AWS Blog
User Network-to-Amazon VPC Connectivity for Applications Hosted on AWS
With so much going on at AWS, we often hear from readers asking for ways to help them make more informed decisions, or put together examples for their planning processes. Joining us today is Jim Carroll, a Sr. Category Leader with Amazon Marketplace to talk about AWS Networking services and solutions in the AWS Marketplace.
-Ana
Last month we announced the new AWS Region in London. This new region expands our global infrastructure and provides our partners and customers with even more geographic options to cost-effectively scale and meet compliance and data residency requirements. This announcement is fresh in my mind because of conversations I’ve had recently with our customers about the AWS networking services and solutions in AWS Marketplace that they leverage to connect their corporate network to their virtual private network on the AWS Cloud.
Customers typically deploy this architecture with AWS in order to support one or a combination of business needs:
- Migrate applications to the AWS Cloud over time
- Quickly and cost-effectively scale their network for branch office and remote connectivity, improving end user experience while migrating applications to the AWS Cloud
- Ensure compliance and data residency requirements are met
Today, I will overview the VPN options available to customers with these business needs, to help simplify their decision-making. With Amazon VPC, you can configure an AWS managed VPN, use private circuit connectivity with AWS Direct Connect, and enable third-party networking software on your VPC for VPN connectivity. You may also choose a client-to-site VPN that allows users to directly access AWS from their desktop or mobile devices.
Steve Morad’s 2014 whitepaper, Amazon Virtual Private Cloud Connectivity Options, provides an overview of the remote network-to-Amazon VPC connectivity options. The table below summarizes these insights, followed by considerations for selecting an AWS managed VPN or a user-managed software VPN end-point in your virtual network on AWS. This discussion contains information from Morad’s whitepaper.
| User Network–to–Amazon VPC Connectivity Options | |
| AWS Managed VPN | IPsec VPN connection over the Internet |
| AWS Direct Connect | Dedicated network connection over private lines |
| AWS Direct Connect + VPN | IPsec VPN connection over private lines |
| AWS VPN CloudHub | Connect remote branch offices in a hub-and-spoke model for primary or backup connectivity |
| Software VPN | Software appliance-based VPN connection over the Internet |
AWS Managed VPN
This approach enables you to take advantage of an AWS-managed VPN endpoint that includes automated multi–data center redundancy and failover built into the AWS side of the VPN connection. Both dynamic and static routing options are provided to give you flexibility in your routing configuration. Figure 1 illustrates.
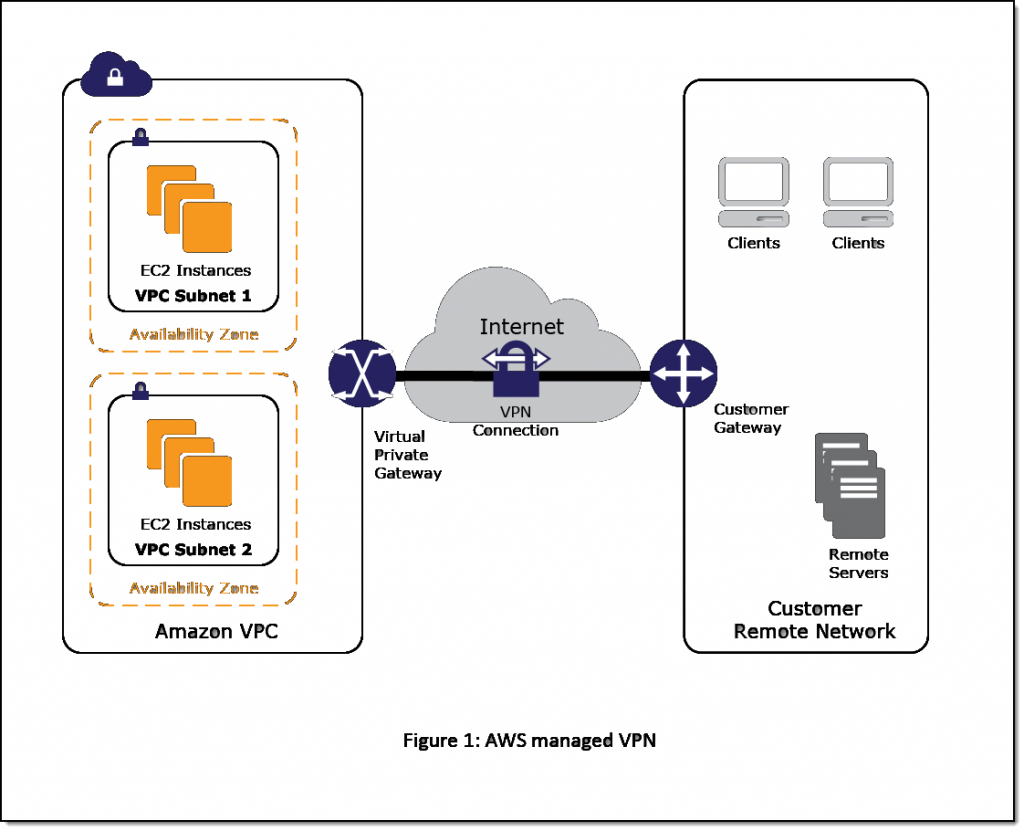
AWS managed VPN considerations:
- Although not shown, the Amazon virtual private gateway represents two distinct VPN endpoints, physically located in separate data centers to increase the availability of your VPN connection.
- Both dynamic and static routing options are provided to give you flexibility in your routing configuration.
- Dynamic routing leverages Border Gateway Protocol (BGP) peering to exchange routing information between AWS and these remote endpoints.
- With dynamic routing, you can also specify routing priorities, policies, and weights (metrics) in your BGP advertisements and influence the path between your network(s) and AWS.
- When using dynamic routing, routes advertised via BGP can be propagated into selected routing tables, making it easier to advertise new routes to AWS.
Software VPN
This option utilizes a software VPN appliance that runs on a single Amazon EC2 instance connecting to your remote network. This option requires that you manage both sides of your Amazon VPC connectivity, including managing the software appliance, configuration, patches, and upgrades.

This option is recommended if you must manage both ends of the VPN connection. Considerations:
- Compliance: You may need to use this approach for compliance and data residency requirements in your hybrid network architecture. IT security and privacy regulations govern specific industries and require your IT infrastructure, including your network, to meet certain government standards.
- Gateway device support: Customers with gateway devices that are not currently supported by the Amazon managed VPN solution, choose to deploy a Software VPN in order to leverage existing on-premises investments. The list of supported gateway devices is located here.
- Networking infrastructure solutions in AWS Marketplace: You can easily extend your on-premises networking infrastructure software with pre-configured and customizable AMIs from popular software vendors on AWS Marketplace.
Example of HA Architecture for Software VPN Instances
Creating a fully resilient VPC connection for software VPN instances requires the setup and configuration of multiple VPN instances and a monitoring instance to track the health of the VPN connections.

Figure 3: High-Level HA Design
We recommend configuring your VPC route tables to leverage all VPN instances simultaneously by directing traffic from all of the subnets in one Availability Zone through its respective VPN instances in the same Availability Zone. Each VPN instance will then provide VPN connectivity for instances that share the same Availability Zone. The white paper provides more information and considerations.
By leveraging networking infrastructure solutions from popular vendors such as Brocade and Cisco in AWS Marketplace, you can take full advantage of existing investments in on-premises systems and thecloud to meet your unique business challenges.
-Jim Carroll
Amazon Cloud Directory – A Cloud-Native Directory for Hierarchical Data
Our customers have traditionally used directories (typically Active Directory Lightweight Directory Service or LDAP-based) to manage hierarchically organized data. Device registries, course catalogs, network configurations, and user directories are often represented as hierarchies, sometimes with multiple types of relationships between objects in the same collection. For example, a user directory could have one hierarchy based on physical location (country, state, city, building, floor, and office), a second one based on projects and billing codes, and a third based on the management chain. However, traditional directory technologies do not support the use of multiple relationships in a single directory; you’d have to create and maintain additional directories if you needed to do this.
Scale is another important challenge. The fundamental operations on a hierarchy involve locating the parent or the child object of a given object. Given that hierarchies can be used to represent large, nested collections of information, these fundamental operations must be as efficient as possible, regardless of how many objects there are or how deeply they are nested. Traditional directories can be difficult to scale, and the pain only grows if you are using two or more in order to represent multiple hierarchies.
New Amazon Cloud Directory
 Today we are launching Cloud Directory. This service is purpose-built for storing large amounts of strongly typed hierarchical data as described above. With the ability to scale to hundreds of millions of objects while remaining cost-effective, Cloud Directory is a great fit for all sorts of cloud and mobile applications.
Today we are launching Cloud Directory. This service is purpose-built for storing large amounts of strongly typed hierarchical data as described above. With the ability to scale to hundreds of millions of objects while remaining cost-effective, Cloud Directory is a great fit for all sorts of cloud and mobile applications.
Cloud Directory is a building block that already powers other AWS services including Amazon Cognito and AWS Organizations. Because it plays such a crucial role within AWS, it was designed with scalability, high availability, and security in mind (data is encrypted at rest and while in transit).
Amazon Cloud Directory is a managed service; you don’t need to think about installing or patching software, managing servers, or scaling any storage or compute infrastructure. You simply define the schemas, create a directory, and then populate your directory by making calls to the Cloud Directory API. This API is designed for speed and for scale, with efficient, batch-based read and write functions.
The long-lasting nature of a directory, combined with the scale and the diversity of use cases that it must support over its lifetime, brings another challenge to light. Experience has shown that static schemas lack the flexibility to adapt to the changes that arise with scale and with new use cases. In order to address this challenge and to make the directory future-proof, Cloud Directory is built around a model that explicitly makes room for change. You simply extend your existing schemas by adding new facets. This is a safe operation that leaves existing data intact so that existing applications will continue to work as expected. Combining schemas and facets allows you to represent multiple hierarchies within the same directory. For example, your first hierarchy could mirror your org chart. Later, you could add an additional facet to track some additional properties for each employee, perhaps a second phone number or a social network handle. After that, you can could create a geographically oriented hierarchy within the same data: Countries, states, buildings, floors, offices, and employees.
As I mentioned, other parts of AWS already use Amazon Cloud Directory. Cognito User Pools use Cloud Directory to offer application-specific user directories with support for user sign-up, sign-in and multi-factor authentication. With Cognito Your User Pools, you can easily and securely add sign-up and sign-in functionality to your mobile and web apps with a fully-managed service that scales to support hundreds of millions of users. Similarly, AWS Organizations uses Cloud Directory to support creation of groups of related AWS accounts and makes good use of multiple hierarchies to enforce a wide range of policies.
Before we dive in, let’s take a quick look at some important Amazon Cloud Directory concepts:
Directories are named, and must have at least one schema. Directories store objects, relationships between objects, schemas, and policies.
Facets model the data by defining required and allowable attributes. Each facet provides an independent scope for attribute names; this allows multiple applications that share a directory to safely and independently extend a given schema without fear of collision or confusion.
Schemas define the “shape” of data stored in a directory by making reference to one or more facets. Each directory can have one or more schemas. Schemas exist in one of three phases (Development, Published, or Applied). Development schemas can be modified; Published schemas are immutable. Amazon Cloud Directory includes a collection of predefined schemas for people, organizations, and devices. The combination of schemas and facets leaves the door open to significant additions to the initial data model and subject area over time, while ensuring that existing applications will still work as expected.
Attributes are the actual stored data. Each attribute is named and typed; data types include Boolean, binary (blob), date/time, number, and string. Attributes can be mandatory or optional, and immutable or editable. The definition of an attribute can specify a rule that is used to validate the length and/or content of an attribute before it is stored or updated. Binary and string objects can be length-checked against minimum and maximum lengths. A rule can indicate that a string must have a value chosen from a list, or that a number is within a given range.
Objects are stored in directories, have attributes, and are defined by a schema. Each object can have multiple children and multiple parents, as specified by the schema. You can use the multiple-parent feature to create multiple, independent hierarchies within a single directory (sometimes known as a forest of trees).
Policies can be specified at any level of the hierarchy, and are inherited by child objects. Cloud Directory does not interpret or assign any meaning to policies, leaving this up to the application. Policies can be used to specify and control access permissions, user rights, device characteristics, and so forth.
Creating a Directory
Let’s create a directory! I start by opening up the AWS Directory Service Console and clicking on the first Create directory button:

