
Cet article décrit comment une technique innovante de reconnaissance de mise en page (OLR, optical layout recognition) appliquée lors d’un grand projet européen de numérisation de la presse ancienne (Europeana Newspapers, 2012-2015) a été utilisée dans une expérience de fouille de données ciblant les métadonnées quantitatives de quotidiens numérisés. Les fichiers numériques de six titres de journaux français des collections de la BnF ont ainsi été analysés avec des techniques d’extraction et de visualisation de données démontrant des voies prometteuses pour la production de connaissances sur la presse ancienne, à l’usage des acteurs des bibliothèques numériques (gestionnaires de programmes de numérisation, conservateurs et médiateurs des collections de presse), ceux du champ des humanités numériques mais aussi le grand public utilisateur des bibliothèques numériques. Démonstration est également faite de l’intérêt de ces métadonnées quantitatives pour la recherche d’information.
I. Introduction : Quelles données ?
Les bibliothèques regorgent de données numériques et elles en produisent quotidiennement de nouvelles : des métadonnées bibliographiques sont créées ou mises à jour dans les catalogues décrivant des collections ; des données d’usage sur les bibliothèques et leur public sont collectées ; des documents numériques sont produits par la numérisation des contenus conservés dans les bibliothèques.
Mais ces données et métadonnées numériques ressortent-elles du concept de big data ? Et sont-elles des cibles légitimes pour du data mining ? Leur volume réduit (douze millions de notices pour le catalogue de la BnF) n’incite-t-il pas à quelque précaution ? Le critère de la volumétrie n’est pas pertinent, si l’on en croit Viktor Mayer-Schoenberger et Kenneth Cukier : “(…) big data refers to things one can do at a large scale that cannot be done at a smaller one, to extract new insights or create new forms of value (…)” [1]. À une large échelle donc, mais en regard de l’activité concernée (“my big data is not your big data” [2]), avec des moyens différents de ceux satisfaisant les besoins métier nominaux, et avec pour objectif de « créer du neuf » : de nouvelles relations (auteur, lieu, date, etc.) sont construites au-dessus de catalogues publics (OPAC) [3] ; le pilotage des bibliothèques s’adosse à l’analyse des données de fréquentation et de lecture [4] ; une histoire des pages de une de quotidiens est élaborée à partir des données extraites d’une bibliothèque numérique [5], [6].
Est-il possible de donner à voir de l’inédit en fouillant les métadonnées descriptives de la presse patrimoniale numérisée pendant le projet Europeana Newspapers1 ? L’expérimentation décrite dans cet article tente de répondre à cette hypothèse, en présentant d’abord un processus de création d’un jeu de métadonnées quantitatives, puis des méthodes d’analyse et d’interprétation et de réutilisation de ces données ; et finalement quelques considérations sur les enjeux de qualité des données.
II. Créer de nouvelles données
A. Le jeu de données Europeana Newspapers
Six quotidiens nationaux et régionaux des collections de la BnF (1814-1945) font partie du corpus traité en OLR (Optical Layout Recognition) par le projet Europeana Newspapers. Le traitement OLR consiste en la description de la structure logique de chaque fascicule et de ses articles (emprise spatiale, titre et sous-titre, etc.) à l’aide des formats METS et ALTO [7] et en la classification des types de contenus (information, feuilleton littéraire, programme des spectacles, publicités, etc., au format MODS).

B. Des documents numériques aux données dérivées
Contenus OCR et OLR sont des sources de métadonnées quantitatives décrivant des « grains » de contenus. Notre hypothèse est que compter ces grains (fig. 2) produit une information porteuse de sens :
- l’OCR (format ALTO) est une source de métadonnées quantitatives relatives à des grains de contenus élémentaires : nombre de mots, d’illustrations, de tableaux, etc.
- l’OLR (format METS) est également une source de métadonnées quantitatives décrivant des objets informationnels de plus haut niveau : articles, sections (regroupement d’articles), types de contenu.

En s’appuyant sur cette conjecture, des documents numériques est donc dérivé un jeu de métadonnées bibliographiques (titre du journal, date de publication) et quantitatives (nombre de pages, articles, mots, illustrations, publicités, etc.) pour chaque fascicule analysé. Des scripts Perl ou XSL (fig. 3) sont utilisés pour extraire certaines métadonnées du manifeste METS décrivant le fascicule (par ex. le nombre d’articles) ou des fichiers OCR associés (par ex. le nombre de mots). Le jeu de données créé contient environ 5,5 millions de métadonnées élémentaires exprimées selon des formats de données usuels (XML, JSON, CSV).

