Most content-based websites, like Yahoo News, HuffPost, or any given news site, organize their stories according to subject matter or in some similar way. You can imagine that websites with a huge amount of stories must need an automated method to filter or categorize them as the content is ingested into their systems. For example, algorithms that power Yahoo News label news articles with tags (e.g., Military conflict, Nuclear policy, Refugees) as they are ingested, and then display the content by subject matter and/or on a personalized feed. This well-known process of labeling content with all its relevant tags is known as Multilabel Learning (MLL).
An overview of a MLL system in action: as the news articles are ingested, MLL tags them with all the relevant labels.
Up to now, whenever scientists and engineers use MLL to create their own specific models to label content however they like, they have used datasets that have pre-computed features like bag-of-words, or dense representations like doc2vec. In the process of writing our recent ACL 2017 publication “DocTag2Vec: An embedding based Multilabel Learning approach for Document Tagging,” presented in the Rep4NLP workshop, we compiled a novel dataset with raw news stories that allows for researchers to be able to construct their own features that are best-suited for their MLL algorithms. As part of our Webscope data-sharing program, we are making our dataset, called Yahoo News Ranked Multi-label Corpus (YNMLC), available to academics to further advance MLL research.
While traditional MLL approaches rely on given features, DocTag2Vec operates on raw text and automatically learns the best features of that text by embedding both documents and the tags in the same vector space. Inference is then done via a simple nearest-neighbor based approach. DocTag2Vec relies on training data that is composed of the raw text of every document and the labels associated with them.
DocTag2Vec embeds documents and the labels associated with them in a common vector-space. This allows inference by a nearest-neighbor approach.
There are many standard datasets available for MLL, but all of them directly provide features and not the actual text of the documents. This allows researchers to work on new algorithms that directly use the provided features but without improving the features themselves. Our YNMLC corpus provides raw text so that researchers can extract their own features that are best for their algorithms. Apart from that, to the best of our knowledge, our corpus is the only one that provides a ranking of the labels for each document in terms of its importance. YNMLC is one of the few large-scale, expertly manually-labeled (by Yahoo News editors) datasets addressing the task of MLL. The corpus contains 48,968 articles that are tagged by any subset of 413 labels. These tags correspond to Vibes (akin to topics) in the Yahoo Newsroom app.
MLL is an area of research that we have applied to labeling news stories. MLL can also be used to label music, videos, blog posts, and virtually any other type of online content. We look forward to seeing the innovative ways in which YNMLC will be used to develop new approaches.
Please cite the following paper if you are using this dataset for academic purposes:
“DocTag2Vec: An embedding based Multilabel Learning approach for Document Tagging”, The 2nd Workshop on Representation Learning for NLP, 2017. Sheng Chen, Akshay Soni, Aasish Pappu, and Yashar Mehdad.
By Edward Bortnikov, Anastasia Braginsky, and Eshcar Hillel
Modern products powered by NoSQL key-value (KV-)storage technologies exhibit ever-increasing performance expectations. Ideally, NoSQL applications would like to enjoy the speed of in-memory databases without giving up on reliable persistent storage guarantees. Our Scalable Systems research team has implemented a new algorithm named Accordion, that takes a significant step toward this goal, into the forthcoming release of Apache HBase 2.0.
HBase, a distributed KV-store for Hadoop, is used by many companies every day to scale products seamlessly with huge volumes of data and deliver real-time performance. At Yahoo, HBase powers a variety of products, including Yahoo Mail, Yahoo Search, Flurry Analytics, and more. Accordion is a complete re-write of core parts of the HBase server technology, named RegionServer. It improves the server scalability via a better use of RAM. Namely, it accommodates more data in memory and writes to disk less frequently. This manifests in a number of desirable phenomena. First, HBase’s disk occupancy and write amplification are reduced. Second, more reads and writes get served from RAM, and less are stalled by disk I/O. Traditionally, these different metrics were considered at odds, and tuned at each other’s expense. With Accordion, they all get improved simultaneously.
We stress-tested Accordion-enabled HBase under a variety of workloads. Our experiments exercised different blends of reads and writes, as well as different key distributions (heavy-tailed versus uniform). We witnessed performance improvements across the board. Namely, we saw write throughput increases of 20% to 40% (depending on the workload), tail read latency reductions of up to 10%, disk write reductions of up to 30%, and also some modest Java garbage collection overhead reduction. The figures below further zoom into Accordion’s performance gains, compared to the legacy algorithm.
Figure 1. Accordion’s write throughput compared to the legacy implementation. 100GB dataset, 100-byte values, 100% write workload. Zipf (heavy-tailed) and Uniform primary key distributions.
Figure 3. Accordion’s disk I/O compared to the legacy implementation. 100GB dataset, 100-byte values, 100% write workload. Zipf key distribution.
Accordion is inspired by the Log-Structured-Merge (LSM) tree design pattern that governs HBase storage organization. An HBase region is stored as a sequence of searchable key-value maps. The topmost is a mutable in-memory store, called MemStore, which absorbs the recent write (put) operations. The rest are immutable HDFS files, called HFiles. Once a MemStore overflows, it is flushed to disk, creating a new HFile. HBase adopts multi-versioned concurrency control – that is, MemStore stores all data modifications as separate versions. Multiple versions of one key may therefore reside in MemStore and the HFile tier. A read (get) operation, which retrieves the value by key, scans the HFile data in BlockCache, seeking the latest version. To reduce the number of disk accesses, HFiles are merged in the background. This process, called compaction, removes the redundant cells and creates larger files.
LSM trees deliver superior write performance by transforming random application-level I/O to sequential disk I/O. However, their traditional design makes no attempt to compact the in-memory data. This stems from historical reasons: LSM trees were designed in the age when RAM was in very short supply, and therefore the MemStore capacity was small. With recent changes in the hardware landscape, the overall MemStore size managed by RegionServer can be multiple gigabytes, leaving a lot of headroom for optimization.
Accordion reapplies the LSM principle to MemStore in order to eliminate redundancies and other overhead while the data is still in RAM. The MemStore memory image is therefore “breathing” (periodically expanding and contracting), similarly to how an accordion bellows. This work pattern decreases the frequency of flushes to HDFS, thereby reducing the write amplification and the overall disk footprint.
With fewer flushes, the write operations are stalled less frequently as the MemStore overflows, and as a result, the write performance is improved. Less data on disk also implies less pressure on the block cache, higher hit rates, and eventually better read response times. Finally, having fewer disk writes also means having less compaction happening in the background, i.e., fewer cycles are stolen from productive (read and write) work. All in all, the effect of in-memory compaction can be thought of as a catalyst that enables the system to move faster as a whole.
