When we talk about the digital self, we are talking about the self as it exists within digital spaces. This holds differently for different people, as some of us prefer to live within an pseudonymous or anonymous identity online, divested from our physical selves, while others consider the digital a more holistic identity that extends from the physical.
Your digital self is gestalt, in that it exists across whatever mediums, web sites, and services you use. These bits are pieces together to form a whole picture of what it means to be you, or some aspect of you. This may be carefully curated, or it may be an emergent property of who you are.
The way your physical self has rights, so too does your digital self. Or, perhaps, it would be more accurate to say that your rights extend to your digital self. I do not personally consider that there is a separation between these selves when it comes to rights, as both are aspects of you and you have rights. I am explicitly not going to list what these rights are, because I have my own ideas about them and yours may differ. Instead, I will briefly talk about consent.
I think it is essential that we genuinely consent to how others interact with us to maintain the sanctity of our selves. Consent is necessary to the protection and expression of our rights, as it ensures we are able to rely on our rights and creates a space where we are able to express our rights in comfort and safety. We may classically think of consent as it relates to sex and sexual consent: only we have the right to determine what happens to our bodies; no one else has the right to that determination. We are able to give sexual consent, and we are able to revoke it. Sexual consent, in order to be in good faith, must be requested and given from a place of openness and transparency. For this, we discuss with our partners the things about ourselves that may impact their decision to consent: we are sober; we are not ill; we are using (or not) protection as we agree is appropriate; we are making this decision because it is a thing we desire, rather than a thing we feel we ought to do or are being forced to do; as well as other topics.
These things also all hold true for technology and the digital spaces in which we reside. Our digital autonomy is not the only thing at stake when we look at digital consent. The ways we interact in digital spaces impact our whole selves, and exploitation of our consent too impacts our whole selves. Private information appearing online can have material consequences — it can directly lead to safety issues, like stalking or threats, and it can lead to a loss of psychic safety and have a chilling effect. These are in addition to the threats posed to digital safety and well being. Consent must be actively sought, what one is consenting to is transparent, and the potential consequences must be known and understood.
In order to protect and empower the digital self, to treat everyone justly and with respect, we must hold the digital self be as sacrosanct as other aspects of the self and treat it accordingly.
This article documents how to install FORT Validator (an RPKI relying party software which also implements the RPKI to Router protocol in a single daemon) on Debian 10 to provide RPKI validation to routers. If you are using testing or unstable then you can just skip the part about apt pinnings.
The packages in bullseye (Debian testing) can be installed as is on Debian stable with no need to rebuild them, by configuring an appropriate pinning for apt:
cat <<END > /etc/apt/sources.list.d/bullseye.list
deb http://deb.debian.org/debian/ bullseye main
END
cat <<END > /etc/apt/preferences.d/pin-rpki
# by default do not install anything from bullseye
Package: *
Pin: release bullseye
Pin-Priority: 100
Package: fort-validator rpki-trust-anchors
Pin: release bullseye
Pin-Priority: 990
END
apt update
Before starting, make sure that curl (or wget) and the web PKI certificates are installed:
apt install curl ca-certificates
If you already know about the legal issues related to the ARIN TAL then you may instruct the package to automatically install it. If you skip this step then you will be asked at installation time about it, either way is fine.
This article documents how to install rpki-client (an RPKI relying party software, the actual validator) and gortr (which implements the RPKI to Router protocol) on Debian 10 to provide RPKI validation to routers. If you are using testing or unstable then you can just skip the part about apt pinnings.
The packages in bullseye (Debian testing) can be installed as is on Debian stable with no need to rebuild them, by configuring an appropriate pinning for apt:
cat <<END > /etc/apt/sources.list.d/bullseye.list
deb http://deb.debian.org/debian/ bullseye main
END
cat <<END > /etc/apt/preferences.d/pin-rpki
# by default do not install anything from bullseye
Package: *
Pin: release bullseye
Pin-Priority: 100
Package: gortr rpki-client rpki-trust-anchors
Pin: release bullseye
Pin-Priority: 990
END
apt update
Before starting, make sure that curl (or wget) and the web PKI certificates are installed:
apt install curl ca-certificates
If you already know about the legal issues related to the ARIN TAL then you may instruct the package to automatically install it. If you skip this step then you will be asked at installation time about it, either way is fine.
Exactly one week after the previous release 0.6.26 of digest, a minor cleanup release 0.6.27 just arrived on CRAN and will go to Debian shortly.
digest creates hash digests of arbitrary R objects (using the md5, sha-1, sha-256, sha-512, crc32, xxhash32, xxhash64, murmur32, spookyhash, and blake3 algorithms) permitting easy comparison of R language objects. It is a fairly widely-used package (currently listed at one million monthly downloads, 282 direct reverse dependencies and 8068 indirect reverse dependencies, or just under half of CRAN) as many tasks may involve caching of objects for which it provides convenient general-purpose hash key generation.
Release 0.6.26 brought support for the (nice, even cryptographic) blake3 hash algorithm. In the interest of broader buildability we had already (with a sad face) disabled a few very hardware-specific implementation aspects using intrinsic ops. But to our chagrin, we left one #error define that raised its head on everybody’s favourite CRAN build platform. Darn. So 0.6.27 cleans that up and also removes the check and #error as … all the actual code was already commented out. If you read this and tears start running down your cheeks, then by all means come and help us bring blake3 to its full (hardware-accelerated) potential. This (probably) only needs a little bit of patient work with the build options and configurations. You know where to find us…
For my work on Debian, i want to use my debian.org email address, while for my personal projects i want to use my gmail.com address.
One way to change the user.email git config value is to git config --local in every repo, but that's tedious, error-prone and doesn't scale very well with many repositories (and the chances to forget to set the right one on a new repo are ~100%).
The solution is to use the git-config ability to include extra configuration files, based on the repo path, by using includeIf:
Content of ~/.gitconfig:
[user] name = Sandro Tosi email = <personal.address>@gmail.com
Every time the git path is in ~/deb/ (which is where i have all Debian repos) the file ~/.gitconfig-deb will be included; its content:
[user] email = morph@debian.org
That results in my personal address being used on all repos not part of Debian, where i use my Debian email address. This approach can be extended to every other git configuration values.
The Debian Janitor is an automated
system that commits fixes for (minor) issues in Debian packages that can be
fixed by software. It gradually started proposing merges in early
December. The first set of changes sent out ran lintian-brush on sid packages maintained in
Git. This post is part of a series about the progress of the
Janitor.
The Janitor knows how to talk to different hosting platforms.
For each hosting platform, it needs to support the platform-
specific API for creating and managing merge proposals.
For each hoster it also needs to have credentials.
This provides coverage for the vast majority of Debian packages
that can be accessed using Git. More than 75% of all packages
are available on salsa - although in some cases, the Vcs-Git
header has not yet been updated.
Of the other 25%, the majority either does not declare where
it is hosted using a Vcs-* header (10.5%), or have not
yet migrated from alioth to another hosting platform
(9.7%). A further 2.3% are hosted somewhere on
GitHub (2%),
Launchpad (0.18%) or
GitLab.com (0.15%), in many cases
in the same repository as the upstream code.
The remaining 1.6% are hosted on many other hosts, primarily
people’s personal servers (which usually don’t have an
API for creating pull requests).
Outdated Vcs-* headers
It is possible that the 20% of packages that do not have
a Vcs-* header or have a Vcs header that say there on
alioth are actually hosted elsewhere. However, it is hard
to know where they are until a version with an updated
Vcs-Git header is uploaded.
The Janitor primarily relies on
vcswatch to find the correct
locations of repositories. vcswatch looks at Vcs-* headers
but has its own heuristics as well. For about 2,000 packages
(6%) that still have Vcs-* headers that point to alioth,
vcswatch successfully finds their new home on salsa.
Merge Proposals by Hoster
These proportions are also visible in the number of pull
requests created by the Janitor on various hosters. The
vast majority so far has been created on Salsa.
Hoster
Open
Merged & Applied
Closed
github.com
92
168
5
gitlab.com
12
3
0
code.launchpad.net
24
51
1
salsa.debian.org
1,360
5,657
126
In this graph, “Open” means that the pull request has been
created but likely nobody has looked at it yet. Merged
means that the pull request has been marked as merged on
the hoster, and applied means that the changes have ended
up in the packaging branch but via a different route (e.g. cherry-picked or
manually applied). Closed means that the pull request was closed without the
changes being incorporated.
Note that this excludes ~5,600 direct pushes, all of which were to salsa-hosted repositories.
See also:
Historical graphs on trends.debian.net with number of packages per VCS and per hoster (purely based on Vcs-* headers in the archive, with no heuristics applied)
A good month after the initial two releases, we are thrilled to announce relase 0.0.3 of RcppSpdlog. This brings us release 1.8.1 of spdlog as well as a few local changes (more below).
RcppSpdlog bundles spdlog, a wonderful header-only C++ logging library with all the bells and whistles you would want that was written by Gabi Melman, and also includes fmt by Victor Zverovic.
This version of RcppSpdlog brings a new top-level function setLogLevel to control what events get logged, updates the main example to show this and to also make the R-aware logger the default logger, and adds both an extended vignette showing several key features and a new (external) package documentation site.
The NEWS entry for this release follows.
Changes in RcppSpdlog version 0.0.3 (2020-10-23)
New function setLogLevel with R accessor in exampleRsink example
Updated exampleRsink to use default logger instance
Upgraded to upstream release 1.8.1 which contains finalised upstream use to switch to REprintf() if R compilation detected
Added new vignette with extensive usage examples, added compile-time logging switch example
In July I finished my Bachelor’s Degree in IT Security at the University of
Applied Sciences in St. Poelten. During the studies I did some elective
courses, one of which was about Data Analysis using Python, Pandas and Jupyter
Notebooks. I found it very interesting to do calculations on different data
sets and to visualize them. Towards the end of the Bachelor I had to find a
topic for my Bachelor Thesis and as a long time user of OpenPGP I thought it
would be interesting to do an analysis of the collection of OpenPGP keys that
are available on the keyservers of the SKS keyserver network.
So in June 2019 I fetched a copy of one of the key dumps of the one of the
keyservers (some keyserver publish these copies of their key database so people
who want to join the SKS keyserver network can do an initial import). At that
time the copy of the key database contained 5,499,675 keys and was around 12GB.
Using the hockeypuck keyserver
software I imported the
keys into an PostgreSQL database.
Hockeypuck uses a table called keys to store the keys and in there the column
doc stores the OpenPGP keys in JSON format (always with a data field
containing the original unparsed data).
For the thesis I split the analysis in three parts, first looking at the Public
Key packets, then analysing the User ID packets and finally studying the
Signature Packets. To analyse the respective packets I used SQL to export the
data to CSV files and then used the pandas read_csv
method
to create a dataframe of the values. In a couple of cases I did some parsing
before converting to a DataFrame to make the analysis step faster. The parsing
was done using the pgpdump python
library.
Together with my advisor I decided to submit the thesis for a journal, so we
revised and compressed the whole paper and the outcome was now
in the Journal of
Wireless Mobile Networks, Ubiquitous Computing, and Dependable Applications
(JoWUA).
I think the work gives some valuable insight in the development of the use of
OpenPGP in the last 30 years. Looking at the public key packets we were able to
compare the different public key algorithms and for example visualize how DSA
was the most used algorithm until around 2010 when it was replaced by RSA.
When looking at the less used algorithms a trend towards ECC based crytography is
visible.
What we also noticed was an increase of RSA keys with algorithm ID 3 (RSA Sign-Only),
which are deprecated. When
we took a deeper look at those keys we realized that most of those keys used a
specific User ID string in the User ID packets which allowed us to attribute
those keys to two software projects both using the Bouncy Castle Java
Cryptographic API (resp. the Spongy
Castle version for Android). We also stumbled over a tutorial on how to create
RSA keys with
Bouncycastle
which also describes how to create RSA keys with code that produces RSA
Sign-Only keys. In one of those projects, this was then
fixed.
By looking at the User ID packets we did some statistics about the most used
email providers used by OpenPGP users. One domain stood out, because it is not
the domain of an email provider: tellfinder.com is a domain used in around
45,000 keys. Tellfinder is a
Big Data analysis software and the UID of all but two of those keys is
TellFinder Page Archiver- Signing Key <support@tellfinder.com>.
We also looked at the comments used in OpenPGP User ID fields. In 2013 Daniel
Kahn Gillmor published a blog post titled OpenPGP User ID Comments considered
harmful in which he
pointed out that most of the comments in the User ID field of OpenPGP keys are
duplicating information that is already present somewhere in the User ID or the
key itself. In our dataset 3,133 comments were exactly the same as the name,
3,346 were the same as the domain and 18,246 comments were similar to the local
part of the email address
Analysing this huge dataset of cryptographic keys of the last 20 to 30 years
was very interesting and I learned a lot about the history of PGP resp.
OpenPGP and the evolution of cryptography overall. I think it
would be interesting to look at even more properties of OpenPGP keys and I also
think it would be valuable for the OpenPGP ecosystem if these kinds analysis
could be done regularly. An approach like Tor
Metrics could lead to interesting findings and
could also help to back decisions regarding future developments of the OpenPGP
standard.
This is part of a series of posts on compiling a custom version of Qt5 in order
to develop for both amd64 and a Raspberry Pi.
Building Qt5 takes a long time. The build server I was using had CPUs and RAM,
but was very slow on I/O. I was very frustrated by that, and I started
evaluating alternatives. I ended up setting up scripts to automatically
provision a throwaway cloud server at Hetzner.
Initial setup
I got an API key from my customer's Hetzner account.
I installed hcloud-cli, currently only in testing and unstable:
apt install hcloud-cli
Then I configured hcloud with the API key:
hcloud context create
Spin up
I wrote a quick and dirty script to spin up a new machine, which grew a bit
with little tweaks:
Now everything is ready for a 16 core, 32Gb ram build on SSD storage.
Tear down
When done:
#!/bin/sh
hcloud server delete buildqt
The whole spin up plus provisioning takes around a minute, so I can do it when
I start a work day, and take it down at the end. The build machine wasn't that
expensive to begin with, and this way it will even be billed by the hour.
A first try on a CPX51 machine has just built the full Qt5 Everywhere
Enterprise including QtWebEngine and all its frills, for amd64, in under 1
hour and 40 minutes.
Transparency is essential to trusting a technology. Through transparency we can understand what we’re using and build trust. When we know what is actually going on, what processes are occurring and how it is made, we are able to decide whether interacting with it is something we actually want, and we’re able to trust it and use it with confidence.
This transparency could mean many things, though it most frequently refers to the technology itself: the code or, in the case of hardware, the designs. We could also apply it to the overall architecture of a system. We could think about the decision making, practices, and policies of whomever is designing and/or making the technology. These are all valuable in some of the same ways, including that they allow us to make a conscious choice about what we are supporting.
When we choose to use a piece of technology, we are supporting those who produce it. This could be because we are directly paying for it, however our support is not limited to direct financial contributions. In some cases this is because of things hidden within a technology: tracking mechanisms or backdoors that could allow companies or governments access to what we’re doing. When creating different types of files on a computer, these files can contain metadata that says what software was used to make it. This is an implicit endorsement, and you can also explicitly endorse a technology by talking about that or how you use it. In this, you have a right (not just a duty) to be aware of what you’re supporting. This includes, for example, organizational practices and whether a given company relies on abusive labor policies, indentured servitude, or slave labor.
Endorsements inspire others to choose a piece of technology. Most of my technology is something I investigate purely for functionality, and the pieces I investigate are based on what people I know use. The people I trust in these cases are more inclined than most to do this kind of research, to perform technical interrogations, and to be aware of what producers of technology are up to.
This is how technology spreads and becomes common or the standard choice. In one sense, we all have the responsibility (one I am shirking) to investigate our technologies before we choose them. However, we must acknowledge that not everyone has the resources for this – the time, the skills, the knowledge, and therein endorsements become even more important to recognize.
Those producing a technology have the responsibility of making all of these angles something one could investigate. Understanding cannot only be the realm of experts. It should not require an extensive background in research and investigative journalism to find out whether a company punishes employees who try to unionize or pay non-living wages. Instead, these must be easy activities to carry out. It should be standard for a company (or other technology producer) to be open and share with people using their technology what makes them function. It should be considered shameful and shady to not do so. Not only does this empower those making choices about what technologies to use, but it empowers others down the line, who rely on those choices. It also respects the people involved in the processes of making these technologies. By acknowledging their role in bringing our tools to life, we are respecting their labor. By holding companies accountable for their practices and policies, we are respecting their lives.
It's been way over two years since we started to use Google Compute Engine (GCE) for Salsa.
Since then, all the jobs running on the shared runners run within a n1-standard-1 instance,
providing a fresh set of one vCPU and 3.75GB of RAM for each and every build.
GCE supports several new instance types, featuring better and faster CPUs, including current AMD EPICs.
However, as it turns out, GCE does not support any single vCPU instances for any of those types.
So jobs in the future will use n2d-standard-2 for the time being,
provinding two vCPUs and 8GB of RAM..
Builds run with IPv6 enabled
All builds run with IPv6 enabled in the Docker environment.
This means the lo network device got the IPv6 loopback address ::1 assigned.
So tests that need minimal IPv6 support can succeed.
It however does not include any external IPv6 connectivity.
Often, one would want to generate smooth data from a fit over a small number of data points. For an example, take the data in the following file. It contains (fake) experimental data points that obey to Michaelis-Menten kinetics:
$$v = \frac{v_m}{1 + K_m/s}$$
in which \(v\) is the measured rate (the y values of the data), \(s\) the concentration of substrate (the x values of the data), \(v_m\) the maximal rate and \(K_m\) the Michaelis constant. To fit this equation to the data, just use the fit-arb fit:
QSoas> l michaelis.dat
QSoas> fit-arb vm/(1+km/x)
After running the fit, the window should look like this:
Now, with the fit, we have reasonable values for \(v_m\) (vm) and \(K_m\) (km). But, for publication, one would want to generate "smooth" curve going through the lines... Saving the curve from "Data.../Save all" doesn't help, since the data has as many points as the original data and looks very "jaggy" (like on the screenshot above)... So one needs a curve with more data points.
