Invisible illness and disability in the library profession
Library workers with invisible illnesses and/or disabilities face barriers to succeeding in the workplace as described in the September 2023 College & Research Libraries article “Hidden Barriers: The Experience of Academic Librarians and Archivists with Invisible Illness and/or Disabilities.” The authors adapted their definition from the Invisible Disabilities Association, which defines an invisible disability as “a physical, mental or neurological condition that is not visible from the outside, yet can limit or challenge a person’s movements, senses, or activities. The article reports on their study of academic librarians and archivists with invisible illnesses and/or disabilities. The survey results indicate that much work is needed to increase understanding and support of the issue. Disclosing and requesting accommodations should be easy and without fear of repercussions. The authors noted that 58 percent of respondents chose not to disclose because it would be “too complicated or energy consuming.” On the positive side, the results indicate requested accommodations are often granted (82 percent), and people who disclose reported actionable support from their supervisors (59 percent).
The most striking statistic from this article was the number of respondents who identified their illness or disability as “invisible.” For both chronic illness and disability, the majority of those who identified as having one of these conditions identified it as invisible. This reminds us that individuals and organizations need to be proactive in creating an inclusive workplace for everyone. This article is also an important reminder that organizations committing to diversity and inclusion should include disability and accessibility-focused topics in their efforts. Contributed by Kate James.
The Archivists: The Unseen Fight to Preserve Our Stories
Latino USA producer Victoria Estrada visited the Nettie Lee Benson Latin American Collection at the University of Texas in Austin (OCLC Symbol: IXA). Her reporting is documented in The Archivists: The Unseen Fight to Preserve Our Stories. The Benson is one of the preeminent collections of Latin American collections, including holding the Latino USA archives.
One of the aspects of the Benson’s story that may be somewhat forgotten is that collecting practices were shaped by demands from students in the 1970s Ethnic Studies movement – due to student pressure, the Benson began collecting materials documenting the Latino / Latina experience in the United States. This episode also grapples with the complexities of colonial collecting practices and discusses institutional support for the Archive of Indigenous Languages of Latin America, a non-custodial archive. The Benson’s support for AILLA helps the institution to “move away from a logic of extraction in the archives.” Contributed by Merrilee Proffitt.
Toolkit for Program Challenges
In August 2022, the Association for Library Service to Children (ALSC) offered “Stand Up Against Book Challenges,” a blog post giving advice to library workers facing book bans (as noted in the “Advancing IDEAs” of 4 October 2022). Now in response to the increase in challenges to Drag Story Hours and other programs presented by libraries, ALSC’s School-Age Programs and Services Committee has prepared the Toolkit for Program Challenges, devoted to the issues unique to these situations. Similar to other tools, the ALSC guide suggests preventive actions to take before challenges, dealing with challenges as they are taking place, and means of following up afterwards, as well as links to additional helpful resources.
Knowing ways to prevent challenges to library programming, to deal with active challenges, and to recover from them are skills increasingly useful to all libraries in our contentious and tumultuous times. Contributed by Jay Weitz.
Kellogg Canada’s EDI efforts met with boycott threats
On 12 September 2023, the Boys and Girls Clubs of Canada announced they had partnered with Kellogg Canada, their Kellogg’s® Froot Loops® cereal brand, and Kids Can Press to create the Kellogg’s® Froot Loops® ED&I Digital Library, a free online library of EDI-focused content including books, podcasts, and more for parents and their children to explore together. The Digital Library went live in July and, beginning at the end of September, Kellogg’s® Froot Loops® cereal boxes appeared at grocery retailers across Canada with a 4-digit pin code to promote the Digital Library. By November, however, there were calls on the Internet to boycott Froot Loops® for their participation in the program.
While corporations, advocacy groups, and publishers are seeking new ways to promote EDI-focused resources for families, threats of product boycotts can undermine these efforts. Those who believe in a more diverse and inclusive society must express our support for projects like these or companies will be less likely to participate and promote similar EDI initiatives. Contributed by Morris Levy.
The LIL team is excited to welcome Katy Gero, who joins us to investigate ethical language models for creative writing. Katy is a post-doc at the Variation Lab at Harvard SEAS, which is led by friend of LIL Elena Glassman.
As part of her work, Katy will be investigating under what circumstances, if any, literary writers would want their own work included as training data in a language model. Through interviews within literary communities and their adjacent fields, she intends to understand what kind of data collection processes and notions of consent are appropriate in these communities.
Secondarily, Katy hopes to collect and release an open-source dataset in the appropriate manner, based on connections made during interviews. Time permitting, we would then train a Transformer model and begin investigations into the utility of such a model compared to other available models. All findings and potential dataset outputs will be publicly available upon their completion.
Katy’s work is part of our ongoing investigations into corners of the emerging AI landscape. Her particular interest in the creative writing world is of course a key point of overlap with the interests of the library world, but themes like copyright, consent, and communal knowledge also echo our values as a lab. To learn more about our AI work, you can visit our website.
“What in the world, Wimsey, are you doing in this Morgue?” Lord Peter is asked at the start of The Unpleasantness at the Bellona Club. Unknown to him, someone sitting in the club has indeed recently died. Miss Bates writes “everything is precariously tottering on the edge of tragedy” in this detective novel, as club members try in vain to keep up appearances in a world irrevocably changed by the Great War. Dorothy L. Sayers’ book joins the US public domain in 28 days. #PublicDomainDayCountdown
Librarians and archivists at York University Libraries are members of the York University Faculty Association, the union for full-time academic employees. Last year YUFA agreed to a new collective agreement. (The old agreement expired on 30 April 2021, and bargaining went very slowly for months, then suddenly very quickly after a strong strike vote. In March 2022 we ratified the 2021–2024 agreement, which was backdated to 1 May 2021. Now in 2023 we’re planning for the next round in 2024, which isn’t going to be smooth.)
Part of the new way of doing things is that a three-person file preparation committee works with the candidate to build the promotion file (a large document showing how the candidate meets or exceeds the criteria). Before, the candidate built it themselves. The new arrangement parallels the faculty process and is meant to make stronger files while reducing work and stress for candidates.
The technical work of building the file—assembling dozens of PDFs and PowerPoint slide decks into one PDF, with a proper table of contents and pagination—is nontrivial. I’m told some people do it with Adobe Acrobat Pro or PDF-XChange Editor, but that looked painfully finicky to me and involved proprietary software. Last year I was on a file prep committee and I volunteered to do it in LaTeX. That worked very well.
I turned what I did into a generic template and put it on GitHub: yufile. Here’s the sample table of contents.
Example of table of contents
The PDF has a good navigable structure:
The PDF has a proper structure
This requires some knowledge of LaTeX, which is also nontrivial (he said litotically). But when all the pieces are in place, rebuilding the file with new constituent documents is just a matter of replacing the old PDFs with the new ones and running one command (twice). Last minute change and two PDFs need updating, and they’re both different lengths than they were before? No problem. Copy file, copy file, run pdflatex twice, and it’s done. From what I hear, doing that with those proprietary programs would involve all kinds of clicking and editing and frustration. And perhaps learning some LaTeX by fiddling with a template and having some good luck will lead to using it more. If you’re interested in page design, typesetting and making beautiful documents, LaTeX is worth a look.
I hope this is useful to anyone doing file preparation at York or elsewhere.
Issue 58 of the Code4Lib Journal is bursting at the seams with examples of how libraries are creating new technologies, leveraging existing technologies, and exploring the use of AI to benefit library work. We had an unprecedented number of submissions this quarter and the resulting issue features 16 articles detailing some of the more unique and innovative technology projects libraries are working on today.
Following the recent transition from Inmagic to Ex Libris Alma, the Technical Services department at the University of Southern California (USC) in Los Angeles undertook a post-migration cleanup initiative. This article introduces methodologies aimed at improving irregular summary holdings data within serials records using Pymarc, regular expressions, and the Alma API in MarcEdit. The challenge identified was the confinement of serials' holdings information exclusively to the 866 MARC tag for textual holdings.
To address this challenge, Pymarc and regular expressions were leveraged to parse and identify various patterns within the holdings data, offering a nuanced understanding of the intricacies embedded in the 866 field. Subsequently, the script generated a new 853 field for captions and patterns, along with multiple instances of the 863 field for coded enumeration and chronology data, derived from the existing data in the 866 field.
The final step involved utilizing the Alma API via MarcEdit, streamlining the restructuring of holdings data and updating nearly 5,000 records for serials. This article illustrates the application of Pymarc for both data analysis and creation, emphasizing its utility in generating data in the MARC format. Furthermore, it posits the potential application of Pymarc to enhance data within library and archive contexts.
Technical services professionals in academic libraries are firmly committed to digital transformation and have embraced technologies and data practices that reshape their work to be more efficient, reliable, and scalable. Evolving systems, constantly changing workflows, and management of large-scale data are constants in the technical services landscape. Maintaining one’s ability to effectively work in this kind of environment involves embracing continuous learning cycles and incorporating new skills - which in effect means training people in a different way and re-conceptualizing how libraries provide support for technical services work. This article presents a micro lens into this space by examining the use of Python within a technical services environment. The authors conducted two surveys and eleven follow up interviews to investigate how Python is used in academic libraries to support technical services work and to learn more about training and organizational support across the academic library community. The surveys and interviews conducted for this research indicate that understanding the larger context of culture and organizational support are of high importance for illustrating the complications of this learning space for technical services. Consequently, this article will address themes that affect skills building in technical services at both a micro and macro level.
Since 2004, the FRASER Digital Library has provided free access to publications and archival collections related to the history of economics, finance, banking, and the Federal Reserve System. The agile web development team that supports FRASER’s digital asset management system embarked on an initiative to automate collecting documents and metadata from US governmental sources across the web. These sources present their content on web pages but do not serve the metadata and document links via an API or other semantic web technologies, making automation a unique challenge. Using a combination of third-party software, lightweight cloud services, and custom Python code, the FRASER Recurring Downloads project transformed what was previously a labor-intensive daily process into a metadata creation and ingest pipeline that requires minimal human intervention or quality control.
This article will provide an overview of the software and services used for the Recurring Downloads pipeline, as well as some of the struggles that the team encountered during the design and build process, and current use of the final product. The project required a more detailed plan than was designed and documented. The fully manual process was not intended to be automated when established, which introduced inherent complexity in creating the pipeline. A more comprehensive plan could have made the iterative development process easier by having a defined data model, and documentation of—and strategy for—edge cases. Further initial analysis of the cloud services used would have defined the limitations of those services, and workarounds could have been accounted for in the project plan. While the labor-intensive manual workflow has been reduced significantly, the required skill sets to efficiently maintain the automated workflow present a sustainability challenge of task distribution between librarians and developers. This article will detail the challenges and limitations of transitioning and standardizing recurring web scraping across more than 50 sources to a semi-automated workflow and potential future improvements to the pipeline.
The General Index is a free database that offers unprecedented access to keywords and ngrams derived from the full text of over 107 million scholarly articles. Its simplest use is looking up articles that contain a term of interest, but the data set is large enough for text mining and corpus linguistics. Despite being positioned as a public utility, there is no user interface; one must download, query, and extract results from raw data tables. Not only is computing skill a barrier to use, but the file sizes are too large for most desktop computers to handle. This article will show a practical way to use the GI for researchers with moderate skills and resources. It will walk though building a bibliography of articles and a visualizing yearly prevalence of a topic in the General Index, using simple R programming commands and a modestly equipped desktop computer (code is available at https://osf.io/s39n7/). It will briefly discuss what else can be done (and how) with more powerful computational resources.
At the University Libraries at Virginia Tech, we recently built a visual kiosk web app for helping patrons in our makerspace locate the tools they need and assist our staff in returning and inventorying our large selection of tools, machines, and consumables. The app is built in Svelte, and uses the Google Sheets "publish to web as csv" feature to pull data from a staff-maintained list of equipment in the space. All of this is tied to a Scalable Vector Graphics (SVG) file that is controlled by JavaScript and CSS to provide an interactive map of our shelving and storage locations, highlighting bins as patrons select specific equipment from a searchable list on the kiosk, complete with photos of each piece of equipment. In this article, you will learn why the app was made, the problems it has solved, why certain technologies were used and others weren't, the challenges that arose during development, and where the project stands to go from here.
This article will talk about how Binghamton University approached building a data dashboard bringing together various datasets, from MySQL, vendor emails, Alma Analytics and other sources. Using Power BI, Power Automate and a Microsoft gateway, we can see the power of easy access to data without knowing all of the disparate systems. We will discuss why we did it, some of the how we did it, and privacy concerns.
When the University of Michigan Library migrated from the Aleph Integrated Library System (ILS) to the Alma Library Services Platform (LSP), many challenges arose in migrating our workflows from a multi-tier client/server structured ILS with an in-house, locally hosted server which was accessed by staff through a dedicated client to a cloud-based LSP accessed by staff through a browser. Among those challenges were deficiencies in timely reporting functionality in the new LSP, and incompatibility with the locally popular macro software that was currently in use. While the Alma LSP includes a comprehensive business intelligence tool, Alma Analytics, which includes a wide variety of out-of-the-box reports and on-demand reporting, it suffers from one big limitation: the data on which the reports are based are a copy of the data from Alma extracted overnight. If you need a report of data from Alma that is timely, Analytics isn’t suitable. These issues necessitated the development of an application that brought together the utility of the Alma APIs and the convenience of the Google Apps Script platform. This article will discuss the resulting tool which provides a real-time report on invoice data stored in Alma using the Google Apps Script platform.
Airtable is an increasingly popular cloud-based format for entering and storing research data, especially in the digital humanities. It combines the simplicity of spreadsheets like CSV or Excel with a relational database’s ability to model relationships and link records. The Center for Digital Research in the Humanities (CDRH) at Nebraska uses Airtable data for two projects, African Poetics (africanpoetics.unl.edu) and Petitioning for Freedom (petitioningforfreedom.unl.edu). In the first project, the data focuses on African poets and news coverage of them, and in the second, the data focuses on habeas corpus petitions and individuals involved in the cases. CDRH’s existing software stack (designed to facilitate display and discovery) can take in data in many formats, including CSV, and parse it with Ruby scripts and ingest it into an API based on the Elasticsearch search index. The first step in using Airtable data is to download and convert it into a usable data format. This article covers the command line tools that can download tables from Airtable, the formats that can be downloaded (JSON being the most convenient for automation) and access management for tables and authentication. Python scripts can process this JSON data into a CSV format suitable for ingesting into other systems The article goes on to discuss how this data processing might work. It also discusses the process of exporting information from the join tables, Airtable’s relational database-like functionality. Join data is not human-readable when exported, but it can be pre-processed in Airtable into parsable formats. After processing the data into CSV format, this article touches on how CDRH API fields are populated from plain values and more complicated structures including Markdown-style links. Finally, this article discusses the advantages and disadvantages of Airtable for managing data, from a developer’s perspective.