Accordion currently provides two levels of in-memory compaction: basic and eager. The former applies generic optimizations that are good for all data update patterns. The latter is most useful for applications with high data churn, like producer-consumer queues, shopping carts, shared counters, etc. All these use cases feature frequent updates of the same keys, which generate multiple redundant versions that the algorithm takes advantage of to provide more value. Future implementations may tune the optimal compaction policy automatically.
Accordion replaces the default MemStore implementation in the production HBase code. Contributing its code to production HBase could not have happened without intensive work with the open source Hadoop community, with contributors stretched across companies, countries, and continents. The project took almost two years to complete, from inception to delivery.
Accordion will become generally available in the upcoming HBase 2.0 release. We can’t wait to see it power existing and future products at Yahoo and elsewhere.
Comment threads following online news articles often range from vacuous to hateful. That said, good conversations do occur online, with people expressing different viewpoints and attempting to inform, convince, or better understand the other side, even if they can get lost among the multitude of unconstructive comments. At Yahoo Research, we show in recent statistical experiments that automatically identifying and ranking good conversations on top will cultivate a more civil and constructive atmosphere in online communities and potentially encourage participation from more users [1].
In an effort to foster more respectful online discussions and encourage more research among academics surrounding comments, we present the Yahoo News Annotated Comments Corpus (YNACC) via our data sharing program, Webscope. The corpus contains 522K comments from 140K comment threads posted in response to online news articles, and contains manual annotations for a subset of 2.4K comment threads and 9.2K comments. The annotations include 6 attributes of individual comments: sentiment, tone, agreement with other commenters, topic of the comment, intended audience, and persuasiveness. The annotations also include 3 attributes of threads: constructiveness, agreeability within the conversation, and type of conversation, i.e., flamewars vs positive/respectful [2].
Annotated conversations in the YNACC corpus were used to create a predictive algorithm and train statistical models to automatically detect “good” conversations. We call these good conversations ERICs: Engaging, Respectful, and/or Informative Conversations, and they are characterized by:
A respectful exchange of ideas, opinions, and/or information in response to a given topic or topics.
Opinions expressed as an attempt to elicit a dialogue or persuade.
Comments that seek to contribute some new information or perspective on the relevant topic.
Example of an ERIC conversation (top) and a non-ERIC conversation (bottom)
ERICs have no single identifying attribute. A good conversation is determined by how many respectful, engaging, and persuading comments are present. For instance, an exchange where communicants are in total agreement throughout can be an ERIC, as can an exchange with a heated disagreement. Our algorithm ranks either of these types of exchanges higher than those that lack ERICs. Many of the labels for the ERICs in our dataset are the result of a new coding scheme (annotation taxonomy) we developed and are for characteristics of online conversations not captured by traditional argumentation or dialogue features. Some of the labels we collected have been annotated in previous work [3,4], and this is the first time they are aggregated in a single corpus at the dialogue level.
Additionally, we collected annotations on 1K threads from the Internet Argument Corpus, representing another domain of online debates. Our corpus and annotation scheme is the first exploration of how characteristics of individual comments contribute to the dialogue-level classification of an exchange. We hope YNACC will facilitate research to understand ERICs and other aspects of dialogue in general.
The technical contributions of this dataset are described in two scientific papers:
[3] Rob Abbott, Brian Ecker, Pranav Anand, and Marilyn Walker. Internet Argument Corpus 2.0: An SQL schema for dialogic social media and the corpora to go with it. LREC 2016.
[4] Marilyn Walker, Jean Fox Tree, Pranav Anand, Rob Abbott, and Joseph King. A corpus for research on deliberation and debate. LREC 2012.
The Yahoo Mail Mining team in Haifa is publishing two research papers in the proceedings of the 26th International World Wide Web Conference in Perth, Australia this week. These publications, discussed in this blog post, will be presented in a track dedicated to the growing field of email and personal search. We would like to encourage the growth and adoption of research in this field by sharing some of our insights and spurring new ideas.
How many times have you tried to search for an email and not been able to find it? You might think that getting the right email search result is as easy as getting a good search result on the Web, where you often find what you’re looking for on the first try. Unfortunately, experience tells us otherwise. The reason? Mail search is, perhaps surprisingly, an entirely different animal. At Yahoo Research, we’ve been working hard at changing this situation.
When searching your mailbox, you are typically looking for a message that you have received and most probably read. You try to remember the name of the person who sent it to you or some distinctive words in the message. In other words, you try to re-find a given message, while in Web search, by contrast, you try to discover new information. In information retrieval, the computer science discipline behind search, this difference is reflected in two measures: recall (optimally “all the truth” – or in practice, the fraction of true instances that are retrieved), and precision (optimally “nothing but the truth” – or in practice, the fraction of retrieved instances that are true). One known mathematical evidence of these metrics is that increasing one automatically decreases the other. Web search targets precision as it draws from a large pool of potentially relevant results, and the searchers do not know and do not care if some relevant results are omitted as long as they get a sufficient answer. By contrast, mail search targets recall, as users know with certainty when the search results miss the messages they want.
Since users want to make sure they do not miss anything when performing a mail search, they expect their results to be sorted by time so as to scan all results in a systematic manner and maintain an illusion of perfect recall. Unfortunately, by doing so, they impose hard challenges on the search mechanism, which is forced to impose strict relevance constraints on the results returned to the user. This is necessary because otherwise, a remotely relevant, yet very recent message could be pushed to the top of the list. In other words, the time-sort view of results users expect imposes high precision constraints. This then negatively impacts recall, which is what users really care about. Catch 22!
By analyzing search behavior, we have discovered that mail users don’t use search as precisely as intended. We have seen that in 40% of the cases where a user performs a search, they don’t really search. Instead, they actually browse by issuing a “contact query” (i.e. a query that simply consists of a contact name) and then scanning the results. Even non-contact queries remain very vague, with an average length of 1.5 search terms. This again highlights the filtering/browsing behavior of Mail users. The two charts below represent search usage stats based on Yahoo Web Mail traffic.
Given that email is critical to so many people, we feel it is important to make sure all of our 225M monthly active Yahoo Mail users are getting the best experience possible. With our users in mind, the Yahoo Mail Mining Research team has adopted two different approaches to achieve improved precision and recall, making email search more effective. The first focuses on search results and second on search queries.