Ce principe de production de données dérivées offre plusieurs avantages. En tout premier lieu, pour le consommateur des données :
- prêtes à l’emploi : pas de documents à extraire des magasins numériques et à analyser,
- d’usage aisé (notamment CSV, JSON), à comparer à la complexité des formats XML métiers (ALTO, METS, MODS, etc.),
- légères : 80 Mo pour les métadonnées dérivées, 1 To pour le corpus EN-BnF,
- abondantes : 5,5 M de métadonnées atomiques.
Pour le producteur, notons que ces données sont faciles à produire et à diffuser (par exemple sous la forme d’archives ZIP par titre de presse, par période, etc.) et n’impliquent aucun enjeu de propriété intellectuelle, puisqu’il s’agit de métadonnées dérivées n’incluant pas les contenus originels.
III. Faire parler les données
A. Analyse statistique : évaluer, dimensionner, anticiper
Certaines données quantifient une réalité dont l’analyste a une connaissance ou une intuition préalable. C’est le cas d’informations statistiques aidant au pilotage d’actions de numérisation ou de valorisation des contenus. Le jeu de métadonnées pourrait alors être un échantillon représentatif de la collection ou du corpus, les informations recherchées étant majoritairement des mesures statistiques. Citons quelques exemples :
- Post-correction automatique de l’OCR : la connaissance de la moyenne des mots imprimés dans un fascicule de presse (5 760 mots par page pour le corpus EN-BnF) permet de dimensionner la puissance de calcul nécessaire pour corriger algorithmiquement et au fil de l’eau l’OCR entrant dans une chaîne de numérisation.

- Programmes de numérisation et valorisation : la densité en articles d’une collection de presse numérique est une donnée ayant un impact potentiel sur les processus et les coûts. Cette dimension varie fortement en fonction des périodes et des titres de presse (fig. 5).

- Banque d’images : dans la perspective de la création d’une banque d’illustrations de presse, une analyse statistique élémentaire éclaire sur les titres de presse richement illustrés et quant au nombre total d’illustrations potentiellement exploitables (427 000, 97 % au XXe siècle).

