Recent entries
Datasette 1.0a4 and 1.0a5, plus weeknotes two hours ago
Two new alpha releases of Datasette, plus a keynote at WordCamp, a new LLM release, two new LLM plugins and a flurry of TILs.
Datasette 1.0a5
Released this morning, Datasette 1.0a5 has some exciting new changes driven by Datasette Cloud and the ongoing march towards Datasette 1.0.
Alex Garcia is working with me on Datasette Cloud and Datasette generally, generously sponsored by Fly.
Two of the changes in 1.0a5 were driven by Alex:
New
datasette.yaml(or.json) configuration file, which can be specified usingdatasette -c path-to-file. The goal here to consolidate settings, plugin configuration, permissions, canned queries, and other Datasette configuration into a single single file, separate frommetadata.yaml. The legacysettings.jsonconfig file used for Configuration directory mode has been removed, anddatasette.yamlhas a"settings"section where the same settings key/value pairs can be included. In the next future alpha release, more configuration such as plugins/permissions/canned queries will be moved to thedatasette.yamlfile. See #2093 for more details.
Right from the very start of the project, Datasette has supported specifying metadata about databases—sources, licenses, etc, as a metadata.json file that can be passed to Datasette like this:
datasette data.db -m metadata.jsonOver time, the purpose and uses of that file has expanded in all kinds of different directions. It can be used for plugin settings, and to set preferences for a table default page size, default facets etc), and even to configure access permissions for who can view what.
The name metadata.json is entirely inappropriate for what the file actually does. It’s a mess.
I’ve always had a desire to fix this before Datasette 1.0, but it never quite got high up enough the priority list for me to spend time on it.
Alex expressed interest in fixing it, and has started to put a plan into motion for cleaning it up.
More details in the issue.
The Datasette
_internaldatabase has had some changes. It no longer shows up in thedatasette.databaseslist by default, and is now instead available to plugins using thedatasette.get_internal_database(). Plugins are invited to use this as a private database to store configuration and settings and secrets that should not be made visible through the default Datasette interface. Users can pass the new--internal internal.dboption to persist that internal database to disk. (#2157).
This was the other initiative driven by Alex. In working on Datasette Cloud we realized that it’s actually quite common for plugins to need somewhere to store data that shouldn’t necessarily be visible to regular users of a Datasette instance—things like tokens created by datasette-auth-tokens, or the progress bar mechanism used by datasette-upload-csvs.
Alex pointed out that the existing _internal database for Datasette could be expanded to cover these use-cases as well. #2157 has more details on how we agreed this should work.
The other changes in 1.0a5 were driven by me:
When restrictions are applied to API tokens, those restrictions now behave slightly differently: applying the
view-tablerestriction will imply the ability toview-databasefor the database containing that table, and bothview-tableandview-databasewill implyview-instance. Previously you needed to create a token with restrictions that explicitly listedview-instanceandview-databaseandview-tablein order to view a table without getting a permission denied error. (#2102)
I described finely-grained permissions for access tokens in my annotated release notes for 1.0a2.
They provide a mechanism for creating an API token that’s only allowed to perform a subset of actions on behalf of the user.
In trying these out for Datasette Cloud I came across a nasty usability flaw. You could create a token that was restricted to view-table access for a specific table... and it wouldn’t work. Because the access code for that view would check for view-instance and view-database permission first.
1.0a5 fixes that, by adding logic that says that if a token can view-table that implies it can view-database for the database containing that table, and view-instance for the overall instance.
This change took quite some time to develop, because any time I write code involving permissions I like to also include extremely comprehensive automated tests.
The
-s/--settingoption can now take dotted paths to nested settings. These will then be used to set or over-ride the same options as are present in the new configuration file. (#2156)
This is a fun little detail inspired by Alex’s configuration work.
I run a lot of different Datasette instances, often on an ad-hoc basis.
I sometimes find it frustrating that to use certain features I need to create a metadata.json (soon to be datasette.yml) configuration file, just to get something to work.
Wouldn’t it be neat if every possible setting for Datasette could be provided both in a configuration file or as command-line options?
That’s what the new --setting option aims to solve. Anything that can be represented as a JSON or YAML configuration can now also be represented as key/value pairs on the command-line.
Here’s an example from my initial issue comment:
datasette \
-s settings.sql_time_limit_ms 1000 \
-s plugins.datasette-auth-tokens.manage_tokens true \
-s plugins.datasette-auth-tokens.manage_tokens_database tokens \
-s plugins.datasette-ripgrep.path "/home/simon/code-to-search" \
-s databases.mydatabase.tables.example_table.sort created \
mydatabase.db tokens.dbOnce this feature is complete, the above will behave the same as a datasette.yml file containing this:
plugins:
datasette-auth-tokens:
manage_tokens: true
manage_tokens_database: tokens
datasette-ripgrep:
path: /home/simon/code-to-search
databases:
mydatabase:
tables:
example_table:
sort: created
settings:
sql_time_limit_ms: 1000I’ve experimented with ways of turning key/value pairs into nested JSON objects before, with my json-flatten library.
This time I took a slightly different approach. In particular, if you need to pass a nested JSON object (such as an array) which isn’t easily represented using key.nested notation, you can pass it like this instead:
datasette data.db \
-s plugins.datasette-complex-plugin.configs \
'{"foo": [1,2,3], "bar": "baz"}'Which would convert to the following equivalent YAML:
plugins:
datasette-complex-plugin:
configs:
foo:
- 1
- 2
- 3
bar: bazThese examples don’t quite work yet, because the plugin configuration hasn’t migrated to datasette.yml—but it should work for the next alpha.
New
--actor '{"id": "json-goes-here"}'option for use withdatasette --getto treat the simulated request as being made by a specific actor, see datasette --get. (#2153)
This is a fun little debug helper I built while working on restricted tokens.
The datasette --get /... option is a neat trick that can be used to simulate an HTTP request through the Datasette instance, without even starting a server running on a port.