I enter a name for my directory (users), choose the person schema (which happens to have two facets; more about this in a moment), and click on Next:

The predefined (AWS) schema will be copied to my directory. I give it a name and a version, and click on Publish:

Then I review the configuration and click on Launch:

The directory is created, and I can then write code to add objects to it.
Pricing and Availability
Cloud Directory is available now in the US East (Northern Virginia), US East (Ohio), US West (Oregon), EU (Ireland), Asia Pacific (Sydney), and Asia Pacific (Singapore) Regions and you can start using it today.
Pricing is based on three factors: the amount of data that you store, the number of reads, and the number of writes (these prices are for US East (Northern Virginia)):
- Storage – $0.25 / GB / month
- Reads – $0.0040 for every 10,000 reads
- Writes – $0.0043 for every 1,000 writes
In the Works
We have some big plans for Cloud Directory!
While the priorities can change due to customer feedback, we are working on cross-region replication, AWS Lambda integration, and the ability to create new directories via AWS CloudFormation.
— Jeff;
AWS Hot Startups- January 2017
It is the start of a new year and Tina Barr is back with many more great new startups to check out.
-Ana
Welcome back to another year of hot AWS-powered startups! We have three exciting new startups today:
- ClassDojo – Connecting teachers, students, and parents to the classroom.
- Nubank – A financial services startup reimagining the banking experience.
- Ravelin – A fraud detection company built on machine learning models.
If you missed any of last year’s featured startups, be sure to check out our Year in Review.
ClassDojo (San Francisco)
 Founded in 2011 by Liam Don and Sam Chaudhary, ClassDojo is a communication platform for the classroom. Teachers, parents, and students can use it throughout the day as a place to share important moments through photos, videos and messaging. With many classrooms today operating as a one-size-fits-all model, the ClassDojo founders wanted to improve the education system and connect the 700 million primary age kids in the world to the very best content and services. Sam and Liam started out by asking teachers what they would find most helpful for their classrooms, and many expressed that they wanted a more caring and inclusive community – one where they could be connected to everyone who was part of their classroom. With ClassDojo, teachers are able to create their own classroom culture in partnership with students and their parents.
Founded in 2011 by Liam Don and Sam Chaudhary, ClassDojo is a communication platform for the classroom. Teachers, parents, and students can use it throughout the day as a place to share important moments through photos, videos and messaging. With many classrooms today operating as a one-size-fits-all model, the ClassDojo founders wanted to improve the education system and connect the 700 million primary age kids in the world to the very best content and services. Sam and Liam started out by asking teachers what they would find most helpful for their classrooms, and many expressed that they wanted a more caring and inclusive community – one where they could be connected to everyone who was part of their classroom. With ClassDojo, teachers are able to create their own classroom culture in partnership with students and their parents.
In five years, ClassDojo has expanded to 90% of K-8 schools in the US and 180 other countries, and their content has been translated into over 35 languages. Recently, they have expanded further into classrooms with video series on Empathy and Growth Mindset that were co-created with Harvard and Stanford. These videos have now been seen by 1 in 3 kids under the age of 14 in the U.S. One of their products called Stories allows for instantly updated streams of pictures and videos from the school day, all of which are shared at home with parents. Students can even create their own stories – a timeline or portfolio of what they’ve learned.
Because ClassDojo sees heavy usage during the school day and across many global time zones, their traffic patterns are highly variable. Amazon EC2 autoscaling allows them to meet demand while controlling costs during quieter periods. Their data pipeline is built entirely on AWS – Amazon Kinesis allows them to stream high volumes of data into Amazon Redshift for analysis and into Amazon S3 for archival. They also utilize Amazon Aurora and Amazon RDS to store sensitive relational data, which makes at-rest encryption easy to manage, while scaling to meet very high query volumes with incredibly low latency. All of ClassDojo’s web frontends are hosted on Amazon S3 and served through Amazon CloudFront, and they use AWS WAF rules to secure their frontends against attacks and unauthorized access. To detect fraudulent accounts they have used Amazon Machine Learning, and are also exploring the new Amazon Lex service to provide voice control so that teachers can use their products hands-free in the classroom.
Check out their blog to see how teachers across the world are using ClassDojo in their classrooms!
Nubank (Brazil)
 Nubank is a technology-driven financial services startup that is working to redefine the banking standard in Brazil. Founder David Vélez with a team of over 350 engineers, scientists, designers, and analysts, they have created a banking alternative in one of the world’s fastest growing mobile markets. Not only is Brazil the world’s 5th largest country in both area and population, but it also has one of the highest credit card interest rates in the world. Nubank has reimagined the credit card experience for a world where everyone has access to smartphones and offers a product customers haven’t seen before.
Nubank is a technology-driven financial services startup that is working to redefine the banking standard in Brazil. Founder David Vélez with a team of over 350 engineers, scientists, designers, and analysts, they have created a banking alternative in one of the world’s fastest growing mobile markets. Not only is Brazil the world’s 5th largest country in both area and population, but it also has one of the highest credit card interest rates in the world. Nubank has reimagined the credit card experience for a world where everyone has access to smartphones and offers a product customers haven’t seen before.
The Brazilian banking industry is both heavily regulated and extremely concentrated. Nubank saw an opportunity for companies that are truly customer-centric and have better data and technology to compete in an industry that has seen little innovation in decades. With Nubank’s mobile app customers are able to block and unblock their credit cards, change their credit limits, pay their bills, and have access to all of their purchases in real time. They also offer 24/7 customer support through digital channels and clear and simple communication. This was previously unheard of in Brazil’s banking industry, and Nubank’s services have been extremely well-received by customers.
From the start, Nubank’s leaders planned for growth. They wanted to build a system that could meet the ever changing regulatory and business rules, have full auditing capability and scale in both size and complexity. They use many AWS services including Amazon DynamoDB, Amazon EC2, Amazon S3, and AWS CloudFormation. By using AWS, Nubank developed its credit card processing platform in only seven months and are able to add features with ease.
Go to Nubank’s blog for more information!
Ravelin (London)
 Launched in 2015, Ravelin is a fraud detection company that works with many leading e-commerce and on-demand companies in a range of sectors including travel, retail, food delivery, ticketing, and transport. The company’s founders (Martin Sweeney, Leonard Austin, Mairtain O’Riada, and Nicky Lally) began their work while trying to solve fraud issues in an on-demand taxi business, which required accurate fraud predictions about a customer with limited information and then making that fraud decision almost instantly. They soon found that there was nothing on the market that was able to do this, and so the founders left to start Ravelin.
Launched in 2015, Ravelin is a fraud detection company that works with many leading e-commerce and on-demand companies in a range of sectors including travel, retail, food delivery, ticketing, and transport. The company’s founders (Martin Sweeney, Leonard Austin, Mairtain O’Riada, and Nicky Lally) began their work while trying to solve fraud issues in an on-demand taxi business, which required accurate fraud predictions about a customer with limited information and then making that fraud decision almost instantly. They soon found that there was nothing on the market that was able to do this, and so the founders left to start Ravelin.
Ravelin allows its clients to spend less time on manual reviews and instead focus on servicing their customers. Their machine learning models are built to predict good and bad behavior based on the relevant customer behavioral and payment data sent via API. Spotting bad behavior helps Ravelin to prevent fraud, and equally importantly, spotting good patterns means fewer good customers are being blocked. Ravelin chose machine learning as their core technology due to its incredible accuracy at a speed and scale that aligns with how their clients’ businesses operate.
Ravelin uses a suite of AWS services to help their machine learning algorithms detect fraud. Their clients are spread all over the world and their peak traffic times can be unpredictable so they scale their Amazon EC2 infrastructure multiple times a day, which helps with handling increased traffic while minimizing server costs. Ravelin also uses services such as Amazon RDS, Amazon DynamoDB, Amazon ElastiCache, and Amazon Elasticsearch Service. Utilizing these services has allowed the Ravelin team more time to concentrate on building fraud detection software.
For the latest in fraud prevention, be sure to check out Ravelin’s blog!
-Tina Barr
AWS IPv6 Update – Global Support Spanning 15 Regions & Multiple AWS Services
We’ve been working to add IPv6 support to many different parts of AWS over the last couple of years, starting with Elastic Load Balancing, AWS IoT, AWS Direct Connect, Amazon Route 53, Amazon CloudFront, AWS WAF, and S3 Transfer Acceleration, all building up to last month’s announcement of IPv6 support for EC2 instances in Virtual Private Clouds (initially available for use in the US East (Ohio) Region).
Today I am happy to share the news that IPv6 support for EC2 instances in VPCs is now available in a total of fifteen regions, along with Application Load Balancer support for IPv6 in nine of those regions.
You can now build and deploy applications that can use IPv6 addresses to communicate with servers, object storage, load balancers, and content distribution services. In accord with the latest guidelines for IPv6 support from Apple and other vendors, your mobile applications can now make use of IPv6 addresses when they communicate with AWS.
IPv6 Now in 15 Regions
IPv6 support for EC2 instances in new and existing VPCs is now available in the US East (Northern Virginia), US East (Ohio), US West (Northern California), US West (Oregon), South America (São Paulo), Canada (Central), EU (Ireland), EU (Frankfurt), EU (London), Asia Pacific (Tokyo), Asia Pacific (Singapore), Asia Pacific (Seoul), Asia Pacific (Sydney), Asia Pacific (Mumbai), and AWS GovCloud (US) Regions and you can start using it today!
You can enable IPv6 from the AWS Management Console when you create a new VPC:

Application Load Balancer
Application Load Balancers in the US East (Northern Virginia), US West (Northern California), US West (Oregon), South America (São Paulo), EU (Ireland), Asia Pacific (Tokyo), Asia Pacific (Singapore), Asia Pacific (Sydney), and AWS GovCloud (US) Regions now support IPv6 in dual-stack mode, making them accessible via IPv4 or IPv6 (we expect to add support for the remaining regions within a few weeks).
Simply enable the dualstack option when you configure the ALB and then make sure that your security groups allow or deny IPv6 traffic in accord with your requirements. Here’s how you select the dualstack option:

You can also enable this option by running the set-ip-address-type command or by making a call to the SetIpAddressType function. To learn more about this new feature, read the Load Balancer Address Type documentation.
IPv6 Recap
Here are the IPv6 launches that we made in the run-up to the launch of IPv6 support for EC2 instances in VPCs:
CloudFront, WAF, and S3 Transfer Acceleration – This launch let you enable IPv6 support for individual CloudFront distributions. Newly created distributions supported IPv6 by default and existing distributions could be upgraded with a couple of clicks (if you using Route 53 alias records, you also need to add an AAAA record to the domain). With IPv6 support enabled, the new addresses will show up in the CloudFront Access Logs. The launch also let you use AWS WAF to inspect requests that arrive via IPv4 or IPv6 addresses and to use a new, dual-stack endpoint for S3 Transfer Acceleration.
Route 53 – This launch added support for DNS queries over IPv6 (support for the requisite AAAA records was already in place). A subsequent launch added support for Health Checks of IPv6 Endpoints, allowing you to monitor the health of the endpoints and to arrange for DNS failover.
IoT – This product launch included IPv6 support for message exchange between devices and AWS IoT.
S3 – This launch added support for access to S3 buckets via dual-stack endpoints.
Elastic Load Balancing – This launch added publicly routable IPv6 addresses for Elastic Load Balancers.
Direct Connect – Supports single and dualstack configurations on public and private VIFs (virtual interfaces).
— Jeff;
AWS Web Application Firewall (WAF) for Application Load Balancers
I’m still catching up on a couple of launches that we made late last year!
Today’s post covers two services that I’ve written about in the past — AWS Web Application Firewall (WAF) and AWS Application Load Balancer:
AWS Web Application Firewall (WAF) – Helps to protect your web applications from common application-layer exploits that can affect availability or consume excessive resources. As you can see in my post (New – AWS WAF), WAF allows you to use access control lists (ACLs), rules, and conditions that define acceptable or unacceptable requests or IP addresses. You can selectively allow or deny access to specific parts of your web application and you can also guard against various SQL injection attacks. We launched WAF with support for Amazon CloudFront.
AWS Application Load Balancer (ALB) – This load balancing option for the Elastic Load Balancing service runs at the application layer. It allows you to define routing rules that are based on content that can span multiple containers or EC2 instances. Application Load Balancers support HTTP/2 and WebSocket, and give you additional visibility into the health of the target containers and instances (to learn more, read New – AWS Application Load Balancer).
Better Together
Late last year (I told you I am still catching up), we announced that WAF can now help to protect applications that are running behind an Application Load Balancer. You can set this up pretty quickly and you can protect both internal and external applications and web services.
I already have three EC2 instances behind an ALB:

I simple create a Web ACL in the same region and associate it with the ALB. I begin by naming the Web ACL. I also instruct WAF to publish to a designated CloudWatch metric:

Then I add any desired conditions to my Web ACL:

For example, I can easily set up several SQL injection filters for the query string:

After I create the filter I use it to create a rule:

And then I use the rule to block requests that match the condition:

To pull it all together I review my settings and then create the Web ACL:

Seconds after I click on Confirm and create, the new rule is active and WAF is protecting the application behind my ALB:

And that’s all it takes to use WAF to protect the EC2 instances and containers that are running behind an Application Load Balancer!
Learn More
To learn more about how to use WAF and ALB together, plan to attend the Secure Your Web Applications Using AWS WAF and Application Load Balancer webinar at 10 AM PT on January 26th.
You may also find the Secure Your Web Application With AWS WAF and Amazon CloudFront presentation from re:Invent to be of interest.
— Jeff;
Introducing the AWS IoT Button Enterprise Program
The AWS IoT Button first made its appearance on the IoT scene in October of 2015 at AWS re:Invent with the introduction of the AWS IoT service. That year all re:Invent attendees received the AWS IoT Button providing them the opportunity to get hands-on with AWS IoT. Since that time AWS IoT button has been made broadly available to anyone interested in the clickable IoT device.
During this past AWS re:Invent 2016 conference, the AWS IoT button was launched into the enterprise with the AWS IoT Button Enterprise Program. This program is intended to help businesses to offer new services or improve existing products at the click of a physical button. With the AWS IoT Button Enterprise Program, enterprises can use a programmable AWS IoT Button to increase customer engagement, expand applications and offer new innovations to customers by simplifying the user experience. By harnessing the power of IoT, businesses can respond to customer demand for their products and services in real-time while providing a direct line of communication for customers, all via a simple device.

AWS IoT Button Enterprise Program
Let’s discuss how the new AWS IoT Button Enterprise Program works. Businesses start by placing a bulk order of the AWS IoT buttons and provide a custom label for the branding of the buttons. Amazon manufactures the buttons and pre-provisions the IoT button devices by giving each a certificate and unique private key to grant access to AWS IoT and ensure secure communication with the AWS cloud. This allows for easier configuration and helps customers more easily get started with the programming of the IoT button device.
Businesses would design and build their IoT solution with the button devices and creation of device companion applications. The AWS IoT Button Enterprise Program provides businesses some complimentary assistance directly from AWS to ensure a successful deployment. The deployed devices then would only need to be configured with Wi-Fi at user locations in order to function.

For enterprises, there are several use cases that would benefit from the implementation of an IoT button solution. Here are some ideas:
- Reordering services or custom products such as pizza or medical supplies
- Requesting a callback from a customer service agent
- Retail operations such as a call for assistance button in stores or restaurants
- Inventory systems for capturing products amounts for inventory
- Healthcare applications such as alert or notification systems for the disabled or elderly
- Interface with Smart Home systems to turn devices on and off such as turning off outside lights or opening the garage door
- Guest check-in/check-out systems
AWS IoT Button
At the heart of the AWS IoT Button Enterprise Program is the AWS IoT Button. The AWS IoT button is a 2.4GHz Wi-Fi with WPA2-PSK enabled device that has three click types: Single click, Double click, and Long press. Note that a Long press click type is sent if the button is pressed for 1.5 seconds or longer. The IoT button has a small LED light with color patterns for the status of the IoT button. A blinking white light signifies that the IoT button is connecting to Wi-Fi and getting an IP address, while a blinking blue light signifies that the button is in wireless access point (AP) mode. The data payload that is sent from the device when pressed contains the device serial number, the battery voltage, and the click type.
Currently, there are 3 ways to get started building your AWS IoT button solution. The first option is to use the AWS IoT Button companion mobile app. The mobile app will create the required AWS IoT resources, including the creation of the TLS 1.2 certificates, and create an AWS IoT rule tied to AWS Lambda. Additionally, it will enable the IoT button device via AWS IoT to be an event source that invokes a new AWS Lambda function of your choosing from the Lambda blueprints. You can download the aforementioned mobile apps for Android and iOS below.
 |
 |
The second option is to use the AWS Lambda Blueprint Wizard as an easy way to start using your AWS IoT Button. Like the mobile app, the wizard will create the required AWS IoT resources for you and add an event source to your button that invokes a new Lambda function.
The third option is to follow the step by step tutorial in the AWS IoT getting started guide and leverage the AWS IoT console to create these resources manually.
Once you have configured your IoT button successfully and created a simple one-click solution using one of the aforementioned getting started guides, you should be ready to start building your own custom IoT button solution. Using a click of a button, your business will be able to build new services for customers, offer new features for existing services, and automate business processes to operate more efficiently.
The basic technical flow of an AWS IoT button solution is as follows:
- A button is clicked and secure connection is established with AWS IoT with TLS 1.2
- The button data payload is sent to AWS IoT Device Gateway
- The rules engine evaluates received messages (JSON) published into AWS IoT and performs actions or trigger AWS Services based defined business rules.
- The triggered AWS Service executes or action is performed
- The device state can be read, stored and set with Device Shadows
- Mobile and Web Apps can receive and update data based upon action

Now that you have general knowledge about the AWS IoT button, we should jump into a technical walk-through of building an AWS IoT button solution.
AWS IoT Button Solution Walkthrough
We will dive more deeply into building an AWS IoT Button solution with a quick example of a use case for providing one-click customer service options for a business.
To get started, I will go to the AWS IoT console, register my IoT button as a Thing and create a Thing type. In the console, I select the Registry and then Things options in console menu.