Appelés à commenter ces résultats, historiens ou conservateurs établiront aisément des liens avec la réalité documentaire qu’ils connaissent :
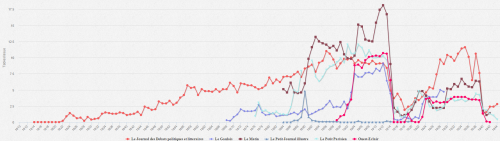
- « Bien sûr, Le Matin est un quotidien apparu durant l’âge d’or de la presse d’information moderne (1890-1914), emblématique de ses innovations : il est fortement structuré en articles et richement illustré. » ( fig. 5, courbe marron : fig. 6 : plus de 6 000 illustrations en moyenne pour 1 000 pages).
- « Le Journal des Débats politiques et littéraires (JDLP) fondé en 1789 est l’héritier des gazettes : il conserve au fil de son histoire un système de rubriquage moins dense en articles que les quotidiens nés à la fin du XIXe et il est économe en illustration. » (fig. 5 : courbe orange ; fig. 6 : 225 illustrations pour 1 000 pages)
Les mesures statistiques collectées permettent d’enrichir cette connaissance avec des données précises (moyennes, totaux, maxima) et représentatives (car collectées sur de vastes échantillons, voire sur la totalité de la collection), qui constituent une aide précieuse pour les activités de gestion de l’écosystème de toute bibliothèque numérique, de la numérisation à la valorisation.
B. Visualisation de données : découvrir des connaissances
L’histoire des méthodes de recherche sur des contenus documentaires ou archivistiques est en partie déterminée par une autre histoire, celle de la numérisation de l’information, et partant de la numérisation patrimoniale, des premiers programmes en mode image à la restructuration des documents et à la description sémantique des contenus atomiques. Les modalités d’interaction des chercheurs avec les corpus numériques ont évolué simultanément, du feuilletage à la fouille de données, sans oublier l’étape de la recherche en texte intégral. En quelques décennies, l’œil du chercheur se sera posé sur microfilms, images numériques, listes de résultats de recherche plein texte, pour finalement s’éloigner des documents, en déléguant à des algorithmes (analyse d’images et de documents, analyse statistique, traitement automatique de la langue, modélisation des textes, visualisation de données) la tâche de nourrir une nouvelle pratique, la lecture distante (telle que théorisée par Franco Moretti [8]).
La communauté des humanités numériques applique des techniques de visualisation de données depuis déjà fort longtemps2. S’agissant de l’étude des périodiques numérisés, une méthodologie tout à la fois rationnelle et pragmatique devrait prendre en compte les particularités de ce type documentaire, notamment sa nature composite (de l’information politique aux programmes de radio, sans oublier feuilleton, critique littéraire et petites annonces) et chaotique (OCR bruité). Citons par exemple les travaux du projet PRELIA3, de la plateforme Médias 194 ou encore ceux de Ryan Cordell (notamment l’identification de motifs textuels à grande échelle malgré les défauts de qualité du texte océrisé5, fig. 7).
Appliquée au jeu de métadonnées d’un titre spécifique, la visualisation de données permet de circonscrire l’analyse à l’histoire du titre considéré. Déployé au contraire à l’échelle du jeu de métadonnées complet, elle met en lumière l’histoire de la presse quotidienne française sur deux siècles. Dans tous les cas, le praticien sera libre de sélectionner et d’affiner la granularité de la visualisation, depuis l’échelle du fascicule jusqu’à celui d’une année de publication ou d’une période temporelle plus large. Et il faudra chaque fois régler la « distance de lecture » et évaluer son impact sur les enjeux d’interprétation. Les exemples suivants donnent quelques cas d’application de ces principes.
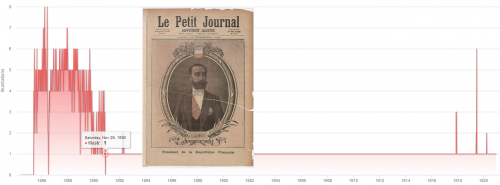
Le rôle de l’image dans la presse quotidienne est un sujet de recherche classique [5],[9] que fouille de données et outils de visualisation peuvent enrichir en données factuelles (micro-faits comme macro-tendances). Ainsi la courbe singulière décrivant la une du supplément du dimanche du Petit Journal (fig. 8) met en évidence l’apparition de l’illustration pleine page en couverture (29 novembre 1890).
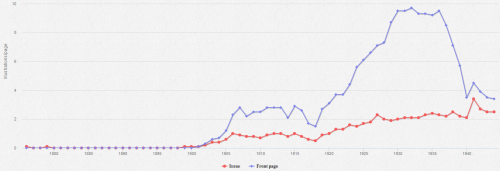
En poursuivant sur cette thématique de l’image, la figure 9 montre que le nombre d’illustrations en une du Petit Parisien (courbe bleue) dépasse la moyenne par page dès 1902, pour suivre ensuite une croissance exponentielle : dans les années 1930, la une contient 45 % des illustrations d’un fascicule de 8 à 10 pages.
Les facteurs de forme de la presse quotidienne ont varié au fil des siècles. La figure 5 permet de situer une des transitions majeures dans la décennie 1880, avec deux familles de titres, les « anciens », basés sur le système du rubriquage (Le Gaulois, Le Journal des débats politiques et littéraires), et les autres (Le Matin, Le Petit Parisien, Ouest-Eclair) qui naissent avec – ou adoptent rapidement –, une mise en page « moderne », avec des caractéristiques qui sont celles de notre presse contemporaine : page de une graphique, titre en bandeau, granularité de l’information à l’article. Cette typologie et son évolution entre XIXe et XXe siècles est illustrée avec un graphe à bulles (fig. 10) combinant les trois facteurs de modernité de forme que sont nombre moyen d’articles par page (x), d’illustrations par page (y) et en une (z, diamètre des bulles).

Légendes : 19 : XIXe s. ; 20 : XXe s. ; PJI : Le Petit Journal supp. illustré ; JDPL : Le Journal des débats politiques et littéraires ;
OE : Ouest-Eclair éd. de Rennes ; G : Le Gaulois ; PP : Le Petit Parisien ; M : Le Matin
Autre registre de métadonnées disponible, la classification réalisée durant le traitement OLR des types de contenus (texte, illustration, tableau et publicité, ou plutôt « réclame ») autorise une analyse documentaire poussée. La figure 11 montre par exemple l’impact de la Grande guerre sur l’activité économique de la presse et permet d’évaluer le délai de retour au niveau d’avant-guerre (10 ans).

De telles métadonnées quantitatives, ordonnées selon des dimensions à la fois temporelle et éditoriale (les titres de presse) et éventuellement croisées avec les contenus eux-mêmes (les textes océrisés), constitue un terrain fertile en hypothèses de recherche. Par ailleurs, la classification des types de contenus sera d’une grande aide pour les chercheurs ciblant un type de contenus spécifique (comme il a été dit, la presse quotidienne est un média composite : extraire un sous-corpus d’une collection de presse numérique reste un challenge technique). Ainsi d’une étude portant sur la formation de la chronique boursière dans la presse quotidienne [10], pour laquelle les données quantitatives offrent un accès direct au corpus cible, les tableaux présents dans la presse quotidienne étant majoritairement utilisés pour les cotations (fig. 12).