I use it for things like generating social media card images for my TILs website.
The new --actor option lets you add a simulated actor to the request, which is useful for testing out things like configured authentication and permissions.
A security fix in Datasette 1.0a4
Datasette 1.0a4 has a security fix: I realized that the API explorer I added in the 1.0 alpha series was exposing the names of databases and tables (though not their actual content) to unauthenticated users, even for Datasette instances that were protected by authentication.
I issued a GitHub security advisory for this: Datasette 1.0 alpha series leaks names of databases and tables to unauthenticated users, which has since been issued a CVE, CVE-2023-40570—GitHub is a CVE Numbering Authority which means their security team are trusted to review such advisories and issue CVEs where necessary.
I expect the impact of this vulnerability to be very small: outside of Datasette Cloud very few people are running the Datasette 1.0 alphas on the public internet, and it’s possible that the set of those users who are also authenticating their instances to provide authenticated access to private data—especially where just the database and table names of that data is considered sensitive—is an empty set.
Datasette Cloud itself has detailed access logs primarily to help evaluate this kind of threat. I’m pleased to report that those logs showed no instances of an unauthenticated user accessing the pages in question prior to the bug being fixed.
A keynote at WordCamp US
Last Friday I gave a keynote at WordCamp US on the subject of Large Language Models.
I used MacWhisper and my annotated presentation tool to turn that into a detailed transcript, complete with additional links and context: Making Large Language Models work for you.
llm-openrouter and llm-anyscale-endpoints
I released two new plugins for LLM, which lets you run large language models either locally or via APIs, as both a CLI tool and a Python library.
Both plugins provide access to API-hosted models:
- llm-openrouter provides access to models hosted by OpenRouter. Of particular interest here is Claude—I’m still on the waiting list for the official Claude API, but in the meantime I can pay for access to it via OpenRouter and it works just fine. Claude has a 100,000 token context, making it a really great option for working with larger documents.
- llm-anyscale-endpoints is a similar plugin that instead works with Anyscale Endpoints. Anyscale provide Llama 2 and Code Llama at extremely low prices—between $0.25 and $1 per million tokens, depending on the model.
These plugins were very quick to develop.
Both OpenRouter and Anyscale Endpoints provide API endpoints that emulate the official OpenAI APIs, including the way the handle streaming tokens.
LLM already has code for talking to those endpoints via the openai Python library, which can be re-pointed to another backend using the officially supported api_base parameter.
So the core code for the plugins ended up being less than 30 lines each: llm_openrouter.py and llm_anyscale_endpoints.py.
llm 0.8
I shipped LLM 0.8 a week and a half ago, with a bunch of small changes.
The most significant of these was a change to the default llm logs output, which shows the logs (recorded in SQLite) of the previous prompts and responses you have sent through the tool.
This output used to be JSON. It’s now Markdown, which is both easier to read and can be pasted into GitHub Issue comments or Gists or similar to share the results with other people.
The release notes for 0.8 describe all of the other improvements.
sqlite-utils 3.35
The 3.35 release of sqlite-utils was driven by LLM.
sqlite-utils has a mechanism for adding foreign keys to an existing table—something that’s not supported by SQLite out of the box.
That implementation used to work using a deeply gnarly hack: it would switch the sqlite_master table over to being writable (using PRAGMA writable_schema = 1), update that schema in place to reflect the new foreign keys and then toggle writable_schema = 0 back again.
It turns out there are Python installations out there—most notably the system Python on macOS—which completely disable the ability to write to that table, no matter what the status of the various pragmas.
I was getting bug reports from LLM users who were running into this. I realized that I had a solution for this mostly implemented already: the sqlite-utils transform() method, which can apply all sorts of complex schema changes by creating a brand new table, copying across the old data and then renaming it to replace the old one.
So I dropped the old writable_schema mechanism entirely in favour of .transform()—it’s slower, because it requires copying the entire table, but it doesn’t have weird edge-cases where it doesn’t work.
Since sqlite-utils supports plugins now, I realized I could set a healthy precedent by making the removed feature available in a new plugin: sqlite-utils-fast-fks, which provides the following command for adding foreign keys the fast, old way (provided your installation supports it):
sqlite-utils install sqlite-utils-fast-fks
sqlite-utils fast-fks my_database.db places country_id country idI’ve always admired how jQuery uses plugins to keep old features working on an opt-in basis after major version upgrades. I’m excited to be able to apply the same pattern for sqlite-utils.
paginate-json 1.0
paginate-json is a tiny tool I first released a few years ago to solve a very specific problem.
There’s a neat pattern in some JSON APIs where the HTTP link header is used to indicate subsequent pages of results.
The best example I know of this is the GitHub API. Run this to see what it looks like here I’m using the events API):
curl -i \
https://api.github.com/users/simonw/eventsHere’s a truncated example of the output:
HTTP/2 200
server: GitHub.com
content-type: application/json; charset=utf-8
link: <https://api.github.com/user/9599/events?page=2>; rel="next", <https://api.github.com/user/9599/events?page=9>; rel="last"
[
{
"id": "31467177730",
"type": "PushEvent",
The link header there specifies a next and last URL that can be used for pagination.
To fetch all available items, you can follow the next link repeatedly until it runs out.
My paginate-json tool can follow these links for you. If you run it like this:
paginate-json \
https://api.github.com/users/simonw/eventsIt will output a single JSON array consisting of the results from every available page.
The 1.0 release adds a bunch of small features, but also marks my confidence in the stability of the design of the tool.
The Datasette JSON API has supported link pagination for a while—you can use paginate-json with Datasette like this, taking advantage of the new --key option to paginate over the array of objects returned in the "rows" key:
paginate-json \
'https://datasette.io/content/pypi_releases.json?_labels=on' \
--key rows \
--nlThe --nl option here causes paginate-json to output the results as newline-delimited JSON, instead of bundling them together into a JSON array.