Maybe the most natural solution is simply to use generate-buffer together with apply-formula using the formula and the values of km and vm obtained from the fit, like:
By default, generate-buffer generate 1000 evenly spaced x values, but you can change their number using the /samples option. The two above commands can be combined to just one call to generate-buffer:
QSoas> generate-buffer 0 20 3.51742/(1+3.69767/x)
This works, but it is quite cumbersome and it is not going to work well for complex formulas or the results of differential equations or kinetic systems...
This is why to each fit- command corresponds a sim- command that computes the result of the fit using a "saved parameters" file (here, michaelis.params, but you can also save it yourself) and buffers as "models" for X values:
This strategy works with every single fit ! As an added benefit, you even get the fit parameters as meta-data, which are displayed by the show command:
QSoas> show 0
Dataset generated_fit_arb.dat: 2 cols, 1000 rows, 1 segments, #0
Flags:
Meta-data: commands = sim-arb vm/(1+km/x) michaelis.params 0 fit = arb (formula: vm/(1+km/x)) km = 3.69767
vm = 3.5174
They also get saved as comments if you save the data.
Important note: the sim-arb command will be available only in the 3.0 release, although you can already enjoy it if you use the github version.
About QSoas
QSoas is a powerful open source data analysis program that focuses on flexibility and powerful fitting capacities. It is released under the GNU General Public License. It is described in Fourmond, Anal. Chem., 2016, 88 (10), pp 5050–5052. Current version is 2.2. You can download its source code and compile it yourself or buy precompiled versions for MacOS and Windows there.
plocate hit testing today,
so it's officially on its way to bullseye :-) I'd love to add a backport
to stable, but bpo policy says only to backport packages with a “notable
userbase”, and I guess 19 installations in popcon
isn't that :-) It's also hit Arch Linux, obviously Ubuntu universe,
and seemingly also other distributions like Manjaro.
No Fedora yet, but hopefully, some Fedora maintainer will pick it up. :-)
Also, pabs pointed out another possible use case, although this is just
a proof-of-concept:
pannekake:~/dev/plocate/obj> time apt-file search bin/updatedb
locate: /usr/bin/updatedb.findutils
mlocate: /usr/bin/updatedb.mlocate
roundcube-core: /usr/share/roundcube/bin/updatedb.sh
apt-file search bin/updatedb 1,19s user 0,58s system 163% cpu 1,083 total
pannekake:~/dev/plocate/obj> time ./plocate -d apt-file.plocate.db bin/updatedb
locate: /usr/bin/updatedb.findutils
mlocate: /usr/bin/updatedb.mlocate
roundcube-core: /usr/share/roundcube/bin/updatedb.sh
./plocate -d apt-file.plocate.db bin/updatedb 0,00s user 0,01s system 79% cpu 0,012 total
Things will probably be quieting down now; there's just not that many more
logical features to add.
I currently need to dabble with R for a smallish
thing. I have previously dabbled with R only once, for an afternoon, and that
was about a decade ago, so I had no prior experience to speak of regarding the
language and its surrounding ecosystem.
Somebody recommended that I try out RStudio, a popular
IDE for R. I was happy to see that an open-source community edition exists,
in the form of a .deb package no less, so I installed it and gave it a try.
It's remarkable how intuitive this IDE is. My first guess at doing something
has so far been correct every. single. time. I didn't have to open the help,
or search the web, for any solutions, either -- they just seem to offer
themselves up.
And it's not just my inputs; it's the output, too. The RStudio window has
multiple tiles, and each tile has multiple tabs. I found this quite confusing
and intimidating on first impression, but once I started doing some work, I was
surprised to see that whenever I did something that produced output in one or
more of the tabs, it was (again) always in an intuitive manner. There's a fine
line between informing with relevant context and distracting with irrelevant
context, but RStudio seems to have placed itself on the right side of it.
This, and many other features that pop up here and there, like the
live-rendering of LaTeX equations, contributed to what has to be one of the
most positive experiences with an IDE that I've had so far.
A new release, now at version 0.1.6, of RcppZiggurat is now on the CRAN network for R.
The RcppZiggurat package updates the code for the Ziggurat generator by Marsaglia and other which provides very fast draws from a Normal distribution. The package provides a simple C++ wrapper class for the generator improving on the very basic macros, and permits comparison among several existing Ziggurat implementations. This can be seen in the figure where Ziggurat from this package dominates accessing the implementations from the GSL, QuantLib and Gretl—all of which are still way faster than the default Normal generator in R (which is of course of higher code complexity).
This release brings a corrected seed setter and getter which now correctly take care of all four state variables, and not just one. It also corrects a few typos in the vignette. Both were fixed quite a while back, but we somehow managed to not ship this to CRAN for two years.
The NEWS file entry below lists all changes.
Changes in version 0.1.6 (2020-10-18)
Several typos were corrected in the vignette (Blagoje Ivanovic in #9).
New getters and setters for internal state were added to resume simulations (Dirk in #11 fixing #10).
Minor updates to cleanup script and Travis CI setup (Dirk).
This year's iteration of the Debian annual conference,
DebConf20, had to be held online,
and while being a resounding success, it made clear to the project our need
to have a permanent live streaming infrastructure for small events held by local Debian groups.
As such, Peertube, a FLOSS video hosting platform,
seems to be the perfect solution for us.
We hope this unconventional gesture from the Debian project will help us make
this year somewhat less terrible and give us, and thus humanity, better Free Software tooling
to approach the future.
Debian thanks the commitment of numerous Debian donors and DebConf sponsors,
particularly all those that contributed to DebConf20 online's success
(volunteers, speakers and sponsors).
Our project also thanks Framasoft and the PeerTube community for developing
PeerTube as a free and decentralized video platform.
The Framasoft association warmly thanks the Debian Project for
its contribution, from its own funds, towards making PeerTube happen.
This contribution has a twofold impact. Firstly, it's a strong sign of
recognition from an international project - one of the pillars of the Free
Software world - towards a small French association which offers tools to
liberate users from the clutches of the web's giant monopolies.
Secondly, it's a substantial amount of help in these difficult times,
supporting the development of a tool which equally belongs to and is useful to everyone.
The strength of Debian's gesture proves, once again, that
solidarity, mutual aid and collaboration are values which allow our communities
to create tools to help us strive towards Utopia.
The Reproducible Builds project depends on our many projects, supporters
and sponsors. We rely on their financial
support, but they are also valued ambassadors who spread the word about the
Reproducible Builds project and the work that we do.
This is the first installment in a series featuring the projects, companies and
individuals who support the Reproducible Builds project. If you are a supporter
of the Reproducible Builds project (of whatever size) and would like to be
featured here, please let get in touch with us at
contact@reproducible-builds.org.
Chris Lamb: Hi Urs and Yoshi, great to meet you. How might you relate the
importance of the Civil Infrastructure Platform to a user who is
non-technical?
A: The Civil Infrastructure Platform (CIP)
project is focused on establishing an open source ‘base layer’ of
industrial-grade software that acts as building blocks in civil infrastructure
projects. End-users of this critical code include systems for electric power
generation and energy distribution, oil and gas, water and wastewater,
healthcare, communications, transportation, and community management. These
systems deliver essential services, provide shelter, and support social
interactions and economic development. They are society’s lifelines, and CIP
aims to contribute to and support these important pillars of modern society.
Chris: We have entered an age where our civilisations have become reliant on
technology to keep us alive. Does the CIP believe that the software that
underlies our own safety (and the safety of our loved ones) receives enough
scrutiny today?
A: For companies developing systems running our infrastructure and keeping our
factories working, it is part of their business to ensure the availability,
uptime, and security of these very systems. However, software complexity
continues to increase, and the efforts spent on those systems is now exploding.
What is missing is a common way of achieving this through refining the same
tools, and cooperating on the hardening and maintenance of standard components
such as the Linux operating system.
Chris: How does the Reproducible Builds effort help the Civil Infrastructure
Platform achieve its goals?
A: Reproducibility helps a great deal in software maintenance. We have a number
of use-cases that should have long-term support of more than 10 years. During
this period, we encounter issues that need to be fixed in the original source
code. But before we make changes to the source code, we need to check whether it
is actually the original source code or not. If we can reproduce exactly the
same binary from the source code even after 10 years, we can start to invest
time and energy into making these fixes.
Chris: Can you give us a brief history of the Civil Infrastructure Platform?
Are there any specific ‘success stories’ that the CIP is particularly proud
of?
A: The CIP Project formed in 2016 as a project hosted by Linux Foundation. It
was launched out of necessity to establish an open source framework and
the subsequent software foundation delivers services for civil infrastructure
and economic development on a global scale. Some key milestones we have
achieved as a project include our collaboration with
Debian, where we are helping with the Debian Long Term
Support (LTS) initiative, which aims to extend
the lifetime of all Debian stable releases to at least 5 years. This is
critical because most control systems for transportation, power plants,
healthcare and telecommunications run on Debian-based embedded systems.
In addition, CIP is focused on IEC 62443,
a standards-based approach to counter security vulnerabilities in industrial
automation and control systems. Our belief is that this work will help mitigate
the risk of cyber attacks, but in order to deal with evolving attacks of this
kind, all of the layers that make up these complex systems (such as system
services and component functions, in addition to the countless operational
layers) must be kept secure. For this reason, the IEC 62443 series is
attracting attention as the de facto cyber-security standard.
Chris: The Civil Infrastructure Platform project comprises a number of
project members from different industries, with stakeholders across multiple
countries and continents. How does working together with a broad group of
interests help in your effectiveness and efficiency?
A: Although the members have different products, they share the requirements
and issues when developing sustainable products. In the end, we are driven by
common goals. For the project members, working internationally is simply daily
business. We see this as an advantage over regional or efforts that focus on
narrower domains or markets.
Chris: The Civil Infrastructure Platform supports a number of other existing
projects and initiatives in the open source world too. How much do you feel
being a part of the broader free software community helps you achieve your
aims?
A: Collaboration with other projects is an essential part of how CIP operates —
we want to enable commonly-used software components. It would not make sense to
re-invent solutions that are already established and widely used in product
development. To this end, we have an ‘upstream first’ policy which means that,
if existing projects need to be modified to our needs or are already working on
issues that we also need, we work directly with them.
Chris: Open source software in desktop or user-facing contexts receives a
significant amount of publicity in the media. However, how do you see the
future of free software from an industrial-oriented context?
A: Open source software has already become an essential part of the industry
and civil infrastructure, and the importance of open source software there is
still increasing. Without open source software, we cannot achieve, run and
maintain future complex systems, such as smart cities and other key pieces of
civil infrastructure.
Chris: If someone wanted to know more about the Civil Infrastructure Platform
(or even to get involved) where should they go to look?
For more about the Reproducible Builds project, please see our website at
reproducible-builds.org. If you are interested in
ensuring the ongoing security of the software that underpins our civilisation
and wish to sponsor the Reproducible Builds project, please reach out to the
project by emailing
contact@reproducible-builds.org.
Armadillo is a powerful and expressive C++ template library for linear algebra aiming towards a good balance between speed and ease of use with a syntax deliberately close to a Matlab. RcppArmadillo integrates this library with the R environment and language–and is widely used by (currently) 786 other packages on CRAN.
A little while ago, Conrad released version 10.1.0 of Armadillo, a a new major release. As before, given his initial heads-up we ran two full reverse-depends checks, and as a consequence contacted four packages authors (two by email, two via PR) about a miniscule required change (as Armadillo now defaults to C++11, an old existing setting of avoiding C++11 lead to an error). Our thanks to those who promptly update their packages—truly appreciated. As it turns out, Conrad also softened the error by the time the release ran around.
But despite our best efforts, the release was delayed considerably by CRAN. We had made several Windows test builds but luck had it that on the uploaded package CRAN got itself a (completely spurious segfault—which can happen on a busy machine building machine things at once). Sadly it took three or four days for CRAN to reply our email. After which it took another number of days for them to ponder the behaviour of a few new ‘deprecated’ messaged tickled by at the most ten or so (out of 786) packages. Oh well. So here we are, eleven days after I emailed the rcpp-devel list about the new package being on CRAN but possibly delayed (due to that seg.fault). But during all that time the package was of course available via the Rcpp drat.
Changes in RcppArmadillo version 0.10.1.0.0 (2020-10-09)
Upgraded to Armadillo release 10.1.0 (Orchid Ambush)
C++11 is now the minimum required C++ standard
faster handling of compound expressions by trimatu() and trimatl()
faster sparse matrix addition, subtraction and element-wise multiplication
expanded sparse submatrix views to handle the non-contiguous form of X.cols(vector_of_column_indices)
expanded eigs_sym() and eigs_gen() with optional fine-grained parameters (subspace dimension, number of iterations, eigenvalues closest to specified value)
deprecated form of reshape() removed from Cube and SpMat classes
ignore and warn on use of the ARMA_DONT_USE_CXX11 macro
I am happy to report that we finally made it! Norwegian Bokmål
became the first translation published on paper of the new Buster
based edition of "The Debian
Administrator's Handbook". The print proof reading copy arrived
some days ago, and it looked good, so now the book is approved for
general distribution. This updated paperback edition is available from
lulu.com. The book is also available for download in electronic
form as PDF, EPUB and Mobipocket, and can also be
read online.
I am very happy to wrap up this Creative Common licensed project,
which concludes several months of work by several volunteers. The
number of Linux related books published in Norwegian are few, and I
really hope this one will gain many readers, as it is packed with deep
knowledge on Linux and the Debian ecosystem. The book will be
available for various Internet book stores like Amazon and Barnes &
Noble soon, but I recommend buying
"Håndbok
for Debian-administratoren" directly from the source at Lulu.
As usual, if you use Bitcoin and want to show your support of my
activities, please send Bitcoin donations to my address
15oWEoG9dUPovwmUL9KWAnYRtNJEkP1u1b.
For the past few years I've had a bunch of virtual machines hosting websites, services, and servers. Of course I want them to be available - especially since I charge people money to access at some of them (for example my dns-hosting service) - and that means I want to know when they're not.
The way I've gone about this is to have a bunch of machines running stuff, and then dedicate an entirely separate machine solely for monitoring and alerting. Sure you can run local monitoring, testing that services are available, the root-disk isn't full, and that kind of thing. But only by testing externally can you see if the machine is actually available to end-users, customers, or friends.
A local-agent might decide "I'm fine", but if the hosting-company goes dark due to a fibre cut you're screwed.
I've been hosting my services with Hetzner (cloud) recently, and their service is generally pretty good. Unfortunately I've started to see an increasing number of false-alarms. I'd have a server in Germany, with the monitoring machine in Helsinki (coincidentally where I live!). For the past month I've started to get pinged with a failure every three/four days on average, "service down - dns failed", or "service down - timeout". When the notice would wake me up I'd go check and it would be fine, it was a very transient failure.
To be honest the reason for this is my monitoring is just too damn aggressive, I like to be alerted immediately in case something is wrong. That means if a single test fails I get an alert, as rather than only if a test failed for something more reasonable like three+ consecutive failures.
I'm experimenting with monitoring in a less aggressive fashion, from my home desktop. Since my monitoring tool is a single self-contained golang binary, and it is already packaged as a docker-based container deployment was trivial. I did a little work writing an agent to receive failure-notices, and ping me via telegram - instead of the previous approach where I had an online status-page which I could view via my mobile, and alerts via pushover.
So far it looks good. I've tweaked the monitoring to setup a timeout of 15 seconds, instead of 5, and I've configured it to only alert me if there is an outage which lasts for >= 2 consecutive failures. I guess the TLDR is I now do offsite monitoring .. from my house, rather than from a different region.
The only real reason to write this post was mostly to say that the process of writing a trivial "notify me" gateway to interface with telegram was nice and straightforward, and to remind myself that transient failures are way more common than we expect.
I'll leave things alone for a moment, but it was a fun experiment. I'll keep the two systems in parallel for a while, but I guess I can already predict the outcome:
The desktop monitoring will report transient outages now and again, because home broadband isn't 100% available.
The heztner-based monitoring, in a different region, will report transient problems, because even hosting companies are not 100% available.
Especially at the cheap prices I'm paying.
The way to avoid being woken up by transient outages/errors is to be less agressive.
I think my paying users will be OK if I find out a services is offline after 5 minutes, rather than after 30 seconds.
If they're not we'll have to talk about budgets ..
The diffoscope maintainers are pleased to announce the release of diffoscope
version 161. This version includes the following changes:
[ Chris Lamb ]
* Fix failing testsuite: (Closes: #972518)
- Update testsuite to support OCaml 4.11.1. (Closes: #972518)
- Reapply Black and bump minimum version to 20.8b1.
* Move the OCaml tests to the assert_diff helper.
[ Jean-Romain Garnier ]
* Add support for radare2 as a disassembler.
[ Paul Spooren ]
* Automatically deploy Docker images in the continuous integration pipeline.
After some fiddling, it turns out I was right and you can
authenticate with a Yubikey over SSH. Here's that procedure so you
don't have to second-guess it yourself.
Installation
On Debian, the PAM module is shipped in the google-authenticator
source package:
apt install libpam-google-authenticator
Then you need to add the module in your PAM stack somewhere. Since I
only use it for SSH, I added this line on top of /etc/pam.d/sshd:
auth required pam_google_authenticator.so nullok
I also used no_increment_hotp debug while debugging to avoid having
to renew the token all the time and have more information about
failures in the logs.
Then reload ssh (not sure that's actually necessary):
service ssh reload
Creating or replacing tokens
To create a new key, run this command on the server:
google-authenticator -c
This will prompt you for a bunch of questions. To get them all right,
I prefer to just call the right ones on the commandline directly:
Those are actually the defaults, if my memory serves me right, except
for the --qr-mode and --emergency-codes (which can't be disabled
so I only print one). I disable the QR code display because I won't be
using the codes on my phone, but you would obviously keep it if you
want to use the app.