Focusing on the results
We have developed a first of its kind ranking algorithm [1] that ranks results by relevance rather than by time sent or received. That way, users are able to efficiently find the messages they are searching for, even if they are not very recent. This relevance ranking algorithm is based on a varied set of features, taking into account every signal that could imply the relevance of a message to a query. Included in the features are those based on the query-message similarity, the message recency, and the message itself (its links, attachments, etc.). Additionally, our algorithm takes into account actions performed on a message. For example, if you “star” a message, it will increase its relevance. However, if you haven’t opened it at all, its relevance will be lessened.
The table below represents the increase obtained in mean reciprocal rank (a.k.a., MRR, one of the most popular metrics in search, based on the average rank of the clicked message), comparing relevance ranking to time ranking, as well as the influence of the different set of features.
Figure 2: Performance of relevance ranking vs. time ranking (lift %)
Our ranking algorithm can display search results in order of relevance, as opposed to reverse chronological order. Consequently, it greatly relaxes strict match constraints, thereby increasing recall by having the most-relevant results at the top and less relevant results – typically missed altogether in the sort-by-time paradigm – still included down the list.
However, we understand that most users may not immediately be open to this revolutionary shift, and will still expect results ranked by time to reinforce their perception of perfect recall. With this in mind, we recently released an intermediate step for presenting search results in which we promote a small number of the most-relevant results on top of the standard time-sorted results. We refer to the top results as heroes, and the research and algorithm supporting our method are detailed in our paper [2] at the 26th International World Wide Web Conference (WWW ‘17) in Perth, Australia. Heroes target precision while the traditional ranked-by-time results target recall; having these two types of results coexist allows us to solve our catch 22 dilemma.
Figure 3: Heroes (appearing as ‘Top results’ in Yahoo desktop mail)
The chart below is based on an online evaluation of the implementation of the heroes feature. Our evaluation demonstrates a lift of 12% in MRR in Yahoo Web mail.
Figure 4: Performance of heroes model vs. traditional time ranking
Focusing on the queries
If we want the quality of search results to improve, we first need users to issue more specific queries and stop entering one-word queries followed by browsing. With such underspecified queries, even the best relevance algorithm we can invent will bring only limited benefits. So we need to assist users in formulating queries and bring them the results they seek faster. The existing query-assistance mechanism in Yahoo Mail today does a beautiful job with contact suggestions (through our Xobni technology) and also leverages past queries from a user’s search history. However, this technology is not sufficient to increase the length of queries and make them more precise.
To improve this situation, we have developed a novel query auto-completion module that takes as input a few characters or words entered by users (a prefix) and offers a list of suggested queries that are generated from three sources: their query log (search history), the content of their mailbox, and the general query log of all users. Moreover, when generating queries based on the general query log, we take into account various demographic attributes of the user such as gender, age, and location, based on the intuition that queries from “users like me” have more of a chance to be relevant to my personal mailbox. For example, the query prefix “sch” typed by a 30-year-old professional from New York might refer to “schedule,” while the same prefix typed by a student from San Francisco might refer to “scholarship.” Or, when typing “Be,” the professional intended “Best Buy,” while the student had the intention of typing “Berkeley.” The algorithm we designed to surface suggestions allows a user to search in a perhaps more precise of a manner than they would have otherwise, thereby helping to exploit the full capacities of the mail search system. Our research paper on query auto-completion [3], including a thorough analysis of the demographics of mail search, will also be published at WWW ‘17.
The combination of all these signals improves the quality of the suggestions by up to 150% when considering the average rank of the clicked suggestion. When splitting the queries according to types (personal contacts, names of companies, general content), the contribution of the general query log is the highest for queries relating to companies/organizations. Examples of this include Amazon or United, where a user typically searches for their last Amazon purchase or upcoming United Airlines flight. The mail traffic originating from a company is usually formatted very similarly for all users; my Amazon purchase notification will look very similar to yours, and the same goes for our flight itineraries if we both booked with United. Thus, it follows that we probably also search for those items in a similar manner.
Figure 5: Word clouds of discriminative queries. Top: men (left) vs. women (right). Bottom: young (left) vs. senior citizens (right).
Both our results-focused and query-focused approaches improve search results and serve to encourage users to search better and more often. These improvements are critical for users to trust that they can retrieve the messages they are looking for since they won’t get lost under a pile of less-relevant search results. This is important, because using the search function is the most efficient way to retrieve data; active users have a large amount of important information in their mailbox they want to regularly retrieve, and most of them do not use folders or other means of organizing their messages. In fact, we know that only 30% of our users create folders, and of those people, only 10% actually use them. In other words, for most users, search is the only way to re-find a message.
As we move forward to improve this effort, we continue to look at all aspects of mail – both on the algorithmic side, by analyzing not only messages, but also attachments, links, photos, invites, and so on; and on the user experience side – to better understand our users’ behaviors and make sure we answer their true, rather than perceived, needs.
Acknowledgements:
This multiple-year work has been published at several top conferences in the last few years and we are grateful to all our co-authors who not only invested so much efforts in this research but published about it: David Carmel, Guy Halawi, Alex Libov, and Ariel Raviv.
A huge thanks to the entire Yahoo Mail engineering and product team. The list of our friends and colleagues there is too long to be fully listed here but nothing would not have happened without their extraordinary support and partnership.
The mail experience has not evolved much in the last few decades as compared to other communication channels. At the same time, personal communications have exploded with the advent and growth of numerous new communication and social networking apps. This might lead you to believe mail is on its way to a slow death. We beg to differ.
As messaging, video chatting, and other social networking methods have reached adolescence, mail has entered its mid-life (without the crisis) while its traffic has significantly changed and evolved. A new type of mail traffic has emerged with the rise of online transactions, including online purchases, financial transactions, travel plans, event notifications, and many others. As a result, the Web mail domain has become dominated by what we call “machine-generated” messages; that is, emails that are generated (usually by companies) via scripts rather than by humans. Following this essential observation, it makes sense that you might want to be able to distinguish traffic generated by machines from that generated by humans. The use cases are numerous: from being able to provide views gathering similar types of messages (personal, travel, purchases, etc.) as surfaced recently in Yahoo Mail (see Figure 1) and Gmail, to being able to provide a user experience tailored to the type of email you are looking at (e.g., you wouldn’t want to provide a “reply” option to a “noreply@” machine-generated address).
Figure 1: Yahoo Mail “Smart Views” – here users can explore emails that are automatically categorized by topic
At Yahoo Research, we have developed a new classifying technology that distinguishes between human- and machine-generated mail. This “Human/Machine” classifier is based on a wide range of features, such as:
sender and traffic characteristics – a machine can generate large traffic bursts sent to a large number of recipients, while a human cannot
semantic attributes – various keywords repeating in machine-generated traffic of all types
structural attributes – messages generated by machines typically have complex HTML structures, while those composed by human are rather flat
Our classifier now achieves a performance of 90% precision and 90% recall for both categories. This means that 90% of the messages actually composed by human beings are indeed classified as “human,” and out of those classified as “human,” we are correct in 90% of the cases. The same goes for machines.
