
This post was written by Betaworks lead scientist Suman Deb Roy and was originally posted on Medium
How Digg Bot finds stories for your favorite topics
A year and half ago, the Notifications Summit was held at Betaworks to deliberate on many key ideas: the push and the pull, notifications as a primary interface, as a meta-app, utility of the lock screen, deep linking, filters etc. There was growing consensus that notifications could become an operating system for the information age, a beacon in the attention economy.
The attention economy has transformed many industries, but none more severely than news media — where a clear oversupply of information has overwhelmed consumers. The larger an information landscape becomes, the more pressing is the demand for actionable and relevant content. This hyper-relevancy is the principal challenge notification systems face.
Somewhat counter-intuitively though, it is only by monitoring and analyzing this entire information landscape that great notifications can be created, because only then can relevance be calculated as a synergy between the world and the user — an elusive attribute of actionable notifications.

Digg Bot notification for the topic “bitcoin”. If you subscribed to this topic, notifications about it might appear on the lock screen (left) and in Facebook Messenger (right) when you open it.
Luckily, Digg has data of the entire information landscape. Each day, Digg aggregates almost 7.5 million unique urls through its various products: Digg Reader which tracks 8 millions of RSS feeds, Digg Deeper that listens to 2–3 million Twitter users and Digg Channels comprising of focused topic pages. This means Digg observes a comprehensive chunk of media produced on the Web every single day, giving it unique potential at notifications technology.
In this post, I’ll explain how we are thinking about notifications at Digg using our messaging services, including topic subscriptions in the news bot, algorithms and heuristics that generate notifications and some results/data we are seeing from this feature.
DiggBot’s Notification Feature
We soft-launched Digg alerts on our Facebook Messenger bot on August 2nd, 2016. Since then, Digg Bot has sent over 34,037 notifications for hundreds of unique topics or keywords to users. Subscribing to a topic in Digg Bot is relatively easy. Just search for any word/phrase and the last card in the carousel will let you subscribe to it.

Alternately, you can add/edit/remove topics from your subscriptions at any time by typing manage subscriptions. When you add/follow a topic, you might receive push notifications comprising of important stories in the topic.
While you can follow traditional beats like politics or technology, the real value of a notification system is in more granular topics, which could range from obsessions like climate change to entities like beyonce or tesla. As an example, I subscribe to artificial intelligence news and these are some notifications Digg Bot sent me.

Notifications for “Artificial Intelligence”. If an important story in your topic breaks after 9pm or before 8 am, we might send them as silent pushes.
You can also subscribe to even finer sub-topics within concepts like artificial intelligence, e.g deep learning. Feel free to track specific entities related to sub-topics as well, such as the company Deepmind that is related to AI. Digg Bot’s algorithm adjusts itself based on the volume and velocity of stories associated to the topic’s generality and sends relevant pushes featuring a representative link related to the topic.

The coolest thing about a notification system is the ability to set up granular alerts about sub-topics. Instead of subscribing to all NBA news from ESPN, you could just get notifications about the Golden State Warriors. Instead of being bombarded with financial news from one publisher, you could configure Digg to notify you about certain companies only.
Digg’s Notification Algorithm
To generate relevant notifications, we must first calculate how pertinent a story is to the user at that moment. This depends on three factors — (1) how important the story is globally, (2) importance of the story in the user’s own world, and (3) time and attention-impeding capacity of an alert. While the first factor can be handled by editors efficiently, in reality, people don’t always care about everything newsrooms want them to care about at that very moment — because urgency is a deeply personal thing. Thus, factors 2 and 3 are hard to balance without intelligent technology.
Time is an inescapable attribute of intelligent notifications. Unfortunately, many popular machine learning solutions begin to wobble when we introduce this exact criterion into the equation — time. Features that appear paramount in static analysis of systems can get eroded when the same system is observed dynamically.
A singular ML framework can be hard to personalize in this regard, because the algorithm needs sophistication to model temporal variations of human attentiveness to news and information. Thus, there are three keyalgorithmic ensembles we employ to address this:
1 . The Trending Ensemble: A group of algorithms that determine the trending nature of a story, characterized by how much attention it is receiving in the social and news media. It is optimized for multi-modal signal monitoring, early detection, and considers accumulative opportunity cost plus seasonality.
The result is every article ingested gets a DiggRank, indicating its trending nature in the world. You can check the current trending articles in Digg Bot.

