Pay rise please
In 1967 Georges Perec wrote a radio play, L’Augmentation, in which you, the protagonist, make some delicate decisions whilst negotiating a pay rise. Is your boss, Mr X, in a good mood? Did he have fish for lunch? Does one of his daughters have measles?

The story takes the form of a flow chart. It’s no coincidence it was written when computers were becoming a part of office and laboratory work, and when flow charts became a popular way to represent the algorithms they were programmed with. 1967 is also the year Perec joined Oulipo, a literary organisation whose members seek to create works based around mathematical constraints and structures. The loops and branches of Perec’s flow chart perfectly embody the frustrating routines of office politics.
Fifty years on, I’ve created a version to run on Alexa, which you can download from Amazon. It may not get me a pay rise, but I should qualify for a freebie Echo Dot.

Follow me follow me
Leap
There were 12 of us in the room, plus Jim the instructor.
We had moved the tables and chairs to one side. Jim asked us to stand in the space we’d created. He asked each of us to pick two other people in the room, without telling anyone who we’d chosen.
The object of this exercise, Jim said, is to move around until each person is at an equal distance from the two people they’ve chosen.
Jim appointed Jo project manager.
You’re the project manager, Jim said. Get your team organised.
Jo had no particular instructions but as a team we instinctively started moving, stepping and turning. I was tracking Mark and Jo — who I’d chosen before her appointment as PM. I imagined a straight line on the floor of the room between the two of them and equidistant from both and walked towards it, adjusting my trajectory as they too moved. Ruth and Paul must have been following me: as I moved they turned and moved too.
Quite quickly we slowed down, making fine adjustments, shuffling into a final position. Was everyone happy? Yes? We’d done it.
Good work Jo!
What had Jo done? She’d let us get on with it. We were a self-organising team. What had I done? I’d suppressed my mathematical instinct to think before moving — I’d leapt rather than looked.
Look
This is a great team training exercise. It encourages exploration and trust. Evidently it works, too — however people choose who to follow, there will be a solution which can be discovered using a simple and sensible strategy. It made me think of shoal behaviour in animals, where there is no leader and each individual follows the same small set of rules, but the apparently sophisticated resulting behaviour suggests the shoal has a mind of its own.

I experimented with a computer simulation. The picture above is a static snap shot — click it to access the live page and explore different configurations. I plan to experiment with different shoaling strategies and to expose more controls. The source code is here github.com/wordaligned/followme.
Unleash the test army
Are the tests adequate?
Recently I described a solution to the problem of dividing a list into evenly sized chunks. It’s a simple enough problem with just two inputs: the list (or other sliceable container) xs and the number of chunks n. Nonetheless, there are traps to avoid and special cases to consider — what if n is larger than the list, for example? Must the chunks comprise contiguous elements from the original list?
The tests I came up with are straightforward and uninspiring. They were developed within the context of my own assumptions about the solution and the special cases I could imagine. They were written after the implementation — which is to say, development wasn’t driven by tests. They are whitebox tests, designed to cover the various paths through the code based on my insider knowledge.
Are these tests adequate? Certainly they don’t accurately represent the data which will hit the algorithm in practice. Can we be sure we haven’t missed anything? Would the tests still cover all paths if the implementation changed?
Property based testing
David R MacIver described another, complementary, approach at a talk I attended at ACCU 2016. In the talk abstract he characterises the (class of) tests I’d written as anecdotal — “let me tell you about this time I called a function … and then it returned this .. and then it raised an exception … etc. etc.”
How about if the test suite instead describes the properties required of the system under test, and then conjures up inputs designed to see if these properties hold under stress? So, rather than our test suite being a limited set of input/output pairs, it becomes an executable specification validated by a robot army.

Lazy sequences working hard
I gave a talk @PyDiff this evening in the computer science department at Cardiff University.
Lazy Sequences working hard
Python has no problem handling large and even infinite streams of data. Just write lazy programs — code which defers data access until the last minute. This talk examines Python’s language and library support for such delaying tactics. There will be live coding, and we’ll draw parallels with similar features in other languages, in particular the Unix shell.
Being unsure where to pitch it, I started off easy and kept going until I’d lost everybody — including myself.
The room was well set up with a good quality projector and whiteboard, along with a desk to sit down when I wanted to write and run code and plenty of space to move around in otherwise. I did feel a bit like a jack-in-the-box by the end.

I’d based the talk on a Jupyter notebook which I replayed with the ingenious RISE reveal.js extension written by Damian Avila. This worked well, since I got the pretty graphics along with the interactive coding. A static version of the slides is available here.
Thanks to everyone who came. Sorry I had to rush off after. If anyone would like to talk at Swansea, please let me know: you’d be most welcome.
Slicing a list evenly with Python

Here’s a problem I came up against recently.
The task was to chop a list into exactly n evenly slized chunks. To give a little more context, let’s suppose we want to divide a list of jobs equally between n workers, where n might be the number of CPU cores available.
We can build the result by repeatedly slicing the input:
def chunk(xs, n):
'''Split the list, xs, into n chunks'''
L = len(xs)
assert 0 < n <= L
s = L//n
return [xs[p:p+s] for p in range(0, L, s)]
This looks promising
>>> chunk('abcdefghi', 3)
['abc', 'def', 'ghi']
but if the size of the list is not an exact multiple of n, the result won’t contain exactly n chunks.
>>> chunk('abcde', 3)
['a', 'b', 'c', 'd', 'e']
>>> chunk('abcdefgh', 3)
['ab', 'cd', 'ef', 'gh']
>>> chunk('abcdefghij', 3)
['abc', 'def', 'ghi', 'j']
(By the way, I’m using strings rather than lists in the examples. The code works equally well for both types, and strings make it slightly easier to see what’s going on.)