Here’s how to use sqlite-utils insert to insert that data directly into a fresh SQLite database:
paginate-json \
'https://datasette.io/content/pypi_releases.json?_labels=on' \
--key rows \
--nl | \
sqlite-utils insert data.db releases - \
--nl --flattenReleases this week
-
paginate-json 1.0—2023-08-30
Command-line tool for fetching JSON from paginated APIs -
datasette-auth-tokens 0.4a2—2023-08-29
Datasette plugin for authenticating access using API tokens -
datasette 1.0a5—2023-08-29
An open source multi-tool for exploring and publishing data -
llm-anyscale-endpoints 0.2—2023-08-25
LLM plugin for models hosted by Anyscale Endpoints -
datasette-jellyfish 2.0—2023-08-24
Datasette plugin adding SQL functions for fuzzy text matching powered by Jellyfish -
datasette-configure-fts 1.1.2—2023-08-23
Datasette plugin for enabling full-text search against selected table columns -
datasette-ripgrep 0.8.1—2023-08-21
Web interface for searching your code using ripgrep, built as a Datasette plugin -
datasette-publish-fly 1.3.1—2023-08-21
Datasette plugin for publishing data using Fly -
llm-openrouter 0.1—2023-08-21
LLM plugin for models hosted by OpenRouter -
llm 0.8—2023-08-21
Access large language models from the command-line -
sqlite-utils-fast-fks 0.1—2023-08-18
Fast foreign key addition for sqlite-utils -
datasette-edit-schema 0.5.3—2023-08-18
Datasette plugin for modifying table schemas -
sqlite-utils 3.35—2023-08-18
Python CLI utility and library for manipulating SQLite databases
TIL this week
- Streaming output of an indented JSON array—2023-08-30
- Downloading partial YouTube videos with ffmpeg—2023-08-26
- Compile and run a new SQLite version with the existing sqlite3 Python library on macOS—2023-08-22
- Configuring Django SQL Dashboard for Fly PostgreSQL—2023-08-22
- Calculating the size of a SQLite database file using SQL—2023-08-21
- Updating stable docs in ReadTheDocs without pushing a release—2023-08-21
- A shell script for running Go one-liners—2023-08-20
- A one-liner to output details of the current Python’s SQLite—2023-08-19
- A simple pattern for inlining binary content in a Python script—2023-08-19
- Running multiple servers in a single Bash script—2023-08-17
Making Large Language Models work for you three days ago
I gave an invited keynote at WordCamp 2023 in National Harbor, Maryland on Friday.
I was invited to provide a practical take on Large Language Models: what they are, how they work, what you can do with them and what kind of things you can build with them that could not be built before.
As a long-time fan of WordPress and the WordPress community, which I think represents the very best of open source values, I was delighted to participate.
You can watch my talk on YouTube here (starts at 8 hours, 18 minutes and 20 seconds). Here are the slides and an annotated transcript, prepared using the custom tool I described in this post.
- What they are
- How they work
- How to use them
- Personal AI ethics
- What we can build with them
- Giving them access to tools
- Retrieval augmented generation
- Embeddings and semantic search
- ChatGPT Code Interpreter
- How they’re trained
- Openly licensed models
- Prompt injection
- Helping everyone program computers
Datasette Cloud, Datasette 1.0a3, llm-mlc and more 13 days ago
Datasette Cloud is now a significant step closer to general availability. The Datasette 1.03 alpha release is out, with a mostly finalized JSON format for 1.0. Plus new plugins for LLM and sqlite-utils and a flurry of things I’ve learned.
Datasette Cloud
Yesterday morning we unveiled the new Datasette Cloud blog, and kicked things off there with two posts:
- Welcome to Datasette Cloud provides an introduction to the product: what it can do so far, what’s coming next and how to sign up to try it out.
- Introducing datasette-write-ui: a Datasette plugin for editing, inserting, and deleting rows introduces a brand new plugin, datasette-write-ui—which finally adds a user interface for editing, inserting and deleting rows to Datasette.
Here’s a screenshot of the interface for creating a new private space in Datasette Cloud:
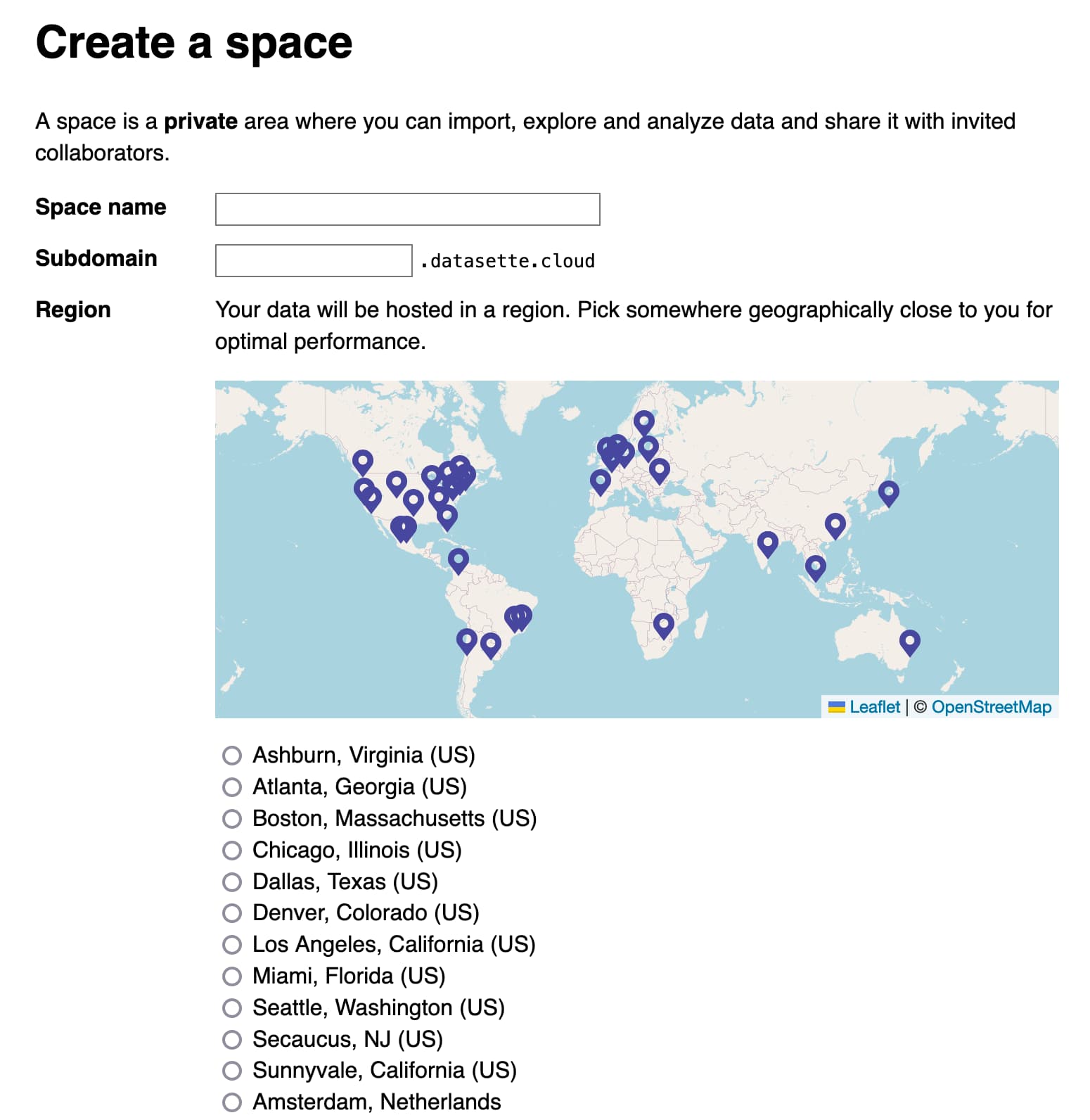
datasette-write-ui is particularly notable because it was written by Alex Garcia, who is now working with me to help get Datasette Cloud ready for general availability.