The name of my IoT thing in this example will be TEW-AWSIoTButton. If you desire to categorize the IoT things, you can create a Thing type and assign a type to similar IoT ‘things’. I will categorize my IoT thing, TEW-AWSIoTButton, as an IoTButton thing type with a One-click-device attribute key and select Create thing button.

After my AWS IoT button device, TEW-AWSIoTButton, is registered in the Thing Registry, the next step is to acquire the required X.509 certificate and keys. I will have AWS IoT generate the certificate for this device, but the service allows for to use your own certificates. Authenticating the connection with the X.509 certificates helps to protect the data exchange between your device and AWS IoT service.

When the certificates are generated with AWS IoT, it is important that you download and save all of the files created since the public and private keys will not be available after you leave the download page. Additionally, do not forget to download the root CA for AWS IoT from the link provided on the page with your generated certificates.
The newly created certificate will be inactive, therefore, it is vital that you activate the certificate prior to use. AWS IoT uses the TLS protocol to authenticate the certificates using the TLS protocol’s client authentication mode. The certificates enable asymmetric keys to be used with devices, and AWS IoT service will request and validate the certificate’s status and the AWS account against a registry of certificates. The service will challenge for proof of ownership of the private key corresponding to the public key contained in the certificate. The final step in securing the AWS IoT connection to my IoT button is to create and/or attach an IAM policy for authorization.

I will choose the Attach a policy button and then select Create a Policy option in order to build a specific policy for my IoT button. In Name field of the new IoT policy, I will enter IoTButtonPolicy for the name of this new policy. Since the AWS IoT Button device only supports button presses, our AWS IoT button policy will only need to add publish permissions. For this reason, this policy will only allow the iot:Publish action.
For the Resource ARN of the IoT policy, the AWS IoT buttons typically follow the format pattern of: arn: aws: iot: TheRegion: AWSAccountNumber: topic/ iotbutton /ButtonSerialNumber. This means that the Resource ARN for this IoT button policy will be:

I should note that if you are creating an IAM policy for an IoT device that is not an AWS IoT button, the Resource ARN format pattern would be as follows: arn: aws: iot: TheRegion: AWSAccountNumber: topic/ YourTopic/ OptionalSubTopic/
The created policy for our AWS IoT Button, IoTButtonPolicy, looks as follows:

The next step is to return to the AWS IoT console dashboard, select Security and then Certificates menu options. I will choose the certificate created in the aforementioned steps.

Then on the selected certificate page, I will select the Actions dropdown on the far right top corner. In order to add the IoTButtonPolicy IAM policy to the certificate, I will click the Attach policy option.


I will repeat all of the steps mentioned above but this time I will add the TEW-AWSIoTButton thing by selecting the Attach thing option.

All that is left is to add the certificate and private key to the physical AWS IoT button and connect the AWS IoT Button to Wi-Fi in order to have the IoT button be fully functional.
Important to note: For businesses that have signed up to participate in the AWS IoT Button Enterprise Program, all of these aforementioned steps; Button logo branding, AWS IoT thing creation, obtaining certificate & key creation, and adding certificates to buttons, are completed for them by Amazon and AWS. Again, this is to help make it easier for enterprises to hit the ground running in the development of their desired AWS IoT button solution.
Now, going back to the AWS IoT button used in our example, I will connect the button to Wi-Fi by holding the button until the LED blinks blue; this means that the device has gone into wireless access point (AP) mode.

In order to provide internet connectivity to the IoT button and start configuring the device’s connection to AWS IoT, I will connect to the button’s Wi-Fi network which should start with Button ConfigureMe. The first time the connection is made to the button’s Wi-Fi, a password will be required. Enter the last 8 characters of the device serial number shown on the back of the physical AWS IoT button device.


The AWS IoT button is now configured and ready to build a system around it. The next step will be to add the actions that will be performed when the IoT button is pressed. This brings us to the AWS IoT Rules engine, which is used to analyze the IoT device data payload coming from the MQTT topic stream and/or Device Shadow, and trigger AWS Services actions. We will set up rules to perform varying actions when different types of button presses are detected.
Our AWS IoT button solution will be a simple one, we will set up two AWS IoT rules to respond to the IoT button being clicked and the button’s payload being sent to AWS IoT. In our scenario, a single button click will represent that a request is being sent by a customer to a fictional organization’s customer service agent. A double click, however, will represent that a text will be sent containing a customer’s fictional current account status.
The first AWS IoT rule created will receive the IoT button payload and connect directly to Amazon SNS to send an email only if the rule condition is fulfilled that the button click type is SINGLE. The second AWS IoT rule created will invoke a Lambda function that will send a text message containing customer account status only if the rule condition is fulfilled that the button click type is DOUBLE.

In order to create the AWS IoT rule that will send an email to subscribers of an SNS topic for requesting a customer service agent’s help, we will go to Amazon SNS and create a SNS topic.

I will create an email subscription to the topic with the fictional subscribed customer service email, which in this case is just my email address. Of course, this could be several customer service representatives that are subscribed to the topic in order to receive emails for customer assistance requests.

Now returning to the AWS IoT console, I will select the Rules menu and choose the Create rule option. I first provide a name and description for the rule.

Next, I select the SQL version to be used for the AWS IoT rules engine. I select the latest SQL version, however, if I did not choose to set a version, the default version of 2015-10-08 will be used. The rules engine uses a SQL-like syntax with statements containing the SELECT, FROM, and WHERE clauses. I want to return a literal string for the message, which is not apart of the IoT button data payload. I also want to return the button serial number as the accountnum, which are not apart of the payload. Since the latest version, 2016-03-23, supports literal objects, I will be able to send a custom payload to Amazon SNS.

I have created the rule, all that is left is to add a rule action to perform when the rule is analyzed. As I mentioned above, an email should be sent to customer service representatives when this rule is triggered by a single IoT button press. Therefore, my rule action will be the Send a message as an SNS push notification to the SNS topic that I created to send an email to our fictional customer service reps aka me. Remember that the use of an IAM role is required to provide access to SNS resources; if you are using the console you have the option to create a new role or update an existing role to provide the correct permissions. Also, since I am doing a custom message and pushing to SNS, I select the Message format type to be RAW.


Our rule has been created, now all that is left is for us to test that an email is successfully sent when the AWS IoT button is pressed once, and therefore the data payload has a click type of SINGLE.

A single press of our AWS IoT Button and the custom message is published to the SNS Topic, and the email shown below was sent to the subscribed customer service agents email addresses; in this example, to my email address.

In order to create the AWS IoT rule that will send a text via Lambda and a SNS topic for the scenario in which customers request account status to be sent when the IoT Button is pressed twice. We will start by creating an AWS IoT rule with an AWS Lambda action. To create this IoT rule, we first need to create a Lambda function and the SNS Topic with a SNS text based subscription.
First, I will go to the Amazon SNS console and create a SNS Topic. After the topic is created, I will create a SNS text subscription for our SNS topic and add a number that will receive the text messages. I will then copy the SNS Topic ARN for use in my Lambda function. Please note, that I am creating the SNS Topic in a different region than previously created SNS topic to use a region with support for sending SMS via SNS. In the Lambda function, I will need to ensure the correct region for the SNS Topic is used by including the region as a parameter of the constructor of the SNS object. The created SNS topic, aws-iot-button-topic-text is shown below.

We now will go to the AWS Lambda console and create a Lambda function with an AWS IoT trigger, an IoT Type as IoT Button, and the requested Device Serial Number will be the serial number on the back of our AWS IoT Button. There is no need to generate the certificate and keys in this step because the AWS IoT button is already configured with certificates and keys for secure communication with AWS IoT.

The next is to create the Lambda function, IoTNotifyByText, with the following code that will receive the IoT button data payload and create a message to publish to Amazon SNS.
'use strict';
console.log('Loading function');
var AWS = require("aws-sdk");
var sns = new AWS.SNS({region: 'us-east-1'});
exports.handler = (event, context, callback) => {
// Load the message as JSON object
var iotPayload = JSON.stringify(event, null, 2);
// Create a text message from IoT Payload
var snsMessage = "Attention: Customer Info for Account #: " + event.accountnum + " Account Status: In Good Standing " +
"Balance is: 1234.56"
// Log payload and SNS message string to the console and for CloudWatch Logs
console.log("Received AWS IoT payload:", iotPayload);
console.log("Message to send: " + snsMessage);
// Create params for SNS publish using SNS Topic created for AWS IoT button
// Populate the parameters for the publish operation using required JSON format
// - Message : message text
// - TopicArn : the ARN of the Amazon SNS topic
var params = {
Message: snsMessage,
TopicArn: "arn:aws:sns:us-east-1:xxxxxxxxxxxx:aws-iot-button-topic-text"
};
sns.publish(params, context.done);
};All that is left is for us to do is to alter the AWS IoT rule automatically created when we created a Lambda function with an AWS IoT trigger. Therefore, we will go to the AWS IoT console and select Rules menu option. We will find and select the IoT button rule created by Lambda which usually has a name with a suffix that is equal to the IoT button device serial number.