Now that audio and video recording hardware is easy to use, highly portable, affordable, and capable of producing high quality content, many universities are seeing a rise in demand for oral history projects and programs on their campuses. The burden of preserving and providing access to this complex format typically falls on the library, oftentimes with no prior involvement or consultation with library staff. This can be challenging when many library staff have no formal training in oral history and only a passing familiarity with the format. To address this issue, librarians at the College of Charleston have implemented AVPreserve’s audiovisual content platform, Aviary, to build out a successful oral history program.
The authors will share their experience building new oral history programs that coexist alongside migrated audiovisual materials from legacy systems. They will detail how they approached migrating legacy oral histories in batch form, and how they leveraged Aviary’s API and embed functionalities to present Aviary audiovisual materials seamlessly alongside other cultural heritage materials in a single, searchable catalog. This article will also discuss techniques for managing an influx of oral histories from campus stakeholders and details on how to make efficient use of time-coded transcripts and indices for the best user experience possible.
CreateFSU is Florida State University Libraries’ branded Reclaim Hosting, Domain of One’s Own web-hosting service. CreateFSU provides current FSU faculty, staff, and some students web domains and over 150 popular open-source content management systems including Wordpress, Drupal, Scalar, and Omeka. Since the launch of the service in September 2021, the Libraries have negotiated the demands of providing such a service with various administrative stakeholders across campus, expanded the target audience, provided support and refined our workflows and documentation to make the service fit campus needs. Using this service, members of the FSU community showcase the fruits of their research to a broad audience in ways that are highly accessible and engaging. More work needs to be done to promote CreateFSU to the FSU community and identify opportunities to integrate the service into existing research and learning workflows. To expand the service to meet new use cases and ensure its scalability, the Libraries hope to convince campus partners to consider its utility to their missions and contribute funding. This article lays out our experiences in launching and hosting this service over its first two years and proposes steps for future development and growth.
This article is a case study describing the implementation of Islandora 2 to create a public online portal for the discovery, access, and use of archives and special collections materials at the University of Nevada, Las Vegas. The authors will explain how the goal of providing users with a unified point of access across diverse data (including finding aids, digital objects, and agents) led to the selection of Islandora 2 and they will discuss the benefits and challenges of using this open source software. They will describe the various steps of implementation, including custom development, migration from CONTENTdm, integration with ArchivesSpace, and developing new skills and workflows to use Islandora most effectively. As hindsight always provides additional perspective, the case study will also offer reflection on lessons learned since the launch, insights on open-source repository sustainability, and priorities for future development.
The University of Florida (UF) launched the UF Digital Collections in 2006. Since this time, the system has grown to over 18 million pages of content. The locally developed digital library system consisted of an integrated public frontend interface and a production backend. As with other monoliths, being able to adapt and make changes to the system became increasingly difficult as time went on and the size of the collections grew. As production processes changed, the system was modified to make improvements on the backend, but the public interface became dated and increasingly not mobile responsive. A decision was made to develop a new system, starting with decoupling the public interface from the production system. This article will examine our experience in rearchitecting our digital library system and deploying our new multi-portal, public-facing system. After an environmental scan of digital library technologies, it was decided to not use a current open-source digital library system. A relatively new programming team, who were new to the library ecosystem, allowed us to rethink many of our existing assumptions and provided new insights and development opportunities. Using technologies that include Python, APIs, ElasticSearch, ReactJS, PostgreSQL, and more, has allowed us to build a flexible and adaptable system that allows us to hire developers in the future who may not have experience building digital library systems.
Jupyter Notebooks are important outputs of modern scholarship, though the longevity of these resources within the broader scholarly record is still unclear. Communities and their creators have yet to holistically understand creation, access, sharing and preservation of computational notebooks, and such notebooks have yet to be designated a proper place among institutional repositories or other preservation environments as first class scholarly digital assets. Before this can happen, repository managers and curators need to have the appropriate tools, schemas and best practices to maximize the benefit of notebooks within their repository landscape and environments.
This paper explores the landscape of Jupyter notebooks today, and focuses on the opportunities and challenges related to bringing Jupyter Notebooks into institutional repositories. We explore the extent to which Jupyter Notebooks are currently accessioned into institutional repositories, and how metadata schemas like CodeMeta might facilitate their adoption. We also discuss characteristics of Jupyter Notebooks created by researchers at the National Center for Atmospheric Research, to provide additional insight into how to assess and accession Jupyter Notebooks and related resources into an institutional repository.
In June and July of 2023 the Palo Alto City Library’s Digital Services team embarked on an exploratory journey applying Large Language Models (LLMs) to library projects. This article, complete with chat transcripts and code samples, highlights the challenges, successes, and unexpected outcomes encountered while integrating ChatGPT Pro into our day-to-day work.
Our experiments utilized ChatGPTs Advanced Data Analysis feature (formerly Code Interpreter). The first goal tested the Search Engine Optimization (SEO) potential of ChatGPT plugins. The second goal of this experiment aimed to enhance our web user experience by revising our BiblioCommons taxonomy to better match customer interests and make the upcoming Personalized Promotions feature more relevant. ChatGPT helped us perform what would otherwise be a time-consuming analysis of customer catalog usage to determine a list of taxonomy terms better aligned with that usage.
In the end, both experiments proved the utility of LLMs in the workplace and the potential for enhancing our librarian’s skills and efficiency. The thrill of this experiment was in ChatGPT's unprecedented efficiency, adaptability, and capacity. We found it can solve a wide range of library problems and speed up project deliverables. The shortcomings of LLMs, however, were equally palpable. Each day of the experiment we grappled with the nuances of prompt engineering, contextual understanding, and occasional miscommunications with our new AI assistant. In short, a new class of skills for information professionals came into focus.
The accessibility of digital audiovisual (AV) collections is a difficult legal and ethical area that nearly all academic libraries will need to navigate at some point. The inclusion of AV accessibility features like captions and transcripts enormously benefit users with disabilities in addition to providing extra value to the repository more universally. However, implementing these features has proven challenging for many reasons. Recent technological advancements in automatic speech recognition (ASR) and its underlying artificial intelligence (AI) technology offer an avenue for librarians in stewarding more accessible collections. This article will discuss these opportunities and present research from Florida State University Libraries evaluating the performance of different ASR tools. The authors will also present an overview of basic AV accessibility-related concepts, ethical issues in using AI technology, and a brief technical discussion of captioning formats.
The paper presents the case for a decentralized and decoupled architecture for scholarly communication. An introduction to the Event Notifications protocol will be provided as being applied in projects such as the international COAR Notify Initiative and the NDE-Usable program by memory institutions in The Netherlands. This paper provides an implementation of Event Notifications using a Solid server. The processing of notifications can be automated using an orchestration service called Koreografeye. Koreografeye will be applied to a citation extraction and relay experiment to show all these tools fit together.
OKFN and Ushahidi teams in Addis Ababa during the DPGA summit (Photos: courtesy of Ushahidi)
The Open Knowledge Foundation’s contribution to the Digital Public Goods Alliance summit in Addis Ababa was a dedicated workshop unpacking how to fight disinformation with open data infrastructure and standards in the electoral context as part of a broader global project exploring Digital Public Infrastructure for Electoral Processes.
The interactive workshop examined cases where the lack of such infrastructure led to social unrest, chaos and debilitated democracies during the electoral process. It focused on how a healthy information ecosystem fights disinformation and the role open data infrastructures and standards play, drawing learnings from past experiences in Latin America and Africa.
It highlighted how an open infrastructure can lead to a healthy information ecosystem, increasing trust in democratic institutions, access to real-time factual information, accountability for results, and civic engagement before, during, and after election day.
The workshop dynamic was to engage in conversation and detect misinformation in three stages of the electoral process: voters’ registration, campaigns, and election day. Three questions were asked to ignite the debate:
What type of misinformation appears at each stage?
What digital tool, open data set or official information would be helpful to counteract it?
What digital public goods can help to fight it?
For each stage, there was a whiteboard with post-it notes so people could debate and write down their thoughts. This setup was key to bringing people together and fueling interaction among participants.
Results of the DPI Workshop
Given the various countries in the room, the conversation was rich and thorough, covering diverse problems from countries with different infrastructures for their electoral processes. This helped the audience understand what other countries are doing to solve misinformation issues and learn tactics to overcome their own challenges.
Here is a direct transcription of all the notes written on the boards:
Voters’ Registration
Problems
Lack of interoperability between systems
Not clear where to register or where to vote
Wrong information on eligibility
Wrong information on boundary delimitation (gerrymandering)
Incorrect forms or procedures for registering
Hard to update voters’ database
Physical databases are difficult to query
Delays in registration or not registering at all
Redundant registration
Tactics and Suggestions
Make it automatic to vote if you have an ID card
Automatic registration
Official/verified channel for information on how to register
Clear and accessible voter registration guidelines
Kenya had 2 general elections in 2017. Results were disputed
Uganda 2021 had candidate harassment
Ecuador 2023 had also violence and the assassination of a candidate
Campaign not to vote
TV Stations with live coverage repeat bogus claims from untrustable information
People radicalised by social media
Tactics and Suggestions
Curated channels of information to be established ahead of time. In Italy and the US are major TV stations, Government Resources, Public sites run by civil society
Transparent results publishing and dissemination
Disinformation datasets. Gather evidence of misinformation from previous elections
Useful DPGs
API for publishing results in a standardised format
First, it is critical that Digital Public Infrastructure can provide adaptable building blocks to build context-specific solutions. Given the diverse range of issues discussed across different countries, it becomes evident that a one-size-fits-all approach will not be effective. Digital Public Infrastructure for Electoral Processes cannot be developed as a general template on how to run elections. It should be a comprehensive toolkit with solutions for specific problems.
Second, Digital Public Goods (DPGs) hold immense potential in combating information pollution. Despite variations in electoral processes among different countries, many encounter similar challenges that can be effectively addressed using common Digital Public Infrastructure (DPI) building blocks. Consequently, establishing an ecosystem of open-source technologies that can be readily reused becomes crucial in addressing and mitigating the impacts of information pollution.
Lastly, we consider that making all the Electoral DPI open by design and by default will increase the trust and resilience of democracies.
As Irene Khan, UN Special Rapporteur on the promotion and protection of the right to freedom of opinion and expression, said: “Diverse and reliable information is an obvious antidote to disinformation and misinformation. States should fulfill their duty to ensure the right to information by increasing their own transparency and by proactively disclosing official data online.”
For that, the existence of open digital public infrastructure and shared practices is essential, and the workshop tried to shed light on such structural challenges and match them with the ambitious solutions the DPGA proposes.
In late September 2023, the University of Waterloo hosted a two-day workshop, “Building an Inter-Institutional and Cross-Functional Research Data Management Community: From Strategy to Implementation.” The goal of the event was to facilitate multi-institutional collaboration in Canada. It did this by bringing together cross-functional cohorts from several Canadian institutions, where each cohort team was comprised of a research administrator, an IT professional, and a librarian—a configuration which also helped strengthen intra-institutional relationships, as well.
This event was made possible by financial support from the Social Sciences and Humanities Research Council of Canada (SSHRC, one of the Canadian Tri-Agencies), and many other individuals and institutions contributed to the success of the event, including the University of Waterloo (host), University of Calgary, University of Ottawa, the Canadian Association of Research Libraries (CARL), OCLC, Compute Ontario, and the Digital Research Alliance of Canada.
The Canadian RDM policy environment
This event was convened in order to help institutions respond to national mandates announced by the Canadian Tri-Agencies (the Canadian Institutes of Health Research (CIHR), Natural Sciences and Engineering Research Council (NSERC), and Social Sciences and Humanities Research Council (SSHRC) are referred to collectively as the Tri-Agencies). In March 2021, the Canadian Tri-Agencies released a Research Data Management Policy that impacts research institutions, with these three primary components:
Data management plans (DMPs) are to be required with any grant proposal to a Tri-Agency. Roll out has begun, but slowly.
Any research institution receiving Tri-Agency funding (251 in all) was required to submit an RDM institutional strategy by March 2023. The strategies were intended to identify capacities and gaps, provide a snapshot of national RDM capacity, and support Tri-Agency planning.
Deposit of research data in an appropriate repository WILL be required, but dates and specifics are not yet defined by the Tri-Agencies.
Institutions have been responding to these requirements by establishing cross-functional teams. For example, the University of Waterloo established an RDM Institutional Strategy Working Group, charged by the Vice President for Research and International, the University Librarian, and the Chief Information Officer. This working group developed an institutional strategy for the university that evaluates current RDM capacities, identifies changes necessary to comply with funder policies, and charts a path forward for facilitating responsible data management across the research life cycle.
The March 2023 deadline for creating and submitting institutional RDM strategies has passed. Now what?
Well, theoretically, each institution should now turn its attention to the implementation of its local RDM strategy. But with complex issues like sensitive data storage and Indigenous data sovereignty, consultation and even partnership with other institutions is desirable. So the Canadian RDM community convened to explore how they might work collectively to address local challenges.
The RDM community workshop
The organizers originally anticipated convening cohorts from ten institutions at the workshop. But when 30 institutions expressed interest in attending, the organizers (with generous additional support from the two University of Waterloo units, the Library and the Office of the Vice President, Research and International) expanded the event to support greater community engagement.
The event was held on 27-29 September 2023 on the University of Waterloo campus, and the event offered a balanced program of presentations and small group discussions. The presentations offered a grounding in the goals of the Tri-Agencies RDM policy, a history of RDM in Canada, as well as brief deep dives into some of the challenging issues of data management, including:
Ethics, security, and sensitive data storage
Indigenous data sovereignty
Social interoperability and the challenges of collaboration
Harmonizing data management practices for multi-institutional research teams
But most of the event was spent engaged in fruitful discussion with others, as participants discussed challenges, experiences, and priorities in a variety of small group configurations, such as by:
Functional groups (i.e., with others from the functional areas of IT, research, or libraries)
Institutional type
Thematic challenges
Recommendations and priorities for action
Volunteers documented the conversations in a shared note taking environment, providing a rich, community-developed record to inform next steps.
Where is the community now?
These conversations surfaced the opportunities, challenges, and anxieties that participants face, including:
Cross-campus social interoperability is improving. Supporting RDM is an institutional effort, requiring multiple campus units to work together. Oftentimes, these campus units had little familiarity with each other, but many participants reported that over the past couple of years they’ve developed relationships with other stakeholder units. With continued effort, these collaborations are finally becoming easier. A feature of this workshop was bringing those people together—often traveling for hours together to get to the event—which no doubt further strengthened these relationships. Participants came from across the country–from Newfoundland to British Columbia to the Northwest Territories!
Little capacity for growth. Many participants expressed concerns and anxiety about their capacity to meet growing needs, an anxiety that seemed universal across institution size, resources, and home unit of all participants. Many participants already felt that they were working at or beyond capacity, which is all the more concerning considering that the Tri-Agencies hasn’t even implemented its data sharing requirements yet.