Alex’s work on the project is being supported by Fly.io, in a particularly exciting form of open source sponsorship. Datasette Cloud is already being built on Fly, but as part of Alex’s work we’ll be extensively documenting what we learn along the way about using Fly to build a multi-tenant SaaS platform.
Alex has some very cool work with Fly’s Litestream in the pipeline which we hope to talk more about shortly.
Since this is my first time building a blog from scratch in quite a while, I also put together a new TIL on Building a blog in Django.
The Datasette Cloud work has been driving a lot of improvements to other parts of the Datasette ecosystem, including improvements to datasette-upload-dbs and the other big news this week: Datasette 1.0a3.
Datasette 1.0a3
Datasette 1.0 is the first version of Datasette that will be marked as “stable”: if you build software on top of Datasette I want to guarantee as much as possible that it won’t break until Datasette 2.0, which I hope to avoid ever needing to release.
The three big aspects of this are:
- A stable plugins interface, so custom plugins continue to work
- A stable JSON API format, for integrations built against Datasette
- Stable template contexts, so that custom templates won’t be broken by minor changes
The 1.0 alpha 3 release primarily focuses on the JSON support. There’s a new, much more intuitive default shape for both the table and the arbitrary query pages, which looks like this:
{
"ok": true,
"rows": [
{
"id": 3,
"name": "Detroit"
},
{
"id": 2,
"name": "Los Angeles"
},
{
"id": 4,
"name": "Memnonia"
},
{
"id": 1,
"name": "San Francisco"
}
],
"truncated": false
}This is a huge improvement on the old format, which featured a vibrant mess of top-level keys and served the rows up as an array-of-arrays, leaving the user to figure out which column was which by matching against "columns".
The new format is documented here. I wanted to get this in place as soon as possible for Datasette Cloud (which is running this alpha), since I don’t want to risk paying customers building integrations that would later break due to 1.0 API changes.
llm-mlc
My LLM tool provides a CLI utility and Python library for running prompts through Large Language Models. I added plugin support to it a few weeks ago, so now it can support additional models through plugins—including a variety of models that can run directly on your own device.
For a while now I’ve been trying to work out the easiest recipe to get a Llama 2 model running on my M2 Mac with GPU acceleration.
I finally figured that out the other week, using the excellent MLC Python library.
I built a new plugin for LLM called llm-mlc. I think this may now be one of the easiest ways to run Llama 2 on an Apple Silicon Mac with GPU acceleration.
Here are the steps to try it out. First, install LLM—which is easiest with Homebrew:
brew install llmIf you have a Python 3 environment you can run pip install llm or pipx install llm instead.
Next, install the new plugin:
llm install llm-mlcThere’s an additional installation step which I’ve not yet been able to automate fully—on an M1/M2 Mac run the following:
llm mlc pip install --pre --force-reinstall \
mlc-ai-nightly \
mlc-chat-nightly \
-f https://mlc.ai/wheelsInstructions for other platforms can be found here.
Now run this command to finish the setup (which configures git-lfs ready to download the models):
llm mlc setupAnd finally, you can download the Llama 2 model using this command:
llm mlc download-model Llama-2-7b-chat --alias llama2And run a prompt like this:
llm -m llama2 'five names for a cute pet ferret'It’s still more steps than I’d like, but it seems to be working for people!
As always, my goal for LLM is to grow a community of enthusiasts who write plugins like this to help support new models as they are released. That’s why I put a lot of effort into building this tutorial about Writing a plugin to support a new model.
Also out now: llm 0.7, which mainly adds a new mechanism for adding custom aliases to existing models:
llm aliases set turbo gpt-3.5-turbo-16k
llm -m turbo 'An epic Greek-style saga about a cheesecake that builds a SQL database from scratch'openai-to-sqlite and embeddings for related content
A smaller release this week: openai-to-sqlite 0.4, an update to my CLI tool for loading data from various OpenAI APIs into a SQLite database.
My inspiration for this release was a desire to add better related content to my TIL website.