Once the rule is selected, we will choose the Edit option beside the Rule query statement section.

We change the Select statement to return the serial number as the accountnum and click Update button to save changes to the AWS IoT rule.

Time to Test. I click the IoT button twice and wait for the green LED light to appear, confirming a successful connection was made and a message was published to AWS IoT. After a few seconds, a text message is received on my phone with the fictitious customer account information.

This was a simple example of how a business could leverage the AWS IoT Button in order to build business solutions for their customers. With the new AWS IoT Button Enterprise Program which helps businesses in obtaining the quantities of AWS IoT buttons needed, as well as, providing AWS IoT service pre-provisioning and deployment support; Businesses can now easily get started in building their own customized IoT solution.
Available Now
The original 1st generation of the AWS IoT button is currently available on Amazon.com, and the 2nd generation AWS IoT button will be generally available in February. The main difference in the IoT buttons are the amount of battery life and/or clicks available for the button. Please note that right now if you purchase the original AWS IoT button, you will receive $20 in AWS credits when you register.
Businesses can sign up today for the AWS IoT Button Enterprise Program currently in Limited Preview. This program is designed to enable businesses to expand their existing applications or build new IoT capabilities with the cloud and a click of an IoT button device. You can read more about the AWS IoT button and learn more about building solutions with a programmable IoT button on the AWS IoT Button product page. You can also dive deeper into the AWS IoT service by visiting the AWS IoT developer guide, the AWS IoT Device SDK documentation, and/or the AWS Internet of Things Blog.
– Tara
New – Create an Amazon Aurora Read Replica from an RDS MySQL DB Instance
Migrating from one database engine to another can be tricky when the database is supporting an application or a web site that is running 24×7. Without the option to take the database offline, an approach that is based on replication is generally the best solution.
Today we are launching a new feature that allows you to migrate from an Amazon RDS DB Instance for MySQL to Amazon Aurora by creating an Aurora Read Replica. The migration process begins by creating a DB snapshot of the existing DB Instance and then using it as the basis for a fresh Aurora Read Replica. After the replica has been set up, replication is used to bring it up to date with respect to the source. Once the replication lag drops to 0, the replication is complete. At this point, you can make the Aurora Read Replica into a standalone Aurora DB cluster and point your client applications at it.
Migration takes several hours per terabyte of data, and works for MySQL DB Instances of up to 6 terabytes. Replication runs somewhat faster for InnoDB tables than it does for MyISAM tables, and also benefits from the presence of uncompressed tables. If migration speed is a factor, you can improve it by moving your MyISAM tables to InnoDB tables and uncompressing any compressed tables.
To migrate an RDS DB Instance, simply select it in the AWS Management Console, click on Instance Actions, and choose Create Aurora Read Replica:

Then enter your database instance identifier, set any other options as desired, and click on Create Read Replica:

You can monitor the progress of the migration in the console:

After the migration is complete, wait for the Replica Lag to reach zero on the new Aurora Read Replica (use the SHOW SLAVE STATUS command on the replica and look for “Seconds behind master”) to indicate that the replica is in sync with the source, stop the flow of new transactions to the source MySQL DB Instance, and promote the Aurora Read Replica to a DB cluster:

Confirm your intent and then wait (typically a minute or so) until the new cluster is available:

Instruct your application to use the cluster’s read and write endpoints, and you are good to go!
— Jeff;
From Raspberry Pi to Supercomputers to the Cloud: The Linux Operating System
Matthew Freeman and Luis Daniel Soto are back talking about the use of Linux through the AWS Marketplace.
– Ana
Linux is widely used in corporations now as the basis for everything from file servers to web servers to network security servers. The no-cost as well as commercial availability of distributions makes it an obvious choice in many scenarios. Distributions of Linux now power machines as small as the tiny Raspberry Pi to the largest supercomputers in the world. There is a wide variety of minimal and security hardened distributions, some of them designed for GPU workloads.
Even more compelling is the use of Linux in cloud-based infrastructures. Its comparatively lightweight architecture, flexibility, and options for customizing it make Linux ideal as a choice for permanent network infrastructures in the cloud, as well as specialized uses such as temporary high-performance server farms that handle computational loads for scientific research. As a demonstration of their own commitment to the Linux platform, AWS developed and continues to maintain their own version of Linux that is tightly coupled with AWS services.
AWS has been a partner to the Linux and Open Source Communities through AWS Marketplace:
- It is a managed software catalog that makes it easy for customers to discover, purchase, and deploy the software and services they need to build solutions and run their businesses.
- It simplifies software licensing and procurement by enabling customers to accept user agreements, choose pricing options, and automate the deployment of software and associated AWS resources with just a few clicks.
- It can be searched and filtered to help you select the Linux distribution – independently or in combination with other components – that best suits your business needs.
Selecting a Linux Distribution for Your Company
If you’re new to Linux, the dizzying array of distributions can be overwhelming. Deciding which distribution to use depends on a lot of different factors, and customers tell us that the following considerations are important to them:
- Existing investment in Linux, if any. Is this your first foray into Linux? If so, then you’re in a position to weight all options pretty equally.
- Existing platforms in use (such as on-premises networks). Are you adding a cloud infrastructure that must connect to your in-house network? If so, you need to consider which of the Linux distributions has the networking and application connectors you require.
- Intention to use more than one cloud platform. Are you already using another cloud provider? Will it need to interconnect with AWS? Your choice of Linux distribution may be affected by what’s available for those connections.
- Available applications, libraries, and components. Your choice of Linux distribution should take into consideration future requirements, and ongoing software and technical support.
- Specialized uses, such as scientific or technical requirements. Certain applications only run on specific, customized Linux distributions.
By examining your responses to each of these areas, you can narrow the list of possible Linux distributions to suit your business needs.
Linux in AWS Marketplace
AWS Marketplace is a great place to locate and begin using Linux distributions along with the top applications that run on them. You can deploy different versions of the distributions from this online store, and AWS scans the catalog daily for security, if we found an issue we notify you — this increases your speed. Scans are run continuously to identify vulnerabilities. AWS notifies customers of any issues found and works with experts to find work-arounds and updates. In addition to support provided by the sellers, the AWS Forums are a great place to ask questions about using Linux on AWS by setting up a free account on the forum. You can also get further details about Linux on AWS from the AWS Documentation.
Applications from AWS Marketplace Running on Linux
Here is a sampling of the featured Linux distributions and applications that run on them, which customers launch from AWS Marketplace.
CentOS Versions 7, 6.5, and 6
The CentOS Project is a community-driven, free software effort focused on delivering a robust open source ecosystem. CentOS is derived from the sources of Red Hat Enterprise Linux (RHEL), and it aims to be functionally compatible with RHEL. CentOS Linux is no-cost to use, and free to redistribute. For users, CentOS offers a consistent, manageable platform that suits a wide variety of deployments. For open source communities, it offers a solid, predictable base to build upon, along with extensive resources to build, test, release, and maintain their code. AWS has several CentOS AMIs that you can launch to take advantage of the stability and widespread use of this distribution.
Debian GNU Linux
Debian GNU/Linux, which includes the GNU OS tools and Linux kernel, is a popular and influential Linux distribution. Users have access to repositories containing thousands of software packages ready for installation and use. Debian is known for relatively strict adherence to the philosophies of Unix and free software as well as using collaborative software development and testing processes. It is popular as a web server operating system. Debian officially contains only free software, but non-free software can be downloaded from the Debian repositories and installed. Debian focuses on stability and security, and is used as a base for many other distributions. AWS has AMIs for Debian available for launch immediately.
Amazon Linux AMI
Amazon Linux is a supported and maintained Linux image provided by AWS. Amazon EC2 Container Service makes it easy to manage Docker containers at scale by providing a centralized service that includes programmatic access to the complete state of the containers and Amazon EC2 instances in the cluster, schedules containers in the proper location, and uses familiar Amazon EC2 features like security groups, Amazon EBS volumes, and IAM roles. Amazon ECS allows you to make containers a foundational building block for your applications by eliminating the need to run a cluster manager, and by providing programmatic access to the full state of your cluster.
Other popular distributions available in AWS Marketplace include Ubuntu, SUSE, Red Hat, Oracle Linux, Kali Linux and more.
Getting Started with Linux on AWS Marketplace
You can view a list hundreds of Linux offerings by simply selecting the Operating System category from the Shop All Categories link on the AWS Marketplace home screen.