The library is expected to lead. It was clear from the discussions that non-library stakeholders (IT and the research office) hope that the library will assume many RDM responsibilities, particularly activities like helping researchers with data management plans (DMPs) as well as metadata curation. Librarians are worried. Clearly more staff resources are needed, but as one participant said, “If more money isn’t coming, what do we stop doing?”
Collaboration is essential for addressing complex challenges. There was widespread agreement that finding solutions to major challenges, such as how to manage and store sensitive data, should not be tackled at the institutional level. Instead, institutions must pool their knowledge and experience.
Institutions must address Indigenous data sovereignty. The Tri-Agencies policy recognizes that a “distinctions-based approach is needed to ensure that the unique rights, interests and circumstances of the First Nations, Métis, and Inuit are acknowledged, affirmed, and implemented” and aligns with the CARE Principles for Indigenous Data Governance. I heard about some institutional efforts, like institutions implementing Indigenous Review Boards (in addition to existing IRBs) or facilitating a community like the Indigenous Research Network at the University of Toronto. But there is widespread concern about “community exhaustion,” and perceptions that the consultation process with Indigenous peoples can be extractive and burdensome. Multi-institutional collaboration may emerge as a positive way to consult and scale.
What’s next?
Convening the event was just the beginning. The workshop team has now busily moved onto the next steps of this effort, including the establishment of a RDM community Slack channel, preliminary coding of the copious event notes, and convening a follow-up virtual meeting. And note, this effort builds upon previous strong Canadian collaboration around RDM.
A next big challenge is to effectively synthesize the knowledge shared in the workshop into a position paper with prioritized short- and long-term recommendations for the Canadian RDM community. This is an exciting collaborative effort–and all the more interesting because it unites libraries with other RDM stakeholders. A forthcoming OCLC Research report entitled Building Research Data Management Capacity: Case Studies in Strategic Library Collaboration will also be highly relevant to this effort. It provides a case study examination of the Canadian Portage Network effort led by CARL, and concludes with actionable recommendations that libraries can apply to make their own collaborations successful and sustainable.
(Mandolessi,
2023) makes a compelling argument that modern computing (the
Internet, the Web, mobile, all of it) hasn’t caused a
historical break or rupture in our understanding of how memory works.
Rather, digital technologies have extended our understanding of the
processes and practices of individual and collective memory. The new
digital technologies, their deployments, and the their integration in
social and cultural practices have presented opportunities to revisit
some theories and concepts from memory studies, and understand them
better. But the tech aren’t entirely new phenomena that require
completely rethinking memory prior to the web.
In the following, I will address what I propose are four major
transformations that collective memory has undergone in the digital era:
(1) the new ontology of the digital archive; (2) the shift from
narrative as a privileged form of collective memory to the cultural form
of the database; (3) the reconfiguration of agency, in which a
distributed memory is performed by human and nonhuman agents in a
dynamic entanglement; and (4) the shift from mnemonic objects to
mnemonic assemblages, comprising persons, things, artefacts, spaces,
discourses, behaviours and expressions in dynamic relatedness. In each
case, I will show how these changes put into practice – and even enhance
– the traits that define collective memory.
I think this perspective is actually really important for doing work in
the field. So much in information technology is designed to be shiny and
new, and to have no forebears. Mandolessi manages to synthesize and
integrate a large amount of previous work in media studies to make her
argument.
One of the new things I learned about in the process is Elena Esposito’s
argument that Artifical Intelligence (AI) (and machine learning) are
better understood as artificial communication(Esposito,
2022). I definitely want to follow up on this, since it seems
to be a clarifying concept (and it’s Open Access).
If you can’t make it through the Sage paywall and want a copy of the
PDF drop me an email.
References
Esposito, E. (2022). Artificial communication: how algorithms
produce social intelligence. Cambridge, Massachusetts: The MIT
Press. Retrieved from https://doi.org/10.7551/mitpress/14189.001.0001
We are becoming familiar with a new vocabulary and new practices: prompt engineering, image generation, hallucination, and so on. In my last post I noted how AI can be weird (to use Ethan Mollick&aposs term for it) because it may not always behave as expected, and can surprise. The structure and content of instructions can influence responses in different ways. I made the point that experience was important to understanding:
Because of this, it is important to build up some tacit knowledge of how these tools behave, and how they can surprise. Understanding the potential and limitations of AI tools depends on use, and on developing some experiential understanding of behaviours. To explain the difference between Perplexity.ai and ChatGPT one needs to have tried them out. To see the impact of prompt engineering techniques it is helpful to have tried different approaches and seen the quite different results one can achieve. And also to see different results across services. // Generative AI and libraries: 7 contexts
So, again, the best way to understand hallucination is to see actual examples of it. The best way to get a sense of why prompting is important is to try ChatGPT or one of the other tools and to see how structuring the prompt in particular ways or adding elements can change the outputs. To understand how search and AI may develop it is useful to actually try out perplexity.ai or Bing Chat (now rebranded as Copilot) to see the interplay between web search and AI. And so on.
Crafting an effective prompt is both an art and a science. It&aposs an art because it requires creativity, intuition, and a deep understanding of language. It&aposs a science because it&aposs grounded in the mechanics of how AI models process and generate responses. // Datacamp
Of course, experience alone cannot make you an expert in how LLMs work, although conversely knowing how they work certainly improves your interaction. Nor will experience alone reveal the ways in which dominant historical perspectives or attitudes influence the results, or which results may be fabricated. (An LLM is a Large Language Model, which is what powers ChatGPT and other services. For more about these, including some developed in the cultural and scholarly domains, see the longer AI posts linked below.)
In that context, I was rather struck by the binary contrast between techno-optimism and strong societal risk posed in the coverage of the somewhat depressing OpenAI board/CEO episode. Discussion of the current state of AI mostly ignored the pressing concerns around current issues and possible remediations (to do with composition of training data, documentation, hidden labor, mitigation of bias, and so on). (See the DAIR publications for examples of issues.)
In my last post, I discussed how understanding these issues was an important part of library work, related to new research skills, policy input, advocacy and other library roles. And also emphasized the need for staff support. Here I am interested in the specific point that understanding some of the general AI discussion benefits from experience in using tools and services.
It is helpful to try out services in areas where you have personal knowledge or expertise, so as to be able to weigh and assess. For example, when looking at a service I sometimes ask questions about Irish diaspora populations in the UK and the US, and differences in perceptions, influence, and so on. It is interesting to see variability across services, and again how prompting can guide responses. One can see an occasional leaning into stereotypes but also the ability to note the existence of stereotypes. Of course, this is very impressionistic - it will be interesting to see more research work on the cultural and social attitudes embedded in LLMs.
Discussion about the library itself is an interesting case. In my inexpert experience it has required quite a bit of prompting to move LLMs away from very stereotypical views of the library and librarians, based presumably on dominant public perceptions in training sets. This suggests in turn how much work we have to do to change the perception of the library in the public record that feeds the LLMs.
This suggests in turn how much work we have to do to change the perception of the library in the public record that feeds the LLMs.
I did not discuss image generation much in my earlier AI posts (links below) because I had not used them very much until recently. I have been looking a little more at DALL·E. The first image below is the response to a very straightforward and simple prompt &aposgenerate an image of a library.&apos It certainly leans into a classical view of what a library is, although I was interested to see the fire! I then iteratively tried to move it from a library configured around collections to a library configured around learning, research and social interaction. I did not spend too long with it, and would not use any of the results. However, certain library tropes remain strong. My requests for social learning spaces with whiteboards didn&apost seem to have much influence. I was amused to see that &aposgroup work&apos has been transformed somewhat in the wall art in the third picture!
Iterating on a prompt to (try to) generate a picture of a library which is progressively more configured around research, learning and social engagement and less around collections
Ongoing adoption and media coverage means that AI usage will increasingly have a shared vocabulary and experience. Familiarity with this will be important in work settings, and will likely be part of the general social background.
In this context, I was reminded of a passage from Steven Johnson’s Everything bad is good for you. He is talking about gaming, but it also seemed relevant to our current moment. I wroteabout this some years ago.
I worry about the experiential gap between people who have immersed themselves in games, and people who have only heard secondhand reports, because the gap makes it difficult to discuss the meaning of games in a coherent way. It reminds me of the way the social critic Jane Jacobs felt about the thriving urban neighborhoods she documented in the sixties: “People who know well such animated city streets will know how it is. People who do not will always have it a little wrong in their heads – like the old prints of rhinoceroses made from travelers’ descriptions of the rhinoceroses.”
As I remarked then, the Jane Jacobs analogy is striking and suggestive. For somebody who has not internalized the experience, but relies on reading or conversation, it is possible that they may have it a ‘little wrong&apos and miss the meaning.
The same is now true of AI. Understanding and participating in the conversation benefits from hands-on experience.
Note: For the moment anyway, Microsoft is making the premium GPT-4 and image generation tool DALL·E 3 available to anyone with a Microsoft account through the Microsoft Copilot. This provides similar functionality to the paid version of ChatGPT.
Acknowledgement: Thanks to Christina Rodriques and Chance Hunt for generously providing helpful comments on a draft.
Methodist missionary E. Stanley Jones was a friend of Mahatma Gandhi, who told him that Christians should “live more like Jesus Christ”, practice their religion “without toning it down”, and “find the good” in non-Christian religions. Inspired by this, Jones organized inter-religious conversations described in his Christ at the Round Table, which becomes public domain in 29 days. The Sat Tal Christian Ashram, which he then founded in a similar spirit, continues today. #PublicDomainDayCountdown
If Hollywood lore is to be believed, the biggest hit of 1928 was written as a joke. Given a last-minute plea for a sentimental song for Al Jolson’s upcoming talkie The Singing Fool, Ray Henderson, Buddy DeSylva, and Lew Brown decided to write the corniest song they could. Jolson took “Sonny Boy” to heart, though, and audiences loved his performance. “Sonny Boy” and The Singing Fool were the top-selling song and film that year. Both join the public domain in 30 days. #PublicDomainDayCountdown
The Nobel Prize for literature often goes to writers near the end of their careers. William Butler Yeats wasn’t done, though, after winning it in 1923. His 1928 collection The Tower includes influential poems like “Sailing to Byzantium” (known for the phrase “no country for old men”), “Leda and the Swan”, and the title poem, named for a home Yeats bought in 1917. The Solitary Walker writes about that tower, and the book, which joins the US public domain in 31 days. #PublicDomainDayCountdown
At the 2023 DLF Forum closing plenary, participants joined us for small group discussions about the four topics registrants indicated were most important to them about attending a conference. We’re excited to offer a similar session virtually to open the door to feedback from folks who may not have attended the Forum in person. Join us in co-creating the blueprint for the future of conferencing in our community. The DLF Forum has always been a place of innovation and collaboration, and together, we can continue to make it even more special. More information and link to register available on DLF’s website.
CLIR and DLF will close on Thursday, December 21 for our winter break and re-open on Thursday, January 4, 2024. We wish you a joyful holiday season and look forward to seeing you in the new year!
This month’s open DLF group meetings:
For the most up-to-date schedule of DLF group meetings and events (plus NDSA meetings, conferences, and more), bookmark the DLF Community Calendar. Can’t find meeting call-in information? Email us at info@diglib.org.
DLF groups are open to ALL, regardless of whether or not you’re affiliated with a DLF member institution. Learn more about our working groups and how to get involved on the DLF website. Interested in starting a new working group or reviving an older one? Need to schedule an upcoming working group call? Check out the DLF Organizer’s Toolkit to learn more about how Team DLF supports our working groups, and send us a message at info@diglib.org to let us know how we can help.
Though her recording career spanned only 10 years, “Empress of the Blues” Bessie Smith had a huge influence on American music. This 2019 NPR interview includes parts of her first record, “Downhearted Blues”, with Maureen Mahon’s explanation of how Smith laid the foundations of rock & roll. (The Rock & Roll Hall of Fame inducted her in 1989.)
Smith’s “Downhearted Blues” was the first of several hits she released in 1923. They join the public domain in 32 days. #PublicDomainDayCountdown
With the 2023 DLF Forum in St. Louis now behind us, we are excited to share some of our plans and ideas for upcoming events. As I’m sure we’ve all experienced, the Covid-19 pandemic has had an immeasurable impact on the landscape of large-scale academic conferences and events. Understandably, expectations about events have changed, including increased emphasis on health and safety, accessibility, affordability, and environmental sustainability.
In response to shifting expectations, DLF is taking a deliberate step forward. In 2024, we will be testing a change in our conference structure. Traditionally, the DLF Forum and affiliated events have been held once a year in-person at a hotel. However, we are now embarking on an experimental journey, introducing a hybrid model that offers an in-person experience in summer and a virtual experience in the fall. Our aim in offering two distinct events in different formats is to provide participants with enhanced flexibility and accessibility, ensuring a more inclusive and dynamic conference experience across the two formats. We are separating the events by season, rather than seeking the simultaneous hybrid model, because it is difficult or impossible to unify two communities of presenters and attendees, causing a jarring split and often insufficient experience for both groups.
We are thrilled to share that CLIR/DLF has partnered with member organization Michigan State University (MSU) Libraries and the College of Arts and Letters (CAL) to host DLF Forum’s in-person summer event, set to take place in July 2024. We are excited about this partnership because of all the innovative work happening at MSU Libraries and CAL in the areas of digital humanities and digital scholarly publishing, among others. Furthermore, we are equally excited to offer a virtual Fall Forum following the summer event.
Why now?
Past agreements with hotels were established years in advance, and our commitment to fulfilling these agreements remained intact when we transitioned to virtual events in 2020 and 2021. With those prior commitments now fulfilled, we are eager to respond to community feedback and reevaluate our conference structure.
Join us on this journey: The launch of the Forum Feedback series
As we embark on this exciting journey to reshape our conference structure, we want to emphasize the importance of the community’s involvement and feedback. Your insights and perspectives are invaluable in guiding us towards a conference experience that truly meets your needs and aspirations. To facilitate open communication and gather valuable insight, we are launching a series called “Forum Feedback” where folks can share thoughts, suggestions, and ideas. Your voice matters, and we need you to help shape the future of our community’s gatherings. Together, we will create a conference that reflects the evolving landscape and embraces the principles of health, safety, accessibility, affordability, and sustainability.
Anything Elon Musk says must be treated skeptically. This is particularly true of anything involving timescales (see Tesla robotaxis). And it is even more true of Musk's plans for visiting and eventually colonizing Mars.