C. Visualisation de données pour la médiation numérique
La visualisation de données offre également des perspectives novatrices en matière de redécouverte et de réappropriation des documents décrits par ces données. En effet, les méthodes et outils de visualisation de données sont en mesure d’aider les bibliothèques numériques à diversifier les modalités de parcours de leurs collections, en allant au-delà des classiques accès par recherche en texte intégral et feuilletage de pages.
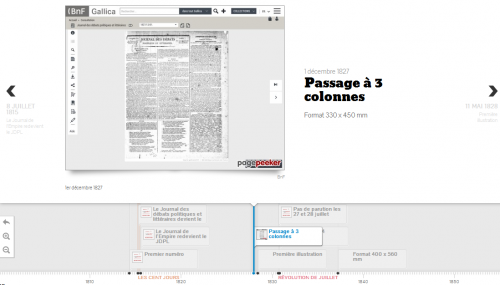
La figure suivante montre ainsi une visualisation interactive de la moyenne de mots par page du Journal des débats politiques et littéraires sur toute sa durée (1814-1944, plusieurs dizaines de milliers de numéros, un point par numéro). Les franches ruptures et autres singularités mises en évidence par ce graphe invitent l’utilisateur à entrer dans la collection de presse via une nouvelle dimension, sa densité en mots. Cette dimension est exprimée par une métaphore visuelle à laquelle est associée une seconde dimension, le temps, à travers lequel le promeneur numérique se déplace (avec une fonctionnalité de zoom).

Les ruptures observées trouvent leur explication dans les changements successifs de maquette et/ou de format, motivés tant par les innovations techniques survenues dans la fabrication du papier ou l’imprimerie, comme étudié par les historiens de la presse [11] (1er déc. 1827 : 3 colonnes, 330×450 mm ; 1er oct. 1830 : 4 colonnes; 1er mars 1837 : 400×560 mm ; 1er janv. 1896 : typographie plus dense) que par le contexte politique (4 août 1914 : réduction à 2 pages et 3 colonnes puis retour à 6 colonnes le 8 août). Les valeurs aberrantes peuvent aussi révéler des trésors documentaires, ainsi des cas de censure telle que pratiquée durant la Grande guerre (voir ainsi le 22 mai 1915). Ici le vide, soit la disparition d’un texte, est découvert en l’affichant. Et les données racontent plusieurs histoires (pour paraphraser Edward Tufte [12]), la Grande, celle de la presse imprimée, celle du Journal des débats.
Il est intéressant de noter que ces documents singuliers, révélés par l’action conjuguée d’une métadonnée quantitative et d’une métaphore visuelle, resteraient cachés, perdus dans la profusion documentaire, pour qui se lancerait dans leur quête muni des outils classiques que sont recherche par critère bibliographique et interrogation par mot clé.
Comme on l’a vu, la visualisation de données en masse fait ressortir des valeurs singulières. En matière d’illustration, un graphe similaire au précédent mais appliqué à la dimension « nombre d’images » met en évidence des fascicules richement illustrés du Journal des débats politiques et littéraires (fig. 14), qui s’avèrent être des suppléments illustrés (27 mars 1899, 201 illustrations), mais également des événements clés de l’histoire du titre, comme la première illustration publiée (dans une publicité, le 11 mai 1828).

Faits et informations extraits grâce aux techniques de fouille et de visualisation de données gagneront à venir enrichir d’autres supports de médiation, qu’ils soient numériques ou non. Dans le premier cas, on pourra citer blog, dossier pédagogique, frise chronologique (fig. 15), etc.
Autre exemple, une exposition sur l’histoire de la presse [13] souhaitant scénographier l’évolution des formats de papier et les liens entre innovations techniques, cadre économique et politique éditoriale, pourrait s’appuyer tant sur des documents physiques (fig. 16, en haut) que sur l’expression graphique d’une analyse statistique des formats de page (calculés à partir des informations extraites des images numérisées, fig. 16, en bas). Il serait tentant de rattacher ce cas illustratif aux tensions entre micro-histoire et histoire quantitative. Opposition artificielle dans le cadre de la mission de médiation qui échoit aux musées et bibliothèques : sélectionner quelques documents exemplaires ou travailler sur une (très6 ) longue série de documents/données n’est pas antinomique.