Converting to a Yubikey-compatible secret
Unfortunately, the encoding (base32) produced by the
google-authenticator command is not compatible with the token
expected by the ykpersonalize command used to configure the Yubikey
(base16 AKA "hexadecimal", with a fixed 20 bytes length). So you
need a way to convert between the two. I wrote a program called
oath-convert which basically does this:
read base32
add padding
convert to hex
print
Or, in Python:
defconvert_b32_b16(data_b32):
remainder =len(data_b32) %8if remainder >0:# XXX: assume 6 chars are missing, the actual padding may vary:# https://tools.ietf.org/html/rfc3548#section-5
data_b32 +="======"
data_b16 = base64.b32decode(data_b32)iflen(data_b16) <20:# pad to 20 bytes
data_b16 += b"\x00"* (20-len(data_b16))return binascii.hexlify(data_b16).decode("ascii")
Note that the code assumes a certain token length and will not work
correctly for other sizes. To use the program, simply call it with:
head -1 .google_authenticator | oath-convert
Then you paste the output in the prompt:
$ ykpersonalize -1 -o oath-hotp -o append-cr -a
Firmware version 3.4.3 Touch level 1541 Program sequence 2
HMAC key, 20 bytes (40 characters hex) : [SECRET GOES HERE]
Configuration data to be written to key configuration 1:
fixed: m:
uid: n/a
key: h:[SECRET REDACTED]
acc_code: h:000000000000
OATH IMF: h:0
ticket_flags: APPEND_CR|OATH_HOTP
config_flags:
extended_flags:
Commit? (y/n) [n]: y
Note that you must NOT pass the -o oath-hotp8 parameter to the
ykpersonalize commandline, which we used to do in the Yubikey
howto. That is because Google Authenticator
tokens are shorter: it's less secure, but it's an acceptable tradeoff
considering the plugin is actually maintained. There's actually a
feature request to support 8-digit codes so that limitation might
eventually be fixed as well.
I’ve had a saga of getting 4K monitors to work well. My latest issue has been video playing, the dreaded mplayer error about the system being too slow. My previous post about 4K was about using DisplayPort to get more than 30Hz scan rate at 4K [1]. I now have a nice 60Hz scan rate which makes WW2 documentaries display nicely among other things.
But when running a 4K monitor on a 3.3GHz i5-2500 quad-core CPU I can’t get a FullHD video to display properly. Part of the process of decoding the video and scaling it to 4K resolution is too slow, so action scenes in movies lag. When running a 2560*1440 monitor on a 2.4GHz E5-2440 hex-core CPU with the mplayer option “-lavdopts threads=3” everything is great (but it fails if mplayer is run with no parameters). In doing tests with apparent performance it seemed that the E5-2440 CPU gains more from the threaded mplayer code than the i5-2500, maybe the E5-2440 is more designed for server use (it’s in a Dell PowerEdge T320 while the i5-2500 is in a random white-box system) or maybe it’s just because it’s newer. I haven’t tested whether the i5-2500 system could perform adequately at 2560*1440 resolution.
The E5-2440 system has an ATI HD 6570 video card which is old, slow, and only does PCIe 2.1 which gives 5GT/s or 8GB/s. The i5-2500 system has a newer ATI video card that is capable of PCIe 3.0, but “lspci -vv” as root says “LnkCap: Port #0, Speed 8GT/s, Width x16” and “LnkSta: Speed 5GT/s (downgraded), Width x16 (ok)”. So for reasons unknown to me the system with a faster PCIe 3.0 video card is being downgraded to PCIe 2.1 speed. A quick check of the web site for my local computer store shows that all ATI video cards costing less than $300 have PCI3 3.0 interfaces and the sole ATI card with PCIe 4.0 (which gives double the PCIe speed if the motherboard supports it) costs almost $500. I’m not inclined to spend $500 on a new video card and then a greater amount of money on a motherboard supporting PCIe 4.0 and CPU and RAM to go in it.
According to my calculations 3840*2160 resolution at 24bpp (probably 32bpp data transfers) at 30 frames/sec means 3840*2160*4*30/1024/1024=950MB/s. PCIe 2.1 can do 8GB/s so that probably isn’t a significant problem.
I’d been planning on buying a new video card for the E5-2440 system, but due to some combination of having a better CPU and lower screen resolution it is working well for video playing so I can save my money.
As an aside the T320 is a server class system that had been running for years in a corporate DC. When I replaced the high speed SAS disks with SSDs SATA disks it became quiet enough for a home workstation. It works very well at that task but the BIOS is quite determined to keep the motherboard video running due to the remote console support. So swapping monitors around was more pain than I felt like going through, I just got it working and left it. I ordered a special GPU power cable but found that the older video card that doesn’t need an extra power cable performs adequately before the cable arrived.
Here is a table comparing the systems.
2560*1440 works well
3840*2160 goes slow
System
Dell PowerEdge T320
White Box PC from rubbish
CPU
2.4GHz E5-2440
3.3GHz i5-2500
Video Card
ATI Radeon HD 6570
ATI Radeon R7 260X
PCIe Speed
PCIe 2.1 – 8GB/s
PCIe 3.0 downgraded to PCIe 2.1 – 8GB/s
Conclusion
The ATI Radeon HD 6570 video card is one that I had previously tested and found inadequate for 4K support, I can’t remember if it didn’t work at that resolution or didn’t support more than 30Hz scan rate. If the 2560*1440 monitor dies then it wouldn’t make sense to buy anything less than a 4K monitor to replace it which means that I’d need to get a new video card to match. But for the moment 2560*1440 is working well enough so I won’t upgrade it any time soon. I’ve already got the special power cable (specified as being for a Dell PowerEdge R610 for anyone else who wants to buy one) so it will be easy to install a powerful video card in a hurry.
Although I still read a lot, during my college sophomore years my reading
habits shifted from novels to more academic works. Indeed, reading dry
textbooks and economic papers for classes often kept me from reading anything
else substantial. Nowadays, I tend to binge read novels: I won't touch a book
for months on end, and suddenly, I'll read 10 novels back to back1.
At the start of a novel binge, I always follow the same ritual: I take out my
e-reader from its storage box, marvel at the fact the battery is still pretty
full, turn on the WiFi and check if there are OS updates. And I have to admit,
Kobo Inc. (now Rakuten Kobo) has done a stellar job of keeping my e-reader up
to date. I've owned this model (a Kobo Aura 1st generation) for 7
years now and I'm still running the latest version of Kobo's Linux-based OS.
Having recently had trouble updating my Nexus 5 (also manufactured 7 years ago)
to Android 102, I asked myself:
Why is my e-reader still getting regular OS updates, while Google stopped
issuing security patches for my smartphone four years ago?
To try to answer this, let us turn to economic incentives
theory.
Although not the be-all and end-all some think it is3, incentives
theory is not a bad tool to analyse this particular problem. Executives at
Google most likely followed a very business-centric logic when they decided to
drop support for the Nexus 5. Likewise, Rakuten Kobo's decision to continue
updating older devices certainly had very little to do with ethics or loyalty
to their user base.
So, what are the incentives that keep Kobo updating devices and why are they
different than smartphone manufacturers'?
A portrait of the current long-term software support offerings for smartphones and e-readers
Before delving deeper in economic theory, let's talk data. I'll be focusing on
2 brands of e-readers, Amazon's Kindle and Rakuten's Kobo. Although the
e-reader market is highly segmented and differs a lot based on geography,
Amazon was in 2015 the clear worldwide leader with 53% of the worldwide
e-reader sales, followed by Rakuten Kobo at 13%4.
On the smartphone side, I'll be differentiating between Apple's iPhones and
Android devices, taking Google as the barometer for that ecosystem. As mentioned
below, Google is sadly the leader in long-term Android software support.
Rakuten Kobo
According to their website and to this Wikipedia
table, the only e-readers Kobo has deprecated are the original
Kobo eReader and the Kobo WiFi N289, both released in 2010. This makes their
oldest still supported device the Kobo Touch, released in 2011. In my book,
that's a pretty good track record. Long-term software support does not seem to
be advertised or to be a clear selling point in their marketing.
Amazon
According to their website, Amazon has dropped support for
all 8 devices produced before the Kindle Paperwhite 2nd generation,
first sold in 2013. To put things in perspective, the first Kindle came out in
2007, 3 years before Kobo started selling devices. Like Rakuten Kobo, Amazon
does not make promises of long-term software support as part of their
marketing.
Owners of iPhone, iPad, iPod or Mac products may obtain a service and parts
from Apple or Apple service providers for five years after the product is no
longer sold – or longer, where required by law.
This means in the worst-case scenario of buying an iPhone model just as it is
discontinued, one would get a minimum of 5 years of software support.
Android
Google's policy for their Android devices is to provide software support for 3
years after the launch date. If you buy a Pixel device just
before the new one launches, you could theoretically only get 2 years of
support. In 2018, Google decided OEMs would have to provide security updates
for at least 2 years after launch, threatening not to license
Google Apps and the Play Store if they didn't comply.
A question of cost structure
From the previous section, we can conclude that in general, e-readers seem to
be supported longer than smartphones, and that Apple does a better job than
Android OEMs, providing support for about twice as long.
Even Fairphone, who's entire business is to build phones designed to last and
to be repaired was not able to keep the Fairphone 1 (2013) updated for more
than a couple years and seems to be struggling to keep the
Fairphone 2 (2015) running an up to date version of Android.
Anyone who has ever worked in IT will tell you: maintaining software over time
is hard work and hard work by specialised workers is expensive. Most commercial
electronic devices are sold and developed by for-profit enterprises and
software support all comes down to a question of cost structure. If companies
like Google or Fairphone are to be expected to provide long-term support for
the devices they manufacture, they have to be able to fund their work somehow.
In a perfect world, people would be paying for the cost of said long-term
support, as it would likely be cheaper then buying new devices every few years
and would certainly be better for the planet. Problem is, manufacturers aren't
making them pay for it.
Economists call this type of problem externalities: things that should be
part of the cost of a good, but aren't for one a reason or another. A classic
example of an externality is pollution. Clearly pollution is bad and leads to
horrendous consequences, like climate change. Sane people agree we should
drastically cut our greenhouse gas emissions, and yet, we aren't.
Neo-classical economic theory argues the way to fix externalities like
pollution is to internalise these costs, in other words, to make people pay
for the "real price" of the goods they buy. In the case of climate change and
pollution, neo-classical economic theory is plain wrong (spoiler alert: it
often is), but this is where band-aids like the carbon tax comes from.
Still, coming back to long-term software support, let's see what would happen
if we were to try to internalise software maintenance costs. We can do this
multiple ways.
1 - Include the price of software maintenance in the cost of the device
This is the choice Fairphone makes. This might somewhat work out for them since
they are a very small company, but it cannot scale for the following reasons:
This strategy relies on you giving your money to an enterprise now,
and trusting them to "Do the right thing" years later. As the years
go by, they will eventually look at their books, see how much ongoing
maintenance is costing them, drop support for the device, apologise and move
on. That is to say, enterprises have a clear economic incentive to promise
long-term support and not deliver. One could argue a company's reputation
would suffer from this kind of behaviour. Maybe sometime it does, but most
often people forget. Political promises are a great example of this.
Enterprises go bankrupt all the time. Even if company X promises 15 years of
software support for their devices, if they cease to exist, your device will
stop getting updates. The internet is full of stories of IoT devices getting
bricked when the parent company goes bankrupt and their servers disappear.
This is related to point number 1: to some degree, you have a disincentive
to pay for long-term support in advance, as the future is uncertain and
there are chances you won't get the support you paid for.
Selling your devices at a higher price to cover maintenance costs does not
necessarily mean you will make more money overall — raising more money to
fund maintenance costs being the goal here. To a certain point, smartphone
models are substitute goods and prices higher than market prices will
tend to drive consumers to buy cheaper ones. There is thus a disincentive to
include the price of software maintenance in the cost of the device.
People tend to be bad at rationalising the total cost of ownership over a
long period of time. Economists call this phenomenon
hyperbolic discounting. In our case, it means people are far more likely
to buy a 500$ phone each 3 years than a 1000$ phone each 10 years. Again,
this means OEMs have a clear disincentive to include the price of long-term
software maintenance in their devices.
Clearly, life is more complex than how I portrayed it: enterprises are not
perfect rational agents, altruism exists, not all enterprises aim solely for
profit maximisation, etc. Still, in a capitalist economy, enterprises wanting
to charge for software maintenance upfront have to overcome these hurdles one
way or another if they want to avoid failing.
2 - The subscription model
Another way companies can try to internalise support costs is to rely on a
subscription-based revenue model. This has multiple advantages over the previous
option, mainly:
It does not affect the initial purchase price of the device, making it easier
to sell them at a competitive price.
It provides a stable source of income, something that is very valuable to
enterprises, as it reduces overall risks. This in return creates an incentive
to continue providing software support as long as people are paying.
If this model is so interesting from an economic incentives point of view, why
isn't any smartphone manufacturer offering that kind of program? The answer is,
they are, but not explicitly5.
Apple and Google can fund part of their smartphone software support via the 30%
cut they take out of their respective app stores. A report from Sensor
Tower shows that in 2019, Apple made an estimated US$ 16 billion
from the App Store, while Google raked in US$ 9 billion from the Google Play
Store. Although the Fortune 500 ranking tells us this respectively
is "only" 5.6% and 6.5% of their gross annual revenue for 2019, the profit
margins in this category are certainly higher than any of their other products.
This means Google and Apple have an important incentive to keep your device
updated for some time: if your device works well and is updated, you are more
likely to keep buying apps from their store. When software support for a device
stops, there is a risk paying customers will buy a competitor device and leave
their ecosystem.
This also explains why OEMs who don't own app stores tend not to provide
software support for very long periods of time. Most of them only make money
when you buy a new phone. Providing long-term software support thus becomes a
disincentive, as it directly reduces their sale revenues.
Same goes for Kindles and Kobos: the longer your device works, the more money
they make with their electronic book stores. In my opinion, it's likely Amazon
and Rakuten Kobo produce quarterly cost-benefit reports to decide when to drop
support for older devices, based on ongoing support costs and the recurring
revenues these devices bring in.
Rakuten Kobo is also in a more precarious situation than Amazon is: considering
Amazon's very important market share, if your device stops getting new updates,
there is a greater chance people will replace their old Kobo with a Kindle.
Again, they have an important economic incentive to keep devices running as long
as they are profitable.
Can Free Software fix this?
Yes and no. Free Software certainly isn't a magic wand one can wave to make
everything better, but does provide major advantages in terms of security, user
freedom and sometimes costs. The last piece of the puzzle explaining why Rakuten
Kobo's software support is better than Google's is technological choices.
Smartphones are incredibly complex devices and have become the main computing
platform of many. Similar to the web, there is a race for features and
complexity that tends to create bloat and make older devices slow and painful
to use. On the other hand, e-readers are simpler devices built for a single
task: display electronic books.
Control over the platform is also a key aspect of the cost structure of
providing software updates. Whereas Apple controls both the software and
hardware side of iPhones, Android is a sad mess of drivers and SoCs, all
providing different levels of support over time6.
If you take a look at the platforms the Kindle and Kobo are built on, you'll
quickly see they both use Freescale I.MX SoCs. These processors
are well known for their excellent upstream support in the Linux kernel and
their relative longevity, chips being produced for either 10 or 15 years. This
in turn makes updates much easier and less expensive to provide.
So clearly, open architectures, free drivers and open hardware helps
tremendously, but aren't enough on their own. One of the lessons we must learn
from the (amazing) LineageOS project is how lack of funding hurts everyone.
If there is no one to do the volunteer work required to maintain a version of
LOS for your device, it won't be supported. Worse, when purchasing a new
device, users cannot know in advance how many years of LOS support they will
get. This makes buying new devices a frustrating hit-and-miss experience. If
you are lucky, you will get many years of support. Otherwise, you risk
your device becoming an expensive insecure paperweight.
So how do we fix this? Anyone with a brain understands throwing away perfectly
good devices each 2 years is not sustainable. Government regulations enforcing
a minimum support life would be a step in the right direction, but at the end
of the day, Capitalism is to blame. Like the aforementioned carbon tax, band-aid
solutions can make things somewhat better, but won't fix our current economic
system's underlying problems.
For now though, I'll leave fixing the problem of Capitalism to someone else.
My most recent novel binge has been focused on re-reading the Dune
franchise. I first read the 6 novels written by Frank Herbert when I was 13
years old and only had vague and pleasant memories of his work. Great stuff. ↩
I'm back on LineageOS! Nice folks released an unofficial LOS
17.1 port for the Nexus 5 last January and have kept it updated since
then. If you are to use it, I would also recommend updating TWRP to this
version specifically patched for the Nexus 5. ↩
Very few serious economists actually believe neo-classical
rational agent theory is a satisfactory explanation of human behavior. In my
opinion, it's merely a (mostly flawed) lens to try to interpret certain
behaviors, a tool amongst others that needs to be used carefully, preferably
as part of a pluralism of approaches. ↩
Good data on the e-reader market is hard to come by and is
mainly produced by specialised market research companies selling their
findings at very high prices. Those particular statistics come from a
MarketWatch analysis. ↩
If they were to tell people: You need to pay us 5$/month if you
want to receive software updates, I'm sure most people would not pay. Would
you? ↩
Coming back to Fairphones, if they had so much problems
providing an Android 9 build for the Fairphone 2, it's because Qualcomm
never provided Android 7+ support for the Snapdragon 801 SoC it
uses. ↩
after reading this post I figured I might as well bite the bullet
and improve on my CDPATH-related setup, especially because it does not
work with Emacs. so i looked around for autojump-related alternatives
that do.
What I use now
I currently have this in my .shenv (sourced by .bashrc):
This allows me to quickly jump into projects from my home dir, or the
"source code" (~/src), "work" (src/tor), or wiki checkouts
(~/wikis) directories. It works well from the shell, but
unfortunately it's very static: if I want a new directory, I need to
edit my config file, restart shells, etc. It also doesn't work from my
text editor.
