Scaling the Datagram Team
If you’ve been following our recent product launches and posts, you may be curious about how our data infrastructure team functions and how it has grown to support the new products and experiences on Instagram. We operate a very lean team - only 20 engineers supporting Search, Explore, Trending, Account Suggestions, and Data Infrastructure - and have created a unique model that gives engineers end-to-end impact while working cohesively with the product and infrastructure teams. This post is about how we evolved into our team structure and lessons we hope you can also apply to your team as you scale.
The Beginning
When we started thinking about how to build out a data team for Instagram in 2013, there were only about 35 engineers working on our mobile apps and backend. I wasn’t one of them, and there was no engineering team dedicated to data infrastructure or products that relied on data processing like ranking and machine learning. I had experience with data infrastructure and product development at Facebook, and saw the chance to close the usual gap between those two worlds in a way that would fit Instagram’s engineering structure. Instead of focusing on infrastructure problems or offering some sort of ranking service to product teams, we decided to innovate and make it more of an end-to-end engineering team, covering both infrastructure and product aspects. Looking back, this was the best decision we could have made because it allowed us to be extremely efficient and take on some big impactful projects. Thus, Datagram, the Instagram Data Team, was born.
Team Scope
Our first challenge was to define a good scope for the team that wouldn’t interfere directly with the existing platform-oriented teams at Instagram (iOS, Android, and infrastructure). Luckily the need for data-oriented solutions was a strong point in our favor.
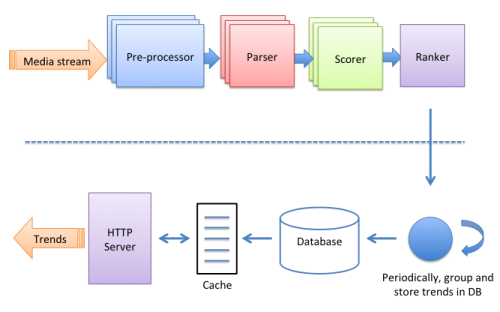
With the idea of being end-to-end, we organized the team around the lifecycle of data, demonstrated by the picture below. The first step is the collection of the data from the existing product and systems. That’s mostly infrastructure work like logging frameworks, streaming technologies, database scrapes, and data warehousing. After that comes the processing of the collected data, which includes things like real-time stream processing, data pipelines, ranking and machine learning algorithms. Processed data can then be used to power products like recommendation systems, discovery surfaces, and search. Building the application logic for such products is the last step of our approach and it closes the cycle as it generates more data to be collected.

This gave us a very well-defined “horizontal” scope that didn’t limit us to a specific subset of technologies or platforms, and avoided ownership ambiguity with the existing teams. The remaining question was whether to define a “vertical” scope for the team (the specific products we would cover) but we just followed the recipe of the other teams at Instagram and left it open to all existing parts of the product.
Being end-to-end and not restricted to a product allows us to be efficient in two ways. First, we only build the systems and the frameworks we actually need for our products. For example, when we were building our account suggestions feature, we only collected the data we needed and only did the ranking and machine learning necessary to build the product. Also, because this was all done by the same team of engineers, we were able to move really fast, with very easy coordination.
Second, we can be very efficient in the prioritization and execution of our projects at the company level. If there is an important sprint around a certain product area, it’s simple (and somewhat obvious) to de-prioritize other areas and get more hands on deck for the urgent deadline. Everyone on the team has a broad knowledge of the different products we are involved with, the infrastructure we have built, and their relative priorities. In general, something we learned along the way is that avoiding scopes centered on specific products and technologies makes everyone more open to different ideas and less defensive about existing solutions. When sprint scenarios arise, everyone is actually eager to jump in and help with it, and often bring great ideas with them.
Projects
The best way to showcase how we work is through examples. Here are a few of the projects we’ve worked on in the last year.
Search
As you can read extensively in our previous blog post, we’ve made some significant improvements to our Search product and its infrastructure over the last year, executed by just a handful of engineers. This was only possible because, when we were faced with the challenge of improving search, we were able to address it with a holistic perspective starting from the changes we needed to make on how we collected the data, our indexing infrastructure, and integrating all that efficiently with our ranking algorithms and UI.
Explore
A year and a half or so ago, the Explore tab would show only popular photos from our community, regardless of your preferences or connections. This experience wasn’t the best and we saw a lot of potential to increase the value and the engagement in that surface. Once more, we looked at the problem from a high level and broke it down into a series of long-term improvements to the product, being careful to make sure each step had some immediate gains as well so we didn’t have an all-or-nothing type of big deliverable. We personalized the photos people see based on their connections, created a surface to show account recommendations, and recently introduced trending places and hashtags. Finally, now that we have all our content indexed in our search infrastructure, we can use it as the source for photos explore content, allowing for better ranking and personalization.
Account suggestions
As important as suggestions are to activate new accounts and help them connect to their friends and interests, very little was being done before the team started. We extended the basic infrastructure to collect the data we needed to calculate the best recommendations, implemented some basic algorithms (mostly informed heuristics) and slowly introduced advanced ranking and machine learning techniques. As we evolved our suggestion systems, new opportunities surfaced and we evolved it into the idea of account pivots, automatically surfacing related recommendations when you follow a user’s profile. Some of this work pushed us to fundamentally change the way we were fetching our data, otherwise we wouldn’t be able to provide a good user experience in terms of reliability and latency. I doubt this would be in our radar if we weren’t doing everything end-to-end.
Analytics
Besides all the user-facing products we help build, our systems provide all of the data being used by our analytics team to assess the healthy of our growth and engagement. We introduced new logging frameworks and a built new systems to collect online and offline data. Obviously, we don’t want to reinvent the wheel so those things were only created because the differences in our technology stacks prevented us from using existing Facebook solutions. Having said that, we made sure to connect our data collection mechanisms to Facebook’s data warehousing systems (e.g., Hive, Presto), saving us a tremendous amount of work.
As the examples above demonstrate, the key to our success so far has been our end-to-end ownership of data problems and their solution. But our secret sauce also includes ruthless prioritization, only hiring people with the right experience to solve the problems we have, and favoring diversity of background so people can teach what they know and learn about the things they don’t know.
Continuity
Growing the team is inevitable no matter how efficient we are and we believe our principles should be able to scale. The main ideas of owning projects end-to-end and not being tied to platforms or temporary initiatives can be used as guidelines in any team or organization. We have started to introduce sub-teams on Datagram and things are going quite well so far with coverage areas divided into broader end-to-end themes like Discovery, Content, and Activation. Sub-teams share technologies and collaborate in multiple projects, which has kept us extremely efficient. Later this summer we are even starting a small Datagram presence in New York with a focus on content ranking across multiple parts of the app. The future is hard to predict, but it looks quite promising!
Rodrigo Schmidt manages Instagram’s data infrastructure engineering team.