Classiquement, ce graphe met en lumière tant que les valeurs moyennes et leurs transitions que des points atypiques, tels ce numéro à 24 mots par page (2 mai 1899) qui s’avère être le plan de l’Exposition universelle de Paris, ou encore un courrier commercial consécutif à la loi sur la presse de 1851, ainsi que les événements historiques singuliers (eu regard des conditions de publication de la presse quotidienne) que sont les périodes de déclaration de guerre.
D. Interroger les métadonnées quantitatives
Utiliser des outils adaptés contribue à améliorer l’efficacité de la fouille de données. BaseX7 est une de ces solutions simples et élégantes (au même titre que les systèmes NoSQL) permettant d’agglomérer tous les fichiers de métadonnées au format XML et d’interroger l’ensemble avec des requêtes XPath/XQuery. Dans le cadre d’une action de médiation numérique consacrée à un titre de presse ou pour l’ensemble du jeu de données, une telle requête identifiera par exemple toutes les pages « graphiques », c’est-à-dire celles à la fois pauvres en mots et incluant au moins une illustration. Des centaines de pages sont ainsi extraites du corpus (fig. 17 : bandes dessinées, dessins de presse, portraits, cartes, partitions, publicités, etc.), autant de documents remarquables qu’il aurait été fort laborieux de découvrir par un dépouillement (fût-il numérique) de la collection.

E. Valoriser les métadonnées quantitatives
Les documents imprimés constitutifs des bibliothèques patrimoniales numériques ne sont pas des textes anonymes et indifférenciés. Ils présentent tous des facteurs de forme singuliers, ils sont tous héritiers de la longue histoire de l’imprimé. Prendre en compte leur matérialité afin de favoriser les usages numériques qui en sont faits est une hypothèse légitime. En particulier dans le cas de la presse ancienne numérisée, du fait de sa profusion8 et de sa nature composite : des centaines d’articles par fascicule, jusqu’à 15 000 mots par page (souvent bruités en sortie du traitement OCR) pour les grands formats du début du XXe s., de nombreux registres de discours : éditorial, information, loisirs, annonces, etc. Comme le souligne Ryan Cordell, “even digitized periodicals remain voluminous, messy, provocatively difficult” [14].
Par conséquent, il fait sens d’alimenter les outils d’accès et d’interrogation des collections de presse avec les métadonnées quantitatives issues de l’OLR ou l’OCR, elles-mêmes porteuses d’une information relative à la forme des documents physiques. En termes d’usage, la figure 18 montre deux exemples de requêtes avancées combinant des critères bibliographiques, par mot-clé et relatifs à la structure logique (en gras : titre d’article, corps de l’article, article incluant un tableau, etc.). Ces requêtes très expressives, proches du langage naturel, sont particulièrement adaptées à la recherche d’information au sein d’un portail de presse.
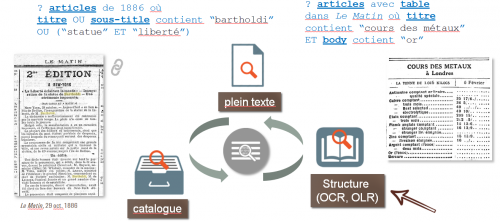
La bibliothèque numérique Trove (http://trove.nla.gov.au) est un exemple emblématique de cette approche. La figure 19 montre son formulaire de recherche avancée et ses critères de structure (types de contenu, longueur de l’article, article illustré).

Cette approche trouve un cas d’application voisin dans la recherche d’images au sein d’une collection de presse numérisée, riche en ressources iconographiques comme il a été dit (cf. fig. 6). En s’appuyant sur les sources d’information à disposition (métadonnée « nombre d’illustrations » ; texte de légende et de titre d’article fournis par l’OLR et l’OCR), il est possible d’interroger la collection à cette fin. Les métadonnées quantitatives jouent alors le rôle d’un simple index (au sens informatique du terme).
Un démonstrateur basé sur le jeu de métadonnées augmenté du texte des légendes a été développé. Utilisant une API REST et des scripts XQuery interrogeant la base, il autorise l’expression de requêtes mêlant critères bibliographique et mot-clé. La figure 20 montre un exemple de recherche iconographique portant sur la statue de la liberté9. Onze illustrations sont trouvées, à comparer aux quinze documents présents dans la collection d’images de Gallica (extraites selon la seule métadonnée bibliographique « titre »).
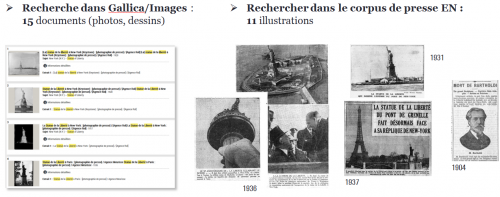
Dans de nombreux cas, l’iconographie de la presse pourra couvrir les lacunes de la collection d’images. Ainsi l’exemple suivant consacré à la bataille de Málaga, événement absent de la collection d’images mais bien sûr traité par la presse quotidienne française de 1937 (quinze illustrations).