Shell jumpers
Those are commandline tools that can be used from a shell, generally
with built-in shell integration so that a shell alias will find the
right directory magically, usually by keeping track of the directories
visited with cd.
Some of those may or may not have integration in Emacs.
Those projects can be used to track files inside a project or find
files around directories, but do not offer the equivalent
functionality in the shell.
"builds a list of recently opened files. This list is is
automatically saved across sessions on exiting Emacs - you can then
access this list through a command or the menu"
To start off, let me say it again: I hate light pollution. I really, really hate it. I love the night sky where you look up and see thousands of stars, and constellations besides Ursa Major. As somebody said once, “You haven’t lived until you’ve seen your shadow by the light of the Milky Way”.
But, ahem, I live in a large city, and despite my attempts using star trackers, special filters, etc. you simply can’t escape it. So, whenever we go on vacation in the mountains, I’m trying to think if I can do a bit of astro-photography (not that I’m good at it).
Which bring me to our recent vacation up in the mountains. I was looking forward to it, until in the week before, when the weather prognosis was switching between snow, rain and overcast for the entire week. No actual day or night with clear skies, so… I didn’t take a tripod, I didn’t take a wide lens, and put night photography out of my mind.
Vacation itself was good, especially the quietness of the place, so I usually went to be early-ish and didn’t look outside. The weather was as forecasted - no new snow (but there was enough up in the mountains), but heavy clouds all the time, and the sun only showed itself for a few minutes at a time.
One night I was up a bit longer than usual, working on the laptop and being very annoyed by a buzzing sound. At first I thought maybe I was imagining it, but from time to time it was stopping briefly, so it was a real noise; I started hunting for the source. Not my laptop, not the fridge, not the TV… but it was getting stronger near the window. I open the door to the balcony, and… bam! Very loud noise, from the hotel nearby, where — at midnight — the pool was being cleaned. I look at the people doing the work, trying to estimate how long it’ll be until they finish, but it was looking like a long time.
Fortunately with the door closed the noise was not bad enough to impact my sleep, so I debate getting angry or just resigned, and since it was late, I just sigh, roll my eyes — not metaphorically, but actually roll my eyes and look up, and I can’t believe my eyes. Completely clear sky, no trace of clouds anywhere, and… stars. Lots of starts. I sit there, looking at the sky and enjoying the view, and I think to myself that it won’t look that nice on the camera, for sure. Especially without a real trip, and without a fast lens.
Nevertheless, I grab my camera and — just for kicks — take one handheld picture. To my surprise (and almost disbelief), blurry pixels aside, the photo does look like what I was seeing, so I grab my tiny tripod that I carried along, and (with only a 24-70 zoom lens), grab a photo. And another, and another and then I realise that if I can make the composition work, and find a good shutter speed, this can turn out a good picture.
I didn’t have a remote release, the tripod was not very stable and it cannot point the camera upwards (it’s basically an emergency tripod), so it was quite sub-optimal; still, I try multiple shots (different compositions, different shutter speeds); they look on the camera screen and on the phone pretty good, so just for safety I take a few more, and, very happy, go to bed.
Coming back from vacation, on the large monitor, it turns out that the first 28 out of the 30 pictures were either blurry or not well focused (as I was focusing manually), and the 29th was almost OK but still not very good. Only the last, the really last picture, was technically good and also composition-wise OK. Luck? Foresight? Don’t know, but it was worth deleting 28 pictures to get this one. One of my best night shots, despite being so unprepared…
Stars! Lots of stars! And mountains…
Of course, compared to other people’s pictures, this is not special. But for me, it will be a keepsake of how a real night sky should look like.
If you want to zoom in, higher resolution on flickr.
Technically, the challenges for the picture were two-fold:
fighting the shutter speed; the light was not the problem, but rather the tripod and lack of remote release: a short shutter speed will magnify tripod issues/movement from the release (although I was using delayed release on the camera), but will prevent star trails, and a long shutter speed will do the exact opposite; in the end, at the focal length I was using, I settled on a 5 second shutter speed.
composition: due to the presence of the mountains (which I couldn’t avoid by tilting the camera fully up), this was for me a difficult thing, since it’s more on the artistic side, which is… very subjective; in the end, this turned out fine (I think), but mostly because I took pictures from many different perspectives.
Next time when travelling by car, I’ll surely take a proper tripod ☺
To enable the asterisk user to load the certificate successfuly (it
doesn't permission to access to the certificates under /etc/letsencrypt/),
I copied it to the right directory:
The machine on which I run asterisk has a tricky Apache setup:
a webserver is running on port 80
port 80 is restricted to the local network
This meant that the certbot domain ownership checks would get blocked by the
firewall, and I couldn't open that port without exposing the private
webserver to the Internet.
So I ended up disabling the built-in certbot renewal mechanism:
And a new version of digest is now on CRAN will go to Debian shortly.
digest creates hash digests of arbitrary R objects (using the md5, sha-1, sha-256, sha-512, crc32, xxhash32, xxhash64, murmur32, spookyhash, and blake3 algorithms) permitting easy comparison of R language objects. It is a fairly widely-used package (currently listed at 896k monthly downloads, 279 direct reverse dependencies and 8057 indirect reverse dependencies, or just under half of CRAN) as many tasks may involve caching of objects for which it provides convenient general-purpose hash key generation.
This release brings two nice contributed updates. Dirk Schumacher added support for blake3 (though we could probably push this a little harder for performance, help welcome). Winston Chang benchmarked and tuned some of the key base R parts of the package. Last but not least I flipped the vignette to the lovely minidown, updated the Travis CI setup using bspm (as previously blogged about in r4 #30), and added a package website using Matertial for MkDocs.
Troubleshooting your audio input.
When doing video conferencing sometimes I hear the remote end not doing very well.
Especially when your friend tells you he bought a new mic
and it didn't sound well, they might be using the wrong
configuration on the OS and using the other mic, or they
might have a constant noise source in the room that affects
the video conferencing noise cancelling algorithms.
Yes, noise cancelling algorithms aren't perfect because detecting what is noise is heuristic and better to have low level of noise.
Here is the app.
I have a video to demonstrate.
It's a bit of a long shot, but maybe someone on Planet Debian or
elsewhere can help us reach the right people at Apple.
Starting with iOS 14, something apparently changed on the way
USB tethering (also called Personal Hotspot) is set up, which broke
it for people using Linux. The driver in use is ipheth, developped
in 2009 and
included in the Linux kernel in
2010.
The kernel driver negotiates over USB with the iOS device in
order to setup the link. The protocol used by both parties to
communicate don't really seemed documented publicly, and it seems
the protocol has evolved over time and iOS versions, and the Linux
driver hasn't been kept up to date. On macOS and Windows the driver
apparently comes with iTunes, and Apple engineers obviously know
how to communicate with iOS devices, so iOS 14 is supported just
fine.
There's an open
bug on libimobildevice (the set of userlands tools used to
communicate with iOS devices, although the update should be done in
the
kernel), with some debugging and communication logs between
Windows and an iOS device, but so far no real progress has been
done. The link is enabled, the host gets an IP from the device, can
ping the device IP and can even resolve name using the device DNS
resolver, but IP forwarding seems disabled, no packet goes farther
than the device itself.
That means a lot of people upgrading to iOS 14 will suddenly
lose USB tethering. While Wi-Fi and Bluetooth connection sharing
still works, it's still suboptimal, so it'd be nice to fix the
kernel driver and support the latest protocol used in iOS 14.
If someone knows the right contact (or the right way to contact
them) at Apple so we can have access to some kind of documentation
on the protocol and the state machine to use, please reach us
(either to the libimobile device bug or to my email address
below).
The Debian Janitor is an automated
system that commits fixes for (minor) issues in Debian packages that can be
fixed by software. It gradually started proposing merges in early
December. The first set of changes sent out ran lintian-brush on sid packages maintained in
Git. This post is part of a series about the progress of the
Janitor.
lintian-brush can currently fix about 150 different issues that lintian can
report, but that's still a small fraction of the more than thousand different
types of issue that lintian can detect.
If you're interested in contributing a fixer script to lintian-brush, there is now a guide
that describes all steps of the process:
how to identify lintian tags that are good candidates for automated fixing
creating test cases
writing the actual fixer
For more information about the Janitor's lintian-fixes efforts, see the landing page.
Mexico was one of the first countries in the world to set up a
national population registry in the late 1850s, as part of the
church-state separation that was for long years one of the national
sources of pride.
Forty four years ago, when I was born, keeping track of the population
was still mostly a manual task. When my parents registered me, my data
was stored in page 161 of book 22, year 1976, of the 20th Civil
Registration office in Mexico City. Faithful to the legal tradition,
everything is handwritten and specified in full. Because, why would
they write 1976.04.27 (or even 27 de abril de 1976) when they
could spell out día veintisiete de abril de mil novecientos setenta y
seis? Numbers seem to appear only for addresses.
So, the State had record of a child being born, and we knew where to
look if we came to need this information. But, many years later, a
very sensible tecnification happened: all records (after a certain
date, I guess) were digitized. Great news! I can now get my birth
certificate without moving from my desk, paying a quite reasonable fee
(~US$4). What’s there not to like?
Digitally certified and all! So great! But… But… Oh, there’s a
problem.
Of course… Making sense of the handwriting as you can see is
somewhat prone to failure. And I cannot blame anybody for failing to
understand the details of my record.
So, my mother’s first family name is Iszaevich. It was digitized as
Iszaerich. Fortunately, they do acknowledge some errors could have
made it into the process, and there is a process to report and
correct
errors.
What’s there not to like?
Oh — That they do their best to emulate a public office using online
tools. I followed some links in that link to get the address to
contact and yesterday night sent them the needed documents. Quite
immediately, I got an answer that… I must share with the world:
Yes, the mailing contact is in the @gmail.com domain. I could care
about them not using a @….gob.mx address, but I’ll let it slip. The
mail I got says (uppercase and all):
GOOD EVENING,
WE INFORM YOU THAT THE RECEPTION OF E-MAILS FOR REQUESTING
CORRECTIONS IN CERTIFICATES IS ONLY ACTIVE MONDAY THROUGH FRIDAY,
8:00 TO 15:00.
*IN CASE YOU SENT A MAIL OUTSIDE THE WORKING HOURS, IT WILL BE
AUTOMATICALLY DELETED BY THE SERVER*
CORDIAL GREETINGS,
I would only be half-surprised if they were paying the salary of
somebody to spend the wee hours of the night receiving and deleting
mails from their GMail account.
I measured how long the most popular Linux distribution’s package manager take
to install small and large packages (the
ack(1p) source code search Perl script
and qemu, respectively).
Where required, my measurements include metadata updates such as transferring an
up-to-date package list. For me, requiring a metadata update is the more common
case, particularly on live systems or within Docker containers.
All measurements were taken on an Intel(R) Core(TM) i9-9900K CPU @ 3.60GHz
running Docker 1.13.1 on Linux 4.19, backed by a Samsung 970 Pro NVMe drive
boasting many hundreds of MB/s write performance. The machine is located in
Zürich and connected to the Internet with a 1 Gigabit fiber connection, so the
expected top download speed is ≈115 MB/s.
See Appendix C for details on the measurement method and command
outputs.
Measurements
Keep in mind that these are one-time measurements. They should be indicative of
actual performance, but your experience may vary.
The difference between the slowest and fastest package managers is 30x!
How can Alpine’s apk and Arch Linux’s pacman be an order of magnitude faster
than the rest? They are doing a lot less than the others, and more efficiently,
too.
Pain point: too much metadata
For example, Fedora transfers a lot more data than others because its main
package list is 60 MB (compressed!) alone. Compare that with Alpine’s 734 KB
APKINDEX.tar.gz.
Of course the extra metadata which Fedora provides helps some use case,
otherwise they hopefully would have removed it altogether. The amount of
metadata seems excessive for the use case of installing a single package, which
I consider the main use-case of an interactive package manager.
I expect any modern Linux distribution to only transfer absolutely required
data to complete my task.
Pain point: no concurrency
Because they need to sequence executing arbitrary package maintainer-provided
code (hooks and triggers), all tested package managers need to install packages
sequentially (one after the other) instead of concurrently (all at the same
time).
In my blog post “Can we do without hooks and
triggers?”, I outline that hooks and
triggers are not strictly necessary to build a working Linux distribution.
Thought experiment: further speed-ups
Strictly speaking, the only required feature of a package manager is to make
available the package contents so that the package can be used: a program can be
started, a kernel module can be loaded, etc.
By only implementing what’s needed for this feature, and nothing more, a package
manager could likely beat apk’s performance. It could, for example:
skip archive extraction by mounting file system images (like AppImage or snappy)
use compression which is light on CPU, as networks are fast (like apk)
skip fsync when it is safe to do so, i.e.:
package installations don’t modify system state
atomic package installation (e.g. an append-only package store)
automatically clean up the package store after crashes
As per the current landscape, there is no
distribution-scoped package manager which uses images and leaves out hooks and
triggers, not even in smaller Linux distributions.
I think that space is really interesting, as it uses a minimal design to achieve
significant real-world speed-ups.
I have explored this idea in much more detail, and am happy to talk more about
it in my post “Introducing the distri research linux distribution".
Appendix A: related work
There are a couple of recent developments going into the same direction:
NixOS’s Nix takes a little over 5s to fetch and unpack 15 MB.
% docker run -t -i nixos/nix
39e9186422ba:/# time sh -c 'nix-channel --update && nix-env -iA nixpkgs.ack'
unpacking channels...
created 1 symlinks in user environment
installing 'perl5.32.0-ack-3.3.1'
these paths will be fetched (15.55 MiB download, 85.51 MiB unpacked):
/nix/store/34l8jdg76kmwl1nbbq84r2gka0kw6rc8-perl5.32.0-ack-3.3.1-man
/nix/store/9df65igwjmf2wbw0gbrrgair6piqjgmi-glibc-2.31
/nix/store/9fd4pjaxpjyyxvvmxy43y392l7yvcwy1-perl5.32.0-File-Next-1.18
/nix/store/czc3c1apx55s37qx4vadqhn3fhikchxi-libunistring-0.9.10
/nix/store/dj6n505iqrk7srn96a27jfp3i0zgwa1l-acl-2.2.53
/nix/store/ifayp0kvijq0n4x0bv51iqrb0yzyz77g-perl-5.32.0
/nix/store/w9wc0d31p4z93cbgxijws03j5s2c4gyf-coreutils-8.31
/nix/store/xim9l8hym4iga6d4azam4m0k0p1nw2rm-libidn2-2.3.0
/nix/store/y7i47qjmf10i1ngpnsavv88zjagypycd-attr-2.4.48
/nix/store/z45mp61h51ksxz28gds5110rf3wmqpdc-perl5.32.0-ack-3.3.1
copying path '/nix/store/34l8jdg76kmwl1nbbq84r2gka0kw6rc8-perl5.32.0-ack-3.3.1-man' from 'https://cache.nixos.org'...
copying path '/nix/store/czc3c1apx55s37qx4vadqhn3fhikchxi-libunistring-0.9.10' from 'https://cache.nixos.org'...
copying path '/nix/store/9fd4pjaxpjyyxvvmxy43y392l7yvcwy1-perl5.32.0-File-Next-1.18' from 'https://cache.nixos.org'...
copying path '/nix/store/xim9l8hym4iga6d4azam4m0k0p1nw2rm-libidn2-2.3.0' from 'https://cache.nixos.org'...
copying path '/nix/store/9df65igwjmf2wbw0gbrrgair6piqjgmi-glibc-2.31' from 'https://cache.nixos.org'...
copying path '/nix/store/y7i47qjmf10i1ngpnsavv88zjagypycd-attr-2.4.48' from 'https://cache.nixos.org'...
copying path '/nix/store/dj6n505iqrk7srn96a27jfp3i0zgwa1l-acl-2.2.53' from 'https://cache.nixos.org'...
copying path '/nix/store/w9wc0d31p4z93cbgxijws03j5s2c4gyf-coreutils-8.31' from 'https://cache.nixos.org'...
copying path '/nix/store/ifayp0kvijq0n4x0bv51iqrb0yzyz77g-perl-5.32.0' from 'https://cache.nixos.org'...
copying path '/nix/store/z45mp61h51ksxz28gds5110rf3wmqpdc-perl5.32.0-ack-3.3.1' from 'https://cache.nixos.org'...
building '/nix/store/m0rl62grplq7w7k3zqhlcz2hs99y332l-user-environment.drv'...
created 49 symlinks in user environment
real 0m 5.60s
user 0m 3.21s
sys 0m 1.66s
Debian’s apt takes almost 10 seconds to fetch and unpack 16 MB.
% docker run -t -i debian:sid
root@1996bb94a2d1:/# time (apt update && apt install -y ack-grep)
Get:1 http://deb.debian.org/debian sid InRelease [146 kB]
Get:2 http://deb.debian.org/debian sid/main amd64 Packages [8400 kB]
Fetched 8546 kB in 1s (8088 kB/s)
[…]
The following NEW packages will be installed:
ack libfile-next-perl libgdbm-compat4 libgdbm6 libperl5.30 netbase perl perl-modules-5.30
0 upgraded, 8 newly installed, 0 to remove and 23 not upgraded.
Need to get 7341 kB of archives.
After this operation, 46.7 MB of additional disk space will be used.
[…]
real 0m9.544s
user 0m2.839s
sys 0m0.775s
Arch Linux’s pacman takes a little under 3s to fetch and unpack 6.5 MB.
% docker run -t -i archlinux/base
[root@9f6672688a64 /]# time (pacman -Sy && pacman -S --noconfirm ack)
:: Synchronizing package databases...
core 130.8 KiB 1090 KiB/s 00:00
extra 1655.8 KiB 3.48 MiB/s 00:00
community 5.2 MiB 6.11 MiB/s 00:01
resolving dependencies...
looking for conflicting packages...
Packages (2) perl-file-next-1.18-2 ack-3.4.0-1
Total Download Size: 0.07 MiB
Total Installed Size: 0.19 MiB
[…]
real 0m2.936s
user 0m0.375s
sys 0m0.160s
Alpine’s apk takes a little over 1 second to fetch and unpack 10 MB.