2. The Clustering Ensemble: Multiple learning algorithms that determine if two separate news articles are part of the same story /event. This addresses a regular irritation with news alerts — duplicate pushes from different outlets about the same story. The clustering ensemble is optimized for detecting consolidated media coverage, diversity and syndicated associations. The result is that all links covering the same story are grouped together in a cluster.

When news about Youtube’s live-TV service broke, about 10–11 media outlets covered it. This gif shows how all those related stories from different publishers were clustered and displayed in Digg’s technology channel.
The clustering ensemble also manages three important situations:
- Story Development: As more media outlets write about a story and it develops, the semantics of article titles and descriptions change (if there is new information) — causing the cluster to split. The algorithm determines if the fresh articles in the news cycle is different enough to represent a story update and big enough to be pushed eventually.
- Unverified Trends: This addresses a significant hassle in the age of breaking social news — the popular yet unverified story. Recall that last year, a single fake news story triggered safety alerts on Facebook. Some of the best information systems might be vulnerable to media hacking. Thus, consolidated media coverage (via clustering) is a heuristic for verifying hoax stories.
- Editorial Expertise: The algorithm has to select one article from the cluster of similar links to be featured in the push notification. If there is a link in the cluster that Digg editors have featured on the front page, it could be prioritized as the representative article of the notification.
3. The Info-Sphere Ensemble: Just because a story is alert-worthy, does not mean it needs to be pushed now. Untimely pushes create ambiguity and a wrong sense of urgency. The final ensemble is a policy network — whose job is to determines if we actually push the story to the user right now or defer it to a later time, given a story’s importance.
The info-sphere ensemble attempts to simulate the information sphere of the user. A user can be subscribed to multiple topics of different granularity. Since the volume and velocity of incoming news for every topic is different, notifications must be modulated. Has the user recently received an alert about this topic? How many total notifications has she received in the last x hours? How surprising is it for stories in this topic to gain this much traction? On average, an individual subscribes to 4–5 topics. These questions are critical in assuring relevant yet non-invasive notifications.
Using these ensembles, Digg Bot has been flagging ~200 stories each day as alert-worthy, although we are noticing the aggregate number rise as more people keep subscribing to newer topics.

The overall number of notification alerts that Digg Bot flags each day. The algorithm went through a tuning spell from Aug 04–10, 2016 right after launch, which is why there was a huge spike and then trough. Tuning involves calculating the right thresholds and parameters once a system goes live, based on volume and velocity of incoming topical stories.
These 3 ensembles collectively give rise to some interesting flavors of notifications, depending on the topic categories you subscribe to.
Flavors of Digg Notifications:
(1) Mix of Breaking, Note-worthy, and Catch-up stories
We cannot emphasize enough the time-horizon of predictions or pushes that make alerts useful. Our priority isn’t necessarily to make notifications breaking, unless absolutely necessary. Instant is not always the best. Thus, the algorithm also calculates whether some topic stories are important but not big enough, so you can catch up with them in your “time-out” hours. This we call — the Digest.
The Digest comprises of top-ranked stories from a subset of your topic subscriptions. The topics chosen for push depend on the popularity of the stories within the topic and the frequency of alerts in that topic. For example, if you subscribed to Westworld (the TV show), these are some notifications (separate and digest) you would have received.

One of the many algorithmic tunings is to determine when something is breaking vs. socially popular vs. can be sent out in a digest. We understand that normal capability for media consumption (even for topics we are passionate about) varies but is possibly limited to pockets of time.
(2) The Obsession Stream
One of my favorite things to track is sports teams. But unlike traditional services that notify us about scores or high-level topic news like NFL, I want to receive all relevant news at a much more granular level, like SEC football or golden state warriors. This liberates me from following multiple services or receiving irrelevant noise about the entire beat.
For example, I follow Real Madrid— these are some notifications I received.
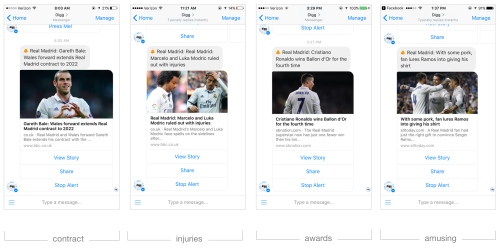
As you can see, alerts about sports teams or players can cover different attributes: new contracts, transfers, injuries, player awards and even amusingly popular memes.
(3) Instantaneous & Incidental
While I am ok to receive certain topic stories later in the Digest, other news pieces must be known in the moment. Certain topics, especially those related to sport teams, players, celebrities or companies, have an element of live in them. Reminding/informing users about critical events during a game or perhaps an earnings call stands out as a much beloved feature.
Here’s some notifications for Real Madrid with a live component in mind:

Sometimes, we forget when a game is about to start. I also like to be passively reminded of the score for a game I missed, instead me explicitly going online to check for it.
(4) Non-Invasive yet Noticeable
Occasionally, your tracked topic stories won’t be big enough for mainstream newsrooms to cover, but could be huge within your own world. An algorithm must decide which of your topics have big enough stories to tell — and when.
We realize you don’t always have free time to consume media, but the best technologies require the smallest amount of attention. For example, assume I follow the topics bots, artificial intelligence, real madrid, data science, westworld , etc., — how can it be compiled to consume later?

Digest is a notification that makes use of the carousel format and is sent during break hours — before/ after work hours for commute or during a potential lunch break. The goal is to sync with the diurnal fluctuations of our news consumption capacity.
Whats Next:
Digg Notifications is a synergy of three ensemble algorithms — the first ensemble proactively monitors millions of media signals, the second determines which signals are semantically similar, and the final ensemble personalizes the push based on socio-temporal patterns.
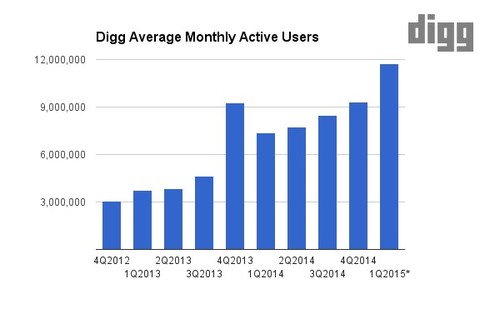
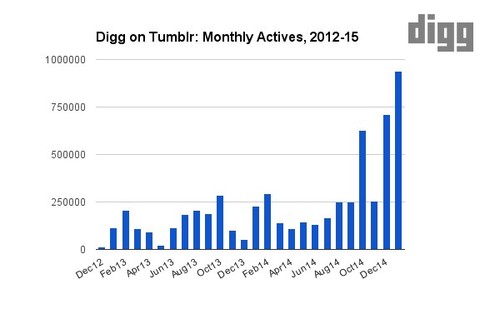
More concepts: We have been noticing a steady rise in the number of unique users subscribed to at least one topic. This also means the number of unique keywords Digg Bot sends notifications for is increasing.

Rising number of Digg Bot topic subscribers month-by-month (left). Growth in unique keywords that people are subscribed to (right). The highest subscribed keyword in every month is annotated in the chart.
Currently, 66% of subscriptions keywords are unigrams, 26% are bigrams and ~6% is trigrams. We noticed that multi-grams are sometimes names of sport teams, or blended concepts like apple vs google.
Tracking sectors: By using subscription topics intelligently, you can also track sectors of industry — such as tech companies, clean energy, celebrity news, sports leagues, political issues, manufacturing in Asia etc.

Notifications generated for 4 tech companies each day. Interestingly, we found users also subscribe to the content type/sectors via publishers names, e.g., subscribing to “tmz” to capture all breaking celebrity news.
API: Behind every bot functionality is an API. Digg’s notification technology is also available as an alerts API. You can subscribe to any company, person, or meta/hybrid topics and get alerts when something noticeable happens. The rate of alerts, ranging from always-breaking to always-digest, is easily customizable in the API based on your requirements. Additionally, you can turn off /customize notifications for individual topics at will in the Digg API.
In this age of limitless data, the goal of notification systems should not be to addict. Instead, it should help us live our lives better with the information we want. Notifications is a fundamental way to process infinite information, and will serve as the lowest layer of conversational intelligence.
You can subscribe to topics on Digg Bot here. For questions/ comments about the Notifications data or Digg Api services, please reach out to api@digg.com








































{kind=link}
{kind=link}