Ce démonstrateur d’un moteur de recherche d’illustrations de presse a permis de mettre en lumière les points suivants :
- L’iconographie présente dans la presse quotidienne est complémentaire d’une collection d’images « classique » (photographies, dessins), avec une forte couverture des thématiques histoire, société, culture populaire, vie quotidienne, etc. Pour l’étude des XIXe et XXe siècles, la presse, premier média de masse, est une ressource sans pareil. Par contre, la presse quotidienne est très peu illustrée avant 1870 (il faut attendre le tournant des XIXe et XXe siècles pour que se généralise le photoreportage, permis par l’amélioration des techniques de prise de vue et l’invention de la similigravure).
- Pour la presse spécialisée (scientifique, professionnelle, sports, loisirs, etc.) et la presse magazine, l’iconographie n’a peu ou pas d’équivalent dans la collection d’images. Ainsi, l’exemple précédent de la bataille de Málaga appliqué au titre emblématique de l’histoire de la presse magazine qu’est Regards permettrait de dévoiler des photographies de Robert Capa et Gerda Taro (ou Henri Cartier-Bresson et Willy Ronis sur d’autres reportages).

- Elle offre un plus large registre de types iconographiques : dessin, photographie, caricature, extrait de film, carte, bande dessinée, publicité, etc. (cf. fig. 17).
- Les 427 000 illustrations des 637 000 pages du corpus EN-BnF sont à mettre en regard des dimensions de la collection d’images de Gallica (950 000 illustrations pour 400 000 documents). Rapporté à une collection de 5 millions de pages de presse, le nombre d’illustrations potentiel avoisinerait les 3 millions.
- Les illustrations sont légendées à 80 % dans le corpus EN-BnF. À défaut de légende, le titre de l’article peut être utilisé, ou encore le premier paragraphe de l’article.
- La qualité de l’iconographie de la presse va de médiocre à correct, du fait des techniques de reproduction et d’impression.
Et que dire des monographies imprimées ? Leur OCR contient bien évidemment des informations quantitatives quant à leur contenu : mot, tableau, illustration (voir [15] pour la démonstration de l’intérêt d’une utilisation extensive de ce principe). Le même mode opératoire pourrait leur être appliqué à des fins de recherche iconographique, en s’appuyant sur :
- la classification en divers types d’« illustrations » opérée automatiquement par certains moteurs OCR (tableaux, timbres, annotations manuscrites, ornements et autres culs-de-lampe),
- une annotation réalisée par un opérateur humain lors de la numérisation (la BnF demande l’identification des cartes et des partitions musicales),
- des algorithmes de détection appliqués en post-traitement contribuant à affiner la description des images en les classant selon leur mode de production (dessin au trait, photographies) ou encore leurs caractéristiques (noir et blanc/couleur, taille).
La figure 23 présente un scénario type de recherche iconographique dans les collections d’imprimés, où cartes, schémas et photographies de la planète Mars sont identifiées grâce à des critères de forme (« page illustrée ») et de type (« cartes »). Là encore, les éventuelles lacunes de la collection des cartes (100 000 cartes dans Gallica, aucune de Mars) peuvent être compensées par l’iconographie présente dans les imprimés.

IV. Contrôler la qualité des données
La qualité des données dérivées influence la validité des analyses et interprétations (notamment visuelles, voir [4],[16] sur cette problématique). En effet, des données irrégulières en nature ou discontinues dans le temps pourraient introduire des biais. Une étude qualitative doit donc impérativement être menée au préalable à toute analyse interprétative.
Et dans tous les cas, les informations de qualité relatives aux collections ou au corpus numériques (taux OCR, manques, niveau de structuration, etc.) gagnent à être communiquées aux utilisateurs finaux – monde académique comme grand public –, par souci de transparence. Une utilisation ultérieure fiable de ces collections et corpus repose en partie sur ce prérequis.
La presse quotidienne des XIXe et XXe siècles se caractérise par une bonne homogénéité de forme, ce qui induit une cohérence et une granularité constantes des métadonnées dérivées du corpus (fascicule, page, article, etc.). Par ailleurs, la démarche employée (fouille de données massive, le fondement de toute approche big data [17]) rassure quant à sa représentativité. Une analyse statistique peut également aider à fournir les informations nécessaires de couverture temporelle et de distribution des données (fig. 24). On constate par exemple que la période 1814-1867 est sous-représentée (par un seul titre, le JDPL). Par contre, la visualisation simultanée du nombre de titres périodiques10 actifs année par année (information extraite du catalogue général de la BnF, courbe bleu) montre que la distribution du corpus est relativement bien corrélée à la production éditoriale.