Given the high degree of accuracy with which we can distinguish between the two types of email traffic, we felt confident launching people-only notifications in Yahoo Mail across all platforms. This new feature (see Figure 2) allows you to get “people-only” notifications. In other words, you can turn on the option to receive a notification only when a person emails you, or you can turn it off and receive a notification for any new incoming message.
While our users have said they enjoy the “people only” feature, what really excites us on the Yahoo Mail Mining team in Haifa, is the opportunity presented by machine-generated emails. We know that machines account for 90% of all mail traffic [4]. These machine-generated messages, whether they are purchase receipts, flight reservations, or something else, contain loads of personal information. So in many ways, the mailbox serves as a personal data store. Unpacking that data in a meaningful way presents an incredible opportunity to advance the mail experience for our users.
Machine-Generated Mail Mining
This line of research, based on the difference between human- and machine-generated mail traffic, was initiated when we investigated better means of mail classification [4][6] and has served different use cases in recent years [3][5], including mail anonymization [2]. Today, it mainly serves automatic mail extraction [1]. With mail extraction, what we attempt to achieve is an automated way of extracting the “personalized” (and thus more meaningful to the user) parts of messages created by automated scripts; more specifically, those parts that are either of high interest to you (the items you purchased, their date of delivery, the details of your trip, etc.), or those that have a business value (e.g., the advertisements we surface). Anonymization techniques that we developed precisely for machine-generated traffic (see Figure 3) allow us to preserve a user’s privacy [2] and adhere to formal PII terms of service.
Figure 3: Anonymized mail sample showing extraction fields
Mail extraction is a process composed of two main phases: clustering the messages and extracting the data. Why do we cluster before extracting? Because if clustered correctly, a single extraction rule can be applied over an entire cluster, and therefore needs to be defined only once per cluster.
Clustering
Clustering mail messages is performed horizontally, exploiting the similarities of machine-generated messages sent en masse with (usually) complex HTML structures. Using the recurrent characteristics of these messages, clusters are created, optimally matching the scripts generating the messages. Previous clustering techniques relied only on the message header [5] and mainly looked for similarities in the messages’ subjects. Today, the state-of-the-art clustering techniques rely on the body of messages (i.e., their structures) [1][2]. These techniques detect similarities in the HTML structure of the messages and allow for flexible matching, including some small differences in the structure. More flexible clustering results in fewer clusters and ease processes that require some maintenance or human intervention.
Figure 4: Cluster of Amazon purchase confirmations
Figure 5: A chart representing the distribution of clusters between different categories
Figure 6: Level of structural flexibility that can be allowed, while still guaranteeing high extraction quality (flexibility represented by edit distance)
Extractions
Once the clusters have been created, and we have guaranteed that all messages within a cluster are similar with regard to structure, we can move on to our next phase: mail extraction. Currently at Yahoo, some manual work is involved in defining extraction rules for interpreting some pieces of messages and for validating parts of the process. Extraction rules are defined per cluster and are applied online for each message entering the system after identifying the cluster to which it belongs.
The fact that mail extraction requires some interpretability during intermediate phases of its cycle is a bottleneck, which prevents scalability and coverage of the long tail. A fully-automated method for creating extraction rules that cover all machine-generated traffic is in the advance stages of development. Our process is based on the similarity of messages guaranteed by the cluster, which is a crucial attribute used for identifying and annotating the pieces of information we want to extract. Figure 7 below is an example of a rule created automatically. It is defined over an Xpath [7], where an Xpath is simply a pointer to a specific location in the message. This rule defines the fields of interest to be extracted from this location and provides their full annotations.
Figure 7: An extraction rule
As we continue to develop our machine-generated mail mining techniques, we hope to broaden our approach and share this research in an effort to encourage others to do the same. As a domain that has significantly changed its nature in recent years, mail deserves a reexamination of its scientific foundation and more attention within the research community.
Acknowledgements:
This multiple-year work has been published at several top conferences in the last few years and we are grateful to all our co-authors who not only invested so much effort in this research, but also published about it:
Nir Ailon, Noa Avigdor-Elgrabli, Marc Cwalinski, Dotan DiCastro, Iftah Gamzu, Ira Grabovitch-Zuyev, Mihajlo Grbovic, Guy Halawi, Yehuda Koren, Zohar Karnin, Edo Liberty, Roman Sandler, David Wajc, Ran Wolff, and Eyal Zohar.
A huge thanks to the entire Yahoo Mail engineering and product team. The list of our friends and colleagues there is too long to be fully listed here but this couldn’t have happened without their extraordinary support and partnership.
References:
[1] Noa Avigdor-Elgrabli, Mark Cwalinskiy, Dotan Di Castro, Iftah Gamzu, Irena Grabovitch-Zuyev, Liane Lewin-Eytan, Yoelle Maarek. Structural Clustering of Machine-Generated Mail. CIKM 2016.
At Yahoo, our Computer Vision team works closely with Flickr, one of the world’s largest photo-sharing communities. The billions of photos hosted by Flickr allow us to tackle some of the most interesting real-world problems in image and video understanding. One of those major problems is that of discovery. We understand that the value in our photo corpus is only unlocked when the community can find photos and photographers that inspire them, so we strive to enable the discovery and appreciation of new photos.
To further that effort, today we are introducing similarity search on Flickr. If you hover over a photo on a search result page, you will reveal a “…” button that exposes a menu that gives you the option to search for photos similar to the photo you are currently viewing.
In many ways, photo search is very different from traditional web or text search. First, the goal of web search is usually to satisfy a particular information need, while with photo search the goal is often one of discovery; as such, it should be delightful as well as functional. We have taken this to heart throughout Flickr. For instance, our color search feature, which allows filtering by color scheme, and our style filters, which allow filtering by styles such as “minimalist” or “patterns,” encourage exploration. Second, in traditional web search, the goal is usually to match documents to a set of keywords in the query. That is, the query is in the same modality—text—as the documents being searched. Photo search usually matches across modalities: text to image. Text querying is a necessary feature of a photo search engine, but, as the saying goes, a picture is worth a thousand words. And beyond saving people the effort of so much typing, many visual concepts genuinely defy accurate description. Now, we’re giving our community a way to easily explore those visual concepts with the “…” button, a feature we call the similarity pivot.