From there you can select your preferred distribution and browse the available offerings:

Most offerings include the ability to launch using 1-Click, so your Linux server can be up and running in minutes.
Flexibility with Pay-As-You-Go Pricing
You pay Amazon EC2 usage costs plus per hour (or per month or annual) and, if applicable, commercial Linux cost for certain distributions directly through your AWS account. You can see in advance what your costs will be, depending on the instance type you select. As a result, using AWS Marketplace is one of the fastest and easiest ways to launch your Linux solution.
Visit http://aws.amazon.com/mp/linux to learn more about Linux on AWS Marketplace.
Matthew Freeman and Luis Daniel Soto
Ready-to-Run Solutions: Open Source Software in AWS Marketplace
There are lot’s of exciting things going on in the AWS Marketplace. Here to tell you more about open source software in the marketplace are Matthew Freeman and Luis Daniel Soto.
– Ana
According to industry research, enterprise use of open source software (OSS) is on the rise. More and more corporate-based developers are asking to use available OSS libraries as part of ongoing development efforts at work. These individuals may be using OSS in their own projects (i.e. evenings and weekends), and naturally want to bring to work the tools and techniques that help them elsewhere.
Consequently, development organizations in all sectors are examining the case for using open source software for applications within their own IT infrastructures as well as in the software they sell. In this Overview, we’ll show you why obtaining your open source software through AWS makes sense from a development and fiscal perspective.
Open Source Development Process
Because open source software is generally developed in independent communities of participants, acquiring and managing software versions is usually done through online code repositories. With code coming from disparate sources, it can be challenging to get the code libraries and development tools to work well together. But AWS Marketplace lets you skip this process and directly launch EC2 instances with the OSS you want. AWS Marketplace also has distributions of Linux that you can use as the foundation for your OSS solution.
Preconfigured Stacks Give You an Advantage
While we may take this 1-Click launch ability for granted with commercial software, for OSS, having preconfigured AMIs is a huge advantage. AWS Marketplace gives software companies that produce combinations or “stacks” of the most popular open source software a location from which these stacks can be launched into the AWS cloud. Companies such as TurnKey and Bitnami use their OSS experts to configure and optimize these code stacks so that the software works well together. These companies stay current with new releases of the OSS, and update their stacks accordingly as soon as new versions are available. Some of these companies also offer cloud hosting infrastructures as a paid service to make it even easier to launch and manage cloud-based servers.
As an example, one of the most popular combinations of open source software is the LAMP stack, which consists of a Linux distribution, Apache Web Server, a MySQL database, and the PHP programming library. You can select a generic LAMP stack based on the Linux distribution you prefer, then install your favorite development tools and libraries.

You would then add to it any adjustments to the underlying software that you need or want to make for your application to run as expected. For example, you may want to change the memory allocations for the application, or change the maximum file upload size in the PHP settings.
You could select an OSS application stack that contains the LAMP elements plus a single application such as WordPress, Moodle, or Joomla!®. These stacks would be configured by the vendor with optimal settings for that individual application so that it runs smoothly, with sufficient memory and disk allocations based on the application requirements. This is where stack vendors excel in providing added value to the basic software provisioning.

You might instead choose a generic LAMP stack because you need to combine multiple applications on a single server that use common components. For example, WordPress has plugins that allow it to interoperate with Moodle directly. Both applications use Apache Web Server, PHP, and MySQL. You save time by starting with the LAMP stack, and configuring the components individually as needed for WordPress and Moodle to work well together.

These are just 2 real-world examples of how you could use a preconfigured solution from AWS Marketplace and adapt it to your own needs.
OSS in AWS Marketplace
AWS Marketplace is one of the largest sites for obtaining and deploying OSS tools, applications, and servers. Here are some of the other categories in which OSS is available.
- Application Development and Test Tools. You can find on AWS Marketplace solutions and CloudFormation templates for EC2 servers configured with application frameworks such as Zend, ColdFusion, Ruby on Rails, and Node.js. You’ll also find popular OSS choices for development and testing tools, supporting agile software development with key product such as Jenkins for test automation, Bugzilla for issue tracking, Subversion for source code management and configuration management tools. Learn more »
- Infrastructure Software. The successful maintenance and protection of your network is critical to your business success. OSS libraries such as OpenLDAP and OpenVPN make it possible to launch a cloud infrastructure to accompany or entirely replace an on-premises network. From offerings dedicated to handling networking and security processing to security-hardened individual servers, AWS Marketplace has numerous security solutions available to assist you in meeting the security requirements for different workloads. Learn more »
- Database and Business Intelligence. Including OSS database, data management and open data catalog solutions. Business Intelligence and advanced analytics software can help you make sense of the data coming from transactional systems, sensors, cell phones, and a whole range of Internet-connected devices. Learn more »
- Business Software. Availability, agility, and flexibility are key to running business applications in the cloud. Companies of all sizes want to simplify infrastructure management, deploy more quickly, lower cost, and increase revenue. Business Software running on Linux provides these key metrics. Learn more »
- Operating Systems. AWS Marketplace has a wide variety of operating systems from FreeBSD, minimal and security hardened Linux installations to specialized distributions for security and scientific work. Learn more »
How to Get Started with OSS on AWS Marketplace
Begin by identifying the combination of software you want, and enter keywords in the Search box at the top of the AWS Marketplace home screen to find suitable offerings.

Or if you want to browse by category, just click “Shop All Categories” and select from the list.

Once you’ve made your initial search or selection, there are nearly a dozen ways to filter the results until the best candidates remain. For example, you can select your preferred Linux distribution by expanding the All Linux filter to help you find the solutions that run on that distribution. You can also filter for Free Trials, Software Pricing Plans, EC2 Instance Types, AWS Region, Average Rating, and so on.

Click on the title of the listing to see the details of that offering, including pricing, regions, product support, and links to the seller’s website. When you’ve made your selections, and you’re ready to launch the instance, click Continue, and log into your account.

Because you log in, AWS Marketplace can detect the presence of existing security groups, key pairs, and VPC settings. Make adjustments on the Launch on EC2 page, then click Accept Software Terms & Launch with 1-Click, and your instance will launch immediately.

If you prefer you can do a Manual Launch using the AWS Console with the selection you’ve made, or start the instance using the API or command line interface (CLI). Either way, your EC2 instance is up and running within minutes.
Flexibility with Pay-As-You-Go Pricing
You pay Amazon EC2 usage costs plus per hour (or per month or annual) and, if applicable, commercial open source software fees directly through your AWS account. As a result, using AWS Marketplace is one of the fastest and easiest ways to get your OSS software up and running.
Visit http://aws.amazon.com/mp/oss to learn more about open source software on AWS Marketplace.
Matthew Freeman, Category Development Lead, AWS Marketplace
Luis Daniel Soto, Sr. Category GTM Leader, AWS Marketplace
AWS Lambda – A Look Back at 2016
2016 was an exciting year for AWS Lambda, Amazon API Gateway and serverless compute technology, to say the least. But just in case you have been hiding away and haven’t heard of serverless computing with AWS Lambda and Amazon API Gateway, let me introduce these great services to you. AWS Lambda lets you run code without provisioning or managing servers, making it a serverless compute service that is event-driven and allows developers to bring their functions to the cloud easily for virtually any type of application or backend. Amazon API Gateway helps you quickly build highly scalable, secure, and robust APIs at scale and provides the ability to maintain and monitor created APIs.
With the momentum of serverless in 2016, of course, the year had to end with a bang as the AWS team launched some powerful service features at re:Invent to make it even easier to build serverless solutions. These features include:
- AWS Greengrass: Run local compute, messaging & data caching for connected IoT devices using Lambda and AWS IoT; https://aws.amazon.com/blogs/aws/aws-greengrass-ubiquitous-real-world-computing/
- Lambda@Edge Preview: New Lambda feature that allows code to be run at global AWS edge locations and triggered in response to Amazon CloudFront requests to reduce network latency to end users; https://aws.amazon.com/blogs/aws/coming-soon-lambda-at-the-edge/
- AWS Batch Preview: Batch computing workload planning, scheduling, and execution across AWS compute services including upcoming Lambda integration as a batch Job; https://aws.amazon.com/blogs/aws/aws-batch-run-batch-computing-jobs-on-aws/
- AWS X-Ray: Analyze and debug distributed applications, such as those built using a microservices architecture, written in Java, Node.js, and .NET deployed on EC2, ECS, AWS Elastic Beanstalk, and upcoming AWS Lambda support; https://aws.amazon.com/blogs/aws/aws-x-ray-see-inside-of-your-distributed-application/
- Continuous Deployment for Serverless: AWS services to create a continuous deployment pipeline for your serverless applications; https://aws.amazon.com/blogs/compute/continuous-deployment-for-serverless-applications/
- Step Functions: Using visual workflows as a reliable way to organize the components of microservices and distributed applications; https://aws.amazon.com/blogs/aws/new-aws-step-functions-build-distributed-applications-using-visual-workflows/
- Snowball Edge: Petabyte-scale data transport appliance with on-board storage and Lambda-powered local processing: https://aws.amazon.com/blogs/aws/aws-snowball-edge-more-storage-local-endpoints-lambda-functions/
- Dead Letter Queues: Support for Lambda function failure notifications to queue or another notification system
- C# Support: C# code as a supported language for AWS Lambda
- API Gateway Monetization: Integration of API Gateway with AWS Marketplace
- API Gateway Developer Portal: Open source serverless web application to get started building your own developer portal
Since Jeff has already introduced most of the aforementioned new service features for building distributed applications and microservices like Step Functions, let’s walk-through the last four new features not yet discussed using a common serverless use case example: Real-time Stream Processing. In our walk-through of the stream processing use case, we will implement a Dead Letter Queue for notifications of errors that may come from the Lambda function processing a stream of data, we will take an existing Lambda function written in Node.js to process the stream and rewrite it using the C# language. We then will build an example of the monetization of a Lambda backed API using API Gateway’s integration with AWS Marketplace. This will be exciting, so let’s get started.
During the AWS Developer Days in San Francisco and Austin, I presented an example of leveraging AWS Lambda for real-time stream processing by building a demo showcasing a streaming solution with Twitter Streaming APIs. I will build upon this example to demonstrate the power of Dead Letter Queues (DLQ), C# Support, API Gateway Monetization features, and the open source template for API Gateway Developer Portal. In the demo, a console or web application streams tweets gathered from the Twitter Streaming API that has the keywords ‘awscloud’ and/or ‘serverless’. Those tweets are sent real-time to Amazon Kinesis Streams where Lambda detects the new records and processes the stream batch by writing the tweets to the NoSQL database, Amazon DynamoDB.
Now that we understand the real-time streaming process demo’s workflow, let’s take a deeper look at the Lambda function that processes the batch records from Kinesis. First, you will notice below that the Lambda function, DevDayStreamProcessor, has an event source or trigger that is a Kinesis stream named DevDay2016Stream with a Batch size of 100. Our Lambda function will poll the stream periodically for new records and automatically read and process batches of records, in this case, the tweets detected on the stream.