One way to fix the problem is to group the final chunks together.
def chunk(xs, n):
'''Split the list, xs, into n chunks'''
L = len(xs)
assert 0 < n <= L
s, r = divmod(L, n)
chunks = [xs[p:p+s] for p in range(0, L, s)]
chunks[n-1:] = [xs[-r-s:]]
return chunks
Now we have exactly n chunks, but they may not be evenly sized, since the last chunk gets padded with any surplus.
>>> chunk('abcde', 3)
['a', 'b', 'cde']
>>> chunk('abcdefgh', 3)
['ab', 'cd', 'efgh']
>>> chunk('abcdefghij', 3)
['abc', 'def', 'ghij']
What does “evenly sized” actually mean? Loosely speaking, we want the resulting chunks as closely sized as possible.
More precisely, if the result of dividing the length of the list L by the number of chunks n gives a size s with remainder r, then the function should return r chunks of size s+1 and n-r chunks of size s. There are choose(n, r) ways of doing this. Here’s a solution which puts the longer chunks to the front of the results.
def chunk(xs, n):
'''Split the list, xs, into n evenly sized chunks'''
L = len(xs)
assert 0 < n <= L
s, r = divmod(L, n)
t = s + 1
return ([xs[p:p+t] for p in range(0, r*t, t)] +
[xs[p:p+s] for p in range(r*t, L, s)])
Here’s a second implementation, this time using itertools. Chaining r copies of s+1 and n-r copies of s gives us the n chunk widths. Accumulating the widths gives us the list offsets for slicing — though note we need to prepend an initial 0. Now we can form a (this, next) pair of iterators over the offsets, and the result is the accumulation of repeated (begin, end) slices taken from the original list.
from itertools import accumulate, chain, repeat, tee
def chunk(xs, n):
assert n > 0
L = len(xs)
s, r = divmod(L, n)
widths = chain(repeat(s+1, r), repeat(s, n-r))
offsets = accumulate(chain((0,), widths))
b, e = tee(offsets)
next(e)
return [xs[s] for s in map(slice, b, e)]
This version does something sensible in the case when the number of slices, n, exceeds the length of the list.
>>> chunk('ab', 5)
['a', 'b', '', '', '']
Finally, some tests.
def test_chunk():
assert chunk('', 1) == ['']
assert chunk('ab', 2) == ['a', 'b']
assert chunk('abc', 2) == ['ab', 'c']
xs = list(range(8))
assert chunk(xs, 2) == [[0, 1, 2, 3], [4, 5, 6, 7]]
assert chunk(xs, 3) == [[0, 1, 2], [3, 4, 5], [6, 7]]
assert chunk(xs, 5) == [[0, 1], [2, 3], [4, 5], [6], [7]]
rs = range(1000000)
assert chunk(rs, 2) == [range(500000), range(500000, 1000000)]
Agile at a distance 👍

I’m happy to be part of a team which supports remote working. This post collects a few notes on how agile practices fare when people may not be colocated. I don’t claim what’s written to be generally true; rather, it’s specific to me, my team, and how we work.

We’re by no means entirely distributed. There are seven of us in the engineering team, all UK based. We have a dedicated office space and of the seven, four are office-based and three are remote workers. Office-based staff are free to work from home when it suits. I’m office-based but work from home around 40% of the time, for example. Remote workers typically visit the office every couple of weeks to attend the sprint ceremonies — review, retrospective, planning. The rest of the company is more distributed and mobile, comprising product and marketing, medical experts, operations engineers, sales and admin.

From bytes to strings in Python and back again
Low level languages like C have little opinion about what goes in a string, which is simply a null-terminated sequence of bytes. Those bytes could be ASCII or UTF-8 encoded text, or they could be raw data — object code, for example. It’s quite possible and legal to have a C string with mixed content.
char const * mixed =
"EURO SIGN " // ASCII
"UTF-8 \xE2\x82\xAC " // UTF-8 encoded EURO SIGN
"Latin-9 \xA4"; // Latin-9 encoded EURO SIGN
This might seem indisciplined and risky but it can be useful. Environment variables are notionally text but actually C strings, for example, meaning they can hold whatever data you want. Similarly filenames and command line parameters are only loosely text.
A higher level language like Python makes a strict distinction between bytes and strings. Bytes objects contain raw data — a sequence of octets — whereas strings are Unicode sequences. Conversion between the two types is explicit: you encode a string to get bytes, specifying an encoding (which defaults to UTF-8); and you decode bytes to get a string. Clients of these functions should be aware that such conversions may fail, and should consider how failures are handled.
Simply put, a string in Python is a valid Unicode sequence. Real world text data may not be. Programmers need to take charge of reconciling any discrepancies.
We faced such problems recently at work. We’re in the business of extracting meaning from clinical narratives — text data stored on medical records systems in hospitals, for example. These documents may well have passed through a variety of systems. They may be unclear about their text encoding. They may not be encoded as they claim. So what? They can and do contain abbreviations, mispellings, jargon and colloquialisms. Refining the signal from such noise is our core business: if we can correctly interpret positional and temporal aspects of a sentence such as:
Previous fracture of left neck of femur
then we can surely deal with text which claims to be UTF-8 encoded but isn’t really.
Our application stack is server-based: a REST API to a Python application handles document ingest; lower down, a C++ engine does the actual document processing. The problem we faced was supporting a modern API capable of handling real world data.
It’s both undesirable and unnecessary to require clients to clean their text before submitting it. We want to make the ingest direct and idiomatic. Also, we shouldn’t penalise clients whose data is clean. Thus document upload is an HTTP POST request, and the document content is a JSON string — rather than, say, base64 encoded binary data. Our server, however, will be permissive about the contents of this string.
So far so good. Postel’s prescription advises:
Be liberal in what you accept, and conservative in what you send.
This would suggest accepting messy text data but presenting it in a cleaned up form. In our case, we do normalise the input data — a process which includes detecting and standardising date/time information, expanding abbreviations, fixing typos and so on — but this normalised form links back to a faithful copy of the original data. What gets presented to the user is their own text annotated with our findings. That is, we subscribe to a more primitive prescription than Postel’s:
Garbage in, garbage out
with the caveat that the garbage shouldn’t be damaged in transit.
