates (4 T-gates, 3 inverse T-gates, and 2 Hadamard gates).
Whereas the internal state of a classical computer with n bits of memory can be described by a length-n vector of binary values, a quantum computer with n qubits of memory requires a length-(2^n) vector of complex numbers. A k-qubit gate is a unitary linear map described by a (2^k)-by-(2^k) matrix of complex numbers.
Importantly, it’s the exponential increase in the dimension of this vector (from n to 2^n), and not the involvement of complex numbers, which makes quantum computers [believed to be] able to solve more problems [in polynomial time] than is possible with a mere classical computer. To see this is the case, note that a (2^k)-by-(2^k) matrix of complex numbers can be emulated by a (2^(k+1))-by-(2^(k+1)) matrix of real numbers. Specifically, replace each complex entry with a real 2-by-2 block:
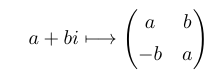
Consequently, a k-qubit complex gate can be emulated with a (k+1)-qubit real gate.
Indeed, it’s possible to restrict to not only real entries, but even to dyadic rational entries. Specifically, the most common universal set of logic gates {T, H, CNOT} consists of matrices whose entries belong to the ring ![\mathbb{Z}[\frac{1}{2}, \zeta]](https://web.archive.org./web/20200517193642im_/https://s0.wp.com/latex.php?latex=%5Cmathbb%7BZ%7D%5B%5Cfrac%7B1%7D%7B2%7D%2C+%5Czeta%5D&bg=ffffff&fg=333333&s=0 "\mathbb{Z}[\frac{1}{2}, \zeta]")

This is helpful for simulation in software: all finite values representable as IEEE 754 floating point numbers are dyadic rationals, and a partial converse is true: all dyadic rationals with numerator and denominator less than some bound (2^53 for double-precision and 2^24 for single-precision) are representable as IEEE 754 floating point numbers.
A universal pair of 3-qubit dyadic rational gates
Consider the Toffoli gate (left) and a new gate that I’m going to call the ‘XHH’ gate (it’s simply a tensor product of a Pauli X-gate and two Hadamard gates, all acting on separate qubits):

In an n-qubit circuit, each of these gates yields n(n – 1)(n – 2)/2 different matrices depending on the choice of qubits on which it acts, so this set expands to n(n – 1)(n – 2) matrices in total. Then we have the following universality theorem:
When n >= 4, the group generated by these matrices is a dense subgroup of the complete rotation group SO(2^n).
This is the best that we could hope for: when tensored by (n – 3) copies of the 2-by-2 identity matrix, these gates yield orthogonal matrices of determinant 1. It means that any special orthogonal gate can be approximated arbitrarily closely (in a number of gates polylogarithmic in the required precision, by the Solovay-Kitaev theorem), which (together with the above discussion of emulating complex unitary gates with real orthogonal gates) yields universal quantum computation.
An eight-dimensional surprise
More interesting is what happens when n = 3: the gates do not form a dense subgroup of O(8) as we might expect from extrapolating this result downwards (and noting that the Toffoli matrix has determinant -1, so the matrices lie in O(8) instead of SO(8) when n = 3).
Rather, they form a finite group of order 696729600.
This number should be familiar from the last post, because it’s the order of the E8 Weyl group. Every entry of every matrix in this group is not only dyadic rational, but in fact an integer multiple of 1/4. Inter alia, this finite group contains the familiar single-qubit Pauli gates X and Z, as well as the two-qubit CNOT gate.