Below the fold in part 1 of this two-part post, I apply some arithmetic just to the logistics of Musk's plans for Mars. Part 2 isn't specific to Musk's plans; I discuss two attempts to list the set of "knowns" about Mars exploration, for which the science is fairly clear but the engineering and the economics don't exist, and the much larger set of "known unknowns", critical aspects requiring robust solutions for which the science, let alone the engineering, doesn't exist:
The plan is to "build 1000+ Starships to transport life to Mars. Basically, (very) modern Noah's Arks," Musk wrote, reiterating a statement he had made during a recent interview with TED curator Chris Anderson. In that interview, he stated that SpaceX would achieve this goal by 2050.
SpaceX and Musk have stated their goal of colonizing Mars to ensure the long-term survival of humanity, with an ambition of sending a thousand Starship spacecraft to Mars during a Mars launch window in a very far future.
The problem with refueling on-orbit is that getting the fuel up for one mission requires a lot of launches. For a manned Moon landing the Government Accountability Office said that SpaceX would "require 16 launches overall". So delivering 100,000 tonnes to Mars would require 16,000 Super Heavy launches costing around $24B and involving 6.4M truck deliveries. One might think that the launches could take the whole of the 780-day interval between Mars launch windows, or a rate of just over 20/day. But because the fuel in the orbital tanks boils off over time, the launches have to happen much faster than that, perhaps around 50/day. in 2022 the Falcon 9 launched 60 times, or 0.16/day. Getting to 50/day requires scaling up over 300 times.
SpaceX's Falcon 9 has an astonishing 99.3% success rate. If the Mars vehicle had the same rate, an extra 113 launches would be needed to cover the failures. Of the 1,000 manned launches, 7 would be failures, carrying 7,000 people.
1000 Starships carrying 1,000,000 people is 1,000 per Starship, which can deliver 100 tons to Mars. That is 220lb/person, so apart from the person and the spacesuit they will need to disembark, they won't have many carry-on bags in the overheads, let alone the air and food needed for the journey. Everything they need to survive on Mars must already have been delivered by earlier missions. Lets guess that each person needs 10 times their weight in life support and other equipment. So the 1M person launch window must be preceded by 10 similar launch windows delivering freight. Now we are talking $264B in launch costs alone, or $264K per person. Even for Elon Musk, over a quarter-trillion dollars is real money. Even that may not be enough. The history of Mars missions shows that Mars landing is a high-risk endeavour. It is very unlikely that all 10,000 freight missions would be successful.
10 launch windows is 7,800 days or more than 21 years. So if Musk wants to land a million humans by 2050 he needs to start launching 50 Starships a day in 2029, a bit more than 5 years from now. Fortunately, he has time to experiment. There are two launch windows before the one when he needs to start in earnest.
If the Starships are to be reused, they have to be re-fueled on Mars using fuel made locally from Martian resources. Each Starship requires 1,200 tons of fuel. Thus unless the Starships are to be expended, during the 2024 and 2026 launch windows Musk needs to deliver a factory to Mars capable of producing 1.2M tons of fuel every 780 days, or nearly 1600 tons/day. Clearly, the factory must weigh several times its daily output. Lets guess it weighs 20 times, or 32,000 tons. So in each of those two launch windows Musk needs to send another 160 Starships to Mars, requiring another 2,560 launches.
But there's another huge problem with Musk's fantasy. The 1,000 Martian emigrants will spend something like 180 days cooped up in each Starship's payload bay, which has a volume of 1,000m3. The average human's volume is around 0.06m3. The cabin volume per passenger of a 1-class 737 is around 0.22m3, so each emigrant will spend 180 days in the equivalent of 4 seats in coach in a 737. I think people paying more than a quarter-million dollars in launch costs alone would be imagining something more like business class! The migrants will end up fighting each other long before they arrive.
And, of course, once the million people land on Mars the story isn't over. They will still be dependent upon supplies from Earth until they can build a completely self-sustaining ecology. They may not need 100,000 tons of supplies every 780 days, but there will still need to be a lot of launches to get fuel into orbit to get a smaller number of Starships with supplies to Mars.
Look, I totally understand that what people like Elon Musk and Jeff Bezos really want is to call up the Magratheans and order one of their custom-made luxury planets lovingly made to their exacting specifications, so they don't have to deal with taxes, government, competitors or people who disagree with them. Let alone having to survive in a 2.5C warmer world racked with war, migration and starvation that is depleting their support staff. It must be really frustrating that niggling little issues like the speed of light mean that the only planet they can afford isn't just a long, slow, expensive commute, but also needs a lot of work to make it a suitable home for a multi-billionaire. That work is the subject of part 2.
All it took for me to get this level of understanding of just the logistics of Musk's fantasy was his own numbers, an Internet connection, a couple of hours, and basic arithmetic. Given Musk's notorious lack of credibility when it comes to schedules, it is disappointing that as far as I can tell no journalist made the effort to inform the public that Musk was BS-ing. Chris Young expressed mild skepticism, "just not very realistic" and "risks putting him in similar territory as he was with Tesla's progress on Level 5 autonomy". But that is a long way from explaining Musk's specific implausibilities.
Global warming and climate change is currently wreaking havoc on the world. As digital preservation professionals, it is our responsibility to mitigate threats that impede our ability to steward digital materials through time. Climate change not only threatens our data through more frequent and more severe weather disasters, but also through reductions in food supply, mass migrations, economic contraction, and political upheaval. In order to start addressing these very real threats, the Climate Watch Working Group has been charged with:
Producing regular annotated bibliographies on recent literature, news, and reports related to climate change and its impact on digital preservation
Creating and adding to an ongoing list of potential risks climate change poses to digital preservation work
Creating and adding to lists of core climate change information resources to get a solid grounding in the issue, help with future projections, and lobby for preservation resources.
The Climate Watch Working Group is the first of at least two NDSA working groups that will be formed to help the profession address how we can adapt our practices and policies to the uncertain future climate change poses. Both groups are expected to work closely together and members who sign up for the Climate Watch Working Group will be welcome to move to the Climate Preparation group when it is established.
The Climate Watch Working Group will meet twice a month with regular assignments between meetings. The expected time commitment is approximately 30 minutes to one hour a week in addition to the bimonthly meeting time.
Please reach out to Sibyl Schaefer (sschaefer(at)ucsd(dot)edu) by Dec. 11, 2023 if you are interested in contributing.
I think you should read the transcript of Barbara Fister's talk, "information literacy, writing instruction, and the problem of stochastic parrots". And then I want to you to come out of hiding.
Buster Keaton stars as a hapless aspiring newsreel maker with eyes for Marceline Day in The Cameraman, his first film for Metro-Goldwyn-Mayer. The National Film Registry made this movie one of its honorees in 2005, calling it “the last of Buster Keaton’s silent comedy classics”.
OCLC brings libraries together. Those of us who work here think about how libraries and the people and services that make up libraries combine into networks and into communities to achieve something that’s greater than a single library.
When networks are activated through communities, we can establish a common understanding of shared challenges. And we can open generous spaces to:
Exchange knowledge, expertise, and resources
Create diverse ecosystems of ideas and relationships
Illuminate new ways of thinking to inform and inspire our work
The Collaboration Continuum. Originally published in Beyond the Silos of the LAMs: Collaboration Among Libraries, Archives and Museums
A theme—what our colleague Titia van der Werf would describe as the “red thread”—that runs through our research is that trust is a necessary ingredient for co-investment, success, and sustainability. Another finding is that the more diverse the network of partners, the richer the potential for true innovation. However, these rich and deep collaborations are rare. They can only be achieved when there is a compelling articulation of the benefit of collaboration, a clear roadmap of what is required, and a definitive casting of roles and responsibilities—all amid a backdrop of competing missions, priorities, pressures, and stakeholder demands.
OCLC was built on the idea of collaboration at scale. For us, collaboration can take many forms—from libraries sharing best practices in the OCLC Community Center to advisory groups that inform our product development roadmaps. The OCLC Research Library Partnership is another way that OCLC supports the needs of diverse institutions. Our transnational partnership brings together a range of library types: academic and university libraries, independent research libraries, national libraries, and specialized libraries such as those connected to museums. Working in this rich space allows us to see common threads of strength and of need. The collective data we have access to through WorldCat enables us to see how collections interact as an ecosystem. Taken together, this gives us a powerful position to envision a future that’s more interconnected, more innovative, and built on trust relationships. It’s a rich, fertile field to grow new ideas and inspire creativity.
An example of this powerful combination of diverse institutions and collections is our recently completed project, Operationalizing the Art Research Collective Collection. Through the trust network of the OCLC RLP and long-term engagement at the annual ARLIS meeting, conversations uncovered needs and opportunities for art research institutions. These include a lack of space for collections, a lack of shared knowledge about collections even at peer institutions, and the challenges faced by art libraries seeking to form mutually beneficial partnerships with other types of institutions on the shared management of print collections. These conversations inspired a research project exploring opportunities for collaboration between art, academic, and independent research libraries.
In this project, community was vital to express needs and possibilities. WorldCat data was just as essential. Because the art research collective collection is both specialized and decentralized, we can’t get a representative view of the art research scholarly record within one local collection. The full scale and scope of the collection is spread out over institutions across the globe. The project used bibliographic and holdings data to describe an art research collective collection in the United States and Canada to illustrate how collection analysis can inform partnership decisions. Resource sharing transactions analysis revealed existing collection sharing partnerships and allowed exploration for other kinds of collaboration.
We found that the art research collective collection is a networked collection, and therefore it’s a collective stewardship responsibility. Innovative, collaborative stewardship models are needed. Three important recommendations include:
Going beyond immediate peer communities for collaboration opportunities
Leveraging complementarities across institutional-based collections
Embracing greater openness to sharing
Operationalizing the Art Research Collective Collection is just one of many projects highlighted in the most recent OCLC Annual Report. In the report you’ll see a throughline of insights into collaboration around collections and stewardship, grounded in the celebration of a diverse ecosystem of global libraries. OCLC stewards this ecosystem through its many engagement communities, like the OCLC RLP, providing a rich knowledge space to create understanding of complex issues as well as a locus for exploring and charting a forward path.
Celebrate with us! Read more about our past year’s achievements and support of our member libraries in the OCLC Annual Report. And explore the Art Research Collective Collection project, including links to its reports, blog posts, presentations, and webinars.
Devon Murphy (they/them) is a metadata and digital collections professional, currently working as Metadata Analyst at the University of Texas at Austin Libraries. Their research areas include information ethics, metadata, Indigenous and non-Indigenous knowledge organization, and linked data. They received dual masters degrees in Art History and Information Science at the University of North Carolina at Chapel Hill (2019), examining information systems in Indigenous-led and non-Indigenous museums. Current research projects include developing metadata best practices for LGBTQ+ materials with the Queer Metadata Collective and creating a shared Spanish subject thesaurus in collaboration with the University of Florida Libraries. Murphy also serves as a member of the Visual Resources Association’s (VRA) Equitable Action Committee.
With ASIS&T 2023 being my first international conference, I had a mild bit of apprehension about the environment of the coming event and its attendees. Although I consider myself both a scholar and a librarian, I was concerned if my presentation would be too practical, or conversely, too outside the conference’s field. Happily, all of my worries were alleviated after the opening keynote, presented by Alison Phipps and Tawona Sitholé. Their choice to utilize a traditional presentation and a poetry performance symbolized to me the varying ways information can be represented and understood, that everything from a list of Library of Congress subject headings to a basket communicates to us, contains metadata for us to interpret and share. This point was further explored by the speakers, who used a calabash (a type of gourd) as both a symbolic and literal site of information. The presenters passed a gourd across the audience, encouraging them to take note of its physical characteristics while explaining that such gourds carry material and cultural knowledge for some African communities. Phipps described that the calabash can be used akin to a knowledge organization system, where varying stories or ideas are related to each other by using the gourd’s structure as a diagram. This theme arose again in a later conference session presented by Chern Li Lew (Victoria University of Wellington), who described the concept of koru (a type of fern in Te Reo Māori) as a model to organize information in line with Māori ways of knowing. In my own work, I focus on ways to integrate different knowledge organization systems in our digital collections, whether through post-custodial means or through use of community-made resources. It was heartening to see such support for these non-Euro-American approaches to information work, as well as evident acceptance of all manner of presenters and their methods.
In the same session as Chern Li Liew, my co-presenter and collaborator Bri Watson (University of British Columbia) and I gave our presentation, “Our Metadata, Our Selves” on the work of the Trans Metadata Collective and its resulting document, the Metadata Best Practices for Trans and Gender Diverse Resources. This document advocates for inserting trans and gender diverse ways of knowing into cultural heritage information systems. For example, we examined how authority record practices can harm trans and gender diverse people by recording inaccurate information or violating privacy. Cataloging choices can have an impact beyond a simple bibliographic record.
I was really excited to share this project with an international audience, providing a great opportunity to see if what we had created was truly useful for others. We received feedback on ways to improve our work and to share it more widely, including considering adding recommendations for Dewey Decimal classification. Fitting with the conference’s theme of “Making a Difference: Putting Policy into Action,” my experience at ASIS&T has inspired me to go further with critical metadata work, both with the Best Practices and within my day-to-day.
Here is a picture of the Statue of Liberty doing a TikTok dance, as painted by van Gogh, as interpreted by ChatGPT. This is very relevant to my point and we’ll come back to it.
One of the best ways to think about large language models is as universal, personal translators. When I gave a talk at a Spanish-language library conference in Argentina recently, it was an excellent chance to test what LLMs currently offer as translators and what they might become. The answer made me optimistic for how LLMs can work as humanistic knowledge tools, in concert with library values.
This is long, so I’ve broken it up into a few sections that might be helpful to different audiences:
LLMs are universal translators. This section explains LLM embedding spaces and argues that many of LLM’s most successful applications are essentially translation tasks. I argue that LLMs are “universal translators,” not in the sense that they are perfect but in the sense that they try to translate between any input and any output.
How I built my own personal translation tools. When I spoke in Argentina, I built my own tools to translate my conference slides to Spanish and to translate other talks to English. This section gets into the weeds of what I did and how I did it. It will be most useful if you are a programmer interested in making more practical use of LLMs, or if you are interested in what might be possible for everyone as LLM tools get easier to use.
What a universal translator means for an innovation lab. The ability to make individual, personalized translation tools changes what all of us should work on next — things that once could have been entire companies are now afternoon projects. This part considers, on the one hand, how my trip made me imagine a bunch of tools I could make and share, and on the other hand whether making and scaling tools still makes sense at all.
The cooperative principle, AI translators, and human connection. This part reflects on my experience of using technical tools to try to connect with people. I find that they highlight the “cooperative principle” — when two people communicate via an accessibility tool, they have to be more attentive, rather than less, to each other’s social signals, making me optimistic that tools can help to bring us together rather than alienate us.
LLMs are universal translators
LLMs are, in a literal sense, universal translators. They take all of their training data and embed it in a single high dimensional space, an embedding space, and then produce outputs by moving around this embedding space.
The goal of an embedding space is that similar concepts end up near each other, and different concepts end up far away. And the goal of a “large” language model is to embed everything — the space is trained using trillions of tokens representing all of the world’s digital knowledge.
