Engineering and Developers Blog
What's happening with engineering and developers at YouTube
Machine learning for video transcoding
Friday, May 13, 2016
At YouTube we care about the quality of the pixels we deliver to our users. With many millions of devices uploading to our servers every day, the content variability is so huge that delivering an acceptable audio and video quality in all playbacks is a considerable challenge. Nevertheless, our goal has been to continuously improve quality by reducing the amount of compression artifacts that our users see on each playback. While we could do this by increasing the bitrate for every file we create, that would quite easily exceed the capacity of many of the network connections available to you. Another approach is to optimize the parameters of our video processing algorithms to meet bitrate budgets and minimum quality standards. While Google’s compute and storage resources are huge, they are finite and so we must temper our algorithms to
also
fit within compute requirements. The hard problem then is to adapt our pipeline to create the best quality output for each clip you upload to us, within constraints of quality, bitrate and compute cycles.
This is a well known triad in the world of video compression and transcoding. The problem is usually solved by finding a sweet spot of transcoding parameters that seem to work well on average for a large number of clips. That sweet spot is sometimes found by trying every possible set of parameters until one is found that satisfies all the constraints. Recently, others have been using this “exhaustive search” idea to tune parameters on a per clip basis.
What we’d like to show you in this blog post is a new technology we have developed that adapts our parameter set for each clip automatically using Machine Learning. We’ve been using this over the last year for improving the quality of movies you see on YouTube and Google Play.
The good and bad about parallel processing
We ingest more than 400 hours of video per minute. Each file must be transcoded from the uploaded video format into a number of other video formats with different codecs so we can support playback on any device you might have. The only way we can keep up with that rate of ingest and quickly show you your transcoded video in YouTube is to break each file in pieces called “chunks,” and process these in parallel. Every chunk is processed independently and simultaneously by CPUs in our Google cloud infrastructure. The complexity involved in chunking and recombining the transcoded segments is significant. Quite aside from the mechanics of assembling the processed chunks, maintaining the quality of the video in each chunk is a challenge. This is because to have as speedy a pipeline as possible, our chunks don’t overlap, and are also very small; just a few seconds. So the good thing about parallel processing is increased speed and reduced latency. But the bad thing is that without the information about the video in the neighboring chunks, it’s now difficult to control chunk quality so that there is no visible difference between the chunks when we tape them back together. Small chunks don’t give the encoder much time to settle into a stable state hence each encoder treats each chunk slightly differently.
Smart parallel processing
You could say that we are shooting ourselves in the foot before starting the race. Clearly, if we communicate information about chunk complexity between the chunks, each encoder can adapt to what’s happening in the chunks after or before it. But inter-process communication increases overall system complexity and requires some extra iterations in processing each chunk.
Actually, OK, truth is we’re stubborn here in Engineering and we wondered how far we could push this idea of “don’t let the chunks talk to each other.”
The plot below shows an example of the PSNR in dB per frame over two chunks from a 720p video clip, using H.264 as the codec. A higher value of PSNR means better picture quality and a lower value means poorer quality. You can see that one problem is the quality at the start of a chunk is very different from that at the end of the chunk. Aside from the average quality level being worse than we would like, this variability in quality causes an annoying pulsing artifact.
Because of small chunk sizes, we would expect that each chunk behaves like the previous and next one, at least statistically. So we might expect the encoding process to converge to roughly the same result across consecutive chunks. While this is true much of the time, it is not true in this case. One immediate solution is to change the chunk boundaries so that they align with high activity video behavior like fast motion, or a scene cut. Then we would expect that each chunk is relatively homogenous so the encoding result should be more uniform. It turns out that this does improve the situation, but not as much as we’d like, and the instability is still often there.
The key is to allow the encoder to process each chunk multiple times, learning on each iteration how to adjust its parameters in anticipation of what happens in across the entire chunk instead of just a small part of it. This results in the start and end of each chunk having similar quality, and because the chunks are short, it is now more likely that the differences across chunk boundaries are also reduced. But even then, we noticed that it can take quite a number of iterations for this to happen. We observed that the number of iterations is affected a great deal by the quantization related parameter (CRF) of the encoder on that first iteration. Even better, there is often a “best” CRF that allows us to hit our target bitrate at a desired quality with just one iteration. But this “best” setting is actually different for every clip. That’s the tricky bit. If only we could work out what that setting was for each clip, then we’d have a simple way of generating good looking clips without chunking artifacts.