Short version: I did exactly that! Each post on that site now includes a list of related posts that are generated using OpenAI embeddings, which help me plot posts that are semantically similar to each other.
I wrote up a full TIL about how that all works: Storing and serving related documents with openai-to-sqlite and embeddings—scroll to the bottom of that post to see the new related content in action.
I’m fascinated by embeddings. They’re not difficult to run using locally hosted models either—I hope to add a feature to LLM to help with that soon.
Getting creative with embeddings by Amelia Wattenberger is a great example of some of the more interesting applications they can be put to.
sqlite-utils-jq
A tiny new plugin for sqlite-utils, inspired by this Hacker News comment and written mainly as an excuse for me to exercise that new plugins framework a little more.
sqlite-utils-jq adds a new jq() function which can be used to execute jq programs as part of a SQL query.
Install it like this:
sqlite-utils install sqlite-utils-jqNow you can do things like this:
sqlite-utils memory "select jq(:doc, :expr) as result" \
-p doc '{"foo": "bar"}' \
-p expr '.foo'You can also use it in combination with sqlite-utils-litecli to run that new function as part of an interactive shell:
sqlite-utils install sqlite-utils-litecli
sqlite-utils litecli data.db
# ...
Version: 1.9.0
Mail: https://groups.google.com/forum/#!forum/litecli-users
GitHub: https://github.com/dbcli/litecli
data.db> select jq('{"foo": "bar"}', '.foo')
+------------------------------+
| jq('{"foo": "bar"}', '.foo') |
+------------------------------+
| "bar" |
+------------------------------+
1 row in set
Time: 0.031s
Other entries this week
How I make annotated presentations describes the process I now use to create annotated presentations like this one for Catching up on the weird world of LLMs (now up to over 17,000 views on YouTube!) using a new custom annotation tool I put together with the help of GPT-4.
A couple of highlights from my TILs:
- Catching up with the Cosmopolitan ecosystem describes my latest explorations of Cosmopolitan and Actually Portable Executable, based on an update I heard from Justine Tunney.
- Running a Django and PostgreSQL development environment in GitHub Codespaces shares what I’ve learned about successfully running a Django and PostgreSQL development environment entirely through the browser using Codespaces.
Releases this week
-
openai-to-sqlite 0.4—2023-08-15
Save OpenAI API results to a SQLite database -
llm-mlc 0.5—2023-08-15
LLM plugin for running models using MLC -
datasette-render-markdown 2.2.1—2023-08-15
Datasette plugin for rendering Markdown -
db-build 0.1—2023-08-15
Tools for building SQLite databases from files and directories -
paginate-json 0.3.1—2023-08-12
Command-line tool for fetching JSON from paginated APIs -
llm 0.7—2023-08-12
Access large language models from the command-line -
sqlite-utils-jq 0.1—2023-08-11
Plugin adding a jq() SQL function to sqlite-utils -
datasette-upload-dbs 0.3—2023-08-10
Upload SQLite database files to Datasette -
datasette 1.0a3—2023-08-09
An open source multi-tool for exploring and publishing data
TIL this week
- Processing a stream of chunks of JSON with ijson—2023-08-16
- Building a blog in Django—2023-08-15
- Storing and serving related documents with openai-to-sqlite and embeddings—2023-08-15
- Combined release notes from GitHub with jq and paginate-json—2023-08-12
- Catching up with the Cosmopolitan ecosystem—2023-08-10
- Running a Django and PostgreSQL development environment in GitHub Codespaces—2023-08-10
- Scroll to text fragments—2023-08-08
How I make annotated presentations 23 days ago
Giving a talk is a lot of work. I go by a rule of thumb I learned from Damian Conway: a minimum of ten hours of preparation for every one hour spent on stage.
If you’re going to put that much work into something, I think it’s worth taking steps to maximize the value that work produces—both for you and for your audience.
One of my favourite ways of getting “paid” for a talk is when the event puts in the work to produce a really good video of that talk, and then shares that video online. North Bay Python is a fantastic example of an event that does this well: they team up with Next Day Video and White Coat Captioning and have talks professionally recorded, captioned and uploaded to YouTube within 24 hours of the talk being given.
Even with that quality of presentation, I don’t think a video on its own is enough. My most recent talk was 40 minutes long—I’d love people to watch it, but I myself watch very few 40m long YouTube videos each year.
So I like to publish my talks with a text and image version of the talk that can provide as much of the value as possible to people who don’t have the time or inclination to sit through a 40m talk (or 20m if you run it at 2x speed, which I do for many of the talks I watch myself).
Annotated presentations
My preferred format for publishing these documents is as an annotated presentation—a single document (no clicking “next” dozens of times) combining key slides from the talk with custom written text to accompany each one, plus additional links and resources.
Here’s my most recent example: Catching up on the weird world of LLMs, from North Bay Python last week.
More examples:
- Prompt injection explained, with video, slides, and a transcript for a LangChain webinar in May 2023.
- Coping strategies for the serial project hoarder for DjangoCon US 2022.
- How to build, test and publish an open source Python library for PyGotham 2021
- Video introduction to Datasette and sqlite-utils for FOSDEM February 2021
- Datasette—an ecosystem of tools for working with small data for PyGotham 2020.
- Personal Data Warehouses: Reclaiming Your Data for the GitHub OCTO speaker series in November 2020.
- Redis tutorial for NoSQL Europe 2010 (my first attempt at this format).
I don’t tend to write a detailed script for my talks in advance. If I did, I might use that as a starting point, but I usually prepare the outline of the talk and then give it off-the-cuff on the day. I find this fits my style (best described as “enthusiastic rambling”) better.
Instead, I’ll assemble notes for each slide from re-watching the video after it has been released.
I don’t just cover the things I said in the the talk—I’ll also add additional context, and links to related resources. The annotated presentation isn’t just for people who didn’t watch the talk, it’s aimed at providing extra context for people who did watch it as well.
