Introduction
This summer I’m working on librsvg, a GNOME library for rendering SVG files, particularly on porting the SVG filter effects from C to Rust. That involves separating the code for different filters from one huge C file into individual files for each filter, and then porting the filter rendering infrastructure and the individual filters.
Thankfully, in the large C file the code for different filters was divided by comment blocks, so several vim macros later I was done with the not so exciting splitting part.
Representing Filters in Rust
SVG filter effects are applied to an existing SVG element to produce a modified graphical result. Each filter consists of a number of filter primitives. The primitives take raster images (bitmaps) as an input (this can be, for example, the rasterized element where the filter was applied, the background snapshot of the canvas at the time the filter was invoked, or an output of another filter primitive), do something with it (like move the pixels to a different position, apply Gaussian blur, or blend two input images together) and produce raster images as an output.
Each filter primitive has a number of properties. The common properties include the bounds of the region where the filter primitive is doing its processing, the name assigned to the primitive’s result, and the input that the primitive operates on. I collected the common properties into the following types:
struct Primitive {
x: Cell<Option<RsvgLength>>,
y: Cell<Option<RsvgLength>>,
width: Cell<Option<RsvgLength>>,
height: Cell<Option<RsvgLength>>,
result: RefCell<Option<String>>,
}
struct PrimitiveWithInput {
base: Primitive,
in_: RefCell<Option<Input>>,
}
Each filter primitive struct is meant to contain one of these two common types along with any extra properties as needed. The common types provide functions for parsing their respective properties so that code need not to be duplicated in each filter.
Note that these properties are just “descriptions” of the final values to be used during rendering. For example, an RsvgLength can be equal to 2 or 50%, and the actual length in pixels is evaluated during rendering and depends on various rendering state such as the coordinate system in use and the size of the enclosing element.
The filter primitive processing behavior is nicely described as a trait:
trait Filter {
fn render(&self, ctx: &FilterContext)
-> Result<FilterResult, FilterError>;
}
Here FilterContext contains various filter state such as the rasterized bitmap representation of the SVG element the filter is being applied to and results of previously rendered primitives, and allows retrieving the necessary input bitmaps. Successful rendering results in a FilterResult which has the name assigned to the primitive and the output image, and errors (like non-existent input filter primitive) end up in FilterError.
When a filter is invoked, it goes through its child nodes (filter primitives) in order, render()s them and stores the results in the FilterContext.
Pixel Iteration
Since many filter primitives operate on a per-pixel basis, it’s important to have a convenient way of transforming the pixel values.
Librsvg uses image surfaces from Cairo, a 2D graphics library, for storing bitmaps. An image surface stores its pixel values in RGBA format in a large contiguous array row by row with optional strides between the rows. The plain way of accessing the values is image[y * stride + x * 4 + ch] where ch is 0, 1, 2 and 3 for R, G, B and A respectively. However, writing this out is rather tedious and error-prone.
As the first step, I added a pixel value struct:
struct Pixel {
pub r: u8,
pub g: u8,
pub b: u8,
pub a: u8,
}
and extended cairo-rs‘s image surface data accessor with the following methods:
fn get_pixel(
&self,
stride: usize,
x: usize,
y: usize,
) -> Pixel;
fn set_pixel(
&mut self,
stride: usize,
pixel: Pixel,
x: usize,
y: usize,
);
using the known trick of declaring a trait containing the new methods and implementing it for the target type. Unfortunately, stride has to be passed through manually because the (foreign) data accessor type doesn’t offer a public way of retrieving it. Adding methods to cairo-rs directly would allow to get rid of this extra argument.
Next, since the pattern of iterating over pixels of an image surface within the given bounds comes up rather frequently in filter primitives, I added a Pixels iterator inspired by the image crate. It allows writing code like this:
for (x, y, pixel) in Pixels::new(&image, bounds) {
/* ... */
}
instead of the repetitive plain version:
for y in bounds.y0..bounds.y1 {
for x in bounds.x0..bounds.x1 {
let pixel = image.get_pixel(stride, x, y);
/* ... */
}
}
Filters with multiple input images can process pixels simultaneously in the following fashion using the standard Rust iterator combinators:
for (x, y, p, p2) in Pixels::new(&image, bounds)
.map(|(x, y, p)| {
(x, y, p, image2.get_pixel(stride, x, y))
})
{
let out_pixel = /* ... */;
out_image.set_pixel(stride, out_pixel, x, y);
}
Benchmarking
Rust is known for its zero-cost abstractions, however it’s still important to keep track of performance because it’s very well possible to write code in such a way that’s hard to optimize away. Fortunately, a benchmarking facility is provided on nightly Rust out of the box: the test feature with the Bencher type.