The plot on the right shows the result of many experiments with our encoder at varying CRF (constant quality) settings, over the same 1080p clip. After each experiment we measured the bitrate of the output file and each point shows the CRF, bitrate pair for that experiment. There is a clear relationship between these two values. In fact it is very well modeled as an exponential fit with three parameters, and the plot shows just how good that modeled line is in fitting the observed data points. If we knew the parameters of the line for our clip, then we’d see that to create a 5 Mbps version of this clip (for example) we’d need a CRF of about 20.
Pinky and the Brain
What we needed was a way to predict our three curve fitting parameters from low complexity measurements about the video clip. This is a classic problem in machine learning, statistics and signal processing. The gory mathematical details of our solution are in technical papers that we published recently.
1
You can see there how our thoughts evolved. Anyway, the idea is rather simple: predict the three parameters given things we know about the input video clip, and read off the CRF we need. This prediction is where the “Google Brain” comes in.
The “things we know about the input video clip” are called video “features.” In our case there are a vector of features containing measurements like input bit rate, motion vector bits in the input file, resolution of the video and frame rate. These measurements can also be made from a very fast low quality transcode of the input clip to make them more informative. However, the exact relationship between the features and the curve parameters for each clip is rather more complicated than an equation we could write down. So instead of trying to discover that explicitly ourselves, we turned to Machine Learning with Google Brain. We first took about 10,000 video clips and exhaustively tested every quality setting on each, measuring the resulting bitrate from each setting. This gave us 10,000 curves which in turn gave us 4 x 10,000 parameters measured from those curves.
The next step was to extract features from our video clips. Having generated the training data and the feature set, our Machine Learning system learned a “Brain” configuration that could predict the parameters from the features. Actually we used both a simple “regression” technique as well as the Brain. Both outperformed our existing strategy. Although the process of training the Brain is relatively computationally heavy, the resulting system was actually quite simple and required only a few operations on our features. That meant that the compute load in production was small.
Does it work?
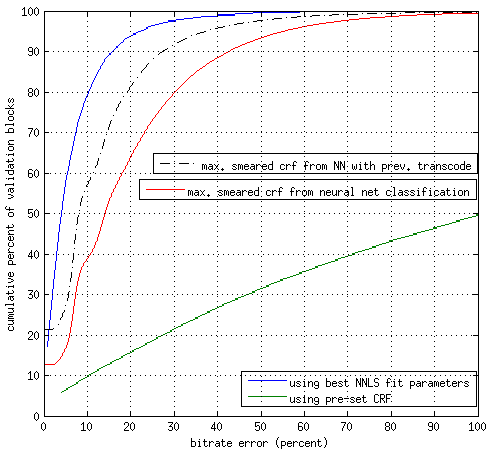
The plot on the right shows the performance of the various systems on 10,000 video clips. Each point (x,y) represents the percentage of clips (y-axis) in which the resulting bitrate after compression is within x% of the target bitrate. The blue line shows the best case scenario where we use exhaustive search to get the perfect CRF for each clip. Any system that gets close to that is a good one. As you can see at the 20% rate, our old system (green line) would hit the target bitrate 15% of the time. Now with our fancy Brain system we can hit it 65% of the time if we use features from your upload only (red line), and better than 80% of the time (dashed line) using some features from a very fast low quality transcode.
But does this actually look good? You may have noticed that we concentrated on our ability to hit a particular bitrate rather than specifically addressing picture quality. Our analysis of the problem showed that this was the root cause. Pictures are the proof of the pudding and you can see some frames from a 720p video clip below (shot from a racing car). The top row shows two frames at the start and end of a typical chunk and you can see that the quality in the first frame is way worse than the last. The bottom row shows the frames in the same chunk using our new automated clip adaptive system. In both cases the measured bitrate is the same at 2.8 Mbps. As you can see, the first frame is much improved and as a bonus the last frame looks better as well. So the temporal fluctuation in quality is gone and we also managed to improve the clip quality overall.
This concept has been used in production in our video infrastructure division for about a year. We are delighted to report it has helped us deliver very good quality streams for movies like "Titanic" and most recently "Spectre." We don’t expect anyone to notice, because they don’t know what it would look like otherwise.
But there is always more we can do to improve on video quality. We’re working on it. Stay tuned.
Anil Kokaram, Engineering Manager, AV Algorithms Team, recently watched "
Tony Cozier speaking about the West Indies Cricket Heritage Centre
," Yao Chung Lin, Software Engineer, Transcoder Team, recently watched "
UNDER ARMOUR | RULE YOURSELF | MICHAEL PHELPS
," Michelle Covell, Research Scientist, recently watched "
Last Week Tonight with John Oliver: Scientific Studies (HBO)
" and Sam John, Software Engineer, Transcoder Team, recently watched "
Atlantis Found: The Clue in the Clay | History
."