A custom tool for building annotated presentations
For this most recent talk I finally built something I’ve been wanting for years: a custom tool to help me construct the annotated presentation as quickly as possible.
Annotated presentations look deceptively simple: each slide is an image and one or two paragraphs of text.
There are a few extra details though:
- The images really need good
alt=text—a big part of the information in the presentation is conveyed by those images, so they need to have good descriptions both for screen reader users and to index in search engines / for retrieval augmented generation. - Presentations might have dozens of slides in—just assembling the image tags in the correct order can be a frustrating task.
- For editing the annotations I like to use Markdown, as it’s quicker to write than HTML. Making this as easy as possible encourages me to add more links, bullet points and code snippets.
One of my favourite use-cases for tools like ChatGPT is to quickly create one-off custom tools. This was a perfect fit for that.
You can see the tool I create here: Annotated presentation creator (source code here).
The first step is to export the slides as images, being sure to have filenames which sort alphabetically in the correct order. I use Apple Keynote for my slides and it has an “Export” feature which does this for me.
Next, open those images using the annotation tool.
The tool is written in JavaScript and works entirely in your browser—it asks you to select images but doesn’t actually upload them to a server, just displays them directly inline in the page.
Anything you type in a textarea as work-in-progress will be saved to localStorage, so a browser crash or restart shouldn’t lose any of your work.
It uses Tesseract.js to run OCR against your images, providing a starting point for the alt= attributes for each slide.
Annotations can be entered in Markdown and are rendered to HTML as a live preview using the Marked library.
Finally, it offers a templating mechanism for the final output, which works using JavaScript template literals. So once you’ve finished editing the alt= text and writing the annotations, click “Execute template” at the bottom of the page and copy out the resulting HTML.
Here’s an animated GIF demo of the tool in action:

I ended up putting this together with the help of multiple different ChatGPT sessions. You can see those here:
- HTML and JavaScript in a single document to create an app that lets me do the following...
- JavaScript and HTML app on one page. User can select multiple image files on their own computer...
- JavaScript that runs once every 1s and builds a JavaScript object of every textarea on the page where the key is the name= attribute of that textarea and the value is its current contents. That whole object is then stored in localStorage in a key called savedTextAreas...
- Write a JavaScript function like this: executeTemplates(template, arrayOfObjects)...
Cleaning up the transcript with Claude
Since the video was already up on YouTube when I started writing the annotations, I decided to see if I could get a head start on writing them using the YouTube generated transcript.
I used my Action Transcription tool to extract the transcript, but it was pretty low quality—you can see a copy of it here. A sample:
okay hey everyone it's uh really
exciting to be here so yeah I call this
court talk catching up on the weird
world of llms I'm going to try and give
you the last few years of of llm
developments in 35 minutes this is
impossible so uh hopefully I'll at least
give you a flavor of some of the weirder
corners of the space because the thing
about language models is the more I look
at the more I think they're practically
interesting any particular aspect of
them anything at all if you zoom in
there are just more questions there are
just more unknowns about it there are
more interesting things to get into lots
of them are deeply disturbing and
unethical lots of them are fascinating
it's um I've called it um it's it's
impossible to tear myself away from this
I I just keep on keep on finding new
aspects of it that are interesting
It’s basically one big run-on sentence, with no punctuation, little capitalization and lots of umms and ahs.
Anthropic’s Claude 2 was released last month and supports up to 100,000 tokens per prompt—a huge improvement on ChatGPT (4,000) and GPT-4 (8,000). I decided to see if I could use that to clean up my transcript.
I pasted it into Claude and tried a few prompts... until I hit upon this one:
Reformat this transcript into paragraphs and sentences, fix the capitalization and make very light edits such as removing ums
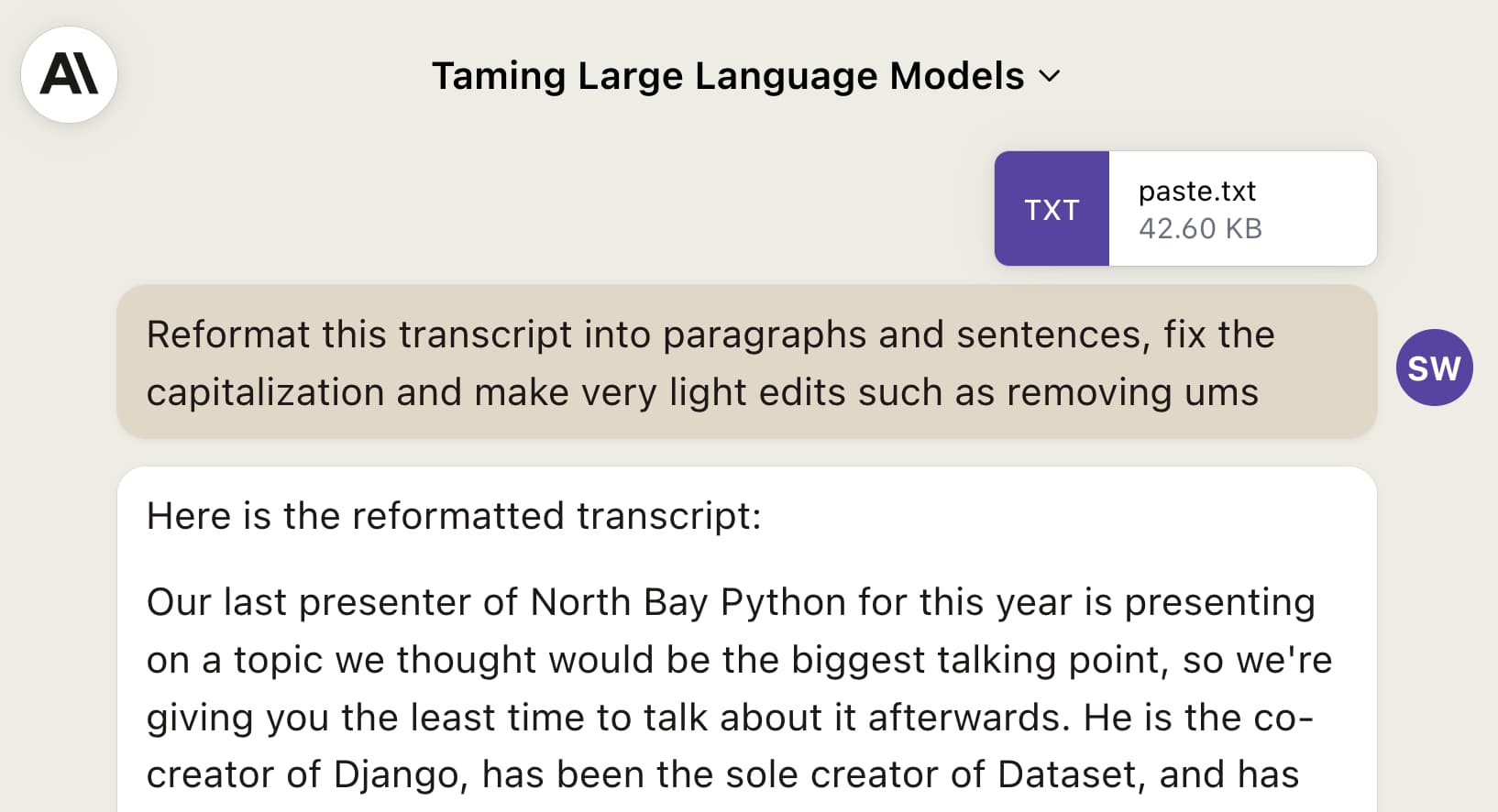
This worked really, really well! Here’s the first paragraph it produced, based on the transcript I show above:
Okay everyone, it’s really exciting to be here. Yeah I call this talk “Catching Up on the Weird World of LLMs.” I’m going to try and give you the last few years of LLMs developments in 35 minutes. This is impossible, so hopefully I’ll at least give you a flavor of some of the weirder corners of the space. The thing about language models is the more I look at them, the more I think they’re practically interesting. Focus on any particular aspect, and there are just more questions, more unknowns, more interesting things to get into.
Note that I said “fractally interesting”, not “practically interesting”—but that error was there in the YouTube transcript, so Claude picked it up from there.
Here’s the full generated transcript.
It’s really impressive! At one point it even turns my dialogue into a set of bullet points:
Today the best are ChatGPT (aka GPT-3.5 Turbo), GPT-4 for capability, and Claude 2 which is free. Google has PaLM 2 and Bard. Llama and Claude are from Anthropic, a splinter of OpenAI focused on ethics. Google and Meta are the other big players.
Some tips:
- OpenAI models cutoff at September 2021 training data. Anything later isn’t in there. This reduces issues like recycling their own text.
- Claude and Palm have more recent data, so I’ll use them for recent events.
- Always consider context length. GPT has 4,000 tokens, GPT-4 has 8,000, Claude 100,000.
- If a friend who read the Wikipedia article could answer my question, I’m confident feeding it in directly. The more obscure, the more likely pure invention.
- Avoid superstitious thinking. Long prompts that “always work” are usually mostly pointless.
- Develop an immunity to hallucinations. Notice signs and check answers.
Compare that to my rambling original to see quite how much of an improvement this is.
But, all of that said... I specified “make very light edits” and it clearly did a whole lot more than just that.
I didn’t use the Claude version directly. Instead, I copied and pasted chunks of it into my annotation tool that made the most sense, then directly edited them to better fit what I was trying to convey.
As with so many things in LLM/AI land: a significant time saver, but no silver bullet.
For workshops, publish the handout
I took the Software Carpentries instructor training a few years ago, which was a really great experience.
A key idea I got from that is that a great way to run a workshop is to prepare an extensive, detailed handout in advance—and then spend the actual workshop time working through that handout yourself, at a sensible pace, in a way that lets the attendees follow along.
A bonus of this approach is that it forces you to put together a really high quality handout which you can distribute after the event.
I used this approach for the 3 hour workshop I ran at PyCon US 2023: Data analysis with SQLite and Python. I turned that into a new official tutorial on the Datasette website, accompanied by the video but also useful for people who don’t want to spend three hours watching me talk!
More people should do this
I’m writing this in the hope that I can inspire more people to give their talks this kind of treatment. It’s not a zero amount of work—it takes me 2-3 hours any time I do this—but it greatly increases the longevity of the talk and ensures that the work I’ve already put into it provides maximum value, both to myself (giving talks is partly a selfish act!) and to the people I want to benefit from it.
Weeknotes: Plugins for LLM, sqlite-utils and Datasette 25 days ago
The principle theme for the past few weeks has been plugins.
Llama 2 in LLM via plugins
I added the ability to support models other than the OpenAI ones to my LLM command-line tool last month. The timing on this could not have been better: Llama 2 (the first commercially usable version of Meta’s LLaMA language model) was released on July 18th, and I was able to add support to prompting it via LLM that very morning thanks to the llm-replicate plugin I had released the day before that launch.
(I had heard a tip that a new exciting LLM was about to be released on Replicate, though I didn’t realize it was Llama 2 until after the announcement.)
A few days ago I took that a step further: the new llm-llama-cpp plugin can now be used to run a GGML quantized version of the Llama 2 model directly on your own hardware.
LLM is available in Homebrew core now, so getting Llama 2 working is as simple as:
brew install llm
llm install llm-llama-cpp llama-cpp-python
llm llama-cpp download-model \
https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGML/resolve/main/llama-2-7b-chat.ggmlv3.q8_0.bin \
--alias llama2-chat --alias l2c --llama2-chatThen:
llm -m l2c 'Tell me a joke about a llama'I wrote more about this in Run Llama 2 on your own Mac using LLM and Homebrew—including instructions for calling Llama 2 using the LLM Python API as well.
Plugins for sqlite-utils
My sqlite-utils project, similar to LLM, is a combined CLI tool and Python library. Based on requests from the community I adding plugin support to it too.