The similarity pivot is a significant addition to the Flickr experience because it offers our community an entirely new way to explore and discover the billions of incredible photos and millions of incredible photographers on Flickr. It allows people to look for images of a particular style, it gives people a view into universal behaviors, and even when it “messes up,” it can force people to look at the unexpectedcommonalities and oddities of our visual world with a freshperspective.
What is “similarity?”
To understand how an experience like this is powered, we first need to understand what we mean by “similarity.” There are many ways photos can be similar to one another. Consider some examples.
It is apparent that all of these groups of photos illustrate some notion of “similarity,” but each is different. Roughly, they are: similarity of color, similarity of texture, and similarity of semantic category. And there are many others that you might imagine as well.
What notion of similarity is best suited for a site like Flickr? Ideally, we’d like to be able to capture multiple types of similarity, but we decided early on that semantic similarity—similarity based on the semantic content of the photos—was vital to wholly facilitate discovery on Flickr. This requires a deep understanding of image content for which we employ deep neural networks.
We have been using deep neural networks at Flickr for a while for various tasks such as object recognition, NSFW prediction, and even prediction of aesthetic quality. For these tasks, we train a neural network to map the raw pixels of a photo into a set of relevant tags, as illustrated below.
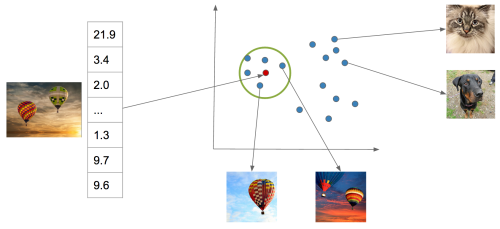
Internally, the neural network accomplishes this mapping incrementally by applying a series of transformations to the image, which can be thought of as a vector of numbers corresponding to the pixel intensities. Each transformation in the series produces another vector, which is in turn the input to the next transformation, until finally we have a vector that we specifically constrain to be a list of probabilities for each class we are trying to recognize in the image. To be able to go from raw pixels to a semantic label like “hot air balloon,” the network discards lots of information about the image, including information about appearance, such as the color of the balloon, its relative position in the sky, etc. Instead, we can extract an internal vector in the network before the final output.
For common neural network architectures, this vector—which we call a “feature vector”—has many hundreds or thousands of dimensions. We can’t necessarily say with certainty that any one of these dimensions means something in particular as we could at the final network output, whose dimensions correspond to tag probabilities. But these vectors have an important property: when you compute the Euclidean distance between these vectors, images containing similar content will tend to have feature vectors closer together than images containing dissimilar content. You can think of this as a way that the network has learned to organize information present in the image so that it can output the required class prediction. This is exactly what we are looking for: Euclidian distance in this high-dimensional feature space is a measure of semantic similarity. The graphic below illustrates this idea: points in the neighborhood around the query image are semantically similar to the query image, whereas points in neighborhoods further away are not.
This measure of similarity is not perfect and cannot capture all possible notions of similarity—it will be constrained by the particular task the network was trained to perform, i.e., scene recognition. However, it is effective for our purposes, and, importantly, it contains information beyond merely the semantic content of the image, such as appearance, composition, and texture. Most importantly, it gives us a simple algorithm for finding visually similar photos: compute the distance in the feature space of a query image to each index image and return the images with lowest distance. Of course, there is much more work to do to make this idea work for billions of images.
Large-scale approximate nearest neighbor search
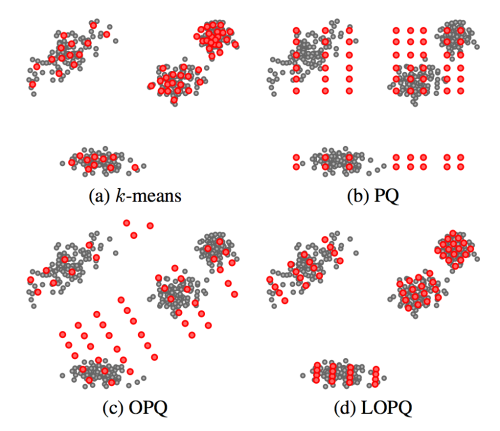
With an index as large as Flickr’s, computing distances exhaustively for each query is intractable. Additionally, storing a high-dimensional floating point feature vector for each of billions of images takes a large amount of disk space and poses even more difficulty if these features need to be in memory for fast ranking. To solve these two issues, we adopt a state-of-the-art approximate nearest neighbor algorithm called Locally Optimized Product Quantization (LOPQ).
To understand LOPQ, it is useful to first look at a simple strategy. Rather than ranking all vectors in the index, we can first filter a set of good candidates and only do expensive distance computations on them. For example, we can use an algorithm like k-means to cluster our index vectors, find the cluster to which each vector is assigned, and index the corresponding cluster id for each vector. At query time, we find the cluster that the query vector is assigned to and fetch the items that belong to the same cluster from the index. We can even expand this set if we like by fetching items from the next nearest cluster.
This idea will take us far, but not far enough for a billions-scale index. For example, with 1 billion photos, we need 1 million clusters so that each cluster contains an average of 1000 photos. At query time, we will have to compute the distance from the query to each of these 1 million cluster centroids in order to find the nearest clusters. This is quite a lot. We can do better, however, if we instead split our vectors in half by dimension and cluster each half separately. In this scheme, each vector will be assigned to a pair of cluster ids, one for each half of the vector. If we choose k = 1000 to cluster both halves, we have k2 = 1000 * 1000 = 1e6 possible pairs. In other words, by clustering each half separately and assigning each item a pair of cluster ids, we can get the same granularity of partitioning (1 million clusters total) with only 2*1000 distance computations with half the number of dimensions for a total computational savings of 1000x. Conversely, for the same computational cost, we gain a factor of k more partitions of the data space, providing a much finer-grained index.
This idea of splitting vectors into subvectors and clustering each split separately is called product quantization. When we use this idea to index a dataset it is called the inverted multi-index, and it forms the basis for fast candidate retrieval in our similarity index. Typically the distribution of points over the clusters in a multi-index will be unbalanced as compared to a standard k-means index, but this unbalance is a fair trade for the much higher resolution partitioning that it buys us. In fact, a multi-index will only be balanced across clusters if the two halves of the vectors are perfectly statistically independent. This is not the case in most real world data, but some heuristic preprocessing—like PCA-ing and permuting the dimensions so that the cumulative per-dimension variance is approximately balanced between the halves—helps in many cases. And just like the simple k-means index, there is a fast algorithm for finding a ranked list of clusters to a query if we need to expand the candidate set.