Now we will examine our Lambda function code which is written in Node.js 4.3. The section of the Lambda function shown below loops through the batch of tweet records from our Kinesis stream, parses each record, and writes desired tweet information into an array of JSON data. The array of the JSON tweet items is passed to the function, ddbItemsWrite which is outside of our Lambda handler.
'use strict';
console.log('Loading function');
var timestamp;
var twitterID;
var tweetData;
var ddbParams;
var itemNum = 0;
var dataItemsBatch = [];
var dbBatch = [];
var AWS = require('aws-sdk');
var ddbTable = 'TwitterStream';
var dynamoDBClient = new AWS.DynamoDB.DocumentClient();
exports.handler = (event, context, callback) => {
var counter = 0;
event.Records.forEach((record) => {
// Kinesis data is base64 encoded so decode here
console.log("Base 64 record: " + JSON.stringify(record, null, 2));
const payload = new Buffer(record.kinesis.data, 'base64').toString('ascii');
console.log('Decoded payload:', payload);
var data = payload.replace(/[\u0000-\u0019]+/g," ");
try
{ tweetData = JSON.parse(data); }
catch(err)
{ callback(err, err.stack); }
timestamp = "" + new Date().getTime();
twitterID = tweetData.id.toString();
itemNum = itemNum+1;
var ddbItem = {
PutRequest: {
Item: {
TwitterID: twitterID,
TwitterUser: tweetData.username.toString(),
TwitterUserPic: tweetData.pic,
TwitterTime: new Date(tweetData.time.replace(/( \+)/, ' UTC$1')).toLocaleString(),
Tweet: tweetData.text,
TweetTopic: tweetData.topic,
Tags: (tweetData.hashtags) ? tweetData.hashtags : " ",
Location: (tweetData.loc) ? tweetData.loc : " ",
Country: (tweetData.country) ? tweetData.country : " ",
TimeStamp: timestamp,
RecordNum: itemNum
}
}
};
dataItemsBatch.push(ddbItem);
counter++;
});
var twitterItems = {};
twitterItems[ddbTable] = dataItemsBatch;
ddbItemsWrite(twitterItems, 0, context, callback);
};
The ddbItemsWrite function shown below will take the array of JSON tweet records processed from the Kinesis stream, and write the records multiple items at a time to our DynamoDB table using batch operations. This function leverages the DynamoDB best practice of retrying unprocessed items by implementing an exponential backoff algorithm to prevent write request failures due to throttling on the individual tables.
function ddbItemsWrite(items, retries, ddbContext, ddbCallback)
{
dynamoDBClient.batchWrite({ RequestItems: items }, function(err, data)
{
if (err)
{
console.log('DDB call failed: ' + err, err.stack);
ddbCallback(err, err.stack);
}
else
{
if(Object.keys(data.UnprocessedItems).length)
{
console.log('Unprocessed items remain, retrying.');
var delay = Math.min(Math.pow(2, retries) * 100, ddbContext.getRemainingTimeInMillis() - 200);
setTimeout(function() {ddbItemsWrite(data.UnprocessedItems, retries + 1, ddbContext, ddbCallback)}, delay);
}
else
{
ddbCallback(null, "Success");
console.log("Completed Successfully");
}
}
}
);
}Currently, this Lambda function works as expected and will successfully process tweets captured in Kinesis from the Twitter Streaming API, however, this function has a flaw that will cause an error to occur when processing batch write requests to our DynamoDB table. In the Lambda function, the current code does not take into account that the DynamoDB batchWrite function should be comprised of no more than 25 write (put) requests per single call to this function up to 16 MB of data. Therefore, without changing the code appropriately to have the ddbItemsWrite function to handle batches of 25 or have the handler function put items in the array in groups of 25 requests before sending to the ddbItemsWrite function; there will be a validation exception thrown when the batch of tweets items sent is greater than 25. This is a great example of a bug that is not easily detected in small-scale testing scenarios yet will cause failures under production load.
Dead Letter Queues
Now that we are aware of an event that will cause the ddbItemsWrite Lambda function to throw an exception and/or an event that will fail while processing records, we have a first-rate scenario for leveraging Dead Letter Queues (DLQ).
Since AWS Lambda DLQ functionality is only available for asynchronous event sources like Amazon S3, Amazon SNS, AWS IoT or direct asynchronous invocations, and not for streaming event sources such as Amazon Kinesis or Amazon DynamoDB streams; our first step is to break this Lambda function into two functions. The first Lambda function will handle the processing of the Kinesis stream, and the second Lambda function will take the data processed by the first function and write the tweet information to DynamoDB. We will then setup our DLQ on the second Lambda function for the error that will occur on writing the batch of tweets to DynamoDB as noted above.
We have two options when setting up a target for our DLQ; Amazon SNS topic or an Amazon SQS queue. In this walk-through, we will opt for using an Amazon SQS queue. Therefore, my first step in using DLQ is to create a SQS Standard queue. A Standard queue type is a queue which has high transactions throughput, a message will be delivered at least once, but another copy of the message may also be delivered, and it is possible that messages might be delivered in an order different from which they were sent. You can learn more about creating SQS queues and queue type in the Amazon SQS documentation.
Once my queue, StreamDemoDLQ, is created, I will grab the ARN from the Details tab of this selected queue. If I am not using the console to designate the DLQ resource for this function, I will need the ARN for the queue for my Lambda function to identify this SQS queue as the DLQ target for error and event failure notifications. Additionally, I will use the ARN to add permissions to my Lambda execution role policy in order to access this SQS queue.

I will now return to my Lambda function and select the Configuration tab and expand the Advanced settings section. I will select SQS in the DLQ Resource field and select my StreamDemoDLQ queue in the SQS Queue field dropdown.

Remember, the execution role for the Lambda function must explicitly provide sqs:SendMessage access permissions to in order to successfully send messages to your SQS DLQ. Therefore, I ensured that my Lambda role, lambda_kinesis_role, has the following IAM policy for SQS permissions.

We have now successfully configured a Dead Letter Queue for our Lambda function using Amazon SQS. To learn more about Dead Letter Queues in Lambda, read the Troubleshooting and Monitoring section of the AWS Lambda Developer Guide and check out the AWS Compute Blog post on Dead Letter Queues.
C# Support
As I mentioned earlier, another very exciting feature added to Lambda during AWS re:Invent was the support for the C# language via the open source .NET Core 1.0 platform. Since the Lambda console does not offer editing for compiled languages yet, in order to author a C# Lambda function you can use tooling in Visual Studio with the AWS Toolkit, Yeoman, and/or the .NET CLI. To deploy Lambda functions written in C#, you can use the Lambda plugin in the AWS ToolKit for Visual Studio or create a deployment package with the .NET Core command line.
A C# Lambda function handler should be defined as an instance or static method in a class. There are two handler function parameters; the first is the input type which is the event data and second is the Lambda context object of type ILambdaContext. The event data input object types for AWS Services include the following:
- Amazon.Lambda.APIGatewayEvents
- Amazon.Lambda.CognitoEvents
- Amazon.Lambda.ConfigEvents
- Amazon.Lambda.DynamoDBEvents
- Amazon.Lambda.KinesisEvents
- Amazon.Lambda.S3Events
- Amazon.Lambda.SNSEvents
Now that we have discussed more detail around C# Support in Lambda, let’s rewrite our DevDayStreamProcessor lambda function with the C# language. For this example, I will use Visual Studio IDE to write the Lambda function, and additionally take advantage of the AWS Lambda Visual Studio plugin to deploy the function. Remember in order to use the AWS Toolkit for Visual Studio with Lambda, you will need to have Visual Studio 2015 Update 3 version and NET Core tools. You can read more about installing Visual Studio 2015 Update 3 and .NET Core here.
To create the C# function using Visual Studio, I start a New Project, select AWS Lambda Project (.NET Core) and name it ServerlessStreamProcessor.

What’s really cool about taking advantage of the AWS Toolkit for Visual Studio to author this function, is that inside of Visual Studio I can use Lambda blueprints to get started in a similar way that I would in using the Lambda console. Therefore in order to replicate the DevDayStreamProcessor in C#, I will select the Simple Kinesis Function blueprint.