There are two categories of plugins so far: plugins that add extra commands to the sqlite-utils CLI tool, and plugins that add extra custom SQL functions that can be executed against SQLite.
There are quite a few plugins listed in the sqlite-utils plugins directory already.
I built sqlite-utils-shell in time for the initial launch, to help demonstrate the new system by adding a sqlite-utils shell command that opens an interactive shell enabling any SQL functions that have been installed by other plugins.
Alex Garcia suggested I look at litecli by Amjith Ramanujam, which is a much more sophisticated terminal shell for SQLite, incorporating auto-completion against tables and columns.
I used that to build a better alternative to my sqlite-utils-shell plugin: sqlite-utils-litecli, which lets you run the following command to get a full litecli shell with all of the custom SQL functions from other plugins:
sqlite-utils litecli mydatabase.db
datasette-auth-tokens and dclient
Meanwhile, in Datasette land... I’ve been investing more time building Datasette Cloud, the SaaS cloud hosted version of Datasette.
The Datasette 1.0 alphas introduced a write API. I wanted a mechanism for Datasette Cloud users to be able to setup automatic imports of data into their instances, taking advantage of that API.
This meant I needed an API key mechanism that allowed tokens to be both created and revoked interactively.
I ended up building that into the existing datasette-auth-tokens plugin, released in preview in the datasette-auth-tokens 0.4a0 alpha.
I’ve been quietly working on a new CLI utility for interacting with Datasette instances via the API, called dcloud. I shipped dcloud 0.2 with a new dclient insert command that can read CSV, TSV or JSON data and write it to an external Datasette instance using that new 1.0 write API.
I’ll have more news to share about Datasette Cloud soon!
Large Language Model talk at North Bay Python
On Sunday I gave the closing talk at North Bay Python, titled Catching up on the weird world of LLMs.
I tried to summarize the last few years of development in the field of LLMs in just 40 minutes. I’m pretty happy with how it turned out! I’ve since published a full annotated transcript of the talk, with slides, additional links and notes—so even if you don’t want to watch the full talk you can still read through a thorough summary of what I covered.
I’ve given a few of my talks this treatment now and I really like it—it’s a great way to unlock as much value as possible from the time I spend putting one of these things together.
Examples of this format:
- Catching up on the weird world of LLMs—from this Sunday.
- Prompt injection explained, with video, slides, and a transcript for a LangChain webinar in May 2023.
- Coping strategies for the serial project hoarder for DjangoCon US 2022.
- How to build, test and publish an open source Python library for PyGotham in November 2021
- Datasette—an ecosystem of tools for working with small data for PyGotham 2020.
- Personal Data Warehouses: Reclaiming Your Data for the GitHub OCTO speaker series in November 2020.
- Redis tutorial at NoSQL Europe—this was the first time I put together annotated slides like this, for a three hour tutorial on Redis presented at NoSQL Europe back in 2010.
This time round I built a small tool to help me assemble the notes and alt attributes for the video—I hope to write more about that soon.
Blog entries these weeks
- Catching up on the weird world of LLMs
- Run Llama 2 on your own Mac using LLM and Homebrew
- sqlite-utils now supports plugins
- Accessing Llama 2 from the command-line with the llm-replicate plugin
Releases these weeks
-
llm-llama-cpp 0.1a0—2023-08-01
LLM plugin for running models using llama.cpp -
datasette-upload-dbs 0.2—2023-08-01
Upload SQLite database files to Datasette -
sqlite-utils-litecli 0.1.1—2023-07-26
Interactive shell for sqlite-utils using litecli -
llm-gpt4all 0.1.1—2023-07-25
Plugin for LLM adding support for the GPT4All collection of models -
dclient 0.2—2023-07-24
A client CLI utility for Datasette instances -
llm 0.6.1—2023-07-24
Access large language models from the command-line -
asgi-replay 0.1a0—2023-07-24
Record and replay ASGI web page loads -
sqlite-utils-shell 0.2—2023-07-24
Interactive shell for sqlite-utils -
sqlite-utils-dateutil 0.1—2023-07-24
Date utility functions for sqlite-utils -
sqlite-migrate 0.1a1—2023-07-23
A simple database migration system for SQLite, based on sqlite-utils -
sqlite-utils 3.34—2023-07-22
Python CLI utility and library for manipulating SQLite databases -
llm-replicate 0.3—2023-07-20
LLM plugin for models hosted on Replicate -
symbex 1.3—2023-07-19
Find the Python code for specified symbols -
datasette-auth-tokens 0.4a0—2023-07-17
Datasette plugin for authenticating access using API tokens
TIL these weeks
- Checking if something is callable or async callable in Python—2023-08-04
- axe-core and shot-scraper for accessibility audits—2023-07-30
- Exploring the Overture Maps places data using DuckDB, sqlite-utils and Datasette—2023-07-27
- Protocols in Python—2023-07-26
- Using pytest-httpx to run intercepted requests through an in-memory Datasette instance—2023-07-25
Catching up on the weird world of LLMs 27 days ago
I gave a talk on Sunday at North Bay Python where I attempted to summarize the last few years of development in the space of LLMs—Large Language Models, the technology behind tools like ChatGPT, Google Bard and Llama 2.
My goal was to help people who haven’t been completely immersed in this space catch up to what’s been going on. I cover a lot of ground: What they are, what you can use them for, what you can build on them, how they’re trained and some of the many challenges involved in using them safely, effectively and ethically.
- What they are
- How they work
- A brief timeline
- What are the really good ones
- Tips for using them
- Using them for code
- What can we build with them?
- ChatGPT Plugins
- ChatGPT Code Interpreter
- How they’re trained
- Openly licensed models
- My LLM utility
- Prompt injection
The video for the talk is now available, and I’ve put together a comprehensive written version, with annotated slides and extra notes and links.
Update 6th August 2023: I wrote up some notes on my process for assembling annotated presentations like this one.
Read on for the slides, notes and transcript.