After we have a set of candidates, we must rank them. We could store the full vector in the index and use it to compute the distance for each candidate item, but this would incur a large memory overhead (for example, 256 dimensional vectors of 4 byte floats would require 1Tb for 1 billion photos) as well as a computational overhead. LOPQ solves these issues by performing another product quantization, this time on the residuals of the data. The residual of a point is the difference vector between the point and its closest cluster centroid. Given a residual vector and the cluster indexes along with the corresponding centroids, we have enough information to reproduce the original vector exactly. Instead of storing the residuals, LOPQ product quantizes the residuals, usually with a higher number of splits, and stores only the cluster indexes in the index. For example, if we split the vector into 8 splits and each split is clustered with 256 centroids, we can store the compressed vector with only 8 bytes regardless of the number of dimensions to start (though certainly a higher number of dimensions will result in higher approximation error). With this lossy representation we can produce a reconstruction of a vector from the 8 byte codes: we simply take each quantization code, look up the corresponding centroid, and concatenate these 8 centroids together to produce a reconstruction. Likewise, we can approximate the distance from the query to an index vector by computing the distance between the query and the reconstruction. We can do this computation quickly for many candidate points by computing the squared difference of each split of the query to all of the centroids for that split. After computing this table, we can compute the squared difference for an index point by looking up the precomputed squared difference for each of the 8 indexes and summing them together to get the total squared difference. This caching trick allows us to quickly rank many candidates without resorting to distance computations in the original vector space.
LOPQ adds one final detail: for each cluster in the multi-index, LOPQ fits a local rotation to the residuals of the points that fall in that cluster. This rotation is simply a PCA that aligns the major directions of variation in the data to the axes followed by a permutation to heuristically balance the variance across the splits of the product quantization. Note that this is the exact preprocessing step that is usually performed at the top-level multi-index. It tends to make the approximate distance computations more accurate by mitigating errors introduced by assuming that each split of the vector in the production quantization is statistically independent from other splits. Additionally, since a rotation is fit for each cluster, they serve to fit the local data distribution better.
LOPQ is state-of-the-art for quantization methods, and you can find more information about the algorithm, as well as benchmarks, here. Additionally, we provide an open-source implementation in Python and Spark which you can apply to your own datasets. The algorithm produces a set of cluster indexes that can be queried efficiently in an inverted index, as described. We have also explored use cases that use these indexes as a hash for fast deduplication of images and large-scale clustering. These extended use cases are studied here.
Conclusion
We have described our system for large-scale visual similarity search at Flickr. Techniques for producing high-quality vector representations for images with deep learning are constantly improving, enabling new ways to search and explore large multimedia collections. These techniques are being applied in other domains as well to, for example, produce vector representations for text, video, and even molecules. Large-scale approximate nearest neighbor search has importance and potential application in these domains as well as many others. Though these techniques are in their infancy, we hope similarity search provides a useful new way to appreciate the amazing collection of images at Flickr and surface photos of interest that may have previously gone undiscovered. We are excited about the future of this technology at Flickr and beyond.
Acknowledgements
Yannis Kalantidis, Huy Nguyen, Stacey Svetlichnaya, Arel Cordero. Special thanks to the rest of the Computer Vision and Machine Learning team and the Vespa search team who manages Yahoo’s internal search engine.
There’s no denying it: chat bots are en vogue and it seems like everyone is experimenting with the technology. Facebook introduced bots for their Messenger Platform, Microsoft launched a controversial chatbot on Twitter called Tay, and at Yahoo, we’ve released our own bots on Kik and Messenger. With so much interest, we’re doing our part as research scientists to advance the state-of-the-art in question-answering, which, among other things, will lead to conversational bots appearing more human.
For the second year in a row, the Yahoo Research Text Mining team in Haifa, in collaboration with Emory University and the U.S. National Institute of Standards and Technology, ran a shared challenge for question-answering called LiveQA as part of the annual Text REtrieval Conference (TREC).
During the 24-hour duration of the competition, 14 teams from the USA, China, Germany, Australia, Canada, Israel, and Qatar participated, though preparations for the competition actually started a few months earlier. Each team developed a Web service that, as input, received a free-form question, and then responded with an answer. The answer could not be longer than 1000 characters, and needed to be returned within one minute. The questions used, from Yahoo Answers, were different than the factoid questions used in some previous TREC QA tracks. Yahoo Answers questions are much more diverse and cover multiple question types, such as opinion, advice, and polls. This made the task far more realistic and challenging.
During the competition day, the TREC participants received a total of 1,088 questions and sent back a total of over 21,000 answers. They usually had no issue with either the time limit (24 seconds to answer, on average) or the length limit (599 characters per average answer).
The answers were judged manually on a four-point scale (excellent/good/fair/poor). The best system in terms of performance was the “EmoryCrowd” system from Emory. This was a unique system, because it used a combination of computational and human labor. First, it computed candidate answers algorithmically, and then it turned to crowdsourced work to rank them – all in less than 60 seconds. This “cyborg” system provided the highest-quality answers by a noticeable margin, trailed by fully-algorithmic systems from CMU, Emory, and Yahoo Research.
Human intellect was shown to be superior not just within hybrid systems, but also by itself, when we had the judges also evaluate the answers given by users on the original Yahoo Answers site. These answers were significantly better than any automated or hybrid system. Of importance though, the Yahoo Answers users had no time or space limit – if they wanted to, they could work on their answers for up to one week, which would give them an obvious advantage. This is just one reason to keep pushing the envelope on automatic question answering. Computers are faster than people for many tasks, they are available 24/7 (if the power is on), and they scale more readily.
Compared to last year’s challenge, the quality of results (i.e. the answers) improved significantly. However, the quality was still below that of the human responders’. We also introduced a new task for question summarization, and this task is far from being solved. Our plan is to run the LiveQA challenge next year, thus allowing the participants to further improve and extend their systems. We hope that additional teams will join this joint research effort of answering real users’ questions in real-time, with the goal of encouraging progress in the field of Natural Language Processing as it relates to question-answering. Who knows, in the future, maybe our learnings will find their way to a bot near you!
What’s the first thing you want to know about any kind of text document (like a Yahoo News or Yahoo Sports article)? What it’s about, of course! That means you want to know something about the people, organizations, and locations that are mentioned in the document. Systems that automatically surface this information are called named entity recognition and linking systems. These are one of the most useful components in text analytics as they are required for a wide variety of applications including search, recommender systems, question answering, and sentiment analysis.
Named entity recognition and linking systems use statistical models trained over large amounts of labeled text data. A major challenge is to be able to accurately detect entities, in new languages, at scale, with limited labeled data available, and while consuming a limited amount of resources (memory and processing power).
After researching and implementing solutions to enhance our own personalization technology, we are pleased to offer the open source community Fast Entity Linker, our unsupervised, accurate, and extensible multilingual named entity recognition and linking system, along with datapacks for English, Spanish, and Chinese.