Benchmark sources are usually placed in the benches/ subdirectory of the crate and look like this:
#![feature(test)]
extern crate rsvg_internals;
#[cfg(test)]
mod tests {
use super::*;
use test::Bencher;
#[bench]
fn my_benchmark_1(b: &mut Bencher) {
/* initialization */
b.iter(|| {
/* code to be benchmarked */
});
}
#[bench]
fn my_benchmark_2(b: &mut Bencher) {
/* ... */
}
/* ... */
}
After ensuring the crate’s crate-type includes "lib", you can run benchmarks with cargo +nightly bench.
I created three benchmarks, one for the straightforward iteration:
b.iter(|| {
let mut r = 0;
let mut g = 0;
let mut b = 0;
let mut a = 0;
for y in BOUNDS.y0..BOUNDS.y1 {
for x in BOUNDS.x0..BOUNDS.x1 {
let base = y * stride + x * 4;
r += image[base + 0] as usize;
g += image[base + 1] as usize;
b += image[base + 2] as usize;
a += image[base + 3] as usize;
}
}
(r, g, b, a)
})
One for iteration using get_pixel():
b.iter(|| {
let mut r = 0;
let mut g = 0;
let mut b = 0;
let mut a = 0;
for y in BOUNDS.y0..BOUNDS.y1 {
for x in BOUNDS.x0..BOUNDS.x1 {
let pixel = image.get_pixel(stride, x, y);
r += pixel.r as usize;
g += pixel.g as usize;
b += pixel.b as usize;
a += pixel.a as usize;
}
}
(r, g, b, a)
})
And one for the Pixels iterator:
b.iter(|| {
let mut r = 0;
let mut g = 0;
let mut b = 0;
let mut a = 0;
for (_x, _y, pixel) in Pixels::new(&image, BOUNDS) {
r += pixel.r as usize;
g += pixel.g as usize;
b += pixel.b as usize;
a += pixel.a as usize;
}
(r, g, b, a)
})
Here are the results I’ve got:
test tests::bench_pixels ... bench: 991,137 ns/iter (+/- 62,654)
test tests::bench_straightforward ... bench: 992,124 ns/iter (+/- 7,119)
test tests::bench_straightforward_getpixel ... bench: 1,034,037 ns/iter (+/- 11,121)
Looks like the abstractions didn’t introduce any overhead indeed!
Implementing a Filter Primitive
Let’s look at how to write a simple filter primitive in Rust. As an example I’ll show the offset filter primitive which moves its input on the canvas by a specified number of pixels.
Offset has an input and two additional properties for the offset amounts:
struct Offset {
base: PrimitiveWithInput,
dx: Cell<RsvgLength>,
dy: Cell<RsvgLength>,
}
Since each filter primitive is an SVG node, it needs to implement NodeTrait which contains a function for parsing the node’s properties:
impl NodeTrait for Offset {
fn set_atts(
&self,
node: &RsvgNode,
handle: *const RsvgHandle,
pbag: &PropertyBag,
) -> NodeResult {
// Parse the common properties.
self.base.set_atts(node, handle, pbag)?;
// Parse offset-specific properties.
for (_key, attr, value) in pbag.iter() {
match attr {
Attribute::Dx => self.dx.set(parse(
"dx",
value,
LengthDir::Horizontal,
None,
)?),
Attribute::Dy => self.dy.set(parse(
"dy",
value,
LengthDir::Vertical,
None,
)?),
_ => (),
}
}
Ok(())
}
}
Finally, we need to implement the Filter trait. Note that render() accepts an additional &RsvgNode argument, which refers to the filter primitive node. It’s different from &self in that it contains various common SVG node state.
impl Filter for Offset {
fn render(
&self,
node: &RsvgNode,
ctx: &FilterContext,
) -> Result<FilterResult, FilterError> {
// Compute the processing region bounds.
let bounds = self.base.get_bounds(ctx);
// Compute the final property values.
let cascaded = node.get_cascaded_values();
let values = cascaded.get();
let dx = self
.dx
.get()
.normalize(&values, ctx.drawing_context());
let dy = self
.dy
.get()
.normalize(&values, ctx.drawing_context());
// The final offsets depend on the currently active
// affine transformation.
let paffine = ctx.paffine();
let ox = (paffine.xx * dx + paffine.xy * dy) as i32;
let oy = (paffine.yx * dx + paffine.yy * dy) as i32;
// Retrieve the input surface.
let input_surface =
get_surface(self.base.get_input(ctx))?;
// input_bounds contains all pixels within bounds,
// for which (x + ox) and (y + oy) also lie
// within bounds.
let input_bounds = IRect {
x0: clamp(bounds.x0 - ox, bounds.x0, bounds.x1),
y0: clamp(bounds.y0 - oy, bounds.y0, bounds.y1),
x1: clamp(bounds.x1 - ox, bounds.x0, bounds.x1),
y1: clamp(bounds.y1 - oy, bounds.y0, bounds.y1),
};
// Create an output surface.
let mut output_surface =
ImageSurface::create(
cairo::Format::ARgb32,
input_surface.get_width(),
input_surface.get_height(),
).map_err(FilterError::OutputSurfaceCreation)?;
let output_stride =
output_surface.get_stride() as usize;
// An extra scope is needed because output_data
// borrows output_surface, but we need to move
// out of it to return it.
