Last night I spoke at a London Perl Mongers meeting. As part of the talk I spoke about a toolchain that I have been using for creating ebooks. In this article I’ll go into a little more detail about the process.
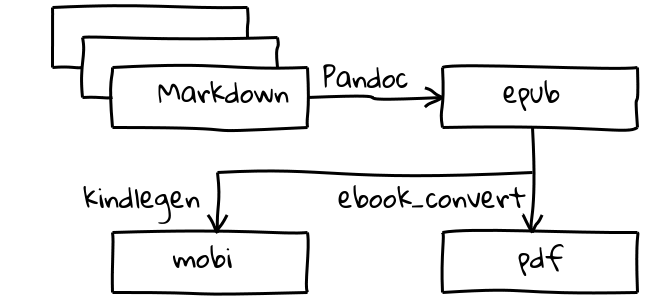
Basically, we’re talking about a process that takes one or more files in some input format and (as easily as possible) turns them into one or more output formats which can be described as “ebooks”. So before we can decided which tools we need, we should decide what those various file formats should be.
For my input format I chose Markdown. This is a text-based format that has become popular amongst geeks over the last few years. Geeks tend to like text-based formats more than the proprietary binary formats like those produced by word processors. This is for a number of reasons. You can read them without any specialised tools. You’re not tied down to using specific tools to create them. And it’s generally easier to store them in a revision management system like Github.
For my output formats, I wanted EPUB and Mobipocket. EPUB is the generally accepted standard for ebooks and Mobipocket is the ebook format that Amazon use. And I also wanted to produce PDFs, just because they are easy to read on just about any platform.
(As an aside, you’ll notice that I said nothing in that previous paragraph about DRM. That’s simply because nice people don’t do that.)
Ok, so we know what file formats we’ll be working with. Now we need to know a) how we create the input format and b) how we convert between the various formats. Creating the Markdown files is easy enough. It’s just a text file, so any text editor would do the job (it would be interesting to find out if any word processor can be made to save text as Markdown).
To convert our Markdown into EPUB, we’ll need a new tool. Pandoc describes itself as “a universal document converter”. It’s not quite universal (otherwise that would be the only tool that we would need), but it is certainly great for this job. Once you have installed Pandoc, the conversion is simple:
pandoc -o your_book.epub title.txt your_book.md --epub-metadata=metadata.xml --toc --toc-depth=2
There are two extra files you need here (I’m not sure why it can’t all be in the same file, but that’s just the way it seems to be). The first (which I’ve called “title.txt”), contains two lines. The first line has the title of your book and the second has the author’s name. Each line needs to start with a “%” character. So it might look like this:
% Your title % Your name
The second file (which I’ve called “metadata.xml”) contains various pieces of information about the book. It’s (ew!) XML and looks like this:
<metadata xmlns:dc="http://purl.org/dc/elements/1.1/"> <dc:title id="main">Your Title</dc:title> <meta refines="#main" property="title-type">main</meta> <dc:language>en-GB</dc:language> <dc:creator opf:file-as="Surname, Forename" opf:role="aut">Forename Surname</dc:creator> <dc:publisher>Your name</dc:publisher> <dc:date opf:event="publication">2015-08-14</dc:date> <dc:rights>Copyright ©2015 by Your Name</dc:rights> </metadata>
So after creating those files and running that command, you’ll have an EPUB file. Next we want to convert that to a Mobipocket file so that we can distribute our book through Amazon. Unsurprisingly, the easiest way to do that is to use a piece of software that you get from Amazon. It’s called Kindlegen and you can download it from their site. Once it is installed, the conversion is as simple as:
kindlegen perlwebbook.epub
This will leave you with a file called “your_book.mobi” which you can upload to Amazon.
There’s one last conversion that you might need. And that’s converting the EPUB to PDF. Pandoc will make that conversion for you. But it does it using a piece of software called LaTeX which I’ve never had much luck with. So I looked for an alternative solution and found it in Calibre. Calibre is mainly an ebook management tool, but it also converts between many ebook formats. It’s pretty famous for having a really complex user interface but, luckily for us, there’s a command line program called “ebook-convert” – which we can use.
ebook-convert perlwebbook.epub perlwebbook.pdf
And that’s it. We start with a Markdown file and end up with an ebook in three formats. Easy.
Of course, that really is the easy part. There’s a bit that comes before (actually writing the book) and a bit that comes after (marketing the book) and they are both far harder. Last year I read a book called Author, Publisher, Entrepreneur which covered these three steps to a very useful level of detail. Their step two is rather different to mind (they use Microsoft Word if I recall correctly) but what they had to say about the other steps was very interesting. You might find it interesting if you’re thinking of writing (and self-publishing) a book.
I love the way that ebooks have democratised the publishing industry. Anyone can write and publish a book and make it available to everyone through the world’s largest book distribution web site.
So what are you waiting for? Get writing. If you find my toolchain interesting (or if you have any comments on it) then please let me know.
And let me know what you’ve written.