Happily, there is a simple way to pass dodgy strings through Python. It’s used in the standard library to handle text data which isn’t guaranteed to be clean — those environment variables, command line parameters, and filenames for example.
The surrogateescape error handler smuggles non-decodable bytes into the (Unicode) Python string in such a way that the original bytes can be recovered on encode, as described in PEP 383:
On POSIX systems, Python currently applies the locale’s encoding to convert the byte data to Unicode, failing for characters that cannot be decoded. With this PEP, non-decodable bytes >= 128 will be represented as lone surrogate codes U+DC80..U+DCFF.
This workaround is possible because Unicode surrogates are intended for use in pairs. Quoting the Unicode specification, they “have no interpretation on their own”. The lone trailing surrogate code — the half-a-pair — can only be the result of a surrogateescape error handler being invoked, and the original bytes can be recovered by using the same error handler on encode.
In conclusion, text data is handled differently in C++ and Python, posing a problem for layered applications. The surrogateescape error handler provides a standard and robust way of closing the gap.
Unicode Surrogate Pairs

Code Listing
>>> mixed = b"EURO SIGN \xE2\x82\xAC \xA4"
>>> mixed
b'EURO SIGN \xe2\x82\xac \xa4'
>>> mixed.decode()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xa4 in position 14:
invalid start byte
>>> help(mixed.decode)
Help on built-in function decode:
decode(encoding='utf-8', errors='strict') method of builtins.bytes instance
Decode the bytes using the codec registered for encoding.
encoding
The encoding with which to decode the bytes.
errors
The error handling scheme to use for the handling of decoding errors.
The default is 'strict' meaning that decoding errors raise a
UnicodeDecodeError. Other possible values are 'ignore' and 'replace'
as well as any other name registered with codecs.register_error that
can handle UnicodeDecodeErrors.
>>> mixed.decode(errors='surrogateescape')
'EURO SIGN € \udca4'
>>> s = mixed.decode(errors='surrogateescape')
>>> s.encode()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'utf-8' codec can't encode character '\udca4' in position 12:
surrogates not allowed
>>> s.encode(errors='surrogateescape')
b'EURO SIGN \xe2\x82\xac \xa4'
24 Puzzles
On The Universe of Discourse Mark Dominus discusses the classic 24 Puzzle:
You are given a sequence of four digits, say 1, 2, 3, 4, and your job is to combine them with ordinary arithmetic operations (+, -, ×, and ÷) in any order to make a target number, typically 24. For example, with 1, 2, 3, 4, you can go with
((1+2)+3)×4=24or with4×((2×3)×1)=24.
Here’s a solver for such puzzles. It uses itertools to generate possible expressions, fractions to get the arithmetic right, and eval to evaluate expressions. It’s limited to expressions formed from 4 numbers which means I don’t have to programmatically calculate different ways of parenthesising: there are only 5.
# http://blog.plover.com/math/24-puzzle.html
import re
import math
# Use fractions for exact calculations
from fractions import Fraction
# Solve for 4 numbers only!
N = 4
# So these are the only expression templates
# where X is a number and @ is an operation
templates = '''\
((X @ X) @ X) @ X
(X @ (X @ X)) @ X
X @ ((X @ X) @ X)
X @ (X @ (X @ X))
(X @ X) @ (X @ X)'''.splitlines()
import itertools as its
def defrac(s):
return re.compile(r'Fraction\((\d+)\)').sub(r'\1', s)
def evaluate(nums, ops, template):
fracs = ('Fraction(%s)' % n for n in nums)
ops = iter(ops)
expr = ''.join(next(fracs) if c == 'X' else
next(ops) if c == '@' else c
for c in template)
try:
return expr, eval(expr)
except ZeroDivisionError:
return expr, None
def solve(spec, ops):
numbers = re.compile(r'\d+').findall(spec)
assert len(numbers) == N + 1
result = Fraction(numbers.pop())
seqs = its.product(its.permutations(numbers),
its.product(ops, repeat=N-1),
templates)
print(defrac(next((e for e, v in its.starmap(evaluate, seqs)
if v == result),
'Impossible')))
def main():
solve('2,5,6,6 => 17', '+-/*')
solve('3,3,8,8 => 24', '+-/*')
main()
Here’s a second attempt, which doesn’t assume there will just be 4 numbers on the left hand side of the equation. Given a sequence of numbers and a set of operators, it repeatedly reduces the sequence length by picking pair of numbers and combining them using one of the operators, iterating over all possible ways of doing this. The first sequence of length 1 which equals the target value gives a solution and terminates the search.
# http://blog.plover.com/math/24-puzzle.html
from fractions import Fraction
import itertools as its
import operator
import re
def pick2(xs):
return ((p[:2], p[2:]) for p in its.permutations(xs))
def allow(op, l, r):
return op != '/' or eval(r) != 0
def apply(op, l, r):
return '(%s%s%s)'%(l, op, r)
def values(xs, ops):
L = [xs]
while L:
xs = L.pop()
if len(xs) == 1:
yield xs.pop()
else:
L.extend([apply(op, *lr)] + list(tl)
for op, (lr, tl) in its.product(ops, pick2(xs))
if allow(op, *lr))
def solve(spec, ops):
numbers = ['Fraction(%s)'%n for n in re.compile(r'\d+').findall(spec)]
target = eval(numbers.pop())
print(next((v for v in values(numbers, ops) if eval(v) == target), 'Impossible'))
def main():
solve('2,5,6,6 => 17', '+-/*')
solve('3,3,8,8 => 24', '+-/*')
main()
Unit Tests Questioned: Reading List
I enjoyed talking about unit testing last night, and would like to thank Swansea Software Development Community and especially Viv Richards for organising the event, TechHub for the venue, and everyone who turned up to listen, ask questions and offer feedback.