Orthogonal projection of the 8-dimensional E8 root system into its 2-dimensional Coxeter plane, drawn by J. G. Moxness. The symmetry group of this set of 240 points is the aforementioned E8 Weyl group of order 696729600.
Given a starting state where all qubits are off (so the vector is (1, 0, 0, 0, 0, 0, 0, 0)), by applying these two gates in various combinations it is possible to reach any of 2160 different vectors (specifically, rescaled copies of the 2160 vectors in the second shell of the E8 lattice). If we instead began with an equal superposition of the eight computational basis states, there would be 240 reachable vectors — the root lattice vectors illustrated in the picture above! Again, the numbers 240 and 2160 should be very familiar from the previous article.
(Vectors that are related by scalar multiplication are identified as the same quantum state, so antipodal pairs of vectors in the previous paragraph correspond to the same quantum state. Consequently, there are only 1080 distinct quantum states reachable from the all-off quantum state, or 120 distinct quantum states reachable from the )
Before I found the set {Toffoli, XHH}, I tried the deceptively similar pair {Toffoli, ZHH}. To my surprise, the program I used to compute the group generated by those elements had an order of 2903040 — significantly smaller than the 696729600-element group I had expected! This is the Weyl group of E7, and in this case we get the smaller subgroup because all six matrices fix the vector (1, 1, 1, -1, 1, -1, -1, -1) and therefore only act nontrivially on its seven-dimensional orthogonal complement. Fortunately, the set {Toffoli, XHH} does not have a fixed vector and generates the full Weyl group of E8.
Unanswered questions
The {Toffoli, ZHH} construction of the E7 Weyl group demonstrates that we can realise the origin-preserving isometry group of a 7-dimensional lattice, even though 7 is not a power of two. An even more beautiful and exceptional lattice than the E8 lattice is the 24-dimensional Leech lattice, whose origin-preserving symmetry group is the Conway group Co0. Is there an elegant set of matrices which generate a group isomorphic to Co0 and have a simple description in terms of quantum gates?
The first nonempty shell of the Leech lattice consists of 196560 points, as opposed to the 240 points in the first shell of the E8 lattice. David Madore has plotted some beautiful projections of this set — they’re as close as possible to being analogous to the Petrie projection of the E8 root system shown above, except inasmuch as Co0 is not a Coxeter group and therefore it’s unclear which plane (if any!) is analogous to the Coxeter plane.
 from the origin in the E8 lattice, a highly symmetric arrangement of points which Maryna Viazovska recently (in 2016) proved is the densest way to pack spheres in 8-dimensional space.
from the origin in the E8 lattice, a highly symmetric arrangement of points which Maryna Viazovska recently (in 2016) proved is the densest way to pack spheres in 8-dimensional space. , but of complex (alas, not projective) 4-space,
, but of complex (alas, not projective) 4-space,  . Specifically, recall the Eisenstein integers, the ring of complex numbers generated by a cube root of unity:
. Specifically, recall the Eisenstein integers, the ring of complex numbers generated by a cube root of unity:
 ) to 0, +1, or −1. The E8 lattice is then concisely expressible as the set of points (w, x, y, z) where:
) to 0, +1, or −1. The E8 lattice is then concisely expressible as the set of points (w, x, y, z) where: . A point
. A point  \in \mathbb{F}_3^4") belongs to the tetracode if and only if w = y − x = z − y = x − z. Equivalently, the coordinates are of the form (d, a, a + d, a − d).
belongs to the tetracode if and only if w = y − x = z − y = x − z. Equivalently, the coordinates are of the form (d, a, a + d, a − d).









 different rules, where
different rules, where  is the number of distinct neighbourhoods that can occur. (We get equality
is the number of distinct neighbourhoods that can occur. (We get equality  in the case of asymmetric rules, but for rules with symmetries the count is more complex and depends on the
in the case of asymmetric rules, but for rules with symmetries the count is more complex and depends on the  .
.
 , where (a, b, c, d) are the four input signals, and indexes into a 4096-element lookup table to retrieve a value between 0 and 7 (the new ‘state’ of the machine). If 0, it immediately self-destructs without constructing any children; if nonzero, it constructs a daughter machine in each vacant space. Finally, it broadcasts the new state as a signal to all four neighbours, before self-destructing anyway.
, where (a, b, c, d) are the four input signals, and indexes into a 4096-element lookup table to retrieve a value between 0 and 7 (the new ‘state’ of the machine). If 0, it immediately self-destructs without constructing any children; if nonzero, it constructs a daughter machine in each vacant space. Finally, it broadcasts the new state as a signal to all four neighbours, before self-destructing anyway.