NixOS’s Nix takes almost 34s to fetch and unpack 180 MB.
% docker run -t -i nixos/nix
83971cf79f7e:/# time sh -c 'nix-channel --update && nix-env -iA nixpkgs.qemu'
unpacking channels...
created 1 symlinks in user environment
installing 'qemu-5.1.0'
these paths will be fetched (180.70 MiB download, 1146.92 MiB unpacked):
[…]
real 0m 33.64s
user 0m 16.96s
sys 0m 3.05s
Debian’s apt takes over 95 seconds to fetch and unpack 224 MB.
% docker run -t -i debian:sid
root@b7cc25a927ab:/# time (apt update && apt install -y qemu-system-x86)
Get:1 http://deb.debian.org/debian sid InRelease [146 kB]
Get:2 http://deb.debian.org/debian sid/main amd64 Packages [8400 kB]
Fetched 8546 kB in 1s (5998 kB/s)
[…]
Fetched 216 MB in 43s (5006 kB/s)
[…]
real 1m25.375s
user 0m29.163s
sys 0m12.835s
Arch Linux’s pacman takes almost 44s to fetch and unpack 142 MB.
% docker run -t -i archlinux/base
[root@58c78bda08e8 /]# time (pacman -Sy && pacman -S --noconfirm qemu)
:: Synchronizing package databases...
core 130.8 KiB 1055 KiB/s 00:00
extra 1655.8 KiB 3.70 MiB/s 00:00
community 5.2 MiB 7.89 MiB/s 00:01
[…]
Total Download Size: 135.46 MiB
Total Installed Size: 661.05 MiB
[…]
real 0m43.901s
user 0m4.980s
sys 0m2.615s
Alpine’s apk takes only about 2.4 seconds to fetch and unpack 26 MB.
% docker run -t -i alpine
/ # time apk add qemu-system-x86_64
fetch http://dl-cdn.alpinelinux.org/alpine/v3.10/main/x86_64/APKINDEX.tar.gz
fetch http://dl-cdn.alpinelinux.org/alpine/v3.10/community/x86_64/APKINDEX.tar.gz
[…]
OK: 78 MiB in 95 packages
real 0m 2.43s
user 0m 0.46s
sys 0m 0.09s
Appendix B: measurement details (2019)
ack
You can expand each of these:
Fedora’s dnf takes almost 30 seconds to fetch and unpack 107 MB.
% docker run -t -i nixos/nix
39e9186422ba:/# time sh -c 'nix-channel --update && nix-env -i perl5.28.2-ack-2.28'
unpacking channels...
created 2 symlinks in user environment
installing 'perl5.28.2-ack-2.28'
these paths will be fetched (14.91 MiB download, 80.83 MiB unpacked):
/nix/store/57iv2vch31v8plcjrk97lcw1zbwb2n9r-perl-5.28.2
/nix/store/89gi8cbp8l5sf0m8pgynp2mh1c6pk1gk-attr-2.4.48
/nix/store/gkrpl3k6s43fkg71n0269yq3p1f0al88-perl5.28.2-ack-2.28-man
/nix/store/iykxb0bmfjmi7s53kfg6pjbfpd8jmza6-glibc-2.27
/nix/store/k8lhqzpaaymshchz8ky3z4653h4kln9d-coreutils-8.31
/nix/store/svgkibi7105pm151prywndsgvmc4qvzs-acl-2.2.53
/nix/store/x4knf14z1p0ci72gl314i7vza93iy7yc-perl5.28.2-File-Next-1.16
/nix/store/zfj7ria2kwqzqj9dh91kj9kwsynxdfk0-perl5.28.2-ack-2.28
copying path '/nix/store/gkrpl3k6s43fkg71n0269yq3p1f0al88-perl5.28.2-ack-2.28-man' from 'https://cache.nixos.org'...
copying path '/nix/store/iykxb0bmfjmi7s53kfg6pjbfpd8jmza6-glibc-2.27' from 'https://cache.nixos.org'...
copying path '/nix/store/x4knf14z1p0ci72gl314i7vza93iy7yc-perl5.28.2-File-Next-1.16' from 'https://cache.nixos.org'...
copying path '/nix/store/89gi8cbp8l5sf0m8pgynp2mh1c6pk1gk-attr-2.4.48' from 'https://cache.nixos.org'...
copying path '/nix/store/svgkibi7105pm151prywndsgvmc4qvzs-acl-2.2.53' from 'https://cache.nixos.org'...
copying path '/nix/store/k8lhqzpaaymshchz8ky3z4653h4kln9d-coreutils-8.31' from 'https://cache.nixos.org'...
copying path '/nix/store/57iv2vch31v8plcjrk97lcw1zbwb2n9r-perl-5.28.2' from 'https://cache.nixos.org'...
copying path '/nix/store/zfj7ria2kwqzqj9dh91kj9kwsynxdfk0-perl5.28.2-ack-2.28' from 'https://cache.nixos.org'...
building '/nix/store/q3243sjg91x1m8ipl0sj5gjzpnbgxrqw-user-environment.drv'...
created 56 symlinks in user environment
real 0m 14.02s
user 0m 8.83s
sys 0m 2.69s
Debian’s apt takes almost 10 seconds to fetch and unpack 16 MB.
% docker run -t -i debian:sid
root@b7cc25a927ab:/# time (apt update && apt install -y ack-grep)
Get:1 http://cdn-fastly.deb.debian.org/debian sid InRelease [233 kB]
Get:2 http://cdn-fastly.deb.debian.org/debian sid/main amd64 Packages [8270 kB]
Fetched 8502 kB in 2s (4764 kB/s)
[…]
The following NEW packages will be installed:
ack ack-grep libfile-next-perl libgdbm-compat4 libgdbm5 libperl5.26 netbase perl perl-modules-5.26
The following packages will be upgraded:
perl-base
1 upgraded, 9 newly installed, 0 to remove and 60 not upgraded.
Need to get 8238 kB of archives.
After this operation, 42.3 MB of additional disk space will be used.
[…]
real 0m9.096s
user 0m2.616s
sys 0m0.441s
Arch Linux’s pacman takes a little over 3s to fetch and unpack 6.5 MB.
% docker run -t -i archlinux/base
[root@9604e4ae2367 /]# time (pacman -Sy && pacman -S --noconfirm ack)
:: Synchronizing package databases...
core 132.2 KiB 1033K/s 00:00
extra 1629.6 KiB 2.95M/s 00:01
community 4.9 MiB 5.75M/s 00:01
[…]
Total Download Size: 0.07 MiB
Total Installed Size: 0.19 MiB
[…]
real 0m3.354s
user 0m0.224s
sys 0m0.049s
Alpine’s apk takes only about 1 second to fetch and unpack 10 MB.
% docker run -t -i alpine
/ # time apk add ack
fetch http://dl-cdn.alpinelinux.org/alpine/v3.10/main/x86_64/APKINDEX.tar.gz
fetch http://dl-cdn.alpinelinux.org/alpine/v3.10/community/x86_64/APKINDEX.tar.gz
(1/4) Installing perl-file-next (1.16-r0)
(2/4) Installing libbz2 (1.0.6-r7)
(3/4) Installing perl (5.28.2-r1)
(4/4) Installing ack (3.0.0-r0)
Executing busybox-1.30.1-r2.trigger
OK: 44 MiB in 18 packages
real 0m 0.96s
user 0m 0.25s
sys 0m 0.07s
qemu
You can expand each of these:
Fedora’s dnf takes over a minute to fetch and unpack 266 MB.
% docker run -t -i nixos/nix
39e9186422ba:/# time sh -c 'nix-channel --update && nix-env -i qemu-4.0.0'
unpacking channels...
created 2 symlinks in user environment
installing 'qemu-4.0.0'
these paths will be fetched (262.18 MiB download, 1364.54 MiB unpacked):
[…]
real 0m 38.49s
user 0m 26.52s
sys 0m 4.43s
Debian’s apt takes 51 seconds to fetch and unpack 159 MB.
% docker run -t -i debian:sid
root@b7cc25a927ab:/# time (apt update && apt install -y qemu-system-x86)
Get:1 http://cdn-fastly.deb.debian.org/debian sid InRelease [149 kB]
Get:2 http://cdn-fastly.deb.debian.org/debian sid/main amd64 Packages [8426 kB]
Fetched 8574 kB in 1s (6716 kB/s)
[…]
Fetched 151 MB in 2s (64.6 MB/s)
[…]
real 0m51.583s
user 0m15.671s
sys 0m3.732s
Arch Linux’s pacman takes 1m2s to fetch and unpack 124 MB.
% docker run -t -i archlinux/base
[root@9604e4ae2367 /]# time (pacman -Sy && pacman -S --noconfirm qemu)
:: Synchronizing package databases...
core 132.2 KiB 751K/s 00:00
extra 1629.6 KiB 3.04M/s 00:01
community 4.9 MiB 6.16M/s 00:01
[…]
Total Download Size: 123.20 MiB
Total Installed Size: 587.84 MiB
[…]
real 1m2.475s
user 0m9.272s
sys 0m2.458s
Alpine’s apk takes only about 2.4 seconds to fetch and unpack 26 MB.
% docker run -t -i alpine
/ # time apk add qemu-system-x86_64
fetch http://dl-cdn.alpinelinux.org/alpine/v3.10/main/x86_64/APKINDEX.tar.gz
fetch http://dl-cdn.alpinelinux.org/alpine/v3.10/community/x86_64/APKINDEX.tar.gz
[…]
OK: 78 MiB in 95 packages
real 0m 2.43s
user 0m 0.46s
sys 0m 0.09s
Over the last year or so I have worked on a research linux distribution in my
spare time. It’s not a distribution for researchers (like Scientific
Linux), but my personal
playground project to research linux distribution development, i.e. try out
fresh ideas.
This article focuses on the package format and its advantages, but there is
more to distri, which I will cover in upcoming blog posts.
Frequently, I was noticing a large gap between the actual speed of an operation
(e.g. doing an update) and the possible speed based on back of the envelope
calculations. I wrote more about this in my blog post “Package managers are
slow”.
To me, this observation means that either there is potential to optimize the
package manager itself (e.g. apt), or what the system does is just too
complex. While I remember seeing some low-hanging fruit¹, through my work on
distri, I wanted to explore whether all the complexity we currently have in
Linux distributions such as Debian or Fedora is inherent to the problem space.
I have completed enough of the experiment to conclude that the complexity is not
inherent: I can build a Linux distribution for general-enough purposes which is
much less complex than existing ones.
① Those were low-hanging fruit from a user perspective. I’m not saying that
fixing them is easy in the technical sense; I know too little about apt’s code
base to make such a statement.
Key idea: packages are images, not archives
One key idea is to switch from using archives to using images for package
contents. Common package managers such as dpkg(1)
use tar(1)
archives with various compression
algorithms.
This idea is not novel: AppImage and
snappy also use
images, but only for individual, self-contained applications. distri however
uses images for distribution packages with dependencies. In particular, there is
no duplication of shared libraries in distri.
A nice side effect of using read-only image files is that applications are
immutable and can hence not be broken by accidental (or malicious!)
modification.
Key idea: separate hierarchies
Package contents are made available under a fully-qualified path. E.g., all
files provided by package zsh-amd64-5.6.2-3 are available under
/ro/zsh-amd64-5.6.2-3. The mountpoint /ro stands for read-only, which is
short yet descriptive.
Perhaps surprisingly, building software with custom prefix values of
e.g. /ro/zsh-amd64-5.6.2-3 is widely supported, thanks to:
Linux distributions, which build software with prefix set to /usr,
whereas FreeBSD (and the autotools default), which build with prefix set to
/usr/local.
Enthusiast users in corporate or research environments, who install software
into their home directories.
Because using a custom prefix is a common scenario, upstream awareness for
prefix-correctness is generally high, and the rarely required patch will be
quickly accepted.
Key idea: exchange directories
Software packages often exchange data by placing or locating files in well-known
directories. Here are just a few examples:
zsh(1)
locates executable programs via PATH components such as /bin
In distri, these locations are called exchange directories and are provided
via FUSE in /ro.
Exchange directories come in two different flavors:
global. The exchange directory, e.g. /ro/share, provides the union of the
share sub directory of all packages in the package store.
Global exchange directories are largely used for compatibility, see
below.
per-package. Useful for tight coupling: e.g. irssi(1)
does not provide any ABI guarantees, so plugins such as irssi-robustirc
can declare that they want
e.g. /ro/irssi-amd64-1.1.1-1/out/lib/irssi/modules to be a per-package
exchange directory and contain files from their lib/irssi/modules.
Search paths sometimes need to be fixed
Programs which use exchange directories sometimes use search paths to access
multiple exchange directories. In fact, the examples above were taken from gcc(1)
’s INCLUDEPATH, man(1)
’s MANPATH and zsh(1)
’s PATH. These are
prominent ones, but more examples are easy to find: zsh(1)
loads completion functions from its FPATH.
Some search path values are derived from --datadir=/ro/share and require no
further attention, but others might derive from
e.g. --prefix=/ro/zsh-amd64-5.6.2-3/out and need to be pointed to an exchange
directory via a specific command line flag.
FHS compatibility
Global exchange directories are used to make distri provide enough of the
Filesystem Hierarchy Standard
(FHS) that
third-party software largely just works. This includes a C development
environment.
I successfully ran a few programs from their binary packages such as Google
Chrome, Spotify, or Microsoft’s Visual Studio Code.
distri’s package manager is extremely fast. Its main bottleneck is typically the network link, even at high speed links (I tested with a 100 Gbps link).
Its speed comes largely from an architecture which allows the package manager to
do less work. Specifically:
Package images can be added atomically to the package store, so we can safely
skip fsync(2)
. Corruption will be cleaned up
automatically, and durability is not important: if an interactive
installation is interrupted, the user can just repeat it, as it will be fresh
on their mind.
Because all packages are co-installable thanks to separate hierarchies, there
are no conflicts at the package store level, and no dependency resolution (an
optimization problem requiring SAT
solving) is required at all.
In exchange directories, we resolve conflicts by selecting the package with the
highest monotonically increasing distri revision number.
distri proves that we can build a useful Linux distribution entirely without
hooks and triggers. Not having to
serialize hook execution allows us to download packages into the package
store with maximum concurrency.
Because we are using images instead of archives, we do not need to unpack
anything. This means installing a package is really just writing its package
image and metadata to the package store. Sequential writes are typically the
fastest kind of storage usage pattern.
Fast installation also make other use-cases more bearable, such as creating disk
images, be it for testing them in qemu(1)
, booting
them on real hardware from a USB drive, or for cloud providers such as Google
Cloud.
Fast package builder
Contrary to how distribution package builders are usually implemented, the
distri package builder does not actually install any packages into the build
environment.
Instead, distri makes available a filtered view of the package store (only
declared dependencies are available) at /ro in the build environment.
This means that even for large dependency trees, setting up a build environment
happens in a fraction of a second! Such a low latency really makes a difference
in how comfortable it is to iterate on distribution packages.
Package stores
In distri, package images are installed from a remote package store into the
local system package store /roimg, which backs the /ro mount.
A package store is implemented as a directory of package images and their
associated metadata files.
You can easily make available a package store by using distri export.
To provide a mirror for your local network, you can periodically distri update
from the package store you want to mirror, and then distri export your local
copy. Special tooling (e.g. debmirror in Debian) is not required because
distri install is atomic (and update uses install).
Producing derivatives is easy: just add your own packages to a copy of the
package store.
The package store is intentionally kept simple to manage and distribute. Its
files could be exchanged via peer-to-peer file systems, or synchronized from an
offline medium.
distri’s first release
distri works well enough to demonstrate the ideas explained above. I have
branched this state into branch
jackherer, distri’s first
release code name. This way, I can keep experimenting in the distri repository
without breaking your installation.
From the branch contents, our autobuilder creates:
Right now, distri is mainly a vehicle for my spare-time Linux distribution
research. I don’t recommend anyone use distri for anything but research, and
there are no medium-term plans of that changing. At the very least, please
contact me before basing anything serious on distri so that we can talk about
limitations and expectations.
I expect the distri project to live for as long as I have blog posts to publish,
and we’ll see what happens afterwards. Note that this is a hobby for me: I will
continue to explore, at my own pace, parts that I find interesting.
My hope is that established distributions might get a useful idea or two from
distri.
There’s more to come: subscribe to the distri feed
I don’t want to make this post too long, but there is much more!
Please subscribe to the following URL in your feed reader to get all posts about
distri:
One of the most awesome helpers I carry around in my ~/bin since
the early '00s is the
sanity.pl
script written by Andreas Gohr. It just recently came back to use
when I started to archive some awesome Corona enforced live
session music with youtube-dl.
Update:
Francois Marier pointed out that Debian contains the
detox
package, which has a similar functionality.
This is a follow-up from the blog post of Russel as seen here: https://etbe.coker.com.au/2020/10/13/first-try-gnocchi-statsd/. There’s a bunch of things he wrote which I unfortunately must say is inaccurate, and sometimes even completely wrong. It is my point of view that none of the reported bugs are helpful for anyone that understand Gnocchi and how to set it up. It’s however a terrible experience that Russell had, and I do understand why (and why it’s not his fault). I’m very much open on how to fix this on the packaging level, though some things aren’t IMO fixable. Here’s the details.
1/ The daemon startups
First of all, the most surprising thing is when Russell claimed that there’s no startup scripts for the Gnocchi daemons. In fact, they all come with both systemd and sysv-rc support:
# ls /lib/systemd/system/gnocchi-api.service /lib/systemd/system/gnocchi-api.service # /etc/init.d/gnocchi-api /etc/init.d/gnocchi-api
Russell then tried to start gnocchi-api without the good options that are set in the Debian scripts, and not surprisingly, this failed. Russell attempted to do what was in the upstream doc, which isn’t adapted to what we have in Debian (the upstream doc is probably completely outdated, as Gnocchi is unfortunately not very well maintained upstream).