Up first @thomasguest #ssdc pic.twitter.com/4nEqh0ErZr
— SSDC (@SwanseaSDC) January 30, 2017
The slides are available here. You’ll find links in the slide deck to the various papers and articles I referenced, but for convenience I’m listing them here with some notes.
How Did Software Get So Reliable Without Proof? by Sir Tony Hoare, published in 1996, is a considered and authoritative paper, in which the author calls into question much of his own research. It’s not necessary to prove your programs correct, he writes, you can create systems which are both large and reliable using more pragmatic techniques. Since then, his conviction has strengthened. I had the privilege of attending his keynote at Europython 2009, when he spoke about the science of computing and the engineering of software (this same talk is available on InfoQ). His closing slide stated: One day, software will be the most reliable component of every product which contains it; and software engineering will be the most dependable of all engineering professions.
Why Most Unit Testing is Waste by James O Coplien calls out the unit testing zealots and makes the point that testers should be skeptical.
How SQLite Is Tested details what it takes to make bomb-proof software. Most of the tests described are system level tests. It’s an impressive document which proves that writing tests requires creativity, determination and maybe even a sprinkling of malice.
Flaky Tests at Google and How We Mitigate Them is an honest and all too familiar tale of unreliable tests. However hard you try to eradicate test instabilities, it seems they creep back in at the same rate.
Goto Fail, Heartbleed, and Unit Testing Culture argues unit tests would have trapped some notorious bugs in low level security software. It goes on to describe in detail the changing culture of the Google Web Server team, which successfully adopted a test-focused regime. There’s some good advice on de-flaking, so I hope the author connected with his suffering colleagues.
The correspondence between Donald E. Knuth and Peter van Emde Boas on priority deques during the spring of 1977 provides the background and context of Donald Knuth’s famous quotation, “Beware of bugs in the above code; I have only proved it correct, not tried it”. It’s a a witty admonition but Donald Knuth isn’t joking. Don’t trust code until you’ve run it. Better, run it repeatedly through automated tests.
Unit Tests Questioned
I’m looking forward to talking at TechHub Swansea at the end of the month on the subject of unit testing.
The introduction to the talk is here.
Hope to see you there.

In this talk we’ll consider if unit testing is a good use of our time.
I am not questioning whether testing is important. This slide shows the abstract of a paper published in 1996 by Tony Hoare. What he says is that you don’t need to prove your software works: you can make it so through design and review; by testing; and by good engineering.

This may no longer seem controversial or novel but maybe it was a surprising thing for Tony Hoare to say. After all, he invented quicksort back in 1959, an algorithm which he proved correct. He also proved how quickly it runs, and that — in the general case — it couldn’t be beaten. Much of Hoare’s subsequent research was dedicated to proving software works using techniques known as formal methods. The idea is that you write a formal specification of what your program should do, and then you mathematically verify your code satisfies that specification. Surely nothing less is good enough for software which really is a matter of life and death: a life support system, or a device driver in a nuclear warhead, for example? Actually, no, he says in this paper, there are more pragmatic routes to reliable software.
So, the idea that you can build reliability via testing may once have seemed radical. It doesn’t any more. Maybe, though, the conventional modern wisdom that unit tests are a good thing should be questioned.

James O Coplien voices a dissenting opinion in a more recent paper, “Why most unit testing is waste”.
What’s Cope on about!?
Such is the force of current thinking that even the title of this paper makes it seem like he’s trolling. Having read the paper carefully, I don’t think he is. That doesn’t mean I agree with him, but I agree with his attitude:
There’s a lot of advice, but very little of it is backed either by theory, data, or even a model of why you should believe a given piece of advice. Good testing begs skepticism. Be skeptical of yourself: measure, prove, retry. Be skeptical of me for heaven’s sake.
So, this talk will do just that.
Unit tests: let’s get skeptical!
A language people use and bitch about
Every so often a new essay hits the top of the programming news sites:
- why I’m rewriting X in C (and abandoning C++)
- why we will never use C++ for Y (which has always been written in C)
- why C++ is a horrible language (it isn’t C)
I’m a sucker for these articles and have some sympathy with them. Every so often I work with C code rather than C++, and find the experience refreshing: rapid compilation, clear build diagnostics, comprehensible APIs, easy debugging, and an agreeable reduction in layering and punctuation.
It’s always easy to return to C because it hasn’t really changed. Well, it has changed, conservatively, and C programmers seem conservative in adopting new features.
By contrast, C++ does change. Sure, C++0X was a long time coming — finally realised as C++11 — but since that giant step, smaller improvements continue apace. As a result C++ code soon looks stale. Every time I visit a source file it seems I have to freshen it, using the new way to prevent copying, or return containers, or manage resources, or pass functions, or … you get the idea.
The truth is, every substantial C++ codebase I’ve worked on reads like a history of C++. Somewhere low down there’ll be hand-written intrusive linked lists; then there’ll be a few layers of classes, some nested for good measure; then templates, boost, functions disguised as classes for use in algorithms; and finally the good stuff, in which auto, lambda, move semantics and intialisers allow us to code as we’ve always wanted.
Bjarne Stroustrup defends C++ on his website:
As someone remarked: There are only two kinds of programming languages: those people always bitch about and those nobody uses.
If that “someone” wasn’t Stroustrup, it is now — he has become the source of his own quotation. His point is that C++ is well-used and must therefore be bitched about.
C provides an immediate counter-example, however. It is undeniably used, but its traps and pitfalls are known and respected, rather than bitched about.
Ultimately, though, I find C too limited. The lack of standard containers and algorithms combined with the overheads of heap management and ubiquitous error checking make programming in C heavy going.
C++ is hard to learn and hard to keep up with. The language has grown, considerably, but the progression is necessary. It’s the more recent extensions which fully realise the power of the standard template library, for example. Stick with C++. The reward will be code which is expressive and efficient.
Negative Sequence Indices in Python
Supply a negative index when accessing a sequence and Python counts back from the end. So, for example, my_list[-2] is the penultimate element of my_list, which is much better than my_list[len(my_list)-2] or even *(++my_list.rbegin()).