{
let mut output_data =
output_surface.get_data().unwrap();
for (x, y, pixel) in
Pixels::new(&input_surface, input_bounds)
{
let output_x = (x as i32 + ox) as usize;
let output_y = (y as i32 + oy) as usize;
output_data.set_pixel(
output_stride,
pixel,
output_x,
output_y,
);
}
}
// Return the result of the processing.
Ok(FilterResult {
name: self.base.result.borrow().clone(),
output: FilterOutput {
surface: output_surface,
bounds,
},
})
}
}
Conclusion
The project is coming along very nicely with a few simple filters already working in Rust and a couple of filter tests getting output closer to the reference images.
I’ll be attending this year’s GUADEC, so I hope to see you there in July!









 Welcome window – Adwaita light theme
Welcome window – Adwaita light theme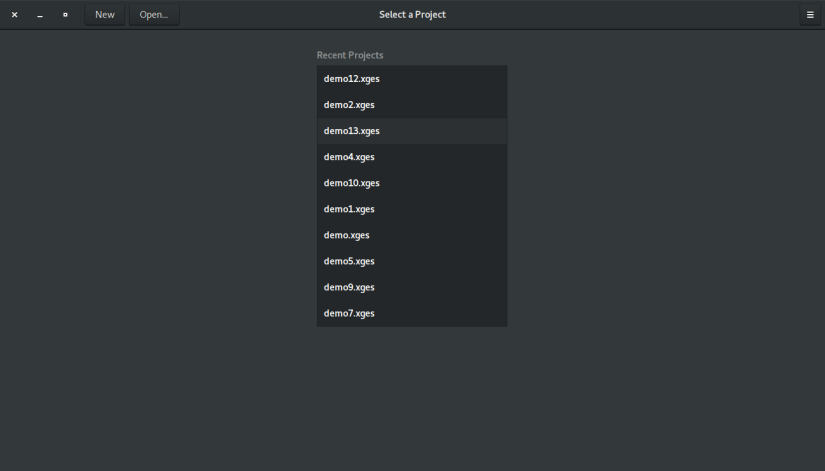 Welcome window – Adwaita dark theme
Welcome window – Adwaita dark theme “Close Project” button (highlighted in right)
“Close Project” button (highlighted in right)

 Initial design of custom project view
Initial design of custom project view
 Oliver with a group of pupils
Oliver with a group of pupils
 Ancient Egyptian Flatpak
Ancient Egyptian Flatpak Modern Flatpak
Modern Flatpak Future Flatpak
Future Flatpak



































 Designed by Smashicons from Flaticon
Designed by Smashicons from Flaticon
 Pitivi’s current welcome dialog
Pitivi’s current welcome dialog Integrated welcome window in GNOME Builder app
Integrated welcome window in GNOME Builder app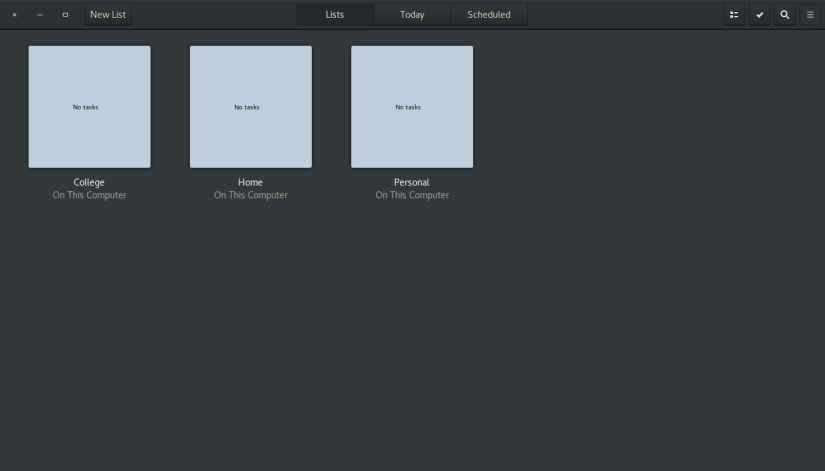 Integrated welcome window in GNOME ToDo app
Integrated welcome window in GNOME ToDo app Integrated welcome/greeter window in Pitivi. Notice that the important action buttons like “New” and “Open” are shown prominently in the header bar.
Integrated welcome/greeter window in Pitivi. Notice that the important action buttons like “New” and “Open” are shown prominently in the header bar. Integrated welcome/greeter window in Pitivi. Notice that other (not so important) action buttons like “Keyboard Shortcuts”, “User Manual”, etc. are shown inside a menu in the header bar.
Integrated welcome/greeter window in Pitivi. Notice that other (not so important) action buttons like “Keyboard Shortcuts”, “User Manual”, etc. are shown inside a menu in the header bar.


