A little over a year and a half ago, we had a dramatic rethink of the technologies and development workflows for building with WordPress.
Our existing codebase and workflows had served us well, but ten years of legacy was beginning to seriously hinder us from building the modern, fast, and mobile-friendly experiences that our users expect. It seemed like collaboration between developers and designers was not firing on all cylinders. So we asked ourselves the question:
“What would WordPress.com look like if we were to start building it today?”
A New Beginning: Prototyping and Iterating
We’d asked ourselves this question before, and had our fair share of initiatives that didn’t result in useful change. Looking back, we were able to pinpoint our biggest mistakes: we’d been starting with a muddy vision, and were trying to solve an ill-defined problem. These insights really helped us change our approach.
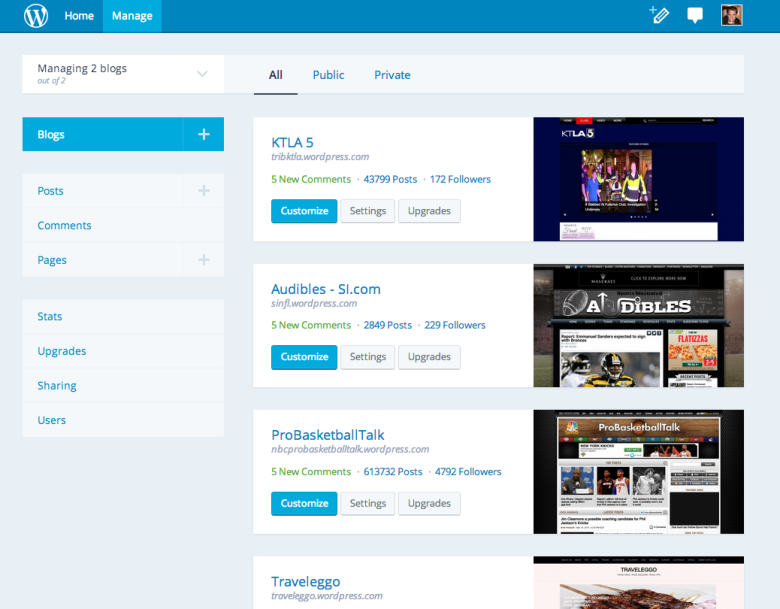
One of the original Calypso prototype screens, listing all of your WordPress sites.
Calypso, the codename for this new WordPress admin interface project, started differently. To present a clear vision, we built an aspirational HTML/CSS design prototype — based on clearly defined product goals — that allowed us to imagine what a new WordPress.com could look like when complete. We knew it would change over time as we launched parts to our users, but the vision provided all of Automattic with something to aim for and get excited about.
Once the Calypso prototype was in a good place, the early days of development were all about making tough decisions such as which language to use, whether to use a framework, and how we would extend our API. Automattic had just acquired Cloudup, an API-powered file-sharing tool built with JavaScript. The Cloudup team showed us a solid, maintainable, and scalable path towards making WordPress.com completely JavaScript-based and API-powered.
Since WordPress is a PHP-powered application, our company-wide development skill-set has historically been PHP-heavy with a sprinkling of advanced JavaScript. This made Calypso intimidating to other engineers and designers at the company for much of the first six months of its development — we were building something that few people could jump in on.
Even core Calypso project team members had to get over our intimidation. None of us were strong JavaScript developers. But as each day passed our experience built, we made mistakes, we reviewed them, we fixed them, and we learned. Once we had the project moving, we set better examples for other engineers, and shared our knowledge across the company.
One great change came out of building an early design prototype: improved collaboration using GitHub. Calypso prototyping was done collaboratively between a handful of designers in GitHub; although many of us had long used GitHub for personal projects it was relatively new for internal projects, which historically used Trac for most project management and bug tracking. Using GitHub helped us see how much easier internal collaboration could be, and how to allow for much greater feedback on individual work being done.

Peer code reviews show no sign of slowing up and are now widely accepted.
As GitHub had worked so well for the prototyping stage we switched for all Calypso development, allowing us to harness the pull request (PR) system for peer code reviews, and build our own custom GitHub-based workflow. Code reviews were new for many developers — traditionally at Automattic, we have had no systematic peer code review system outside of the VIP team’s daily code review of client sites. Code review, though it initially added to the intimidation of starting to work with Calypso, greatly increased the quality of our codebase and helped everyone level up their JavaScript skills.
What started as a team of seven people working on Calypso quickly spread to a cross-section of teams with ten, then 14, then 20 Automatticians actively working in the Calypso codebase. Two months after the launch of the first Calypso-powered feature on WordPress.com, we had 40 contributors working on Calypso across five different teams. We iterated over the next year with the “release early, release often” Automattic mindset, launching 40 distinct Calypso-powered features on WordPress.com with over 100 individual contributors.
By the middle of 2015 the Calypso codebase was in good enough shape to be used outside of the web browser. Since Calypso is entirely JavaScript, HTML, and CSS, it can run locally on a device with a lightweight node.js server setup. Using a technology called Electron, we built native desktop clients running the same code bundled inside the applications. We started work first on a native Mac desktop app, which is now available, and continued that work on soon-to-be-launched Windows and Linux apps. Seeing these apps come together and using them internally really started to justify all the hard work we’d spent building the Calypso codebase.
Open Sourcing Calypso, the Power Behind WordPress.com
One of our Calypso developer hangouts in progress, and Team IO, who built the Calypso editor, at our all-company Grand Meetup in October.
Over the past year and a half, Calypso has gone from an idea to an aspirational prototype to a fully functioning product built, launched iteratively, and used by millions of WordPress.com users. Internally, it’s been a period of great change and growth. We’ve embraced cross-team collaboration through GitHub and peer code reviews through the PR review system, gone from just a couple of great JavaScript developers to a company full of them, and seen incredible collaboration between designers and developers on a daily basis.
A handy chart to show the differences between the old and new WordPress.com. (pdf, img)
We’re proud to be able to open source all of the hard work we’ve put in, and to continue to build on the product in an open way. You can read more about opening up Calypso development on our CEO Matt Mullenweg’s site.
Over the next few months, we’ll publish more in-depth posts exploring the technicals and workflows behind Calypso: how we manage our own unique GitHub flows, how we’ve used other popular open source libraries like React and concepts like Flux, and our experiences bundling and launching native app clients. Keep an eye out for those by following this blog (in the bottom right), and in the meantime, check out the active Calypso codebase as we continue to iterate on it.
 Andy Peatling
Andy Peatling
Calypso Project Lead
Like this:
Like Loading...
















{kind=link}