That final example uses one of C++’s reverse iterators. It gets the penultimate element of a collection by advancing an iterator from the reversed beginning of that collection. If you’re addicted to negative indices you can use them with C++ arrays, sort of.
#include <iostream>
int main()
{
char const * domain = "wordaligned.org";
char const * end = domain + strlen(domain);
std::cout << end[-3] << end[-2] << end[-1] << '\n';
return 0;
}
Compiling and running this program outputs the string “org”.
Going back to Python, the valid indices into a sequence of length L are -L, -L+1, … , 0, 1, … L-1. Whenever you write code to calculate an index used for accessing a sequence, and especially if you’re catching any resulting IndexErrors, it’s worth checking if the result of the calculation can be negative, and if — in this case — you really do want the from-the-back indexing behaviour.
The power of negative indices increases with slicing. Take a slice of a sequence by supplying begin and end indices.
>>> domain = 'wordaligned.org' >>> domain[4:9] 'align' >>> domain[4:-4] 'aligned' >>> digits = list(range(10)) >>> digits [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] >>> digits[3:4] [3] >>> digits[1:-1] [1, 2, 3, 4, 5, 6, 7, 8]
Omitting an index defaults it to the end of the sequence. Omit both indices and both ends of the sequence are defaulted, giving a sliced copy.
>>> domain[-3:] 'org' >>> domain[:4] 'word' >>> digits[:] [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
I prefer the list(digits) form for copying digits but you should certainly be familiar with the digits[:] version.
You can supply any indices as slice limits, even ones which wouldn’t be valid for item access. Imagine laying your sequence out on an indexed chopping board, slicing it at the specified points, then taking whatever lies between these points.
>>> digits[-1000000] Traceback (most recent call last): File "<stdin>", line 1, in <module> IndexError: list index out of range >>> digits[1000000] Traceback (most recent call last): File "<stdin>", line 1, in <module> IndexError: list index out of range >>> digits[-1000000:1000000] [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
Sequence slicing also takes a step parameter.
>>> digits[::2] [0, 2, 4, 6, 8] >>> digits[1::2] [1, 3, 5, 7, 9]
This parameter too can be negative. The sign of the step affects which limiting values the begin and end slice parameters default to. It’s subtle behaviour, but you soon get used to it.
>>> digits[0:10:-2] [] >>> digits[::-2] [9, 7, 5, 3, 1] >>> digits[-2::-2] [8, 6, 4, 2, 0]
How do you reverse a string? Slice it back to front!
>>> domain[::-1] 'gro.dengiladrow'
To recap: the default slice limits are the start and end of the sequence, 0 and -1, or -1 and 0 if the step is negative. The default step is 1 whichever way round the limits are. When slicing, s[i:j:k], i and j may take any integer value, and k can take any integer value except 0.
The zero value creates another interesting edge case. Here’s a function to return the last n items of a sequence.
>>> def tail(xs, n) ... return xs[-n:] ...
It fails when n is 0.
>>> tail(digits, 3) [7, 8, 9] >>> tail(digits, 2) [8, 9] >>> tail(digits, 1) [9] >>> tail(digits, 0) [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
By the way, we’ve already seen slicing working well with lists and strings. It also works nicely with range objects.
>>> r = range(10) >>> r[::2] range(0, 10, 2) >>> r[1::2] range(1, 10, 2)
Python Streams vs Unix Pipes
Contents
I chanced upon an interesting puzzle:
Find the smallest number that can be expressed as the sum of 5, 17, 563, 641 consecutive prime numbers, and is itself a prime number.

Here, the prime numbers are an infinite steam:
2, 3, 5, 7, 11, 13 ...
and sums of N consecutive primes are similarly infinite. For example, the sum of 2 consecutive primes would be the stream:
2+3, 3+5, 5+7, 7+11, 11+13 ...
which is:
5, 8, 12, 18, 24 ...
and the sum of 3 consecutive primes is:
10 (=2+3+5), 15, 23, 31 ...
Had we been asked to find the smallest number which can be expressed as the sum of 3 consecutive primes and as the sum of 5 consecutive primes and is itself prime, the answer would be 83.
>>> 23 + 29 + 31 83 >>> 11 + 13 + 17 + 19 + 23 83
Infinite series and Python
My first thought was to tackle this puzzle using Python iterators and generators. Here’s the outline of a strategy:
- starting with a stream of primes
- tee the stream to create 4 additional copies
- transform these copies into the consecutive sums of 5, 17, 563 and 641 primes
- now merge these consecutive sums back with the original primes stream
- group the elements of this merged stream by value
- the first group which contains 5 elements must have occurred in every source, and is therefore a prime and representable as the consecutive sum of 5, 17, 563 and 641 primes
- which solves the puzzle!
Note that when we copy an infinite stream we cannot consume it first. We will have to be lazy or we’ll get exhausted.
Courtesy of the Python Cookbook, I already had a couple of useful recipes to help implement this strategy:
def primes():
'''Generate the sequence of prime numbers: 2, 3, 5 ... '''
....
def stream_merge(*ss):
'''Merge a collection of sorted streams.
Example: merge multiples of 2, 3, 5
>>> from itertools import count, islice
>>> def multiples(x): return (x * n for n in count(1))
>>> s = stream_merge(multiples(2), multiples(3), multiples(5))
>>> list(islice(s, 10))
[2, 3, 4, 5, 6, 6, 8, 9, 10, 10]
'''
....
Both these functions merit a closer look for the cunning use they make of standard containers, but we’ll defer this inspection until later. In passing, note that stream_merge()’s docstring suggests we might try using it as basis for primes():
form the series of composite (non-prime) numbers by merging the streams formed by multiples of prime numbers;
the primes remain when you remove these composites from the series of natural numbers.
This scheme is hardly original — it’s a variant of Eratosthenes’ sieve — but if you look carefully you’ll notice the self-reference. Unfortunately recursive definitions of infinite series don’t work well with Python[1], hence primes() requires a little more finesse. We’ll take a look at it later.