Comme on vient de le voir, les corpus eux-mêmes peuvent contribuer à leur propre validation qualitative. Ainsi une visualisation en calendrier des données disponibles pour un titre de presse (fig. 25) montre les rares manques, ce qui laisse à penser que son avatar numérique est représentatif de la réalité documentaire sous-jacente [18].

Ou encore, préalablement à une étude sur l’apparition de la chronique boursière dans la presse française s’appuyant sur les contenus typés « tableau » ([10], cf. fig. 12), cette hypothèse sera validée empiriquement par les brusques inflexions constatées en 1914 et 1939 (cf. fig. 26), étant connu et établi par ailleurs le fait historique du quasi-arrêt des tableaux de cotation et de la chronique boursière durant les deux guerres mondiales.
Conclusion
Cette étude a montré que les métadonnées quantitatives de fascicules de journaux, a priori peu disertes, s’expriment haut et fort lorsqu’interrogées à la bonne distance. Ce constat s’explique par le type documentaire, la presse quotidienne, sujet idéal pour une structuration fine (« à l’article ») et partant la création d’un ensemble cohérent de métadonnées sérialisées selon une dimension temporelle.
Pour une bibliothèque numérique, créer et diffuser de telles métadonnées quantitatives – par simple téléchargement ou par tout autre moyen (API, interface web d’interrogation) – donne aux chercheurs un terrain d’étude prêt à l’usage pour des actions de fouille de données dans des disciplines variées (histoire de la presse, de l’imprimé, du journalisme ; sciences de l’information ; sociologie, etc.) relevant du champ et des pratiques des « humanités numériques ». Mais ces métadonnées sont susceptibles de s’appliquer à d’autres catégories d’usage, qu’il s’agisse de gestion de la bibliothèque numérique, de médiation numérique ou encore de consultation des collections numériques.
Par ailleurs, le mode opératoire rend cette expérimentation généralisable, à plusieurs titres :
- Le traitement OLR est désormais un standard en matière de numérisation des collections de presse patrimoniales.
- La génération de métadonnées quantitatives ne nécessite qu’un traitement informatique élémentaire.
- L’exploitation de telles métadonnées peut s’appuyer sur une grande variété d’outils de fouille et de visualisation de données, qui ne nécessitent le plus souvent que des compétences informatiques basiques.
Enfin, ses résultats appellent plusieurs suites possibles :
- Expérimenter sur d’autres types documentaires présentant une cohérence de forme et une dimension temporelle : revues et magazines du XXe, premiers livres imprimés du XVIe s. etc.
- Fournir les résultats aux chargés de collection et de médiation numérique des portails numériques (dans le cas de la BnF, bnf.fr et data.bnf.fr) afin de les éditorialiser au fil d’actions de médiation de la collection numérique (présentation des titres de presse, frise chronologique, etc.).
- Mettre à la disposition des acteurs de la recherche des jeux de métadonnées quantitatives prédéfinis (par titre de presse, par date, etc.) et/ou une infrastructure technique de livraison de documents numériques11 dans laquelle les spécificités de la presse numérisée seraient prises en compte (sélection de corpus par critères multiples : titre, date, titre de rubrique, type de contenu, etc.).
- Enrichir les moteurs de recherche avec ces métadonnées quantitatives afin de décrire le plus fidèlement possible tant la forme matérielle que la structure sémantique de la presse numérisée.
Nous pensons que cette étude a mis en évidence le bénéfice pour les bibliothèques numériques à utiliser les méthodes et outils du champ des humanités numériques. Et fournir ainsi de meilleurs services à tous leurs utilisateurs, y compris ceux de la communauté des humanités numériques, en mettant à leur disposition des corpus numériques plus riches et mieux structurés.
Les scripts, les jeux de données dérivées et les graphes décrits dans cet article sont librement disponibles : http://altomator.github.io/EN-data_mining. Ils ont été créés avec des outils open source (BaseX, Highcharts, Google Charts, timeline.knightlab).