For broad usability, our system links text entity mentions to Wikipedia. For example, in the sentence Yahoo is a company headquartered in Sunnyvale, CA with Marissa Mayer as CEO, our system would identify the following entities:
On the algorithmic side, we use entity embeddings, click-log data, and efficient clustering methods to achieve high precision. The system achieves a low memory footprint and fast execution times by using compressed data structures and aggressive hashing functions.
Entity embeddings are vector-based representations that capture how entities are referred to in context. We train entity embeddings using Wikipedia articles, and use hyperlinked terms in the articles to create canonical entities. The context of an entity and the context of a token are modeled using the neural network architecture in the figure below, where entity vectors are trained to predict not only their surrounding entities but also the global context of word sequences contained within them. In this way, one layer models entity context, and the other layer models token context. We connect these two layers using the same technique that (Quoc and Mikolov ‘14) used to train paragraph vectors.
Architecture for training word embeddings and entity embeddings simultaneously. Ent represents entities and W represents their context words.
Search click-log data gives very useful signals to disambiguate partial or ambiguous entity mentions. For example, if searchers for “Fox” tend to click on “Fox News” rather than “20th Century Fox,” we can use this data in order to identify “Fox” in a document. To disambiguate entity mentions and ensure a document has a consistent set of entities, our system supports three entity disambiguation algorithms:
*Currently, only the Forward Backward Algorithm is available in our open source release–the other two will be made available soon!
These algorithms are particularly helpful in accurately linking entities when a popular candidate is NOT the correct candidate for an entity mention. In the example below, these algorithms leverage the surrounding context to accurately link Manchester City, Swansea City, Liverpool, Chelsea, and Arsenal to their respective football clubs.
Ambiguous mentions that could refer to multiple entities are highlighted in red. For example, Chelsea could refer to Chelsea Football team or Chelsea neighborhood in New York or London. Unambiguous named entities are highlighted in green.
Examples of candidate retrieval process in Entity Linking for both ambiguous and unambiguous examples referred in the example above. The correct candidate is highlighted in green.
At this time, Fast Entity Linker is one of only three freely-available multilingual named entity recognition and linking systems (others are DBpedia Spotlight and Babelfy). In addition to a stand-alone entity linker, the software includes tools for creating and compressing word/entity embeddings and datapacks for different languages from Wikipedia data. As an example, the datapack containing information from all of English Wikipedia is only ~2GB.
The technical contributions of this system are described in two scientific papers:
There are numerous possible applications of the open-source toolkit. One of them is attributing sentiment to entities detected in the text, as opposed to the entire text itself. For example, consider the following actual review of the movie “Inferno” from a user on MetaCritic (revised for clarity): “While the great performance of Tom Hanks (wiki_Tom_Hanks) and company make for a mysterious and vivid movie, the plot is difficult to comprehend. Although the movie was a clever and fun ride, I expected more from Columbia (wiki_Columbia_Pictures).” Though the review on balance is neutral, it conveys a positive sentiment about wiki_Tom_Hanks and a negative sentiment about wiki_Columbia_Pictures.
Many existing sentiment analysis tools collate the sentiment value associated with the text as a whole, which makes it difficult to track sentiment around any individual entity. With our toolkit, one could automatically extract “positive” and “negative” aspects within a given text, giving a clearer understanding of the sentiment surrounding its individual components.
Feel free to use the code, contribute to it, and come up with addtional applications; our system and models are available at https://github.com/yahoo/FEL.
The Apache Hadoop technology suite is the engine behind the Big Data revolution that has been transforming multiple industries over the last decade. Hadoop was born at Yahoo 10 years ago as a pioneering open-source project. It quickly outgrew the company’s boundaries to become a vehicle that powers thousands of businesses ranging from small enterprises to Web giants.
These days, Yahoo is the largest Hadoop deployment in the industry. We run tens of thousands of Hadoop machines in our datacenters and manage more than 600 petabytes of data. Our products use Hadoop in a variety of ways that reflect a wealth of data processing patterns. Yahoo’s infrastructure harnesses Hadoop Distributed File System (HDFS) for ultra-scalable storage, Hadoop MapReduce for massive ad-hoc batch processing, Hive and Pig for database-style analytics, HBase for key-value storage, Storm for stream processing, and Zookeeper for reliable coordination.
Yahoo’s commitment to Hadoop goes far beyond operating the technology at Web scale. The company’s engineers and scientists make contributions to both entrenched and incubating Hadoop projects. Our Scalable Platforms team at Yahoo Research in Haifa has championed multiple innovative efforts that have benefited Yahoo products as well as the entire Hadoop community. Just recently, we contributed new algorithms to HBase, Omid (transaction processing system for HBase), and Zookeeper. Our work significantly boosted the performance of these systems and hardened their fault-tolerance. For example, the enhancements to Omid were instrumental for turning it into an Apache Incubation project (candidate for top-level technology status), whereas the work in HBase was named one of its top new features this year.
Our team launched approximately three years ago. Collectively we add many years of experience to Yahoo and the Hadoop community in distributed computing research and development. We specialize in scalability and high availability, arguably the biggest challenges in big data platforms. We love to identify hard problems in large-scale systems, design algorithms to solve them, develop the code, experiment with it, and finally contribute to the community. The team features researchers with deep theoretical backgrounds as well as the engineering maturity required to deal with complex production code. Our researchers regularly present their innovations at leading industrial conferences (Hadoop Summit and HBaseCon), as well as at top academic venues.
The researchers in our team comprise a blend of backgrounds in distributed computing, programming languages, and big systems, and most of us hold PhD degrees in these areas. We are especially proud to be a pioneering team of Hadoop developers in Israel. As such, we teach courses in big data technologies, organize technical meetups, and collaborate with academic colleagues. We are always happy to share our expertise with the ever-growing community of Hadoop users in the local hi-tech industry.
Our Scalable Platforms team in Haifa has been making significant contributions to the local research and engineering communities!
Automatically identifying that an image is not suitable/safe for work (NSFW), including offensive and adult images, is an important problem which researchers have been trying to tackle for decades. Since images and user-generated content dominate the Internet today, filtering NSFW images becomes an essential component of Web and mobile applications. With the evolution of computer vision, improved training data, and deep learning algorithms, computers are now able to automatically classify NSFW image content with greater precision.
Defining NSFW material is subjective and the task of identifying these images is non-trivial. Moreover, what may be objectionable in one context can be suitable in another. For this reason, the model we describe below focuses only on one type of NSFW content: pornographic images. The identification of NSFW sketches, cartoons, text, images of graphic violence, or other types of unsuitable content is not addressed with this model.