Moving on, to solve the original puzzle we need a consecutive sum filter. This will transform a stream of numbers into a stream of consecutive sums of these numbers:
def consecutive_sum(s, n):
'''Generate the series of sums of n consecutive elements of s
Example: 0, 1, 2, 3, 4 ... => 0+1, 1+2, 2+3, 3+4, ...
>>> from itertools import count, islice
>>> list(islice(consecutive_sum(count(), 2), 10))
[1, 3, 5, 7, 9, 11, 13, 15, 17, 19]
'''
lo, hi = itertools.tee(s)
csum = sum(next(hi) for _ in range(n))
while True:
yield csum
csum += next(hi) - next(lo)
Here we can think of the summed elements as lying within a sliding window: each time we slide the window an element gets added to the top and an element gets removed from the bottom, and we adjust csum accordingly.
So, now we have:
-
the series of prime numbers,
primes() -
a
stream_merge()connector -
a
consecutive_sum()filter
The remaining stream adaptors come from the standard itertools module. Note that the stream_merge() works here since all the consecutive sum series are strictly increasing. Note also that the stream of prime numbers can be treated as consecutive_sum(s=primes(), n=1), handling the “and is itself a prime number” requirement.
>>> lens = 1, 5, 17, 563, 641
>>> N = len(lens)
>>> from itertools import tee, groupby
>>> ps = tee(primes(), N)
>>> csums = [consecutive_sum(p, n) for p, n in zip(ps, lens)]
>>> solns = (n for n, g in groupby(stream_merge(*csums))
if len(list(g)) == N)
Here, solns is yet another stream, the result of merging the N input consecutive sum streams then filtering out the numbers which appear N times; that is, the numbers which can be expressed as sums of 1, 5, 17, 563 and 641 consecutive primes.
The first such number solves the original puzzle.
>>> next(solns) 7002221
Here’s a picture of how these stream tools link up to solve this particular puzzle. The great thing is that we can reconnect these same tools to solve a wide range of puzzles, and indeed more practical processing tasks. To use the common analogy, we direct data streams along pipes.
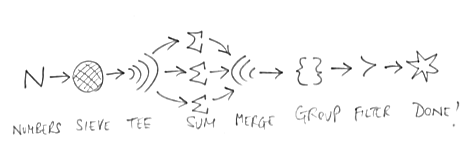
Infinite series in Other Languages
Python is the language I find most convenient most of the time, which explains why I reached for it first. It’s an increasingly popular language, which helps explain why I didn’t need to write the tricky parts of my solution from scratch: they’d already been done. Python is also a language which makes compromises. Having used Python to find a solution to the puzzle I wondered if there wasn’t some other language better suited to this kind of problem.
Haskell makes no compromises when it comes to functional programming. Its lazy evaluation and inductive recursion make it a perfect fit for this kind of puzzle — but my approach of teeing, filtering and merging made me consider the Unix Shell. Now, I use Bash every day and page through its manual at least once a week. Scripting appeals and I’m comfortable at the command line. How hard could it be to solve this puzzle using Bash? After all, I already knew the answer!
Partial sums.
Here’s a simple shell function to generate partial sums. I’ve used awk, a little language I gave up on a long time ago in favour of more rounded scripting languages like Perl and then Python. Now I look at it again, it seems to fill a useful gap. Awk processes a file sequentially, applying pattern-action rules to each line, a processing template which I’ve reinvented less cleanly many times. Despite my rediscovery of awk, I’ll be keeping its use strongly in check in what follows.
$ psum() { awk '{ print s += $1 }'; }
Much like Perl, awk guesses what you want to do. Here, it conjures the summation variable, s, into existence, assigning it a default initial value of 0. (Good guess!) Since we’re doing arithmetic awk converts the first field of each input line into a number. We can test psum by using jot to generate the sequence 1, 2, 3, 4, 5 (this is on a Mac — on a Linux platform use seq instead of jot).
$ jot 5 | psum 1 3 6 10 15
Consecutive sums
You may be wondering why we’ve bothered creating this partial sum filter since it’s the sums of consecutive elements we’re after, rather than the sum of the series so far. Well, notice that if P[i] and P[i+n] are two elements from the series of partial sums of S, then their difference, P[i+n] - P[i], is the sum of the n consecutive elements from S.
So to form an n-element consecutive sum series we can tee the partial sums streams, advance one of these by n, then zip through them in parallel finding their differences. An example makes things clear:
$ mkfifo pipe
$ jot 5 | psum | tee pipe | tail -n +2 | paste - pipe
3 1
6 3
10 6
15 10
15
Here, jot 5 generates the sequence 1, 2, 3, 4, 5, which psum progressively accumulates to 1, 3, 6, 10, 15. We then tee this partial sum series through two pipes: the first, pipe, is an explicitly created named pipe created by mkfifo, the second is implicitly created by the pipeline operator, |. The remainder of the command line delays one series by one (note that tail numbers lines from 1, not 0, so tail -n +1 is the identity filter) then pastes the two series back together[2].
By appending a single awk action to the pipeline we get a consecutive sum series.
$ jot 5 | psum | tee pipe | tail -n +2 | paste - pipe | awk '{print $1 - $2}'
2
3
4
5
15
The output 2, 3, 4, 5 is the series of consecutive sums of length 1 taken from the original series 1, 2, 3, 4, 5. The trailing 15 and the 1 missed from the start are edge case problems, and easily corrected.
Accumulating an increasing series of numbers in order to find the differences between elements lying a given distance apart on this series isn’t a very smart idea on a computer with a fixed word-size, but it’s good to know (e.g.) that awk doesn’t stop counting at 32 bits.
$ let "N=1<<32" && echo $N | tee >(awk '{print $1 * $1}')
4294967296
18446744073709551616
Exactly if and when awk stops counting, I’m not sure. The documentation doesn’t say and I haven’t looked at the source code.
Bug Fixes
Let’s capture these tiny functions and name them. Here, then, are revised psum() and sdiff() filters. The edge case problems should now be fixed.