A classic example to understand embedding spaces is this: we take a bunch of data and train an encoder so that if we put in similar words, they encode to a similar location in space. Words like “king” and “queen” each end up encoded as locations somewhere in the embedding space. And then, miraculously, it turns out we can do math on those locations and it makes sense. If you encode “king” into a location, and then subtract the location of “man” and add the location of “woman”, you arrive at the location of “queen.”
This is already a kind of “translation” — we’re literally moving, or translating, from the location of “king” to the location of “queen.” But we can do other kinds of translation with this same technique. We can subtract English and add Spanish, and move from “king” to “rey.” Or we can build encoders that embed pictures and sound as well as text, and encode a picture of King Arthur and come out with the word “king,” or encode the word “king” and come out with an audio file of someone saying “king.”
Embedding spaces translate from everything to everything.
Not surprisingly, a lot of the most promising applications of LLMs can be thought of as translation problems:
A programmer inputs a comment describing what a function should do in English, and it is translated to an implementation of the function in Python.
A doctor inputs an image of an x-ray, and it is translated to an English-language diagnosis.
A user inputs a text description of an image, and it is translated to an image matching the description.
A lawyer inputs a list of summaries of case holdings and facts provided by a client, and it is translated to a legal brief.
A social network inputs images uploaded by users, and they are translated to text descriptions for screenreader users.
This brings us back to the image of the Statue of Liberty doing a TikTok dance, as painted by van Gogh, that opened the article. How did the program “know” what the Statue of Liberty looks like, what dancing looks like, how van Gogh paints, or how those would all go together? It started at a random point in a high-dimensional embedding space, and then translated toward the spot that had the highest overlap of Statue-of-Liberty-ness, dance-ness, and van Gogh-ness, which it could do because it was able to encode and decode both text and images in and out of that space. It could just as easily have navigated to nearby spaces — from Statue of Liberty to Napoleon, or from van Gogh to Monet:
All of the concepts of the world are embedded in the same space and available for translation.
The idea of large language models is that we want the same model to do all of these tasks, because with human problems there’s no way of predicting what’s relevant to what. The lawyer’s brief or the programmer’s code or the Firefox translation could all require a concept map that includes Napoleon or TikTok trends for an accurate translation; large language models are willing to absorb it all and remix in any form.
That’s what I mean by “universal” translator — we don’t have to decide, up front, which facts are necessary for a successful translation, what inputs and outputs to use, because every available idea can be translated in and out of the same embedding space.
Being a universal translator doesn’t make something an accurate translator, or a social benefit. I’m not using “universal” as a superlative or saying it can do any particular translation task well. But a universal translator is a very different tool from a special-purpose translator, and it’s worth experimenting to see what it means to have one.
How I built my own personal translation tools
So, I believe that LLMs are universal translators. And I also believe, as the head of an innovation lab, that getting our hands messy is the best way to improve our intuitions about what’s coming next. So when I was invited to give a talk on disruptive innovation in libraries (adapted transcript) at the Universidad Católica de Argentina for a Spanish audience — a language I don’t speak — it was the perfect chance to experiment with what it means to have a universal translator.
To be clear, I was able to attend this Spanish-language conference not because of the tools described below, but because of the resourcefulness, patience, and enthusiasm of UCA library director Maria Soledad Lago, language professor Mercedes Rego Perlas, and the other speakers and attendees who welcomed me. Many thanks for all of their support, including with these experiments!
The scenario I decided to test was: I’m attending a conference in a foreign language, and I’m going to use low-level APIs to see if it’s possible to build my own tools to solve problems while I’m there.
My first goal was to see if it was possible to translate my slides. I knew my talk would be offered with simultaneous translation, but I wanted it to be easier to follow the text on the slides as well. That is, I wanted to show each block of text in the slides in both English and Spanish, like this:
PowerPoint already has a translator built in — you can click a text box and get a translation, like this:
I wanted to see if I could save time by automatically inserting translations for all the text boxes. I also thought I could improve on the PowerPoint feature in a couple of ways:
I could include round-trip translations in each box, English -> Spanish -> English, which would give me a way to check the translation accuracy without speaking Spanish.
I could translate entire slides at once, instead of just one text box, which would give the translation program more context to work with.
I could keep the internal formatting of the text boxes, so the same word would end up highlighted in both versions of the text.
And because the goal was to test whether universal translation can make translation tools more personal and customizable, I wanted to try to do all this in a few hours.
I started by asking ChatGPT to write a program to edit a PowerPoint deck for me:
With a little back and forth, I had a starting point — a simple program that capitalizes each word in a PowerPoint. I then started copying and pasting in code to call the OpenAI API. All I’d have to do is take the text blocks for each page, ask GPT4 to translate them to Argentine Spanish, and put the results back in. This gave me a chance to try out OpenAI’s function calling API for structured output, which I had a hunch would help with translation.
I had the fun experience at this point of having Copilot, a GPT-powered coding tool, start to recommend instructions to supply to its sibling in the translation prompt:
Here you can see that I’ve written some code myself to make a “translate” function that takes a string in English and returns Spanish, and I’m writing the instructions that will be sent off to the model. Copilot sees what I’m doing, and suggests the completion of the instruction in gray italic text — including, itself, translating English to Spanish.
The upshot was a script that edited slides to look like this:
This looks like a mess, but it’s just what I wanted! For example, here’s the text of the first block:
“The Library is to us what a laboratory is to the chemist or the physicist, and what the museum is to the naturalist.” -> “La biblioteca es para nosotros lo que el laboratorio es para el químico o el físico, y lo que el museo es para el naturalista.” -> “The library is for us what the laboratory is for the chemist or the physicist, and what the museum is for the naturalist.”
Since the round trip language looks good, I can guess that the Spanish is at least intelligible, and delete the round trip translation and move on.
Checking the round trip translations was a fascinating game, and changed how I think about machine translation. One slide I was suspicious about, for example, translated the English “patron” as “mecenas”:
I wondered if “patrons” came through correctly, or was confusing, so checked what ChatGPT thought, without tipping my hand about the word “mecenas”:
Me: what word is most common for library users in spanish? is there a word like “patrons” that denotes something distinct from commercial customers?
ChatGPT: In Spanish, the term “usuarios” is commonly used to refer to library users. “Usuarios” simply means “users.” When specifically referring to library patrons in a context where there’s a need to distinguish them from commercial customers or other types of users, the term “socios” (members) or “afiliados” (affiliates) can be used. However, the context is essential, as “socios” can also mean “partners” in a business sense, and “afiliados” can mean “affiliates” in other contexts.
But in general, “usuarios de la biblioteca” (library users) is a standard and clear way to refer to library patrons in Spanish.
Me: how would “Los usuarios (socios?) no nos deben su patrocinio.” come across if translated to english?
ChatGPT: The sentence “Los usuarios (socios?) no nos deben su patrocinio.” would translate to English as: “The users (members?) do not owe us their patronage.” Here, “usuarios” means “users,” and “socios” can mean “members” or “partners.” The term “patrocinio” typically means “sponsorship,” but in this context, it seems to imply “support” or “patronage.”
I thought it was fun that English-language libraries have this ongoing debate about “patron” as a term, but Spanish libraries don’t seem to have adopted that usage, so I decided to highlight the translation challenge in the slide:
All in all, in the space of about four hours, I made a novel tool to translate slides and used it to translate and check the slides for a half hour talk. Throughout, I overtly put a lot of trust in ChatGPT’s language advice, which I knew could be completely inaccurate — an intentional decision to trust the audience of humans to meet me halfway in deciphering any errors ChatGPT might introduce.
Audience feedback was good — influenced, I think, by the fact that I presented it as an experiment and checked in on the translation quality as I presented the trickier slides. Audience members commented that the translated slides were helpful for following a talk in simultaneous translation, and the key points were not lost.
At the same time, it was clear that the translations remained choppy and required readers to work to interpret what I meant. Mercedes Rego Perlas, a linguistics professor at the Universidad de Buenos Aires who worked with me to translate a later version of the talk, commented that the AI was bad at knowing what it didn’t know: if I used untranslatable terms like “loss leader” or “cost center,” the program gamely emitted nonsense, where a human translator would know to ask for clarification and negotiate a compromise, as Mercedes herself did at several points. As always with LLMs, it would take more experimentation to see if a better prompt or control loop could fix that problem — Mercedes was less optimistic than I was.
Building my own tools, part 2: real time translation
After my own talk, I tested out the “universal translator” in other ways. For example, I tested GPT4’s new vision capabilities by asking it to interpret photos in conversations like this one, from a talk by Andrés Felipe Echavarría, Director de Bibliotecas, Pontificia Universidad Javeriana, Colombia:
This was a chance to explore how translation works as a matter of culture as well as language — note how the model was able to ask questions and get more context that would let it use outside knowledge to complete the translation.
I also attended an Argentinian digital library conference that didn’t offer simultaneous translation — the 21st Jornada sobre la Biblioteca Digital Universitaria at the Universidad de Buenos Aires. For this conference I decided to test whether it was possible to use low level APIs to build my own simultaneous translator.
I started with some sample code to record and transcribe audio, and adapted it to write audio files and transcriptions to a folder every 10 seconds. I then ran a second program (copying and pasting from the slide translation program) that would translate each 10 second block. And, when those short translations proved choppy, I made a third program that would roll up 100-second blocks of audio to re-transcribe and translate more coherently.
The result looked like this — three separate windows running on my computer that would let me follow what was going on in each talk:
Screenshots of realtime translation of Nicolas Petrosini, Universidad de Palermo’s, talk, Integrando tecnología y aprendizaje en la biblioteca universitaria: ChatGPT, TikTok y la alfabetización en inteligencia artificial.
After a few hours I had a prototype that exactly served my needs and allowed me to follow the details of all of the talks I saw.
One of the fun parts of building my own prototype translator was encountering edge cases and mistakes. For example, I was using a speech-to-text model called Whisper that will do its best to transcribe even very quiet staticy noises into text. Users are supposed to filter out silences for themselves, but I chose not to, so during breaks Whisper would translate background noise into hallucinated text — and then, because it uses the previous transcript to predict the next transcript, it would repeat itself in a game of telephone:
You can see how, right at the end, this fades seamlessly into something that would actually be said at a library conference, as it starts transcribing speech and not static and noise becomes signal. Most people would probably not want this in their translation stream, but because I was building my own tools, I could choose to tweak them in this direction.
What a universal translator means for an innovation lab
So, this is amazing! I went to an international conference and tested out a universal translation API that, with the help of my very supportive hosts and human translators, and just a few hours of tool building, changed my experience of the conference. What does that mean for our Library Innovation Lab, which builds open tools to help people collect and preserve and access knowledge?
The tools I built would have each required entire technically sophisticated businesses to invent and maintain a few years ago — and I built them as just a small part of preparing for a single conference. What does that mean?
I’m not the only one asking that question. After OpenAI’s recent DevDay, a number of startups building on OpenAI’s APIs objected that OpenAI’s new tools, like custom agents called “GPTs” or the ability to search and retrieve data from documents, had destroyed their business models. But that wasn’t because OpenAI had stolen anything valuable or done anything very complicated — it was just that, once a universal translator existed, there wasn’t much left to those companies. The things they were doing were easy for anyone to do.
The same thing is happening to us at the Library Innovation Lab. When I got back home, I sketched an idea of what it would look like for Harvard to make an arbitrary x-to-y translation program available to attendees of the many in-person events that take place here every day:
The idea of this sketch is that translation can be from anything to anything: if you’d like to attend a talk, but you need it to be in text instead of visual, and English instead of French, and high school math instead of postgraduate math, you can just describe what you want and the magic of LLM embedding spaces can give you far more access than you had before.
I love this idea, but we didn’t start working on it at the Library Innovation Lab — not because it is too difficult, or unhelpful, but because it is too obvious: soon an app with this shape will exist in multiple versions on every phone, and these features will be built into every existing software product (just as there are already dozens of Zoom apps offering some variation of AI features like this). As an innovation lab, there isn’t anything for us to do … or is there?
Where I think we’ll have a lot to do, as a small team interested in empowering people with knowledge, is to help people navigate the shift from large, standardized tools to small and personal ones. The Silicon Valley software business model has been to make large, standardized platforms, monopolize them and extract value, and as a public interest software lab it’s tempting to follow in the same path and look for interventions that scale — “we want to invent the next Creative Commons!” But the universal translator is so generically useful that our individual relationship to knowledge can change — we can look for interventions that scale in the beautiful way that public libraries scale, where lots of little institutions help every patron solve their own problems. To do that we’ll have to do a lot of work as a lab and community in making sense of what these tools are and how to safely use them.
OpenAI itself, of course, is a classic centralized service with a great deal of power, which makes questions about what happens to it next, what competitors emerge, how they are regulated, and what open source tools are allowed to exist, all very important.
But at the same time, OpenAI is a thinner and weaker control point than the platforms that came before it. Traditionally a service to translate talks has been very different from a service to annotate images or write legal briefs, so each of those services could build deep “moats” around their businesses. By comparison, the scripts to adapt OpenAI’s APIs to each of those tasks are not very long, and the APIs themselves are relatively easily replicated. In many ways OpenAI is important right now not because it has a monopoly, but because it is paying to be first to discover things that then become common knowledge. Our relationship to software platforms has changed.
I see a few ways for libraries to get involved in this shift, and I’m interested in your thoughts on others:
First, we can help our patrons understand the shift and engage with it. A universal translator offers access to timely knowledge that can unlock profound benefits for our patrons. But it’s an access that is still opaque and confusing, in part because it’s more like access to a simulation than like access to a human expert or a database — more like learning to use a weather report or GPS navigation than a book. We can help teach the knowledge literacy skills that make these tools work for people instead of against them, and we can demystify their operation and cut through ways that commercial players try to make things deliberately opaque. Interface experiments like my PowerPoint translation are ventures in making a technology shaped more like its user, and understanding how it can serve human interaction.
Second, we can apply collection development and access skills to the content of the universal translator. LLMs are deeply curated, in hard to see ways: their answers depend on curation of their training data sets, and their extensive manual finetuning workforces, and their hidden system prompts and control loops. They embed — but hide — a great deal of subjective knowledge about the world, and their embedding spaces have strange strengths and weaknesses. We can help to explore those embedding spaces, to signpost them, to fill them out and file off rough edges, just as we do with other knowledge collections. The Library Innovation Lab’s various case studies and projects like COLD Cases, Poems and Secrets, AI Book Bans, and Provenance in the age of Generative AI are experiments in this direction.
The cooperative principle, AI translators, and human connection
But before we buy too far into this view of LLMs as knowledge tools our patrons need access to — is universal translation valuable at all, or just a bad substitute that risks putting people out of work and alienating us from each other? I want to argue that it can be deeply valuable, strengthening the ongoing value and involvement of human beings and human translators.