To the best of our knowledge, there is no open source model or algorithm for identifying NSFW images. In the spirit of collaboration and with the hope of advancing this endeavor, we are releasing our deep learning model that will allow developers to experiment with a classifier for NSFW detection, and provide feedback to us on ways to improve the classifier.
Our general purpose Caffe deep neural network model (Github code) takes an image as input and outputs a probability (i.e a score between 0-1) which can be used to detect and filter NSFW images. Developers can use this score to filter images below a certain suitable threshold based on a ROC curve for specific use-cases, or use this signal to rank images in search results.
Convolutional Neural Network (CNN) architectures and tradeoffs
In recent years, CNNs have become very successful in image classification problems [1] [5] [6]. Since 2012, new CNN architectures have continuously improved the accuracy of the standard ImageNet classification challenge. Some of the major breakthroughs include AlexNet (2012) [6], GoogLeNet [5], VGG (2013) [2] and Residual Networks (2015) [1]. These networks have different tradeoffs in terms of runtime, memory requirements, and accuracy. The main indicators for runtime and memory requirements are:
Flops or connections – The number of connections in a neural network determine the number of compute operations during a forward pass, which is proportional to the runtime of the network while classifying an image.
Parameters -–The number of parameters in a neural network determine the amount of memory needed to load the network.
Ideally we want a network with minimum flops and minimum parameters, which would achieve maximum accuracy.
Training a deep neural network for NSFW classification
We train the models using a dataset of positive (i.e. NSFW) images and negative (i.e. SFW – suitable/safe for work) images. We are not releasing the training images or other details due to the nature of the data, but instead we open source the output model which can be used for classification by a developer.
We use the Caffe deep learning library and CaffeOnSpark; the latter is a powerful open source framework for distributed learning that brings Caffe deep learning to Hadoop and Spark clusters for training models (Big shout out to Yahoo’s CaffeOnSpark team!).
While training, the images were resized to 256x256 pixels, horizontally flipped for data augmentation, and randomly cropped to 224x224 pixels, and were then fed to the network. For training residual networks, we used scale augmentation as described in the ResNet paper [1], to avoid overfitting. We evaluated various architectures to experiment with tradeoffs of runtime vs accuracy.
MS_CTC [4] – This architecture was proposed in Microsoft’s constrained time cost paper. It improves on top of AlexNet in terms of speed and accuracy maintaining a combination of convolutional and fully-connected layers.
Squeezenet [3] – This architecture introduces the fire module which contain layers to squeeze and then expand the input data blob. This helps to save the number of parameters keeping the Imagenet accuracy as good as AlexNet, while the memory requirement is only 6MB.
VGG [2] – This architecture has 13 conv layers and 3 FC layers.
GoogLeNet [5] – GoogLeNet introduces inception modules and has 20 convolutional layer stages. It also uses hanging loss functions in intermediate layers to tackle the problem of diminishing gradients for deep networks.
ResNet-50 [1] – ResNets use shortcut connections to solve the problem of diminishing gradients. We used the 50-layer residual network released by the authors.
ResNet-50-thin – The model was generated using our pynetbuilder tool and replicates the Residual Network paper’s 50-layer network (with half number of filters in each layer). You can find more details on how the model was generated and trained here.
Tradeoffs of different architectures: accuracy vs number of flops vs number of params in network.
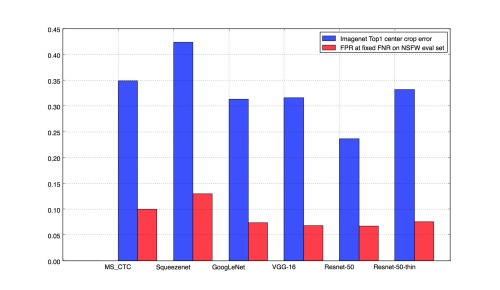
The deep models were first pre-trained on the ImageNet 1000 class dataset. For each network, we replace the last layer (FC1000) with a 2-node fully-connected layer. Then we fine-tune the weights on the NSFW dataset. Note that we keep the learning rate multiplier for the last FC layer 5 times the multiplier of other layers, which are being fine-tuned. We also tune the hyper parameters (step size, base learning rate) to optimize the performance.
We observe that the performance of the models on NSFW classification tasks is related to the performance of the pre-trained model on ImageNet classification tasks, so if we have a better pretrained model, it helps in fine-tuned classification tasks. The graph below shows the relative performance on our held-out NSFW evaluation set. Please note that the false positive rate (FPR) at a fixed false negative rate (FNR) shown in the graph is specific to our evaluation dataset, and is shown here for illustrative purposes. To use the models for NSFW filtering, we suggest that you plot the ROC curve using your dataset and pick a suitable threshold.
Comparison of performance of models on Imagenet and their counterparts fine-tuned on NSFW dataset.
We are releasing the thin ResNet 50 model, since it provides good tradeoff in terms of accuracy, and the model is lightweight in terms of runtime (takes < 0.5 sec on CPU) and memory (~23 MB). Please refer our git repository for instructions and usage of our model. We encourage developers to try the model for their NSFW filtering use cases. For any questions or feedback about performance of model, we encourage creating a issue and we will respond ASAP.
Results can be improved by fine-tuning the model for your dataset or use case. If you achieve improved performance or you have trained a NSFW model with different architecture, we encourage contributing to the model or sharing the link on our description page.
Disclaimer: The definition of NSFW is subjective and contextual. This model is a general purpose reference model, which can be used for the preliminary filtering of pornographic images. We do not provide guarantees of accuracy of output, rather we make this available for developers to explore and enhance as an open source project.
[1] He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. “Deep residual learning for image recognition” arXiv preprint arXiv:1512.03385 (2015).
[2] Simonyan, Karen, and Andrew Zisserman. “Very deep convolutional networks for large-scale image recognition.”; arXiv preprint arXiv:1409.1556(2014).
[3] Iandola, Forrest N., Matthew W. Moskewicz, Khalid Ashraf, Song Han, William J. Dally, and Kurt Keutzer. “SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and 1MB model size.”; arXiv preprint arXiv:1602.07360 (2016).
[4] He, Kaiming, and Jian Sun. “Convolutional neural networks at constrained time cost.” In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5353-5360. 2015.
[5] Szegedy, Christian, Wei Liu, Yangqing Jia, Pierre Sermanet,Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. “Going deeper with convolutions” In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1-9. 2015.
[6] Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. “Imagenet classification with deep convolutional neural networks” In Advances in neural information processing systems, pp. 1097-1105. 2012.