$ psum() { awk 'BEGIN { print 0 }{print s += $1 }'; }
$ delay() { let "n = $1 + 1" && tail +$n; }
$ sdiff() { mkfifo p.$1 && tee p.$1 | delay $1 | paste - p.$1 | \
awk 'NF == 2 {print $1 - $2 }'; }
A quick test:
$ jot 5 | psum | sdiff 3 6 9 12
The output is, as expected, the series of sums of consecutive triples taken from 1, 2, 3, 4, 5 (6=1+2+3, 9=2+3+4, 12=3+4+5).
There’s a pernicious bug, though. These functions can’t handle infinite series so they are of limited use as pipeline tools. For example, if we stream in the series 0, 1, 2, … (generated here as the partial sums of the series 1, 1, 1, …) nothing gets output and we have to interrupt the process.
# This command appears to hang $ yes 1 | psum | sdiff 1 ^C
To work around this is, we can use Gnu stdbuf to prohibit tail and paste from using output buffers.
$ psum() { awk 'BEGIN { print 0 }{print s += $1 }'; }
$ delay() { let "n = $1 + 1" && stdbuf -o 0 tail +$n; }
$ sdiff() { mkfifo p.$1 && tee p.$1 | delay $1 | \
stdbuf -o 0 paste - p.$1 | \
awk 'NF == 2 {print $1 - $2 }'; }
Now the data flows again:
# Accumulate the stream 1 1 1 ... # and print the difference between successive elements $ yes 1 | psum | sdiff 1 1 1 1 1 ^C
Merging Streams
The Unix shell merges streams rather more succinctly than Python. Sort -m does the job directly. Note that a standard sort cannot yield any output until all its inputs are exhausted, since the final input item might turn out to be the one which should appear first in the output. Merge sort, sort -m, can and does produce output without delay[3].
$ yes | sort ^C $ yes | sort -m y y y y y ^C
Generating Primes
No doubt it’s possible to generate the infinite series of prime numbers using native Bash code, but I chose to reuse the Python Cookbook recipe for the job.
#!/usr/bin/env python
import itertools
def primes():
'''Generate the prime number series: 2, 3, 5 ... '''
D = {}
for n in itertools.count(2):
p = D.pop(n, None)
if p is None:
yield n
D[n * n] = n
else:
x = n + p
while x in D:
x += p
D[x] = p
for p in primes():
print(p)
This is a subtle little program which makes clever use of Python’s native hashed array container, the dictionary. In this case dictionary values are the primes less than n and the keys are composite multiples of these primes. The loop invariant, roughly speaking, is that the dictionary values are the primes less than n, and the corresponding keys are the lowest multiples of these primes greater than or equal to n. It’s a lazy, recursion-free take of Eratosthenes’ sieve.
For the purposes of this article the important things about this program are:
- it generates an infinite series of numbers to standard output[4], making it a good source for a shell pipeline
- by making it executable and adding the usual shebang incantation, we can invoke this Python program seamlessly from the shell.
Pipe Connection
Recall the original puzzle:
Find the smallest number that can be expressed as the sum of 5, 17, 563, 641 consecutive prime numbers, and is itself a prime number.
First, let’s check the connections by solving a simpler problem which we can manually verify: to find prime numbers which are also the sum of 2 consecutive primes. As we noted before, this is the same as finding primes numbers which are the consecutive sums of 1 and 2 primes.
In one shell window we create a couple of named pipes, c.1 and c.2, which we’ll use to stream the consecutive sum series of 1 and 2 primes respectively. The results series comprises the duplicates when we merge these pipes.
$ mkfifo c.{1,2}
$ sort -mn c.{1,2} | uniq -d
In another shell window, stream data into c.1 and c.2:
$ for i in 1 2; do (primes | psum | sdiff $i > c.$i) & done
In the first window we see the single number 5, which is the first and only prime number equal to the sum of two consecutive primes.
Prime numbers equal to the sum of three consecutive primes are more interesting. In each shell window recall the previous commands and switch the 2s to 3s (a simple command history recall and edit, ^2^3^, does the trick). The merged output now looks like this:
$ sort -mn c.1 c.3 | uniq -d 23 31 41 ...
We can check the first few values:
23 = 5 + 7 + 11 31 = 7 + 11 + 13 41 = 11 + 13 + 17
At this point we’re confident enough to give the actual puzzle a try. Start up the solutions stream.
$ mkfifo c.{1,5,17,563,641}
$ sort -mn c.{1,5,17,563,641} | uniq -c | grep "5 "
Here, we use a standard shell script set intersection recipe: uniq -c groups and counts repeated elements, and the grep pattern matches those numbers common to all five input streams.
Now we can kick off the processes which will feed into the consecutive sum streams, which sort is waiting on.
$ for i in 1 5 17 563 641; do (primes | psum | sdiff $i > c.$i) & done
Sure enough, after about 15 seconds elapsed time[5], out pops the result:
$ sort -mn c.{1,5,17,563,641} | uniq -c | grep "5 "
5 7002221
15 seconds seems an eternity for arithmetic on a modern computer (you could start up a word processor in less time!), and you might be inclined to blame the overhead of all those processes, files, large numbers, etc. In fact it took around 6 seconds for the Python program simply to generate prime numbers up to 7002221, and my pure Python solution ran in 9 seconds.
Portability
One of the most convenient things about Python is its portability. I don’t mean “portable so long as you conform to the language standard” or “portable if you stick to a subset of the language” — I mean that a Python program works whatever platform I use without me having to worry about it.
Non-portability put me off the Unix shell when I first encountered it: there seemed too many details, too many platform differences — which shell are you using? which extensions? which implementation of the core utilities, etc, etc? Readily available and well-written documentation didn’t help much here: generally I want the shell to just do what I mean, which is why I switched so happily to Perl when I discovered it.