The cooperative principle observes that there is always translation effort in any conversation, even between two people who use the same language. If I choose to use a complicated phrase like “libraries are turning into cost centers instead of loss leaders” in a presentation — well, first of all, I probably should delete that phrase from the talk, because it’s confusing. But if I keep it in, I know I’ll need to highlight those words, and define what I mean by them, and unpack the connection I’m drawing for my audience, and then make eye contact and check if I need to speed up or slow down. I’ll do work, and my audience will do work, to bridge the gap in meaning. Keeping those terms in the talk will be worth it if the work of translation leads to better understanding.
If we add in automated translation tools to a conversation, how does it change the experience for people doing this work to understand and be understood? I missed a lot on my trip by not speaking Spanish — what did I lose by translating via machine, instead of through a human translator, and instead of through learning and speaking Spanish myself?
Douglas Hofstadter has staked out one end of this argument in the ominously titled Atlantic article Learn a Foreign Language Before It’s Too Late, where he argues that “AI translators may seem wondrous but they also erode a major part of what it is to be human”:
Today’s AI technology allows people of different cultures to communicate instantly and effortlessly with one another. Wow! Isn’t that a centuries-long dream come true, weaving the world ever more tightly together? Isn’t it a wonderful miracle? Isn’t the soon-to-arrive world where everyone can effortlessly speak every language just glorious?
Some readers will certainly say “yes,” but I would say “no.” In fact, I see this looming scenario as a great tragedy. I see it as the beginning of the end of the age-old tradition of learning foreign languages …
The question comes down to why we humans use language at all. Isn’t the purpose of language just the communication of facts? If so, then why not simply go for maximizing the number of facts transferred per second? Well, to me, this sounds like a shockingly utilitarian and pragmatic description of what I view as a perpetually astonishing and quasi-magical phenomenon that lies at the very core of conscious life. …
As my friend David Moser put it, what may soon go down the drain forever, thanks to these new AI technologies, is the precious gift that one can gain only by immersing oneself deeply in another culture and thereby acquiring an entirely new set of ways of looking at the world. It’s a gift that can’t help but turn any human being into a far richer and broader one.
After presenting, watching presentations, and making friends in a language I don’t speak, I am inclined to stake out the opposite end: I think AI translation can accentuate rather than undermine human connection and the subtlety of human language.
When you add in a machine translator, the cooperative work doesn’t vanish, but becomes even more important. Now there are three of you in the room: there’s the large language model, gamely taking inputs like “loss leader” and finding a spot for them in a universal embedding space to try to translate into new outputs, and there’s the humans speaking and listening, gamely looking for familiar facial expressions and words and gestures and clues to meaning, to try to figure out what’s been lost in translation. The two humans have to trust each other and be cooperative partners, because neither of them can follow the process all the way along; they have to be just as attuned and sensitive to nuance as always.
Using machine translation doesn’t feel “effortless,” as Hofstadter suggests; it feels as tricky as any sincere effort at communication. But it also feels like having important new tools to help with that connection.
I don’t think this work that will vanish as LLMs become better translators — it’s work that we are always doing, even when speaking in the same language to someone we know well. And I don’t think it will replace human translators either — there’s a reason married couples might pay a third party human, a marriage counselor, to help translate between them in their own language, and a reason that it often has to be just the right marriage counselor to succeed. But a universal, technical translator will change what we expect from human translators. When we add in a third human as translator, we aren’t looking for them just to play a mechanistic role — we’re involving a third human in relationship with us, who brings their own nuances of meaning to the conversation, and engages in the shared cooperative project of trying to all understand each other.
Not techno optimism, but human optimism
This piece has been somewhat rose-tinted — I had a positive experience with LLMs as translators, and wanted to make a case for why that matters. It matters because knowledge tools always have the power to connect us and make us more human, and we should notice when there are new ways to do that.
I’m telling this rose-tinted story in full awareness of a number of issues that are important and challenging to address — issues with LLM accuracy; the opacity and subjectivity of LLM knowledge curation; the alienation that can come from interjecting technology into social interactions; the economic impacts of automation, of outsourcing, and of data use; the privacy and centralization risks of hosted models and the anti-regulatory risks of open source models. We’ll keep working on those, and using library principles to do it. But I believe, from this experience, that there is something winnable and worth winning at the end of it.
Last Wednesday, 22 November, Open Knowledge Foundation and AfroLeadership organised a round table on Digital Public Infrastructure (DPI) for Electoral Processes, focusing on initiatives developed in Francophone Africa.
This was the fourth round table in the framework of this initiative, with which we are trying to map the initiatives and projects already active in the field, to connect with experts to understand together what the challenges and opportunities, and to build together a solid public digital infrastructure for electoral processes that can help make our democracies more participatory and therefore less vulnerable.
We would like to thank Charlie Martial Ngounou of AfroLeadership for his invaluable help in selecting the speakers.
Round Table
Cyrille Bechon, Executive Director of the NGO Nouveau Droit de l’Homme in Cameroon, spoke to us a great deal about trust, which is essential for guaranteeing participation in the electoral process. Her NGO is working hard to advocate reform of the electoral system in Cameroon, but also to reform the rules for protecting elections, particularly with regard to independent candidates and the failure to take account of young people (in Cameroon today, you can’t vote if you’re over 20). “We need tools that will enable us to observe the entire electoral cycle (during, before, and after)”.
Philippe Nanga, coordinator of the NGO Un Monde Avenir in Cameroon, is also working on a consensual and participatory revision of the electoral code. He is doing this in particular through training and deployment of local players and facilitators, who reach out to the general public to explain the electoral issues and the importance of taking part in voting. Philippe also believes that in order to achieve a transparent and secure democratic process, electoral reform is needed, along with independent observation of the electoral cycle by civil society. “That’s what we did during the last elections. We deployed 1,350 observers in the 10 regions of Cameroon, which enabled the results from the 6,000 polling stations to be published on the evening of the close of the elections”. The speed with which the results are published reduces the fear of fraud and increases voter confidence, according to Philippe.
Abdulayé Diallo, who is responsible for electoral issues and digital rights at the Rencontre Africaine des Droits de l’Homme (RADHO), fully agrees with the other two speakers: observation of the entire electoral cycle, and the participation of civil society, are essential. With a view to the elections in Senegal in 2024, he is working on the development of a solid digital public infrastructure. Together with RADHO, they have published an open database containing all the election results from 1998 to date. “Digital tools allow massive participation in democracy and a certain transparency against corruption, we must seize them.”
Pius Kossi Kougblenou from the NGO Acomb in Togo and a member of the Open Knowledge Network, presented us with the Bridge (Building Resources in Democracy, Governance, and Elections) election administration methodology as a good example. Elections in Togo have historically been marked by protests, street demonstrations, violence, injuries, deaths, exile, and a worsening of the socio-political crisis. “To counter this, electoral methodologies such as Bridge are necessary”, according to Kossi, although there are still challenges to be faced, particularly in relation to corruption.
Didier Amani, President of Tournons la Page, spoke to us about the use of ICTs to make the electoral process more democratic and citizen-friendly. During the last local elections in Ivory Coast, Tournons la Page monitored the institutional communication surrounding the elections in order to measure the impact and commitment of citizens. The findings? Official communications are highly ineffective: they fail to address the fundamental issues and leave room for hate speech and disinformation campaigns that discourage voters. “We need to set up a citizens’ election monitoring system”. Like Philippe, Didier also thinks that the results need to be shared quickly. That’s how we can start to counter the narrative of fraud.
After the round table discussion, we gave the floor to the audience, to hear their challenges, questions and opinions.
Yussuf Ndiaye, Vice-Chairman of the Comité Miroir du Sénégal on good governance, stressed that for there to be general acceptance of the consensus on the electoral process, we need to have confidence in the players. According to him, there needs to be good monitoring and resource people to supervise both before and after the event. “This is the only way to avoid conflict”.
Responding to Yussuf, Abdulayé Diallo reminded us that in Africa all political crises are electoral in nature. Inclusion and participation are necessary if we are to have a true symmetry of information. To achieve this, it is essential to have open and accessible databases.
Cyrille Bechon agrees with Yussuf: the question of consensus depends on the good faith of the players. Once we have this consensus, we need to put in place clear rules and mechanisms to ensure that the consensus is respected and that it is not circumvented. According to Cyrille, even more than consensus, we need additional commitment measures. Philippe Nanga comes back to this: consensus is the key to preventing conflict, but it needs to be formalised in law and given concrete form in institutions. That’s the way to win the trust of the public and ensure that they want to get involved and participate.
We all agree: there is work to be done with education to restore confidence in the institutions in place.
Another major concern relates to infrastructure, and in particular the poor quality of the internet in African countries and the frequent internet shutdowns during election periods.
About the Project
The Open Knowledge Foundation wants to create and enable an international alliance to advocate, design and implement building blocks for a Digital Public Infrastructure for Electoral Processes. The goal of the alliance is to create open-by-design technology that can be reused to make democratic processes more trustworthy, resilient, and transparent.
It is not about voting systems. It’s about how open source technology can support all of the stages of the electoral process. From managing the database of candidates and polling stations to the publications and archiving of results.
Democracy needs to be more participatory and only openness can create the foundations for processes where people can be integrated.
The first step in this initiative is to understand what is already available in the field of open elections. We are carrying out a collaborative mapping of local and global projects to gather critical mass and identify gaps, elements that can be reused and the most urgent needs.
Do you know of existing projects or professionals contributing to a digital public infrastructure for elections? Add them now to our Project Repository or Global Directory under the Open Elections category.
Join the Coalition
You can express your interest in being part of the coalition working on this project. Fill out the form below and stay tuned for our team to get in touch with more information about the next steps.
Margaret Mead spent several months in Samoa researching her book Coming of Age in Samoa, a groundbreaking bestseller joining the public domain in 34 days.
After Mead died, her reports of the sex lives of Samoan adolescents were disputed by Derek Freeman, as well as by some Samoans. Samoan cultural norms had shifted notably by that time, though. Mainland American cultural norms have also shifted since 1928, as can be seen with this book and other works featured in our #PublicDomainDayCountdown.
A major theme of this blog since 2014's Economies of Scale in Peer-to-Peer Networks has been that decentralized systems aren't, because economic forces overwhelm the technologies of decentralization. Last year I noted that this rule applied to Decentralized Finance (DeFi) in Shadow Banking 2.0 based on Prof. Hilary Allen's DeFi: Shadow Banking 2.0? which she summarizes thus:
TL;DR: DeFi is neither decentralized, nor very good finance, so regulators should have no qualms about clamping down on it to protect the stability of our financial system and broader economy.
While the main vision of DeFi’s proponents is intermediation without centralised entities, we argue that some form of centralisation is inevitable. As such, there is a “decentralisation illusion”. First and foremost, centralised governance is needed to take strategic and operational decisions. In addition, some features in DeFi, notably the consensus mechanism, favour a concentration of power.
A small number of participants are dominating the world of decentralized finance as the crypto sector, which seeks to replicate financial markets without middlemen, still hasn’t recovered from FTX’s collapse a year ago.
Most categories in DeFi — from peer-to-peer lending to decentralized exchanges — are seeing capital largely held in a few major projects, according to data compiled by crypto-risk modeling company Gauntlet. The firm used a popular measure of market concentration and competition called the Herfindahl-Hirschman Index.
HHI is calculated by squaring the market share of each competing firm in the industry—expressed as either fractions, decimals, or whole numbers—and then summing the resulting numbers ... The result is proportional to the average market share, weighted by market share. As such, it can range from 0 to 1.0, moving from a huge number of very small firms to a single monopolistic producer.
In Shen's graph above the HHI is expressed in "points" from 0 to 10,000. Shen comments:
Based on the metric, the most competition exists between decentralized finance exchanges, with the top four venues holding about 54% of total market share. Other categories including decentralized derivatives exchanges, DeFi lenders, and liquid staking, are much less competitive. For example, the top four liquid staking projects hold about 90% of total market share in that category, according to Gauntlet.
Protocol
Revenue
Market
$M
Share %
Lido
304
55.2
Uniswap V3
55
10.0
Maker DAO
48
8.7
AAVE V3
24
4.4
Top 4
78.2
Venus
18
3.3
GMX
14
2.5
Rari Fuse
14
2.5
Rocket Pool
14
2.5
Pancake Swap AMM V3
13
2.4
Compound V2
13
2.4
Morpho Aave V2
10
1.8
Goldfinch
9
1.6
Aura Finance
8
1.5
Yearn Finance
7
1.3
Stargate
5
0.9
Total
551
Shen provides a breakdown of the last 180 days revenue of DeFi projects, which I reformatted into this table. It shows that the top project, Lido, has 55% of the revenue, the top two have 2/3, and the top four projects have 78%. This is clearly a highly concentrated market, typical of cryptocurrency markets in general.
Why does the centralization of Defi matter? First, for all the bad things concentration causes in general markets — see for example Matt Stoller's Big. But more importantly, because the technologies of decentralization impose massive costs over and above those of equivalent centralized systems. The incentive to pay these additional costs is to reap the profits centralized systems sacrifice to regulation. If you are paying the costs but not evading regulation, what is the point? I discussed this in Economic Incentives.
If despite claims of "decentralization" regulators can shut down the few big players in a market, the decentralized systems will be paying the massive extra costs but not reaping the unregulated profits. Of course, there is a Whac-A-Mole aspect; kill a big player and one or more smaller players will get bigger enough to be worth taking out. But it won't take many of these cycles for the market to get the message.
This piece is adapted from a keynote talk I gave at Innovación y Experiencia del Usuario at Universidad Católica de Argentina on November 1, 2023.
I was asked to give a talk on the subject of “disruptive innovation in libraries,” which isn’t necessarily the phrase I would choose to describe our work, but I enjoyed using that lens to explore the changes all libraries are going through.
If you want to skip around, Part 1 explores the disruptive changes libraries are experiencing with the arrival of the internet over the last forty years; Part 2 proposes a new mission for libraries in reweaving cultural memory for the internet age; and Part 3 outlines what I’ve learned so far about leading “disruptive innovation” within large, established institutions.
When I think about disruptive innovation in libraries I think about two stories.
One is the story of Christopher Langdell, who reinvented the library where I work when he became dean in 1870.
Langdell changed everything over the course of a few years: different budgets, different physical architecture, different staff, different patrons, different rules. And he did all of that by announcing a different mission for the library. He announced: “The Library is to us what a laboratory is to the chemist or the physicist, and what the museum is to the naturalist,” meaning that the purpose of having a law library is to have the specimens that make it possible to learn and practice the law. He then made all of his choices by asking what would make sure that Harvard Law School had the world’s best laboratory for conducting law — for example, by having one copy of everything, and enough copies of the popular things that everyone could get their hands on one.