Bibliographie
- K. Cukier, V. Mayer-Schönberger, Big Data: A Revolution That Will Transform How We Live, Work, and Think, Eamon Dolan/Houghton Mifflin Harcourt, 2013.
- R. Green and M. Panzer , “The Interplay of Big Data, WorldCat, and Dewey”, in Advances In Classification Research Online, 24(1).
- M. Teets and M. Goldner, “Libraries’ Role in Curating and Exposing Big Data”, Future Internet 2013, 5, 429-438.
- R. Lapôtre, “Faire parler les données des bibliothèques : du Big Data à la visualisation de données”, Library Curator memorandum, ENSSIB, 2014. http://www.enssib.fr/bibliotheque-numerique/notices/65117-faire-parler-les-donnees-des-bibliotheques-du-big-data-a-la-visualisation-de-donnees
- The Front Page, http://dhistory.org/frontpages.
- T. Sherratt, “4 million articles later…”, June 29, 2012.
http://discontents .com .au/ 4-million-articles-later - C. Neudecker and L. Wilms, KB National Library of the Netherlands, “Europeana Newspapers, A Gateway to European Newspapers Online”, FLA Newspapers/GENLOC PreConference Satellite Meeting, Singapore, August 2013.
- F. Moretti, Graphes, cartes et arbres. Modèles abstraits pour une autre histoire de la littérature. Les Prairies Ordinaires, 2008. Trad. de l’anglais, Verso, 2005.
- L. Joffredo, “La fabrication de la presse”. http://expositions.bnf.fr/presse/arret/07-2.htm
- P.-C. Langlais, “La formation de la chronique boursière dans la presse quotidienne française (1801-1870). Métamorphoses textuelles d’un journalisme de données”. Thèse de doctorat en science de l’information et de la communication, CELSA Université Paris-Sorbonne, 2015.
- G. Feyel, La Presse en France des origines à 1944. Histoire politique et matérielle, Ellipses, 2007.
- E. Tufte, The Visual Display of Quantitative Information, Graphics Press, 2001.
- “SCOOP, une histoire graphique de la presse”, musée de l’Imprimerie, Lyon, 2015.
- R. Cordell, “What has the Digital Meant to American Periodicals Scholarshipˮ, American Periodicals, 26.1 2016.
- Lease Morgan, E., “Use and understand: the inclusion of services against texts in library catalogs and discovery systems”, Libray Hi Tech, Vol. 30, Issue 1, pp. 35-59.
- Y. Jeanneret, « Complexité de la notion de trace. De la traque au tracé » In : Galinon-Mélénec Béatrice (dir.). L’Homme trace. Perspectives anthropologiques des traces contemporaines. CNRS Editions, Paris, 2011.
- E. Aiden, J.-B. Michel, Uncharted: Big Data as a Lens on Human Culture. New York : Riverhead Books, 2013.
- A. Dunning, and C. Neudecker, “Representation and Absence in Digital Resources: The Case of Europeana Newspapers”, Digital Humanities 2014, Lausanne, Switzerland. http://dharchive.org/paper/DH2014/Paper-773.xml
- http://www.europeana-newspapers.eu/ [↩]
- Cf. par ex. John Burrows, “Textual Analysis”, in A Compagnion to Digital Humanities, 2004 [↩]
- http://prelia.hypotheses.org [↩]
- http://www.medias19.org [↩]
- https://viraltexts.org [↩]
- Ici très exactement 47 799. [↩]
- basex.org [↩]
- Qui ne manque pas de faire écho à notre ère d’abondance informationnelle… On peut estimer à 120 millions de pages de presse la collection patrimoniale de la BnF, le catalogue général recensant environ 130 000 titres (presse et revues confondues). En 2012, 129 millions de pages étaient déjà numérisées en Europe (The “State of the Art”: A Comparative Analysis of Newspaper Digitization to Date, 2015. https://www.crl.edu/sites/default/files/d6/attachments/events/ICON_Report-State_of_Digitization_final.pdf) [↩]
- http://basexapplication.2ftbeuqbi2.eu-central-1.elasticbeanstalk.com/rest/?run=findCaptionedIllustrations.xq&fromDate=1886-01-01&keyword=statue.*liberté. Demander à l’auteur l’accès à l’API. [↩]
- De périodicité inférieure au mois. [↩]
- Ce point sera abordé par le projet de recherche BnF « Corpus » (2016-2018), qui a pour objectif l’étude des services que peut rendre une bibliothèque en matière de fouille de textes et de données à destination de la recherche. [↩]