The bug #972087 is therefore, IMO not valid.
2/ The database setup
By default for all things OpenStack in Debian, there are some debconf helpers using dbconfig-common to help users setup database for their services. This is clearly for beginners, but that doesn’t prevent from attempting to understand what you’re doing. That is, more specifically for Gnocchi, there are 2 databases: one for Gnocchi itself, and one for the indexer, which not necessarily is using the same backend. The Debian package already setups one database, but one has to do it manually for the indexer one. I’m sorry this isn’t well enough documented.
Now, if some package are supporting sqlite as a backend (since most things in OpenStack are using SQLAlchemy), it looks like Gnocchi doesn’t right now. This is IMO a bug upstream, rather than a bug in the package. However, I don’t think the Debian packages are to be blame here, as they simply offer a unified interface, and it’s up to the users to know what they are doing. SQLite is anyway not a production ready backend. I’m not sure if I should close #971996 without any action, or just try to disable the SQLite backend option of this package because it may be confusing.
3/ The metrics UUID
Russell then thinks the UUID should be set by default. This is probably right in a single server setup, however, this wouldn’t work setting-up a cluster, which is probably what most Gnocchi users will do. In this type of environment, the metrics UUID must be the same on the 3 servers, and setting-up a random (and therefore different) UUID on the 3 servers wouldn’t work. So I’m also tempted to just close #972092 without any action on my side.
4/ The coordination URL
Since Gnocchi is supposed to be setup with more than one server, as in OpenStack, having an HA setup is very common, then a backend for the coordination (ie: sharing the workload) must be set. This is done by setting an URL that tooz understand. The best coordinator being Zookeeper, something like this should be set by hand:
coordination_url=zookeeper://192.168.101.2:2181/
Here again, I don’t think the Debian package is to be blamed for not providing the automation. I would however accept contributions to fix this and provide the choice using debconf, however, users would still need to understand what’s going on, and setup something like Zookeeper (or redis, memcache, or any other backend supported by tooz) to act as coordinator.
5/ The Debconf interface cannot replace a good documentation
… and there’s not so much I can do at my package maintainer level for this.
Russell, I’m really sorry for the bad user experience you had with Gnocchi. Now that you know a little big more about it, maybe you can have another go? Sure, the OpenStack telemetry system isn’t an easy to understand beast, but it’s IMO worth trying. And the recent versions can scale horizontally…
Note that since I am making a public website available over Tor, I do not
need the location of the website to be hidden and so I used the same
settings as
Cloudflare in their
public Tor proxy.
Also, I explicitly used the external IPv6 address of my server in the
configuration in order to prevent localhost
bypasses.
After restarting the Tor daemon to reload the configuration file:
and configured my Apache vhosts in /etc/apache2/sites-enabled/www.conf:
<VirtualHost *:443>
ServerName fmarier.org
ServerAlias ixrdj3iwwhkuau5tby5jh3a536a2rdhpbdbu6ldhng43r47kim7a3lid.onion
Protocols h2, http/1.1
Header set Onion-Location "http://ixrdj3iwwhkuau5tby5jh3a536a2rdhpbdbu6ldhng43r47kim7a3lid.onion%{REQUEST_URI}s"
Header set alt-svc 'h2="ixrdj3iwwhkuau5tby5jh3a536a2rdhpbdbu6ldhng43r47kim7a3lid.onion:443"; ma=315360000; persist=1'
Header add Strict-Transport-Security: "max-age=63072000"
Include /etc/fmarier-org/www-common.include
SSLEngine On
SSLCertificateFile /etc/letsencrypt/live/fmarier.org/fullchain.pem
SSLCertificateKeyFile /etc/letsencrypt/live/fmarier.org/privkey.pem
</VirtualHost>
<VirtualHost *:80>
ServerName fmarier.org
Redirect permanent / https://fmarier.org/
</VirtualHost>
<VirtualHost *:80>
ServerName ixrdj3iwwhkuau5tby5jh3a536a2rdhpbdbu6ldhng43r47kim7a3lid.onion
Include /etc/fmarier-org/www-common.include
</VirtualHost>
Note that /etc/fmarier-org/www-common.include contains all of the
configuration options that are common to both the HTTP and the HTTPS sites
(e.g. document root, caching headers, aliases, etc.).
$ whois 2a0b:f4c2:2::1
...
inet6num: 2a0b:f4c2::/40
netname: MK-TOR-EXIT
remarks: -----------------------------------
remarks: This network is used for Tor Exits.
remarks: We do not have any logs at all.
remarks: For more information please visit:
remarks: https://www.torproject.org
which indicates that the first request was not using the .onion
address.
Last weekend, Tim Burgess’s twitter listening party covered The Cure’s short, dark 1982 album “Pornography”. I realised I’d never actually played the record, which I picked up a couple of years ago from a shop in the Grainger Market which is sadly no longer there. It was quite a wallet-threatening shop so perhaps it’s a good thing it’s gone.
Monday was a dreary, rainy day which seemed the perfect excuse to put it on. It’s been long enough since I last listened to my CD copy of the album that there were a few nice surprises to rediscover. The closing title track sounded quite different to how I remembered it, with Robert Smith’s vocals buried deeper in the mix, but my memory might be mixing up a different session take.
Truly a fitting closing lyric for our current times: I must fight this sickness /
Find a cure
I've released version 1.0.0 of plocate, my faster locate(1)!
(Actually, I'm now at 1.0.2, after some minor fixes and
improvements.) It has a new build system, portability fixes,
man pages, support for case-insensitive searches (still quite fast),
basic and extended regex searches (as slow as mlocate)
and a few other options. The latter two were mostly to increase mlocate
compatibility, not because I think either is very widely used.
That, and supporting case-insensitive searches was an interesting
problem in its own right :-)
It now also has a small home page
with tarballs. And access() checking is also now asynchronous via io_uring
via a small trick (assuming Linux 5.6 or newer, it can run an
asynchronous statx() to prime the cache, all but guaranteeing
that the access() call itself won't lead to I/O), speeding up
certain searches on non-SSDs even more.
There's also a Debian package in NEW.
In short, plocate now has grown up, and it wants to be your
default locate. I've considered replacing mlocate's updatedb
as well, but it's honestly not a space I want to be in right
now; it involves so much munging with special cases caused
by filesystem restrictions and the likes.
Bug reports, distribution packages and all other feedback
welcome!
I’ve been investigating the options for tracking system statistics to diagnose performance problems. The idea is to track all sorts of data about the system (network use, disk IO, CPU, etc) and look for correlations at times of performance problems. DataDog is pretty good for this but expensive, it’s apparently based on or inspired by the Etsy Statsd. It’s claimed that the gnocchi-statsd is the best implementation of the protoco used by the Etsy Statsd, so I decided to install that.
I use Debian/Buster for this as that’s what I’m using for the hardware that runs KVM VMs. Here is what I did:
# it depends on a local MySQL database
apt -y install mariadb-server mariadb-client
# install the basic packages for gnocchi
apt -y install gnocchi-common python3-gnocchiclient gnocchi-statsd uuid
In the Debconf prompts I told it to “setup a database” and not to manage keystone_authtoken with debconf (because I’m not doing a full OpenStack installation).
This gave a non-working configuration as it didn’t configure the MySQL database for the [indexer] section and the sqlite database that was configured didn’t work for unknown reasons. I filed Debian bug #971996 about this [1]. To get this working you need to edit /etc/gnocchi/gnocchi.conf and change the url line in the [indexer] section to something like the following (where the password is taken from the [database] section).
Here’s an official page about how to operate Gnocchi [3]. The main thing I got from this was that the following commands need to be run from the command-line (I ran them as root in a VM for test purposes but would do so with minimum privs for a real deployment).
gnocchi-api
gnocchi-metricd
To communicate with Gnocchi you need the gnocchi-api program running, which uses the uwsgi program to provide the web interface by default. It seems that this was written for a version of uwsgi different than the one in Buster. I filed Debian bug #972087 with a patch to make it work with uwsgi [4]. Note that I didn’t get to the stage of an end to end test, I just got it to basically run without error.
After getting “gnocchi-api” running (in a terminal not as a daemon as Debian doesn’t seem to have a service file for it), I ran the client program “gnocchi” and then gave it the “status” command which failed (presumably due to the metrics daemon not running), but at least indicated that the client and the API could communicate.
Then I ran the “gnocchi-metricd” and got the following error:
2020-10-12 14:59:30,491 [9037] ERROR gnocchi.cli.metricd: Unexpected error during processing job
Traceback (most recent call last):
File "/usr/lib/python3/dist-packages/gnocchi/cli/metricd.py", line 87, in run
self._run_job()
File "/usr/lib/python3/dist-packages/gnocchi/cli/metricd.py", line 248, in _run_job
self.coord.update_capabilities(self.GROUP_ID, self.store.statistics)
File "/usr/lib/python3/dist-packages/tooz/coordination.py", line 592, in update_capabilities
raise tooz.NotImplemented
tooz.NotImplemented
At this stage I’ve had enough of gnocchi. I’ll give the Etsy Statsd a go next.
Update
Thomas has responded to this post [5]. At this stage I’m not really interested in giving Gnocchi another go. There’s still the issue of the indexer database which should be different from the main database somehow and sqlite (the config file default) doesn’t work.
I expect that if I was to persist with Gnocchi I would encounter more poorly described error messages from the code which either don’t have Google hits when I search for them or have Google hits to unanswered questions from 5+ years ago.
The Gnocchi systemd config files are in different packages to the programs, this confused me and I thought that there weren’t any systemd service files. I had expected that installing a package with a daemon binary would also get the systemd unit file to match.
The cluster features of Gnocchi are probably really good if you need that sort of thing. But if you have a small instance (EG a single VM server) then it’s not needed. Also one of the original design ideas of the Etsy Statsd was that UDP was used because data could just be dropped if there was a problem. I think for many situations the same concept could apply to the entire stats service.
If the other statsd programs don’t do what I need then I may give Gnocchi another go.
Welcome to gambaru.de. Here is my monthly report (+ the first week in October) that covers what I have been doing for Debian. If you’re interested in Java, Games and LTS topics, this might be interesting for you.
Debian Games
I spent most of the time this month to tackle remaining GCC 10 bugs in packages like nettoe, pcsxr, slimevolley (patch by Reiner Herrmann), openal-soft, slashem and alien-arena. I also investigated a build failure in gfpoken (#957271) and springlobby and finally uploaded a new revision of warzone2100 to address another FTBFS while building the PDF documentation.
and sponsored a new release of mgba for Ryan Tandy.
Debian Java
The focus was on two major packages this month, PDFsam, a tool to manipulate PDF files and Netbeans, one of the three well known Java IDEs. I basically updated every PDFsam related sejda dependency and packaged a new library libsejda-common-java, which is currently waiting in the NEW queue. As soon as this one has been approved, we should be able to see the latest release in Debian soon.
Unfortunately I came to the conclusion that maintaining Netbeans in Debian is no longer a viable solution. I have been the sole maintainer for the past five years and managed to package the basic Java IDE in Stretch. I also had a 98% ready package for Buster but there were some bugs that made it unfit for a stable release in my opinion. The truth is, it takes a lot of time to patch Netbeans, just to make the build system DFSG compliant and to build the IDE from source. We have never managed to provide more functionality than the basic Java IDE features too. Still, we had to maintain dozens of build-dependencies and there was a constant struggle to make everything work with just a single version of a library. While the Debian way works great for most common projects, it doesn’t scale very well for very complex ones like Java IDEs. Neither Eclipse nor Netbeans are really fully maintainable in Debian since they consist of hundreds of different jar files, even if the toolchain was perfect, it would require too much time to maintain all those Debian packages.
I voiced that sentiment on our debian-java mailinglist while also discussing the situation of complex server packages like Apache Solr. Similar to Netbeans it requires hundreds of jar files to get running. I believe our users are better served in those cases by using tools like flatpak for desktop packages or jdeb for server packages. The idea is to provide a Debian toolchain which would download a source package from upstream and then use jdeb to create a Debian package. Thus we could provide packages for very complex Java software again, although only via the Debian contrib distribution. The pros are: software is available as Debian packages and integrates well with your system and considerably less time is needed to maintain such packages: Cons: not available in Debian main, no security support, not checked for DFSG compliance.
Should we do that for all of our packages? No. This should really be limited to packages that otherwise would not be in Debian at all and are too complex to maintain, when even a whole team of normal contributors would struggle.
Finally the consequences were: the Netbeans IDE has been removed from Debian main but the Netbeans platform package, libnb-platform18-java, is up-to-date again just like visualvm, which depends on it.
I eventually filed a RFA for privacybadger. As I mentioned in my last post, the upstream maintainer would like to see regular updates in Debian stable but I don’t want to regularly contribute time for this task. If someone is ready for the job, let me know.
This was my 55. month as a paid contributor and I have been paid to work 31,75 hours on Debian LTS, a project started by Raphaël Hertzog. In that time I did the following:
Investigated and fixed a regression in squid3 when using the icap server. (#965012)
DLA-2394-1. Issued a security update for squid3 fixing 4 CVE.
DLA-2400-1. Issued a security update for activemq fixing 1 CVE.
DLA-2403-1. Issued a security update for rails fixing 1 CVE.
DLA-2404-1. Issued a security update for eclipse-wtp fixing 1 CVE.
DLA-2405-1. Issued a security update for httpcomponents-client fixing 1 CVE.
Triaged open CVE for guacamole-server and guacamole-client and prepared patches for CVE-2020-9498 and CVE-2020-9497.
Prepared patches for 7 CVE in libonig.
ELTS
Extended Long Term Support (ELTS) is a project led by Freexian to further extend the lifetime of Debian releases. It is not an official Debian project but all Debian users benefit from it without cost. The current ELTS release is Debian 8 „Jessie“. This was my 28. month and I have been paid to work 15 hours on ELTS.
ELA-291-1. Issued a security update for libproxy fixing 1 CVE.
ELA-294-1. Issued a security update for squid3 fixing 4 CVE.
ELA-295-1. Issued a security update for rails fixing 2 CVE.
ELA-296-1. Issued a security update for httpcomponents-client fixing 1 CVE.
I wanted to share Type design issue I hit recently with Striot.
Within StrIoT you define a stream-processing program, which is a series of
inter-connected operators, in terms of a trio of graph types:
The outer-most type is a higher-order type provided by the Graph library we
use: Graph a. This layer deals with all the topology concerns: what is
connected to what.
The next type we define in StrIoT: StreamVertex, which is used to replace
a in the above and make the concrete type Graph StreamVertex. Here we
define all the properties of the operators. For example: the parameters supplied
to the operator, and a unique vertexID integer that is unfortunately necessary.
We also define which operator type each node represents, with an
instance of the third type,
For some recent work I needed to define some additional properties for the
operators: properties that would be used in a M/M/1 model (Jackson network) to
represent the program do some cost modelling with. Initially we supplied this
additional information in completely separate instances of types: e.g. lists
of tuples, the first of a pair representing a vertexID, etc. This was mostly
fine for totally novel code, but where I had existing code paths that operated
in terms of Graph StreamVertex and now needed access to these parameters, it
would have meant refactoring a lot of code. So instead, I added these properties
directly to the types above.
Some properties are appropriate for all node types, e.g. mean average service time.
In that case, I added the parameter to the StreamVertex type:
data StreamVertex = StreamVertex
{ vertexId :: Int
…
, serviceTime:: Double
}
Other parameters were only applicable to certain node types. Mean average
arrival rate, for example., is only valid for Source node types;
selectivity is appropriate only for filter types. So, I added these to the
StreamOperator type:
This works pretty well, and most of the code paths that already exist did not
need to be updated in order for the model parameters to pass through to where
they are needed. But it was not a perfect solution, because I now had to modify
some other, unrelated code to account for the type changes.
Mostly this was test code: where I'd defined instances of Graph StreamVertex
to test something unrelated to the modelling work, I now had to add filter
selectivities and source arrival rates. This was tedious but mostly solved with
automatically with some editor macros.
One area though, that was a problem, was equality checks and pattern matching.
Before this change, I had a few areas of code like this
if Source == operator (head (vertexList sg))
…
if a /= b then… -- where a and b are instances of StreamOperator
I had to replace them with little helper routines like
cmpOps :: StreamOperator -> StreamOperator -> Bool
cmpOps (Filter _) (Filter _) = True
cmpOps (FilterAcc _) (FilterAcc _) = True
cmpOps x y = x == y
A similar problem was where I needed to synthesize a Filter, and I didn't care
about the selectivity, indeed, it was meaningless for the way I was using the type.
I have a higher-level function that handles "hoisting" an Operator through a Merge:
So, before, you have some operator occurring after a merge operation, and afterwards,
you have several instances of the operator on all of the input streams prior to the
Merge. Invoking it now looks like this
filterMerge = pushOp (Filter 0)
It works, the "0" is completely ignored, but the fact I have to provide it, and it's
unneeded, and there is no sensible value for it, is a bit annoying.
I think there's some interesting things to consider here about Type design, especially
when you have some aspects of a "thing" which are relevant only in some contexts and
not others.
The first time Linda Tirado came to the viral attention of the Internet
was in 2013 when she responded to a forum question: "Why do poor people do
things that seem so self-destructive?" Here are some excerpts from her
virally popular five-page response, which is included in the first
chapter:
I know how to cook. I had to take Home Ec. to graduate high school.
Most people on my level didn't. Broccoli is intimidating. You have
to have a working stove, and pots, and spices, and you'll have to do
the dishes no matter how tired you are or they'll attract bugs. It is
a huge new skill for a lot of people. That's not great, but it's
true. And if you fuck it up, you could make your family sick. We
have learned not to try too hard to be middle class. It never works
out well and always makes you feel worse for having tried and failed
yet again. Better not to try. It makes more sense to get food that
you know will be palatable and cheap and that keeps well. Junk food
is a pleasure that we are allowed to have; why would we give that up?