His changes were deeply disruptive: he described them as changes of “so radical a character that they have produced a very complete revolution in the Library in almost every particular.” And he acknowledged in his annual report that they caused “more or less temporary inconvenience and embarrassment,” which I think is annual report language for something that caused a great deal of chaos and disruption.
But the disruptive changes worked, because they made the library essential to the law school: he wrote that “without the library, the School would lose its most important characteristics, and indeed its identity.” This was true — the law library became a primary reason for people to go to Harvard and for Harvard to be a premier law school.
For those of us who came afterward, therefore, much of our job was to make sure that Langdell’s mission at the library continued to be carried out; we had to make sure that the people who came after us did about the same, or a bit better, than the people who came before us.
This is the distinction between “disruptive innovation” and “sustaining innovation” — sustaining innovation improves your existing services (and everyone tends to like it), while disruptive innovation adopts new services backed by a new mission (and it is risky, and in some cases simply a bad idea).
Langdell’s story illustrates one side of disruptive innovation: when you choose a new mission to better serve your values.
Wikipedia
The second story is the transition from paper encyclopedias to Wikipedia, which I’m using as a shorthand for the many changes that libraries have gone through with the arrival of the internet.
Before the internet, encyclopedias were essential, and so they were one reason libraries were essential: if you wanted to know a fact, you had to look it up, and if you didn’t have an encyclopedia at home, you had to get yourself to a library. Wikipedia changed that: you no longer had to go to a library to look up a fact.
Libraries are still valuable after Wikipedia — for evidence see the Wikipedia page that begins “Academic Research Libraries and Wikipedia are natural allies. Really.” We can help you understand what you’re seeing on the internet, check whether it is reliable, and find resources to expand your knowledge. If you care about the answer you should check with us. But we are no longer essential.
And because we’re libraries, we don’t even get to be mad about that! As long as you can solve your knowledge problems better than before, we are thrilled.
This is the other kind of disruptive innovation: the innovation that happens to you from outside, when something about the world changes so that pursuing your mission no longer best serves your values.
There are lots of variations of this story, like the arrival of digital journals, open journals, and preprint servers in academic libraries. And there are lots of other stories to tell about Wikipedia — the reasons knowledge experts had to be justifiably skeptical of it as a resource, the miracle that it worked as well as it did, the role libraries played in making it possible, etc.
But for purposes of this talk, “Wikipedia” is shorthand for something we need to get in our bones:
Patrons are finding knowledge in all kinds of new ways that better solve their problems.
Those new ways might seem strange or even broken to us, but we don’t get to tell people that they are solving their problems wrong.
New ways to solve problems can make us fundamentally less valuable. Patrons would suffer less if libraries vanished tomorrow, because Wikipedia exists.
This is not the last change; new ways to solve problems are emerging faster, not slower. (See: AI.)
The trap: libraries are less indispensable than they have ever been
So here’s the thing we’re grappling with in library work: many forms of library service are no longer essential. We can no longer be satisfied by making sure that the next generation does a bit better than the last generation.
Every library has graphs shaped something like this, which shows a sharp change in visits to US public libraries around 2009:
WordsRated: Visits to US public libraries per year (billions)
And we also have graphs like this, from the same article, which shows the sharp decline fully offset by an increase in digital borrowing:
WordsRated: Physical and digital collection use at US public libraries (billions)
The point is not to decide which of these graphs is right — the point is that the demand for our services is changing in a different way than it did before. We’re moving from a world like this, where our metrics are stable and controlled mostly by external factors like how many college students there are:
To a world like this, where our metrics have sharp bends in them and some go up while others go down, because of sudden shifts in what our patrons need:
We don’t know what the shape will be or where the sudden bends will lead — we just know that they’ll happen, much faster than before, so we need to learn to deal with sharp changes in the graph. And the lesson of Wikipedia is that we don’t get to complain about that: patrons do not owe us their patronage.
If patrons go off to solve their essential problems some other way, we don’t get to tell them not to. We never have. We either take the sharp turn with them, and become essential in the new places they live, or we stop mattering.
This isn’t news! Libraries have been working on this question for decades. Nicholas Hune-Brown recently wrote beautifully about the ways public libraries are learning to be “the last truly public space” and the history behind that struggle.
And it’s not specific to libraries. To take a nearby example, book publishers are stuck in a similar trap, where their profit margins are collapsing at exactly the time when they most need extra funds to find new ways of serving their mission.
But I think that trap is clearer and easier to see when it’s measured by a publisher’s balance sheet. What keeps me up at night is that libraries — especially university libraries — will be too slow to respond to changing patron needs, becoming less and less essential from the perspective of university administration, without seeing the trap clearly enough or facing up to what it means to be essential, and that we’ll shrink down to nothing.
What does “essential” mean here, in the sense Langdell made the Harvard Law School Library essential? It means something like, will giving the library less money result in lower quality admissions, lower quality faculty recruits, or less successful graduates? The way we shrink down to nothing is straightforward: on the one hand, we shift from “loss leader” to “cost center,” shifting from something that is essential to the school to bring students in the door, to something that deans push to spend less on each year. Cathy Eisenhower wrote about the changing pressure for university libraries to turn a profit, for example, in Inside Higher Ed back in 2010.
And on the other hand, we shift from “curator” to “contract negotiator” — we no longer use librarians’ distinct professional skills, ethics, and competence to choose what to acquire, and thus define the substantive fields we work in, but instead subscribe to a much smaller list of databases curated by commercial vendors with very different goals and values. The things that are essential to us — things like building collections for the long term, and not just until the publisher changes the subscription terms — are no longer in our power to control.
Escaping the trap: adopting a new mission
So we need a mission that makes us essential — just like Langdell announced the mission of being the “laboratory for the law” in 1870, or public libraries have worked to adopt a new mission as the “last truly public space.” What is the mission for university libraries?
Your answer will be better than mine, but my pitch today is that our essential mission is to be the home for cultural memory.
Five billion people have connected to the internet in the last 30 years, generating millions of petabytes of data per year.
But librarians know that data doesn’t make a library. Writing data to disk doesn’t mean collecting or curating knowledge; storing data doesn’t mean preserving knowledge; accessing data doesn’t mean access to knowledge.
Doing those things well — collecting, preserving, and accessing knowledge — gives us cultural memory. It gives us the ability to remember, plan, and pursue shared goals.
It’s easy to feel the opposite of that today — that connecting five billion of us with instant communicators, and generating zettabytes of data a year, has created the inability, at a large social scale, to remember truthfully what has happened, make coherent plans, or solve problems that require us to coordinate. The internet when it isn’t working feels like cultural dementia.
(I’m not saying, for purposes of this talk, whether our “cultural dementia” is better or worse than it was before the internet — the truth has always been hard to discern, and social coordination problems have always been hard to solve. But it certainly is a palpable problem today.)
Libraries are extraordinarily good at helping with this — they’re one of the few technologies where, the more of them you have in your society, the stronger, the more robust, the more flexible, the more resilient you get.
So when the Library Innovation Lab innovates, when it tries experiments, that’s what I’m looking for — what are the ways that we can strengthen cultural memory? Like:
Perma.cc, which literally repairs cultural memory by fixing link rot in court decisions and law journals — and now offers tools.perma.cc, which lets any library or archive run their own web archive with the policies that matter to their communities.
OpenCasebook.org, which lets law faculty collaborate on their own open source casebooks to reinvent the legal curriculum.
Case.law, which digitized seven million court decisions, and built a wide variety of interfaces around those decisions, to let everyone in the world explore US caselaw.
… and our new experiments in AI, which are once again focused on how to guide a new technology to have it help, rather than hurt, our ability to communicate and reason as a society.
We’re a small lab, and the things we can try are a small slice of the many ways libraries can explore novel missions. So for the rest of the talk, I’d like to share a grab bag of things I’ve learned about how to build a team that can respond to sharp changes in the graph and try something new.
How to build an innovation team — what I know so far
OK, so you’re on board with the idea that libraries should get themselves out of the disruptive innovation trap, by building teams that can test new and essential missions for their larger institutions. How do you do that?
You don’t have to be the size of Harvard to build an innovation team. The trick is to start with the resources you have, and build a loop that helps you grow:
Start with existing staff — your staff are innovating already, so you can start by just recognizing that and acknowledging it as part of their work.
Get easy wins — practice identifying new things you are doing that can be polished and announced.
Welcome participants — take the new projects, find people positively affected by them, and bring them into the conversation.
Tell your story — when you have small successes, broadcast them to build support for your work.
Grow resources — once you broadcast successes, use them to bring in more resources, which let you take on larger changes.
When you have this process up and running, the skills you are using will go in a loop something like this:
This won’t necessarily be eight people! It might be one person wearing eight hats. But if it’s working it will need skills like those eight people, so let’s talk through what these roles are bringing to the team:
Your product owner is responsible for placing bets and seeing them through. They keep track of what resources the team has to spend on getting things done and what opportunities there are to spend them, and they’re obsessive about making an impact.
Once bets are picked, your artist is an enthusiastic, optimistic creator who likes making new things and learning new skills. This could be a literal artist or a metaphorical artist — a programmer, a lawyer, a reference librarian, etc. — but someone who loves making the next thing.
Your researcher helps to measure your audience and your success and make what you learn replicable — what is the need we’re trying to fill, how well are we filling it, and how can we share what we learned?
Your community organizer is building relationships around your work — who are all the people affected by what you’re doing, and how can they be better informed and involved and represented? This job has lots of different names in practice, maybe “outreach” or “support.”
As cool things are made, they then need to be talked about. Press relations uses all of the cool stuff, the research about the cool stuff, and the relationships around the cool stuff to tell public stories about the cool stuff.
And finally, those successes feed back into your relationship with the larger institution that supports you. Innovation labs in larger organizations have a bunch of different complicated relationships that require different skill sets:
Your investor is whoever backs your bets, financially and otherwise. Often this is a professor or dean in a university library setting. They need to be on board with the risks you are taking and ready to back your decisions.
Your ambassador navigates impacts of innovation on the rest of the organization as you explore new missions, engaging with leaders of other groups who might be sensitive to you getting out of your lane or entering their territory.
Your administrator absorbs the new stress you’re putting on the larger organization, as the new things you’re trying to do put the bureaucracy through unexpected paces. (“I don’t know — how do we …” hire new kinds of people, take new forms of payment, get new kinds of permission from the trademark office, pursue new grants, enter new kinds of contracts — whatever it is you don’t usually ask for.)
With all of this up and running, you’ll be well set up to do the kind of design thinking process that you’ll often see highlighted in innovation talks:
It’s worth learning the details of this kind of process, or complementary processes like co-design and design justice, but the most important high level concept is the shape: with our patrons’ needs changing faster than before, we need to build tighter loops between exploring, prototyping, shipping changes, learning how they work, and using that information to explore again.
The other thing a group like this is well set up for is to explore new business models. Remember that at the end of the loop is “grow resources” that can feed back into your team. When newspapers lost their traditional funding stream of classified ads, the successful ones didn’t just switch to one new funding stream, but to lots of smaller ones, so they would be shielded from the shocks of any one funding source disappearing the way classified ads did.
Likewise, there are a wide variety of funding models libraries can explore, including: grants; gifts; corporate partnerships; mixed paid and free services; consortial funding; donations; pro bono support; and more. Running a flexible product process will allow you to try all of these, and learn what works for the kind of problems you need to solve.
Ending things
Finally I want to talk a bit about ending things. All successful ideas follow a course something like this:
An innovation team is best at the exploration and testing phases, and many library practices lead to excellence at the operation phase. But the phase I think is most important is the one we’re all bad at — sunsetting.
Patrons hate when we end things — there is always someone who deeply values whatever the thing is we were doing, and who can clearly articulate the values we were serving by doing it, and those are likely to be values we still honestly proclaim and hold. Ending things makes us feel like hypocrites.
But if we can’t end things well, we put impossible pressure on our operations teams to keep everything running forever, and in turn, those people end up stressed and understaffed and in no kind of mindset for exploration and testing of new ideas. We can’t do the rest well unless we’re good at endings — whether that’s ending near the beginning, in an exploratory phase where you have freedom to try and fail easily, or near the end, when you are helping a long term community understand that a service has to change.
I think the way we end things well is to focus on enduring values. Remember that the point was never to maximize the number of paper encyclopedias; the point was to be the cultural memory that strengthened our communities. It’s by articulating the underlying values we were trying to serve in the first place that we can best bring everyone on board with changes that are coming. We aren’t giving up, we’re moving on together.
We can’t avoid disruption, because our patrons don’t owe us their patronage and their needs are rapidly changing. But we remain necessary: we offer the cultural memory that allows society to function. So we need to build teams that can effectively test new ideas, and end old ideas, and do both of those by connecting, again and again, to the shared values that made all of this worth it: the values of building a public place where people can think, remember, plan, collaborate, and preserve the things that matter to them.
W. E. B. Du Bois, famous for nonfiction like The Souls of Black Folk and The Philadelphia Negro, also wrote fiction. His 1928 novel Dark Princess: A Romance is described by its current publisher as a “novel of sensual love, radical politics, and the quest for racial justice”. That blend of themes got a mixed reception from both Black and white reviewers, but in his 1940 autobiography Du Bois wrote that it was his favorite book. It joins the public domain in 35 days. #PublicDomainDayCountdown
I started rubyland.news a few years ago because it was a thing I wanted to see for the Ruby community. I had been feeling a shrinking of the ruby open source collaborative community, it felt like the room was emptying out.
I wanted to make people writing about ruby and what they were doing with it visible to each other and to the community, in order to try to (re)build/preserve/strengthen a self-conception as a community, connect people to each other, provide entry to newcomers, and just make it easier to find ruby news.
I develop and run rubyland.news in my spare time, as a hobby project, all by myself, on custom Rails software. I have never and will never accepted money for editorial placement — the feeds included in rubyland.news are exclusively based on my own judgement of what will serve readers and the community well.
Why am I asking for money?
The total cost of Rubyland News, including hosting and the hostname itself, are around $180 a month. Current personal regular monthly donations add up to about $100 a year — from five individual sponsors (thank you!!!!)
I pay for this out of my pocket. I’m doing totally fine, no need to worry about me, but I do work for an academic non-profit, and don’t have the commercial market software engineer income some may assume.
Sure, I could run it somewhere cheaper than heroku (and eventually might have to) — but I’m doing all this in my spare time, I don’t want to spend an iota more time or psychic energy on (to me) boring operational concerns than I need to.
Some donations would also help motivate me to keep putting energy into this, showing me that the project really does have value to the community. If I am funded to exceed my costs, I might also add resources necessary for additional features (like a non-limited DB to keep a searchable history around?)
If you donate $5/month or more, and would like to be publicly listed/thanked, I am very happy to do so, just let me know!