It should be noted that when writing Lambda functions in C#, there is no need to mark the class declaration nor the target handler function as a Lambda function. Additionally, when writing CloudWatch logs you can use the standard C# Console class WriteLine function or use the ILambdaContext LogLine function found as a part of the ILambdaContext interface. With the template for accessing the Kinesis stream in place, I finish writing the C# Lambda function, ServerlessStreamProcessor, utilizing the same variable names as in the Node.js code in DevDayStreamProcessor. Please note the C# Lambda handler function below.
using System.Collections.Generic;
using Amazon.Lambda.Core;
using Amazon.Lambda.KinesisEvents;
using Amazon.DynamoDBv2;
using Amazon.DynamoDBv2.DataModel;
using Newtonsoft.Json.Linq;
// Assembly attribute to enable the Lambda function's JSON input to be converted into a .NET class.
[assembly: LambdaSerializerAttribute(typeof(Amazon.Lambda.Serialization.Json.JsonSerializer))]
namespace ServerlessStreamProcessor
{
public class LambdaTwitterStream
{
string twitterID, timeStamp;
int itemNum = 0;
private static AmazonDynamoDBClient dynamoDBClient = new AmazonDynamoDBClient();
List<TwitterItem> dataItemsBatch = new List<TwitterItem>();
public void FunctionHandler(KinesisEvent kinesisEvent, ILambdaContext context)
{
DynamoDBContext dbContext = new DynamoDBContext(dynamoDBClient);
context.Logger.LogLine($"Beginning to process {kinesisEvent.Records.Count} records...");
foreach (var record in kinesisEvent.Records)
{
context.Logger.LogLine($"Event ID: {record.EventId}");
context.Logger.LogLine($"Event Name: {record.EventName}");
// Kinesis data is base64 encoded so decode here
string tweetData = GetRecordContents(record.Kinesis);
context.Logger.LogLine($"Decoded Payload: {tweetData}");
tweetData = @"" + tweetData;
JObject twitterObj = JObject.Parse(tweetData);
twitterID = twitterObj["id"].ToString();
timeStamp = DateTime.Now.Millisecond.ToString();
itemNum++;
context.Logger.LogLine(timeStamp);
context.Logger.LogLine($"Twitter ID is: {twitterID}");
context.Logger.LogLine(itemNum.ToString());
TwitterItem ddbItem = new TwitterItem()
{
TwitterID = twitterID,
TwitterUser = twitterObj["username"].ToString(),
TwitterUserPic = twitterObj["pic"].ToString(),
TwitterTime = DateTime.Parse(twitterObj["time"].ToString()).ToUniversalTime().ToString(),
Tweet = twitterObj["text"].ToString(),
TweetTopic = twitterObj["topic"].ToString(),
Tags = twitterObj["hashtags"] != null ? twitterObj["hashtags"].ToString() : String.Empty,
Location = twitterObj["loc"] != null ? twitterObj["loc"].ToString() : String.Empty,
Country = twitterObj["country"] != null ? twitterObj["country"].ToString() : String.Empty,
TimeStamp = timeStamp,
RecordNum = itemNum
};
dataItemsBatch.Add(ddbItem);
}
context.Logger.LogLine(JObject.FromObject(dataItemsBatch).ToString());
ddbItemsWrite(dataItemsBatch, 0, dbContext, context);
context.Logger.LogLine("Success - Completed Successfully");
context.Logger.LogLine("Stream processing complete.");
}There are only a few differences that should be noted between our Kinesis stream processor written in C# and our original Node.js code. Since the input parameter type supported by default in C# Lambda functions is the System.IO.Stream type, the Kinesis base64 string is decoded by using a StreamReader with ASCII encoding in a blueprint provided function, GetRecordContents.
private string GetRecordContents(KinesisEvent.Record streamRecord)
{
using (var reader = new StreamReader(streamRecord.Data, Encoding.ASCII))
{
return reader.ReadToEnd();
}
}The other thing to note is that in order to write the tweet data to the DynamoDB Table, I added the AWS .NET SDK NuGet package for DynamoDB; AWSSDK.DynamoDBv2 to the Lambda function project via the NuGet package manager within Visual Studio. I also created a .NET data object, TwitterItem, to map to the data being stored in the DynamoDB table. Using the AWS .NET SDK higher level programming interface, object persistence model for DynamoDB, I created a collection of TwitterItem objects to be written via the BatchWrite object class in our ddbItemsWrite C# function.
private async void ddbItemsWrite(List<TwitterItem> items, int retries, DynamoDBContext ddbContext, ILambdaContext context)
{
BatchWrite<TwitterItem> twitterStreamBatchWrite = ddbContext.CreateBatchWrite<TwitterItem>();
try
{
twitterStreamBatchWrite.AddPutItems(items);
await twitterStreamBatchWrite.ExecuteAsync();
}
catch (Exception ex)
{
context.Logger.LogLine($"DDB call failed: {ex.Source} ");
context.Logger.LogLine($"Exception: {ex.Message}");
context.Logger.LogLine($"Exception Stacktrace: {ex.StackTrace}");
}
}
Another benefit of using AWS Toolkit for Visual Studio to author my C# Lambda function is that I can deploy my Lambda function directly to AWS with a single click. Selecting my project name in the Solution Explorer and performing a right-click, I get a menu option, Publish to AWS Lambda, which brings up a menu for information to include about my Lambda function for deployment to AWS.

It is important to note that the handler function signature follows the nomenclature of Assembly :: Namespace :: ClassName :: Method, therefore, the signature of our C# Lambda function shown here is: ServerlessStreamProcessor :: ServerlessStreamProcessor.LambdaTwitterStream :: FunctionHandler. We provide this information to the Upload to AWS Lambda dialog box and select Next to assign a role for the function.


Upon completion, you can test in the Lambda console or in Visual Studio with AWS toolkit provided plugin (shown below) using the sample data of the triggering event source for an iterative approach to developing the Lambda function.

You can learn more about authoring AWS Lambda functions using the C# Language in the AWS Lambda developer guide or by reading the post announcing C# Support on the Compute Blog.
API Gateway Monetization and Developer Portal
If you have been following the microservices momentum, you may be aware of an architectural pattern that calls for using smart endpoints and/or using an API gateway via REST APIs to manage access and exposure of individual services that make up a microservices solution. Amazon API Gateway enables creation and management of RESTful APIs to expose AWS Lambda functions, external HTTP endpoints, as well as, other AWS services. In addition, Amazon API Gateway allows clients and external developers to have access to a deployed APIs by via HTTP protocol or a platform/language targeted SDK.
With the introduction of SaaS Subscriptions on AWS Marketplace and the API Gateway integration with the AWS Marketplace, you can now monetize your APIs by allowing customers to directly consume the APIs you create with API Gateway in the AWS Marketplace. AWS customers can subscribe and be billed for the APIs published on the marketplace with their existing AWS account. With the integration of API Gateway with the AWS Marketplace, the process to get started is easy on the AWS Marketplace.
To get started, you must ensure that you have enabled the Usage Plan feature in Amazon API Gateway.

Once enabled the next step is to create a Usage Plan, enable throttling (if desired) with targeted rate and burst request thresholds, and finally enable quotas (if you choose) by providing targeted request quota per a set timeframe.

Next, we would choose our APIs and related stage(s) that we wish to be associated with the usage plan. Please note that this is an optional step as you can opt not associate a specific API with your usage plan.

All that is left to do is add or create an API key for the usage plan. Again, it should be noted that this is also an optional step in creating your usage plan.

Now that we have our usage plan, StreamingPlan, we are ready for the next step in preparation for selling our API on the marketplace. You have the option to create multiple usage plans with varying APIs and limits, and sell these plans as differentiated API products on AWS Marketplace.

In order to enable customers to buy our new API product, however, the AWS Marketplace requires that each API product has an external developer portal to handle subscription requests, provide API information details and ability for the management of usage.
This customer need for an external developer portal for the marketplace birthed the new open source API Gateway developer portal serverless web application implementation. The goal of the API Gateway developer portal project was to allow customers to follow a few easy steps to create a serverless web application that lists a catalog of your APIs built with API Gateway while allowing for developer signups.
The API Gateway developer portal was built upon AWS Serverless Express; an open source library published by AWS which aids you in utilizing AWS Lambda and Amazon API Gateway in building web applications/services with the Node.js Express framework. Additionally, the API Gateway developer portal application uses an AWS SAM (Serverless Application Model) template to deploy its serverless resources. AWS SAM is a simplified CloudFormation template and specification that allows easier management and deployment of serverless applications on AWS.
To build your developer portal using the API Gateway portal, you would start by cloning the aws-api-gateway-developer-portal project from GitHub.

Assuming you have the latest version of the AWS CLI and Node.js installed, you would setup the developer portal by running “npm run setup” on the command line for Mac and Linux OS users. For Windows users, you would run “npm run win-setup” on the command line setup the developer portal.


The result is a functional sample developer portal website running on S3 that you can customize in order to create your own developer portal for your APIs.

The frontend of the sample developer portal website is built with the React JavaScript library, and the backend is an AWS Lambda function running using the aws-serverless-express library. Additionally, a Lambda function with a SNS event source was created as a listener for notification when customers subscribe or unsubscribe to your API via the AWS Marketplace console. You can learn more about the steps to build, customize, and deploy your API Gateway developer portal web application with this reference project by visiting the AWS Compute blog post which discusses the architecture and implementation in more detail.
The next key step in monetizing our API is establishing an account on the AWS Marketplace. If an account is not already established, registering is simply verifying that you meet the requirement prerequisites provided in the AWS Marketplace Seller Guide and completing a seller registration form on the AWS Marketplace Management Portal. You can see a snapshot of the start of the seller registration form below.

To list the API, you would fill a product load form describing the API, establish the pricing for the API, and provide t\he IDs of AWS Accounts that will test the API subscription process. Completing this form would also require you to submit the URL for your API developer portal.
When your seller registration is complete, you will be supplied an AWS Marketplace product code. You will need to associate your marketplace product code with your API usage plan. In order to complete this step, you would simply log into the API Gateway console and go to your API usage plan. Go to the Marketplace tab and enter your product code. This tells API Gateway to send measurement data to AWS Marketplace when your API is used.

With your Amazon API Gateway managed API packaged into a usage plan, the accompanying API developer portal created, seller account registration completed, and product code associated with API usage plan; we are now ready to monetize our API on the AWS Marketplace.
Learn more about monetizing your APIs created with API Gateway by checking out the related blog post and reviewing the API Gateway developer guide documentation.
Summary
As you can see, the AWS teams were busy in 2016 working to make the customer experience easier for creating and deploying serverless architectures, as well as, providing mechanisms for customers to generate and monetize their API Gateway managed APIs.
Visit the product documentation for AWS Lambda and Amazon API Gateway to learn more about these services and all the newly released features.
– Tara