We have very few of them.
and
I smoke. It's expensive. It's also the best option. You see, I am
always, always exhausted. It's a stimulant. When I am too tired to
walk one more step, I can smoke and go for another hour. When I am
enraged and beaten down and incapable of accomplishing one more thing,
I can smoke and I feel a little better, just for a minute. It is the
only relaxation I am allowed. It is not a good decision, but it is
the only one that I have access to. It is the only thing I have found
that keeps me from collapsing or exploding.
This book is an expansion on that essay. It's an entry in a growing genre
of examinations of what it means to be poor in the United States in the
21st century. Unlike most of those examinations, it isn't written by an
outsider performing essentially anthropological field work. It's one of
the rare books written by someone who is herself poor and had the
combination of skill and viral fame required to get an opportunity to talk
about it in her own words.
I haven't had it worse than anyone else, and actually, that's kind of
the point. This is just what life is for roughly a third of the
country. We all handle it in our own ways, but we all work in the
same jobs, live in the same places, feel the same sense of never quite
catching up. We're not any happier about the exploding welfare rolls
than anyone else is, believe me. It's not like everyone grows up and
dreams of working two essentially meaningless part-time jobs while
collecting food stamps. It's just that there aren't many other
options for a lot of people.
I didn't find this book back in 2014 when it was published. I found it in
2020 during Tirado's second round of Internet fame: when the police shot
out her eye with "non-lethal" rounds while she was covering the George
Floyd protests as a photojournalist. In characteristic fashion, she
subsequently reached out to the other people who had been blinded by the
police, used her temporary fame to organize crowdfunded support for
others, and is planning on having "try again" tattooed over the scar.
That will give you a feel for the style of this book. Tirado is blunt,
opinionated, honest, and full speed ahead. It feels weird to call this
book delightful since it's fundamentally about the degree to which the
United States is failing a huge group of its citizens and making their
lives miserable, but there is something so refreshing and clear-headed
about Tirado's willingness to tell you the straight truth about her life.
It's empathy delivered with the subtlety of a brick, but also with about
as much self-pity as a brick. Tirado is not interested in making you feel
sorry for her; she's interested in you paying attention.
I don't get much of my own time, and I am vicious about protecting
it. For the most part, I am paid to pretend that I am inhuman, paid
to cater to both the reasonable and unreasonable demands of the
general public. So when I'm off work, feel free to go fuck yourself.
The times that I am off work, awake, and not taking care of life's
details are few and far between. It's the only time I have any
autonomy. I do not choose to waste that precious time worrying about
how you feel. Worrying about you is something they pay me for; I
don't work for free.
If you've read other books on this topic (Emily Guendelsberger's
On the Clock is still the best of those
I've read), you probably won't get many new facts from Hand to
Mouth. I think this book is less important for the policy specifics than
it is for who is writing it (someone who is living that life and can be
honest about it) and the depth of emotional specifics that Tirado brings
to the description. If you have never been poor, you will learn the
details of what life is like, but more significantly you'll get a feel for
how Tirado feels about it, and while this is one individual perspective
(as Tirado stresses, including the fact that, as a white person, there are
other aspects of poverty she's not experienced), I think that perspective
is incredibly valuable.
That said, Hand to Mouth provides even more reinforcement of the
importance of universal medical care, the absurdity of not including
dental care in even some of the more progressive policy proposals, and the
difficulties in the way of universal medical care even if we solve the
basic coverage problem. Tirado has significant dental problems due to
unrepaired damage from a car accident, and her account reinforces my
belief that we woefully underestimate how important good dental care is to
quality of life. But providing universal insurance or access is only the
start of the problem.
There is a price point for good health in America, and I have rarely
been able to meet it. I choose not to pursue treatment if it will
cost me more than it will gain me, and my cost-benefit is done in more
than dollars. I have to think of whether I can afford any potential
treatment emotionally, financially, and timewise. I have to sort out
whether I can afford to change my life enough to make any treatment
worth it — I've been told by more than one therapist that I'd be fine
if I simply reduced the amount of stress in my life. It's true,
albeit unhelpful. Doctors are fans of telling you to sleep and eat
properly, as though that were a thing one can simply do.
That excerpt also illustrates one of the best qualities of this book. So
much writing about "the poor" treats them as an abstract problem that the
implicitly not-poor audience needs to solve, and this leads rather
directly to the endless moralizing as "we" attempt to solve that problem
by telling poor people what they need to do. Tirado is unremitting in
fighting for her own agency. She has a shitty set of options, but within
those options she makes her own decisions. She wants better options and
more space in which to choose them, which I think is a much more
productive way to frame the moral argument than the endless hand-wringing
over how to help "those poor people."
This is so much of why I support universal basic income. Just give people
money. It's not all of the solution — UBI doesn't solve the problem of
universal medical care, and we desperately need to find a way to make work
less awful — but it's the most effective thing we can do immediately.
Poor people are, if anything, much better at making consequential
financial decisions than rich people because they have so much more
practice. Bad decisions are less often due to bad decision-making than
bad options and the balancing of objectives that those of us who are not
poor don't understand.
Hand to Mouth is short, clear, refreshing, bracing, and, as you
might have noticed, very quotable. I think there are other books in this
genre that offer more breadth or policy insight, but none that have the
same feel of someone cutting through the bullshit of lazy beliefs and
laying down some truth. If any of the above excerpts sound like the sort
of book you would enjoy reading, pick this one up.
Update 2020-10-19: All packages are now available in Debian/experimental!
More than a month has passed since my last KDE/Plasma for Debian update, but things are progressing nicely.
OBS packages
On the OBS side, I have updated the KDE Apps to 20.08.2, and the KDE Frameworks to 5.75. Especially the update of apps brings in at least a critical security fix.
Concerning the soon to be released Plasma 5.20, packages are more or less ready, but as reported here we have to wait for Qt 5.15 to be uploaded to unstable, which is also planned in the near future.
Debian main packages
Uploads of Plasma 5.19.4 to Debian/experimental are processing nicely, more than half the packages are already done, and the rest is ready to go. What holds us back is the NEW queue, as usual.
We (Scarlett, Patrick, me) hope to have everything through NEW and in experimental as soon as possible, followed by an upload of probably Plasma 5.19.5 to Debian/unstable.
Thanks also to Lisandro for accepting me into the Salsa Qt/KDE team.
This month for our book club Daniel, Lars, Vince and I read Hardcoded secrets, unverified tokens, and other common JWT mistakes which wasn’t quite what we’d thought when it was picked. We had been expecting an analysis of JSON web tokens themselves as several us had been working in the area and had noticed various talk about problems with the standard but instead the article is more a discussion of the use of semgrep to find and fix common issues, using issues with JWT as examples.
We therefore started off with a bit of a discussion of JWT, concluding that the underlying specification was basically fine given the problem to be solved but that as with any security related technology there were plenty of potential pitfalls in implementation and that sadly many of the libraries implementing the specification make it far too easy to make mistakes such as those covered by the article through their interface design and defaults. For example interfaces that allow interchangable use of public keys and shared keys are error prone, as is is making it easy to access unauthenticated data from tokens without clearly flagging that it is unauthenticated. We agreed that the wide range of JWT implementations available and successfully interoperating with each other is a sign that JWT is getting something right in providing a specification that is clear and implementable.
Moving on to semgrep we were all very enthusiastic about the technology, language independent semantic matching with a good set of rules for a range of languages available. Those of us who work on the Linux kernel were familiar with semantic matching and patching as implemented by Coccinelle which has been used quite successfully for years to both avoiding bad patterns in code and making tree wide changes, as demonstrated by the article it is a powerful technique. We were impressed by the multi-language support and approachability of semgrep, with tools like their web editor seeming particularly helpful for people getting started with the tool, especially in conjunction with the wide range of examples available.
This was a good discussion (including the tangential discussions of quality problems we had all faced dealing with software over the years, depressing though those can be) and semgrep was a great tool to learn about, I know I’m going to be using it for some of my projects.
Last year, my intent had been to post monthy updates with details of the F/LOSS
contributions I had made during the previous month. I wanted to do this as a
way to summarize and reflect on what I had done, and also to hopefully
motivate me to do more.
Fast forward, and it's been over a year since my last blog post. So much for
those plans.
I won't go into specific detail about the F/LOSS contributions I've made in the
past year. This isn't meant to be a "catch-up" post, per se. It's more of an
acknowledgement that I didn't do what I set out to do, as well as something
of a reset to enable me to continue blogging (or not) as I see fit.
So, to summarize those contributions:
As expected, most of my contributions were to projects that I regularly
contribute to, like Debian, Apache Axis2/C, or PasswordSafe.
There were also some one-off contributions to projects that I use but am not
actively involved in, such as log4cxx or PyKAN.
There was also a third category of contributions that are a bit of a special
case. I made some pseudonymous contributions to a F/LOSS project that I did
not want to tie to my public identity. I hope to write more about that
situation in a future post.
All in all, I'm pretty happy with the contributions I've made in the
past year. Historically, my F/LOSS activity had been somewhat sporadic,
sometimes with months passing in between contributions. But looking through
my notes from the past year, it appears that I made contributions every single
month, with no skipped months. Of course, I would have liked to have done more,
but I consider the improvement in consistency to be a solid win.
As for the blog, well... Judging by the most recent year-long gap (as well as
the gaps before that), I'm not likely to start regularly writing posts anytime
soon. But then again, if sporadic F/LOSS contribtutions can turn into
regular F/LOSS contributions, then maybe sporadic blog posts can turn into
regular blog posts, too. Time will tell.
Salsa CI aims at improving the Debian packaging lifecycle by delivering
Continuous Integration fully compatible with Debian packaging.
The main Salsa CI's project is the
pipeline, that builds
packages and run different tests after every git push to Salsa.
The pipeline makes it possible to have a quick and early feedback about any
issues the new changes may have created or solved, without the need to upload
to the archive.
All of the pipeline jobs run on amd64 architecture, but the Salsa CI Team has
recently added support to build packages also on i386 architecture.
This work started during the Salsa CI Sprint at DebConf20 after the
"Where is Salsa CI right now" talk,
and required different changes at the core of pipeline to make it possible.
For more details, this is the related merge request:
https://salsa.debian.org/salsa-ci-team/pipeline/-/merge_requests/256
If you have any questions, you can contact the Salsa CI Team at the #salsaci
channel on irc.oftc.net
So, a bit more thank 18 months ago, I started a new adventure.
After a few flights with a friend of mine in a Robin DR400 and
Jodel aircrafts, I enlisted in a local flight club at the Lognes
airfield (LFPL), and started a Pilot Private License training. A
PPL is an international flight license for non commercial
operations. Associated with a qualification like the SEP (Single
Engine Piston), it enables you to fly basically anywhere in the
world (or at least anywhere where French is spoken by the air
traffic controllers) with passengers, under Visual Flight Rules
(VFR).
A bit like with cars, training has two parts, theoretical and
practical, both validated in a test. You don't have to pass the
theoretical test before starting the practical training, and it's
actually recommended to do both in parallel, especially since
nowadays most of the theoretical training is done online (you still
have to do 10h of in-person courses before taking the test).
So in March 2019 I started both trainings. Theoretical training is
divided in various domains, like regulations, flight mechanics,
meteorology, human factors etc. and you can obviously train in
parallel. Practical is more sequential and starts with basic flight
training (turns, climbs, descents), then take-off, then landing
configuration, then landing itself. All of that obviously with a
flight instructor sitting next to you (you're on the left seat but
the FI is the “pilot in command”). You then start doing circuit
patterns, meaning you take off, do a circuit around the airfield,
then land on the runway you just took off. Usually you actually
don't do a complete landing but rather touch and go, and do it
again in order to have more and more landing training.
Once you know how to take-off, do a pattern and land when
everything is OK, you start practicing (still with your flight
instructor aboard) various failures: especially engine failures at
take off, but also flaps failure and stuff like that, all that
while still doing patterns and practicing landings. At one point,
the flight instructor deems you ready: he exits the plane, and you
start your first solo flight: engine tests, take off, one pattern,
landing.
For me practical training was done in an Aquila AT-01/A210, which
is a small 2-seater. It's really light (it can actually be used as
an ultralight), empty weight is a bit above 500kg and max weight is
750. It doesn't go really fast (it cruises at around 100 knots, 185
km/h) but it's nice to fly. As it's really lightweight the wind
really shakes it though and it can be a bit hard to land because it
really glides very well (with a lift-to-drag ratio at 14). I tried
to fly a lot in the beginning, so the basic flight training was
done in about 6 months and 23 flight hours. At that point my
instructor stepped out of the plane and I did my first solo flight.
Everything actually went just fine, because we did repeat a lot
before that, so it wasn't even that scary. I guess I will remember
my whole life, as people said, but it was pretty uneventful,
although the controller did scold me a little because when taxiing
back to the parking I misunderstood the instructions and didn't
stop where asked (no runway incursion though).
After the first solo flight, you keep practicing patterns and solo
flights every once in a while, and start doing cross-country
flights: you're not restricted to the local airfields (LFPL, LFAI,
LFPK) but start planning trips to more remote airports, about 30-40
minutes away (for me it was Moret/LFPU, Troyes/LFQB,
Pontoise/LFPT). Cross country flights requires you to plan the
route (draw it on the map, and write a navigation log so you know
what to do when in flight), but also check the weather, relevant
information, especially NOTAMs - Notice To Air Men (I hope someone
rename those Notice to Air Crews at one point), estimate the fuel
needed etc. For me, flight preparation time was between once and
twice the flight time. Early flight preparation is completed on the
day by last-minute checks, especially for weather. During the
briefing (with the flight instructor at first, but for the test
with the flight examiner and later with yourself) you check in turn
every bit of information to decide if you're GO or not for the
flight. As a lot of things in aviation, safety is really paramount
here.
Once you've practiced cross country flight a bit, you start
learning what to do in case of failures during a non-local flights,
for example an engine failure in a middle of nowhere, when you have
to chose a proper field to land, or a radio failure. And again when
you're ready for it (and in case of my local club, once you pass
your theoretical exam) you go for cross-country solo flights (of
the 10h of solo flight required for taking the test, 5h should be
done in cross-country flights). I went again to Troyes (LFQB), then
Dijon-Darois (LFGI) and did a three-legs flight to Chalons-Ecury
(LFQK) and Pont sur Yonne (LFGO).
And just after that, when I was starting to feel ready for the
test, COVID-19 lockdown happened, grounding everyone for a few
months. Even after it was over, I felt a bit rusty and had to take
some more training. I finally took the test in the beginning of
summer, but the first attempt wasn't good enough: I was really
stressed, and maybe not completely ready actually. So a bit more
training during summer, and finally in September I took the final
test part, which was successful this time.
After some paperwork, a new, shiny, Pilot Private License arrived
at my door.
And now that I can fly basically when I want, the autumn is finally
here with bad weather all day long, so actually planning real
flights is a bit tricky. For now I'm still flying solo on familiar
trips, but at some point I should be able to bring a passenger with
me (on the Aquila) and at some point migrate to a four-seaters like
the DR400, ubiquitous in France.
I grew up riding bikes with my friends, but I didn't keep it up once I went to
University. A couple of my friends persevered and are really good riders, even
building careers on their love of riding.
I bought a mountain bike in 2006 (a sort of "first pay cheque" treat after
changing roles) but didn't really ride it all that often until this year. Once
Lockdown began, I started going for early morning rides in order to get some
fresh air and exercise.
Once I'd got into doing that I decided it was finally time to buy a new bike.
I knew I wanted something more like a "hybrid" than a mountain bike but apart
from that I was clueless. I couldn't even name the top manufacturers.
Ross Burton—a friend from the Debian
community—suggested I take a look at Cotic, a small
UK-based manufacturer based in the peak district. Specifically their
Escapade
gravel bike. (A gravel bike, it turns out, is kind-of like a hybrid.)
My new Cotic Escapade
I did some due diligence, looked at some other options, put together a
spreadsheet etc but the Escapade was the clear winner. During the project I
arranged to have a socially distant cup of tea with my childhood friend Dan,
now a professional bike mechanic, who by coincidence arrived on his own Cotic
Escapade. It definitely seemed to tick all the boxes. I just needed to agonise
over the colour choices: Metallic Orange (a Cotic staple) or a Grey with some
subtle purple undertones. I was leaning towards the Grey, but ended up plumping
for the Orange.
I could just cover it under Red Hat UK’s cycle to work scheme. I’m very pleased
our HR dept is continuing to support the scheme, in these times when they also
forbid me from travelling to the office.
And so here we are. I’m very pleased with it! Perhaps I'll write more about
riding, or post some pictures, going forward.
One of the points Flanigan makes in her piece “Seat Belt Mandates and Paternalism” is that we’re conditioned to use seat belts from a very early age. It’s a thing we internalize and build into our understanding of the world. People feel bad when they don’t wear a seat belt.(1) They’re unsettled. They feel unsafe. They feel like they’re doing something wrong.
Masks have started to fit into this model as well. Not wearing a mask feels wrong. An acquaintance shared a story of crying after realizing they had left the house without a mask. For some people, mask wearing has been deeply internalized.
We have regular COVID tests at NYU. Every other week I spit into a tube and then am told whether I am safe or sick. This allows me to hang out with my friends more confident than I would feel otherwise. This allows me to be closer to people than I would be otherwise. It also means that if I got sick, I would know, even if I was asymptomatic. If this happened, I would need to tell my friends. I would trace the places I’ve been, the people I’ve seen, and admit to them that I got sick. I would feel shame because something I did put me in that position.
There were (are?) calls to market mask wearing and COVID protection with the same techniques we use around sex: wear protection, get tested, think before you act, ask consent before touching, be honest and open with the people around you about your risk factors.
This is effective, at least among a swath of the population, but COVID has effectively become another STD. It’s a socially transmitted disease that we have tabooified into creating shame in people who have it.
The problem with this is, of course, that COVID isn’t treatable in the same way syphilis and chlamydia are. Still, I would ask whether people don’t report, or get tested, or even wear masks, because of shame? In some communities, wearing a mask is a sign that you’re sick. It’s stigmatizing.(2)
I think talking about COVID the way we talk about sex is not the right approach because, in my experience, the ways I learned about sex were everything from factually wrong to deeply harmful. If what we’re doing doesn’t work, what does?