If you don’t want to donate or can’t spare the cash, but do want to send me an email telling me about your use of rubyland news, I would love that too! I really don’t get much feedback! And would love to know any features you want or need. (With formerly-known-as-twitter being on the downslide, are there similar services you’d like to see rubyland.news published to?) jonathan at rubyland.news)
Thanks
Thanks to anyone who donates anything at all
also to anyone who sends me a note to tell me that they value Rubyland News (seriously, I get virtually no feedback — telling me things you’d like to be better/different is seriously appreciated too! Or things you like about how it is now. I do this to serve the community, and appreciate feedback and suggestions!)
To anyone who reads Rubyland News at all
To anyone who blogs about ruby, especially if you have an RSS feed, especially if you are doing it as a hobbyist/community-member for purposes other than business leads!
To my current monthly github sponsors, it means a lot!
To anyone contributing in their own way to any part of open source communities for reasons other than profit, sometimes without much recognition, to help create free culture that isn’t just about exploiting each other!
The following post is part of an ongoing series about the OCLC-LIBER “Building for the future” program.
The OCLC Research Library Partnership (RLP) and LIBER (Association of European Research Libraries) hosted a facilitated discussion on the topic of research data management (RDM) on 15 November 2023. This event was offered as a component of the ongoing Building for the future series being jointly sponsored by our organizations where this year we are exploring the topic of how libraries are working to provide state-of-the-art services, as described in LIBER’s 2023-2027 strategy. RDM support is a core part of that vision.
OCLC RLP team members worked with members of the LIBER Research Data Management Working Group to develop the discussion questions, and we chose to explore one of the topics that came up during our planning: the challenges and tensions that RDM service providers face in their current work environments. We followed that with prompts about strategies, best practices, and what the ideal RDM landscape might look like.
The virtual event was attended by participants from eight countries and 25 institutions, offering a transnational view of RDM growth and challenges. Small group discussions were facilitated by volunteers from LIBER working groups and OCLC Research.
RDM professionals face plenty of challenges
Despite many institutional, regional, and national differences, I heard far more similarities than differences emerge in this discussion. RDM practitioners reported shared challenges, including:
Low awareness by researchers about available RDM services in the library. While many participants reported an increase in data management planning (DMP) mandates and services, many researchers were still unaware that RDM support services were available to support them. One person said, “People don’t think of the library,” and another voiced concerns that the library wasn’t [yet] seen as a competent partner in RDM. Several participants expressed frustration that when researchers did seek library support, they often came late in the research process, after key decisions and actions had already taken place.
Understaffing. There were near universal concerns about capacity, across many national environments in Europe and North America. In most cases, participants were “one-person operations” and “often isolated somewhat from the rest of the library.” RDM staff members typically had a broad portfolio of responsibilities that extended beyond RDM support, making it difficult to carve out time for strategic planning and relationship building with other campus stakeholders. Concerns about scalability of RDM services were ubiquitous.
Disciplinary differences (and needed expertise) create challenges. It’s impossible for a single RDM curator to be skillful in a wide array of disciplinary norms. One discussion group talked about how this presented a need for the RDM professional to be both expert and learner while working with researchers.
Many RDM professionals have a non-library background. Instead of library science degrees, many RDM professionals hold a PhD, often in a scientific discipline, which offers much relevant data management experience. But a challenge for these workers is that others in the library may not understand their work, creating the potential for tension and misunderstandings. One participant described feeling “not fully a part of any group.” This is consistent with scholar Celia Whitchurch’s description of “Third Space professionals” who are working in emerging areas situated within traditional organizational structures, a situation that can offer both security and constraints.[1]
RDM engagement is driven almost exclusively by mandates, rather than researcher interest. In other words, researchers may not be seeking input on that DMP because they want to improve their processes, but because they are required to have one. As a result, researchers frequently push back on these requirements, which can create a challenging environment for RDM professions. And these aren’t just STEM challenges. Humanist scholars also push back on requirements, in part because they may not perceive the content they have collected as “data,” and open science/reproducibility narratives don’t resonate with them.
Cross-campus collaboration is essential. There are many campus stakeholders with an interest in RDM, including researcher administrators and information technology (IT) professionals, and RDM service provision requires significant coordination or social interoperability. As we describe in our OCLC Research report on Social Interoperability in Research Support, this can be a challenging and time-intensive process, which many discussion group participants expressed frustration with.
When prompted to describe their experiences, participants shared the following, captured in this word cloud:
Word cloud summarizing participants’ feelings about the challenges of working in RDM
But there are strategies to make it work
Sure, that’s a long list of challenges. But participants shared numerous examples of how they were tackling these difficulties. These include:
Focus on working with early career researchers (ECRs). Postgraduate students and postdoctoral researchers are frequently more receptive to RDM support than later career researchers. Participants described working with ECRs as both an investment in the future as well as a bottom-up approach to influence the behavior of more senior researchers.
Invest time in collaborating with other campus units. One specific tactic mentioned was identifying human connectors who can help facilitate introductions and cross-campus relationship building. Another tactic was co-sponsoring events, which builds trust and can potentially also boost impact for both sponsoring units. This was echoed by a participant whose organization has seen the benefits of investing in a staff position focused on community engagement, trust building, and informal learning around RDM activities.
Find ways to proactively communicate with researchers early in the research process. For example, by working with the proposal/research development office on campus, it’s possible to identify researchers who have applied for grants requiring DMPs and to contact them at that stage, to offer support at the beginning of the project. Another participant described an intake/ticketing process that informed distributed RDM team members of a new request, to support transparency and triage.
Collect metrics and demonstrate impact. In order to advocate for more resources, RDM practitioners must demonstrate the usage and value of existing services. This requires developing a system for tracking consulting interactions and curation work and possibly creating a short annual report. I have found the annual reports by the Research Data Service at the University of Illinois a good example of this type of effort.
Imagining an ideal future
We concluded the event by asking participants to envision an ideal RDM ecosystem. Participants responded with these thoughts:
Improved structures to support cross-campus collaboration. The library is one of many RDM stakeholders on campus, and it must develop strong, trusting relationships with a new group of stakeholders to support researchers. Moving forward, institutions may need to develop new standing committees, task forces, and/or new operational configurations to provide greater stability. One recent example is the cross-unit RDM institutional strategy working group at the University of Waterloo (Canada), working in response to funder policies. LIBER, in collaboration with ADBU (the association of directors of university libraries in France), recently released a toolkit offering guidance to research libraries on the development of RDM support services. The toolkit recognizes the challenges of working in a multi-stakeholder environment.
Greater interoperability and FAIRness. Participants want greater ability to aggregate repository content at scale, made possible through greater interoperability and machine readability. This is consistent with LIBER goals, including its joint strategy with OpenAIRE and SPARC Europe to strengthen the European repository network. SPARC US is similarly leading efforts to create a U.S. Repository Network (USRN).
Leveraging multi-institutional collaboration to scale. Working with practitioners at other institutions is seen as highly desirable for many reasons: to scale capacity and expertise, to share experiences and best practices, for mutual support, and to provide greater equity and access to researchers at smaller institutions. This is the topic of a forthcoming OCLC Research report entitled Building Research Data Management Capacity: Case Studies in Strategic Library Collaboration, which provides actionable recommendations based upon real-world examples of multi-institutional collaborations, including the US-based Data Curation Network.
Increased researcher buy-in. Participants would like to work with researchers who have embraced datasets as a first-class research object and don’t see RDM management as a mandated chore. Participants envisioned ways to incentivize data sharing research behaviors, such as the incorporation of RDM training in the postgraduate student curriculum. Another suggestion was the revision of institutional policies to reward data sharing, similar to journal publishing.
More resources, please. In an ideal environment, participants imagined more staff, unlimited IT support, and much more funding. One participant said, “If they [agencies] want open data, they need to pay for it.”
Finding your people
Word cloud summary from event polling
Working in an emerging area of practice can feel lonely, particularly when there aren’t others doing similar work at your own institution. This event brought together RDM professionals from across Europe and North America, and it was gratifying to hear that participants valued their time together and felt validated, encouraged, and connected by the event.
Join us for the upcoming facilitated discussion on data-driven decision making
This RDM session was the first of three facilitated discussions on state-of-the-art services that we are hosting in 2023-2024. The next event takes place on 7 February, when we will collectively dive into the topic of data-driven decision making. In this 90-minute session, we will explore how libraries are using data and analytics to inform library decision making in areas such as shared print and collective collections, contract management and publisher negotiations, and research impact and visualizations. Register today to save your spot; virtual spots are limited.
[1] Whitchurch, Celia. 2015. “The Rise of Third Space Professionals: Paradoxes and Dilemmas.” In: Forming, Recruiting and Managing the Academic Profession, edited by U. Teichler and W. Cummings, vol. 14. The Changing Academy – The Changing Academic Profession in International Comparative Perspective. Switzerland: Springer, Cham. https://doi.org/10.1007/978-3-319-16080-1_5.
The most beloved community conference for datamakers from all around the world is back in May 2024! After a very successful seventh edition in Buenos Aires in April 2023, we have decided to linger a little longer in Latin America. We are very excited to announce that csv,conf,v8 will take place in Mexico!
The commallama will take over Puebla (close to Mexico City) for two full days. Please block 29-31 May 2024 in your calendars (+ 27-28 May for pre conference events), because we already anticipate a mindblowing edition, with excellent keynote speakers, inspiring talks, and amazing communities from all over the world. If you are passionate about data and its application to society, this is the conference for you. Get ready for a two-day blast where you can hear about cool ongoing projects, swap skills, ideas, and kickstart awesome collaborations!
The call for session proposals is now open and you can submit in English or in Spanish. Deadline for session proposals is January 10th. Keep an eye on the website, more information about the location and speakers will also be there soon. Meanwhile, please share the news wildly within your networks. We can’t wait to see you all in Mexico!
Harvard geologist Kirtley F. Mather was an activist for academic freedom (advocating for teaching evolution and against faculty loyalty oaths) and president of Promoting Enduring Peace. Kennard B. Bork writes in GSA Today that he had a “deep belief in the mutual powers of the scientific endeavor and religious faith”.
He published two books in 1928, Old Mother Earth and Science in Search of God, that express many of his passions. Both join the public domain in 36 days. #PublicDomainDayCountdown

 Example of table of contents
Example of table of contents
 The PDF has a proper structure
The PDF has a proper structure
 OKFN and Ushahidi teams in Addis Ababa during the DPGA summit (Photos: courtesy of Ushahidi)
OKFN and Ushahidi teams in Addis Ababa during the DPGA summit (Photos: courtesy of Ushahidi)






















.jpg)



 In October, with support from a
In October, with support from a 












 Screenshots of realtime translation of Nicolas Petrosini, Universidad de Palermo’s, talk, Integrando tecnología y aprendizaje en la biblioteca universitaria: ChatGPT, TikTok y la alfabetización en inteligencia artificial.
Screenshots of realtime translation of Nicolas Petrosini, Universidad de Palermo’s, talk, Integrando tecnología y aprendizaje en la biblioteca universitaria: ChatGPT, TikTok y la alfabetización en inteligencia artificial.












 Data Reportal:
Data Reportal:  Statista:
Statista: 

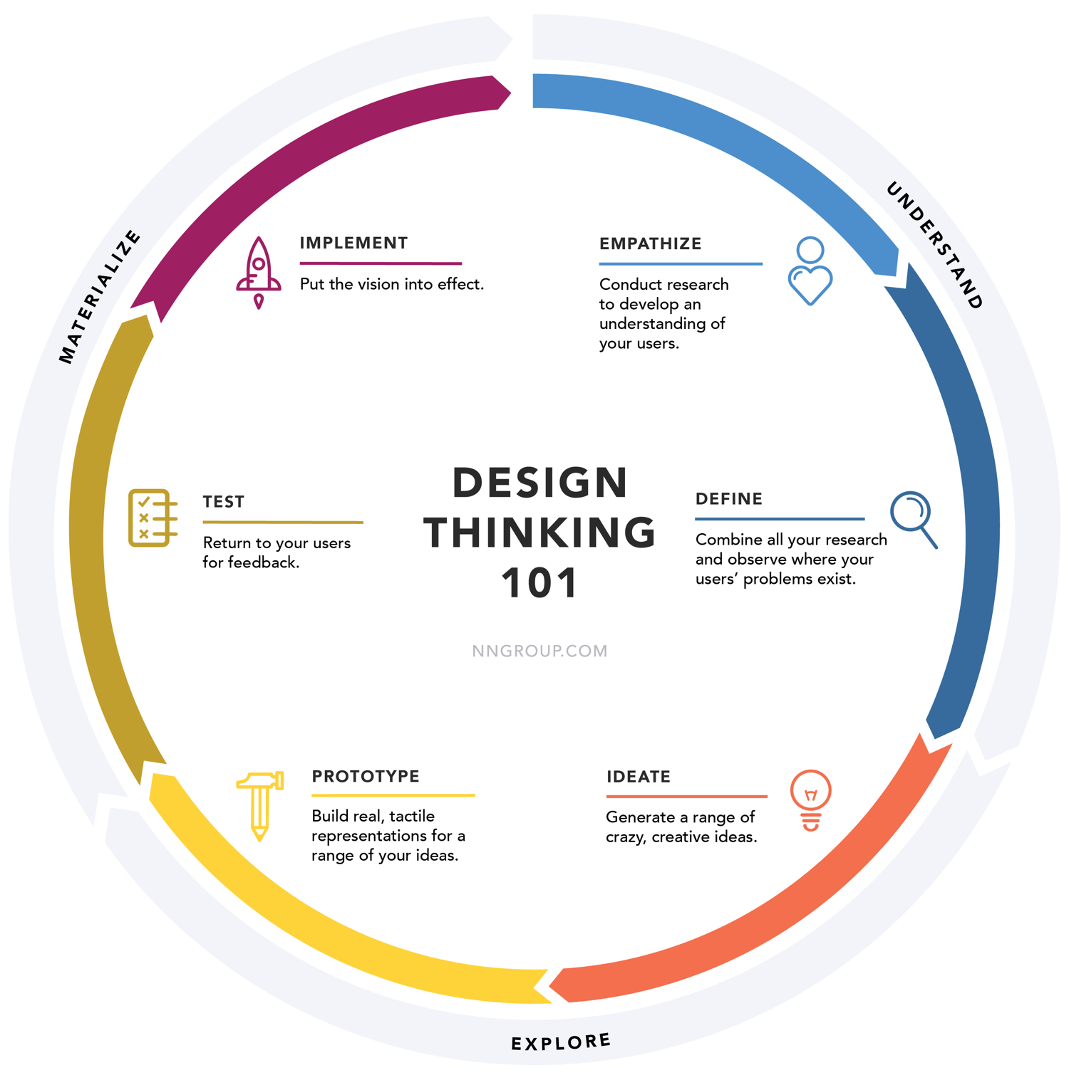 Nielsen Norman Group,
Nielsen Norman Group, 



{kind=link}