Since then this situation has, for me, improved in many ways. Non-Unix platforms are declining as are the different flavours of Unix. Bash seems to have become the standard shell of choice and Cygwin gets better all the time. GNU coreutils predominate. As a consequence I’ve forgotten almost all the Perl I ever knew and am actively rediscovering the Unix shell.
Writing this article, though, I was reminded of the platform dependent behaviour which used to discourage me. On a Linux platform close to hand I had to use seq instead of jot, and awk formatted large integers in a scientific form with a loss of precision.
$ echo '10000000001 0' | awk '{print $1 - $2}'
1e+10
On OS X the same command outputs 10000000001. I couldn’t tell you which implementation is more correct. The fix is to explicitly format these numbers as decimal integers, but the danger is that the shell silently swallows these discrepancies and you’ve got a portability problem you don’t even notice.
$ echo '10000000001 0' | awk '{printf "%d\n", $1 - $2}'
10000000001
Stream Merge
I mentioned stream_merge() at the start of this article, a general purpose function written by Raymond Hettinger which I originally found in the Python Cookbook. As with the prime number generator, you might imagine the merge algorithm to be recursively defined:
to merge a pair of streams, take items from the first which are less than the head of the second, then swap;
to merge N streams, merge the first stream with the merged (N-1) rest.
Again the Python solution does it differently, this time using a heap as a priority queue of items from the input streams. It’s ingenious and efficient. Look how easy it is in Python to shunt functions and pairs in and out of queues.
from heapq import heapify, heappop, heapreplace
def stream_merge(*ss):
'''Merge a collection of sorted streams.'''
pqueue = []
for i in map(iter, ss):
try:
pqueue.append((i.next(), i.next))
except StopIteration:
pass
heapify(pqueue)
while pqueue:
val, it = pqueue[0]
yield val
try:
heapreplace(pqueue, (it(), it))
except StopIteration:
heappop(pqueue)
A more sophisticated version of this code has made it into the Python standard library, where it goes by the name of heapq.merge (I wonder why it wasn’t filed in itertools?)
Alternative Solutions
As usual Haskell wins the elegance award, so I’ll quote in full a solution built without resorting to cookbookery which produces the (correct!) answer in 20 seconds.
module Main where
import List
isPrime x = all (\i -> 0/=x`mod`i) $ takeWhile (\i -> i*i <= x) primes
primes = 2:filter (\x -> isPrime x) [3..]
cplist n = map (sum . take n) (tails primes)
meet (x:xs) (y:ys) | x < y = meet xs (y:ys)
| y < x = meet (x:xs) ys
| x == y = x:meet xs ys
main = print $ head $ \
(primes `meet` cplist 5) `meet` (cplist 17 `meet` cplist 563) `meet` cplist 641
[1] CPython, more precisely — I don’t think anything in the Python language itself prohibits tail recursion. Even using CPython, yet another recipe from the online Python Cookbook explores the idea of an @tail_recursion decorator.
[2] Tail is more commonly used to yield a fixed number of lines from the end of the file: by prefixing the line count argument with a + sign, it skips lines from the head of the file. The GNU version of head can similarly be used with a - prefix to skip lines at the tail of a file. The notation is {compact,powerful,subtle,implementation dependent}.
[3] Sort -m is a sort which doesn’t really sort — its inputs should already be sorted — rather like the +n option turning tail on its head.
[4] The series is infinite in theory only: at time n the number of items in the has_prime_factors dictionary equals the number of primes less than n, and each key in this dictionary is larger than n. So resource use increases steadily as n increases.
[5] I used a MacBook laptop used to run these scripts.
Model Name: MacBook Model Identifier: MacBook1,1 Processor Name: Intel Core Duo Processor Speed: 2 GHz Number Of Processors: 1 Total Number Of Cores: 2 L2 Cache (per processor): 2 MB Memory: 2 GB Bus Speed: 667 MHz
Productivity++ != Better
When it comes to productivity there seems to be an assumption that it’s a good thing, and that more equals better. I’d like to question that. What matters is producing the right stuff, whatever that is, and if you’re not sure, producing less would be better.
It can be hard to cancel work which is in progress or which has already been completed, even though, as software developers, version control can faithfully store and restore our work should we need it.
More tests does not equal better either. An increasing unit test count would seem uncontroversial, but let’s not forget we’re aiming for coverage and completeness whilst avoiding redundancy. Good unit tests and good design go hand in hand. Good unit tests avoid extended setup and good design reduces the need for combinatorial test suites. More system tests will slow down development, especially if they’re flaky.
I went to a wonderful and detailed talk at ACCU 2014 by Wojciech Seliga. He described his time as a development manager at Atlassian and the various steps taken to improve their CI builds: to speed them up and get them passing, that is. One particularly effective step was the daring elimination of an entire suite of fragile system tests. Late one evening, after a drink or two, a senior engineer just deleted them. Those tests haven’t failed since (!).
I wonder how that engineer felt. Nervous maybe, a bit reckless perhaps. But productive? Can destruction be productive?
On a similar note, one of the best changes made to the code base I work on has been to kill off unwanted configurations. We no longer support 32 bit builds: eliminating them has removed an entire class of integer conversion issues and slashed CI turnaround times. A reductive act, but one which allows us to produce more of what’s wanted.
What is wanted though?
The trouble is, if we’re not sure what to do, we like to do something, and we like to be seen to do something. We like to produce. We like to deliver. We don’t like to sit around in meetings talking about what to do. In these circumstances, though, production is questionable. More than once I have seen clean architecture crumble then decay, smothered by unwanted features.
Project dashboards can add to the problem. Graphics showing who added the most lines of code are open to misinterpretation and gaming. Who had the best ideas? Who reduced, removed or simplified? Does your dashboard display these metrics?
Remember, we are software developers, not software producers.
Go! Steady. Ready?
I’m looking forward to talking about Go at the ACCU 2016 Conference this Friday. If you’d like to find out what connects an Easter egg with flying horses and the runner in the green vest, then come along. Expect live coding, concurrent functions and answers.
>>> import antigravity