(1) Yes, I know not everyone.
(2) Many men who don’t wear masks cite it as feeling emasculating, rather than stigmatizing.
Here is the first QSoas quiz ! I recently measured several identical spectra in a row to evaluate the noise of the setup, and so I wanted to average all the spectra and also determine the standard deviation in the absorbances. Averaging the spectra can simply be done taking advantage of the average command:
QSoas> load Spectrum*.dat /flags=spectra
QSoas> average flagged:spectra
However, average does not provide means to make standard deviations, it just takes the average of all but the X column. I wanted to add this feature, but I realized there are already at least two distinct ways to do that...
One that relies simply on average and on apply-formula, and which requires that you remember how to compute standard deviations.
One that is a little more involved, that requires more data manipulation (take a look at contract for instance) and relies on the fact that you can use statistics in apply-formula (and in particular you can use y_stddev to refer to the standard deviation of \(y\)), but which does not require you to know exactly how to compute standard deviations.
To help you, I've added the result in Average.dat. The figure below shows a zoom on the data superimposed to the average (bonus points to find how to display this light red area that corresponds to the standard deviation !).
I will post the answer later. In the meantime, feel free to post your own solutions or attempts, hacks, and so on !
About QSoas
QSoas is a powerful open source data analysis program that focuses on flexibility and powerful fitting capacities. It is released under the GNU General Public License. It is described in Fourmond, Anal. Chem., 2016, 88 (10), pp 5050–5052. Current version is 2.2. You can download its source code or buy precompiled versions for MacOS and Windows there.
I don’t have to mention that 2020 is a special year, so all the normal race plan was out the window, and I was very happy and fortunate to be able to do even one race. And only delayed 3 weeks to write this race report :/ So, here’s the story ☺
Preparing for the race
Because it was a special year, and everything was crazy, I actually managed to do more sports than usual, at least up to end of July. So my fitness, and even body weight, was relatively fine, so I subscribed to the mid-distance race (official numbers: 78km distance, 1570 meters altitude), and then off it went to a proper summer vacation — in a hotel, even.
And while I did do some bike rides during that vacation, from then on my training regime went… just off? I did train, I did ride, I did get significant PRs, but it didn’t “click” anymore. Plus, due to—well, actually not sure what, work or coffee or something—my sleep regime also got completely ruined…
On top of that, I didn’t think about the fact that the race was going to be mid-September, and that high up in the mountains, the weather could have be bad enough (I mean, in 2018 the weather was really bad even in August…) such that I’d need to seriously think about clothing.
Race week
I arrive in Scuol two days before the race, very tired (I think I got only 6 hours of sleep the night before), and definitely not in a good shape. I was feeling bad enough that I was not quite sure I was going to race. At least weather was OK, such that normal summer clothing would suffice. But the race info was mentioning dangerous segments, to be very careful, etc. etc. so I was quite anxious.
Note 1: my wife says, this was not the first time, and likely not the last time that two days before the race I feel like quitting. And as I’m currently on-and-off reading the interesting “The Brave Athlete: Calm the Fuck Down and Rise to the Occasion” book (by Lesley Paterson and Simon Marshall; it’s an interesting book, not sure if I recommend it or not), I am beginning to think that this is my reaction to races where I have “overshot” my usual distance. Or, in general, races where I fear the altitude gain. Not quite sure, but I think it is indeed the actual cause.
So I spend Thursday evening feeling unwell, and thinking I’ll see how Friday goes. Friday comes, and having slept reasonably well entire night, I pick up my race number, then I take another nap in the afternoon - in total, I’ve slept around 13 hours that day. So I felt much better, and was looking forward to the race.
Saturday morning comes, I manage to wake up early, and get ready in time; almost didn’t panic at all that I’m going to be late.
Note 2: my wife also says that this is the usual way I behave. Hence, it must be most of it a mental issue, rather than real physical one ☺
Race
I reach the train station in time, I get on the train, and by the time the train reached Zernez, I fully calm down. There was am entire hour wait though before the race, and it was quite chilly. Of course I didn’t bring anything beside what I was wearing, relying on temperature getting better later in the day.
During the wait, there were two interesting things happening.
First, we actually got there (in Zernez) before the first people from the long distance passed by, both men and women. Seeing them pass by was cool, thinking they already had ~1’200m altitude in just 30-ish kilometres.
The second thing was, as this was the middle and not the shortest distance, the people in the group looked differently than in previous years. More precisely, they were looking very fit, and I was feeling… fat. Well, I am overweight, so it was expected, but I was feeling it even more than usual. I think only one or two in ten people were looking as fit as me or less… And of course, the pictures post-race show me even less “fit-looking” than I thought. Ah, self-deception is a sweet thing…
And yes, we all had to wear masks, up until the last minute. It was interesting, but not actually annoying - and small enough price for being able to race!
Then the race starts, and as opposed to many other years, it starts slow. I didn’t feel that rush of people starting fast, it was… reasonable?
First part of the race (good)
Thus started the first part of the race, on a new route that I was unfamiliar with. There was not too much climbing, to be honest, and there was some tricky single-trail through the woods, with lots of the roots. I actually had to get off the bike and push it, since it was too difficult to pedal uphill on that path. Other than that, I was managing so far to adjust my efforts well enough that my usual problems related to climbing (lower back pain) didn’t yet appear, even as the overall climbed meters were increasing. I was quite happy at that, and had lots of reserves. To my (pleasant) surprise, two positive things happened:
I was never alone, a sign that I wasn’t too far back.
I was passing/being passed by people, both on climbs but also on descents! It’s rare, but I did overtake a few people on a difficult trail downhill.
With all the back and forth, a few people became familiar (or at least their kit), and it was fun seeing who is better uphill vs. downhill.
And second part (not so good)
I finally get to (around) S-chanf, on a very nice but small descent, and on flat roads, and start the normal route for the short race. Something was off though - I knew from past years that these last ~47km have around 700-800m altitude, but I had already done around 1000m. So the promised 1571m were likely to be off, by at least 100-150m. I set myself a new target of 1700m, and adjust my efforts based on that.
And then, like clockwork on the 3:00:00 mark, the route exited the forest, the sun got out of the clouds, and the temperature started to increase from 16-17°C to 26°+, with peaks of 31°C. I’m not joking: at 2:58:43, temp was 16°, at 3:00:00, it was 18°, at 3:05:45, it was 26°. Heat and climbing are my two nemeses, and after having a pretty good race for the first 3 hours and almost exactly 1200m of climbing, I started feeling quite miserable.
Well, it was not all bad. There were some nice stretches of flat, where I knew I can pedal strongly and keep up with other people, until my chain dropped, so I had to stop, re-set it, and lose 2 minutes. Sigh.
But, at least, I was familiar with this race, or so I thought. I completely mis-remembered the last ~20km as a two-punch climb, Guarda and Ftan, whereas it is actually a three-punch one: Guarda, Ardez, and only then Ftan. Doesn’t help that Ardez has the nice ruins that I was remembering and which threw me off.
The saddest part of the day was here, on one of the last climbs - not sure if to Guarda or to Arddez, where a guy overtakes me, and tells me he’s glad he finally caught up with me, he almost got me five or six times (!), but I always managed to break off. Always, until now. Now, this was sad (I was huffing and puffing like a steam locomotive now), but also positive, as I never had that before. One good, one bad?
And of course, it was more than 1’700m altitude, it was 1’816m. And the descent to Scuol shorter and it didn’t end as usual with the small but sharp climb which I just love, due to Covid changes.
But, I finished, and without any actual issues, and no dangerous segments as far as I saw. I was anxious for no good reason…
Conclusion (or confusion?)
So this race was interesting: three hours (to the minute) in which I went 43.5km, climbed 1200m, felt great, and was able to push and push. And then the second part, only ~32km, climbed only 600m, but which felt quite miserable.
I don’t know if it was mainly heat, mainly my body giving up after that much climbing (or time?), or both. But it’s clear that I can’t reliably race for more than around these numbers: 3 hours, ~1000+m altitude, in >20°C temperature.
One thing that I managed to achieve though: except due to the technically complex trail at the beginning where I pushed the bike, I did not ever stop and push the bike uphill because I was too tired. Instead, I managed (badly) to do the switch sitting/standing as much as I could motivate myself, and thus continue pushing uphill. This is an achievement for me, since mentally it’s oh so easy to stop and push the bike, so I was quite glad.
As to the race results, they were quite atrocious:
age category (men), 38 out of 52 finishers, 4h54m, with first finisher doing 3h09m, so 50% slower (!)
overall (men), 138 out of 173 finishers, with first finisher 2h53m.
These results clearly don’t align with my feeling of a good first half of the race, so either it was purely subjective, or maybe in this special year, only really strong people registered for the race, or something else…
One positive aspect though, compared to most other years, was the consistency of my placement (age and overall):
Zuoz: 38 / 141
S-Chanf: 39 / 141
Zernez: 39 / 141
Guarda: 38 / 138
Ftan: 38 / 138
(“next” - whatever this is): 38 / 138
Finish: 38 / 138
So despite all my ranting above, and all the stats I’m pulling out of my own race, it looks like my position in the race was fully settled in the really first part, and I didn’t gain nor lose practically anything afterwards. I did dip one place but then gained it back (on the climb to Guarda, even).
The split times (per-segment rankings) are a bit more variable, and show that I was actually fast on the climbs but losing speed on the descents, which I really don’t understand anymore:
Zernez-Zuoz (unclear type): 38 / 141
Zuoz-S-Chanf (unclear type): 40 / 141
S-Chanf-Zernez (mostly downhill): 39 / 143
Zernez-Guarda (mostly uphill): 37 / 136
Guarda-Ftan (mostly uphill): 37 / 131
Ftan-Scuol (mostly downhill): 43 / 156
The difference at the end is striking. I’m visually matching the map positions to km and then use VeloViewer for computing the altitude gain, but Zernez to Guarda is 420m altitude, and Guarda to Ftan is 200m altitude gain, and yet on both, I was faster than my final place, and by quite a few places on overall, only to lose that on the descent (Ftan-Scuol), and by a large margin.
So, amongst all the confusion here, I think the story overall is:
indeed I was quite fit for me, so the climbs were better than my place in the race (if that makes sense).
however, I’m not actually good at climbing nor fit (watts/kg), so I’m still way back in the pack (oops!).
and I do suck at descending, both me (skills) and possible my bike setup as well (too high tyre pressure, etc.) so I lose even more time here…
As usual, the final take-away points are: lose the extra weight that is not needed, get better skills, get better core to be better at climbing.
I’ll finish here with one pic, taken in Guarda (4 hours into the race, more or less):
This month I accepted 278 packages and rejected 58. The overall number of packages that got accepted was 304.
Debian LTS
This was my seventy-fifth month that I did some work for the Debian LTS initiative, started by Raphael Hertzog at Freexian.
This month my all in all workload has been 19.75h. During that time I did LTS uploads of:
[DLA 2382-1] curl security update for one CVE
[DLA 2383-1] nfdump security update for two CVEs
[DLA 2384-1] yaws security update for two CVEs
I also started to work on new issues of qemu but had to learn that most of the patches I found have not yet been approved by upstream. So I moved on to python3.5 and cimg. The latter is basically just a header file and I had to find its reverse dependencies to check whether all of them can still be built with the new cimg package. This is still WIP and I hope to upload new versions soon.
Last but not least I did some days of frontdesk duties.
Debian ELTS
This month was the twenty seventh ELTS month.
During my allocated time I uploaded:
ELA-284-1 for curl
ELA-288-1 for libxrender
ELA-289-1 for python3.4
Like in LTS, I also started to work on qemu and encountered the same problems as in LTS above.
When building the new python packages for ELTS and LTS, I used the same VM and encountered memory problems that resulted in random tests failing. This was really annoying as I spent some time just chasing the wind. So up to now only the LTS package got an update and the ELTS one has to wait for October.
Last but not least I did some days of frontdesk duties.
Other stuff
This month I only uploaded some packages to fix bugs:
Welcome to the September 2020 report from the Reproducible Builds project. In our monthly reports, we attempt to summarise the things that we have been up to over the past month, but if you are interested in contributing to the project, please visit our main website.
This month, the Reproducible Builds project was pleased to announce a donation from Amateur Radio Digital Communications (ARDC) in support of its goals. ARDC’s contribution will propel the Reproducible Builds project’s efforts in ensuring the future health, security and sustainability of our increasingly digital society. Amateur Radio Digital Communications (ARDC) is a non-profit which was formed to further research and experimentation with digital communications using radio, with a goal of advancing the state of the art of amateur radio and to educate radio operators in these techniques. You can view the full announcement as well as more information about ARDC on their website.
The Threema privacy and security-oriented messaging application announced that “within the next months”, their apps “will become fully open source, supporting reproducible builds”:
This is to say that anyone will be able to independently review Threema’s security and verify that the published source code corresponds to the downloaded app.
The previous year has seen great progress in Arch Linux to get reproducible builds in the hands of the users and developers. In this talk we will explore the current tooling that allows users to reproduce packages, the rebuilder software that has been written to check packages and the current issues in this space.
During the Reproducible Builds summit in Marrakesh, GNU Guix, NixOS and Debian were able to produce a bit-for-bit identical binary when building GNU Mes, despite using three different major versions of GCC. Since the summit, additional work resulted in a bit-for-bit identical Mes binary using tcc and this month, a fuller update was posted by the individuals involved.
Last month, an issue was identified where a large number of Debian .buildinfo build certificates had been ‘tainted’ on the official Debian build servers, as these environments had files underneath the /usr/local/sbin directory to prevent the execution of system services during package builds. However, this month, Aurelien Jarno and Wouter Verhelst fixed this issue in varying ways, resulting in a special policy-rcd-declarative-deny-all package.
diffoscope is our in-depth and content-aware diff utility that can not only locate and diagnose reproducibility issues, it provides human-readable diffs of all kinds too.
In September, Chris Lamb made the following changes to diffoscope, including preparing and uploading versions 159 and 160 to Debian:
New features:
Show “ordering differences” only in strings(1) output by applying the ordering check to all differences across the codebase. […]
Bug fixes:
Mark some PGP tests that they require pgpdump, and check that the associated binary is actually installed before attempting to run it. (#969753)
Don’t raise exceptions when cleaning up after guestfs cleanup failure. […]
Ensure we check FALLBACK_FILE_EXTENSION_SUFFIX, otherwise we run pgpdump against all files that are recognised by file(1) as data. […]
Codebase improvements:
Add some documentation for the EXTERNAL_TOOLS dictionary. […]
Abstract out a variable we use a couple of times. […]
Also include the general news in our RSS feed […] and drop including weekly reports from the RSS feed (they are never shown now that we have over 10 items) […].
Update ordering and location of various news and links to tarballs, etc. […][…][…]
In addition, Holger Levsen re-added the documentation link to the top-level navigation […] and documented that the jekyll-polyglot package is required […]. Lastly, diffoscope.org and reproducible-builds.org were transferred to Software Freedom Conservancy. Many thanks to Brett Smith from Conservancy, Jérémy Bobbio (lunar) and Holger Levsen for their help with transferring and to Mattia Rizzolo for initiating this.
Upstream patches
The Reproducible Builds project detects, dissects and attempts to fix as many currently-unreproducible packages as possible. We endeavour to send all of our patches upstream where appropriate. This month, we wrote a large number of these patches, including:
The Reproducible Builds project operates a Jenkins-based testing framework to power tests.reproducible-builds.org. This month, Holger Levsen made the following changes:
Highlight important bad conditions in colour. […][…]
Add support for detecting more problems, including Jenkins shutdown issues […], failure to upgrade Arch Linux packages […], kernels with wrong permissions […], etc.
Misc:
Delete old schroot sessions after 2 days, not 3. […]
In addition, stefan0xC fixed a query for unknown results in the handling of Arch Linux packages […] and Mattia Rizzolo updated the template that notifies maintainers by email of their newly-unreproducible packages to ensure that it did not get caught in junk/spam folders […]. Finally, build node maintenance was performed by Holger Levsen […][…][…][…], Mattia Rizzolo […][…] and Vagrant Cascadian […][…][…].
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:


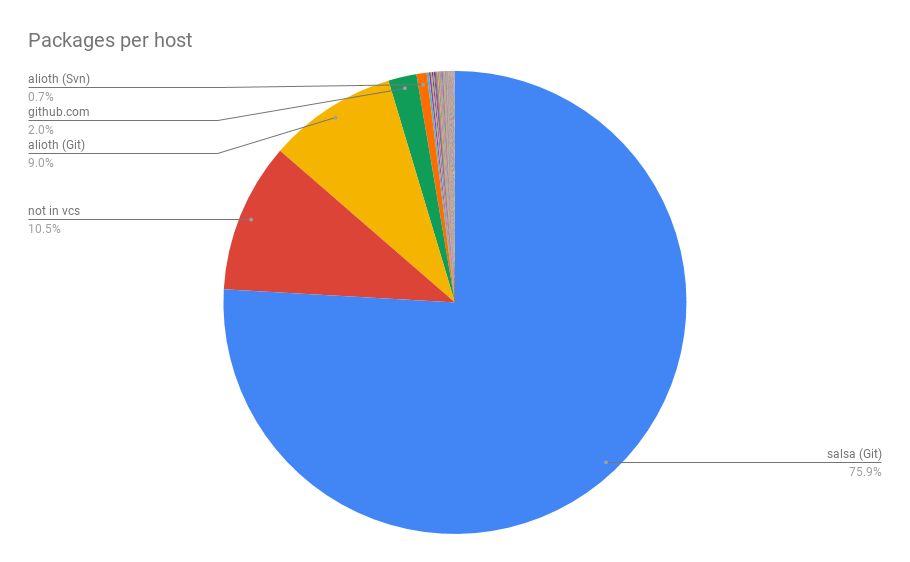


















 Like
Like