1
Optimizing transcoder quality targets using a neural network with an embedded bitrate model, Michele Covell, Martin Arjovsky, Yao-Chung Lin and Anil Kokaram, Proceedings of the Conference on Visual Information Processing and Communications 2016, San Francisco
Multipass Encoding for reducing pulsing artefacts in cloud based video transcoding, Yao-Chung Lin, Anil Kokaram and Hugh Denman, IEEE International Conference on Image Processing, pp 907-911, Quebec 2015
Because retro is in -- announcing historical data in the YouTube Reporting API
Tuesday, May 10, 2016
YouTube creators rely on data -- data about how their channel is performing, data about their video’s ratings, their earnings. Lots of data. That’s why we
launched the YouTube Reporting API
back in October, which helps you bulk up your data requests while keeping them on a low-quota diet.
Reports made with the API started from the day you scheduled them, going forward. Now that it’s been in the wild, we’ve heard another request loud and clear: you don’t just want current data, you want older data, too. We’re happy to announce that the Reporting API now delivers historical data covering 180 days prior to when the reporting job is first scheduled (or July 1st, 2015, whichever is later.)
Developers with a keen eye may have already noticed this, as it launched a few weeks ago! Just in case you didn’t, you can find more information on how historical data works by checking out the
Historical Data section
of the Reporting API docs.
(Hint: if you’ve already got some jobs scheduled, you don’t need to do anything! We’ll generate the data automatically.)
New to the Reporting API? Tantalized by the possibility of all that historical data? Our documentation explains everything you need to know about scheduling jobs and the types of reports available. Try it out with our
API Explorer
, then dive into the
sample code
or write your own with one of our
client libraries
.
Happy reporting,
YouTube Developer Relations on behalf of
Alvin Cham
,
Markus Lanthaler
,
Matteo Agosti
, and
Andy Diamondstein
Labels
.net
360
acceleration
access control
accessibility
actionscript
activities
activity
android
announcements
apis
app engine
appengine
apps script
as2
as3
atom
authentication
authorization
authsub
best practices
blackops
bootcamp
captions
categories
channels
charts
chrome
chromeless
client library
clientlibraries
clientlogin
code
color
comments
compositing
create
curation
custom player
decommission
default
deprecation
devs
direct
discovery
docs
Documentation RSS
dotnet
education
embed
embedding
events
extension
feeds
flash
format
friendactivity
friends
fun
gears
google developers live
google group
googlegamedev
googleio
html5
https
iframe
insight
io12
io2011
ios
iphone
irc
issue tracker
java
javascript
json
json-c
jsonc
knight
legacy
Live Streaming API
LiveBroadcasts API
logo
machine learning
mashups
media:keywords keywords tags metadata
metadata
mobile
mozilla
NAB 2016
news
oauth
oauth2
office hours
open source
partial
partial response
partial update
partners
patch
php
player
playlists
policy
previews
pubsubhubbub
push
python
quota
rails
releases
rendering
reports
responses
resumable
ruby
samples
sandbox
shortform
ssl https certificate staging stage
stack overflow
stage video
staging
standard feeds
storify
storyful
subscription
sup
Super Chat API
survey
tdd
theme
tos
tutorials
updates
uploads
v2
v3
video
video files
video transcoding
virtual reality
voting
VR
watch history
watchlater
webvtt
youtube
youtube api
YouTube Data API
youtube developers live
youtube direct
YouTube live
YouTube Reporting API
ytd
Archive
2017
Mar
Jan
2016
Nov
Oct
Aug
May
Apr
2015
Dec
Nov
Oct
May
Apr
Mar
Jan
2014
Oct
Sep
Aug
May
Mar
2013
Dec
Oct
Sep
Aug
Jul
Jun
May
Apr
Mar
Feb
2012
Dec
Nov
Sep
Aug
Jul
Jun
May
Apr
Mar
Feb
Jan
2011
Dec
Oct
Sep
Aug
Jul
Jun
May
Apr
Mar
Feb
Jan
2010
Dec
Nov
Oct
Sep
Jul
Jun
May
Apr
Mar
Feb
Jan
2009
Nov
Oct
Sep
Aug
Jul
Jun
May
Apr
Mar
Feb
Jan
2008
Dec
Nov
Oct
Sep
Aug
Jul
Jun
May
Apr
Mar
Feb
2007
Dec
Nov
Aug
Jun
May
Feed
YouTube
on
Follow @youtubedev