Like XML, XQuery is a case-sensitive language. Keywords in
XQuery use lower-case characters and are not reserved—that is,
names in XQuery expressions are allowed to be the same as language
keywords, except for certain unprefixed function-names listed in
A.3 Reserved Function
Names.
2.1 Expression Context
[Definition: The expression
context for a given expression consists of all the information
that can affect the result of the expression.] This information is
organized into two categories called the static context and the dynamic
context.
2.1.1 Static
Context
[Definition: The static context of an
expression is the information that is available during static
analysis of the expression, prior to its evaluation.] This
information can be used to decide whether the expression contains a
static error.
If analysis of an expression relies on some component of the
static
context that has not been assigned a value, a static error is raised
[err:XPST0001].
The individual components of the static context are summarized below.
Rules governing the scope
and initialization of these components can be found in C.1 Static Context
Components.
-
[Definition:
XPath 1.0 compatibility mode. This component must be set by all
host languages that include XPath 2.0 as a subset, indicating
whether rules for compatibility with XPath 1.0 are in effect.
XQuery sets the value of this component to
false. ]
-
[Definition:
Statically known namespaces. This is a set of (prefix, URI)
pairs that define all the namespaces that are known during static
processing of a given expression.] The URI value is whitespace
normalized according to the rules for the xs:anyURI
type in [XML Schema]. Note the difference
between in-scope namespaces, which is a
dynamic property of an element node, and statically known namespaces, which is a
static property of an expression.
-
[Definition:
Default element/type namespace. This is a namespace URI or
"none". The namespace URI, if present, is used for any unprefixed
QName appearing in a position where an element or type name is
expected.] The URI value is whitespace normalized according to the
rules for the xs:anyURI type in [XML Schema].
-
[Definition: Default function namespace.
This is a namespace URI or "none". The namespace URI, if present,
is used for any unprefixed QName appearing in a position where a
function name is expected.] The URI value is whitespace normalized
according to the rules for the xs:anyURI type in
[XML Schema].
-
[Definition: In-scope schema definitions. This
is a generic term for all the element declarations, attribute
declarations, and schema type definitions that are in scope during
processing of an expression.] It includes the following three
parts:
-
[Definition: In-scope schema types. Each
schema type definition is identified either by an expanded QName (for
a named type) or by an implementation-dependent
type identifier (for an anonymous type). The in-scope schema
types include the predefined schema types described in 2.5.1 Predefined Schema Types.
If the Schema
Import Feature is supported, in-scope schema types also include
all type definitions found in imported schemas. ]
-
[Definition: In-scope element declarations.
Each element declaration is identified either by an expanded QName (for
a top-level element declaration) or by an implementation-dependent element
identifier (for a local element declaration). If the Schema
Import Feature is supported, in-scope element declarations
include all element declarations found in imported
schemas. ] An element declaration includes
information about the element's substitution group affiliation.
[Definition: Substitution groups
are defined in [XML Schema] Part 1,
Section 2.2.2.2. Informally, the substitution group headed by a
given element (called the head element) consists of the set
of elements that can be substituted for the head element without
affecting the outcome of schema validation.]
-
[Definition: In-scope attribute
declarations. Each attribute declaration is identified either
by an expanded
QName (for a top-level attribute declaration) or by an
implementation-dependent
attribute identifier (for a local attribute declaration).
If the Schema
Import Feature is supported, in-scope attribute declarations
include all attribute declarations found in imported
schemas.]
-
[Definition: In-scope variables.
This is a set of (expanded QName, type) pairs. It defines the set
of variables that are available for reference within an expression.
The expanded
QName is the name of the variable, and the type is the
static type of
the variable.]
Variable declarations
in a Prolog are added to
in-scope variables. An
expression that binds a variable (such as a let,
for, some, or every
expression) extends the in-scope variables of its
subexpressions with the new bound variable and its type.
Within a function
declaration, the in-scope variables are extended by the
names and types of the function
parameters.
-
[Definition: Context item
static type. This component defines the static type of the context item within
the scope of a given expression.]
-
[Definition: Function signatures.
This component defines the set of functions that are available to
be called from within an expression. Each function is uniquely
identified by its expanded QName and its arity (number of
parameters).] In addition to the name and arity, each function
signature specifies the static types of the function parameters and
result.
The function signatures include the
signatures of constructor functions, which are
discussed in 3.12.5
Constructor Functions.
-
[Definition:
Statically known collations. This is an implementation-defined set of
(URI, collation) pairs. It defines the names of the collations that
are available for use in processing queries and
expressions.] [Definition: A collation is a
specification of the manner in which strings and URIs are compared
and, by extension, ordered. For a more complete definition of
collation, see [XQuery 1.0 and
XPath 2.0 Functions and Operators].]
-
[Definition: Default collation. This
identifies one of the collations in statically known collations as the
collation to be used by functions and operators for comparing and
ordering values of type xs:string and
xs:anyURI (and types derived from them) when no
explicit collation is specified.]
-
[Definition: Construction mode.
The construction mode governs the behavior of element and document
node constructors. If construction mode is preserve,
the type of a constructed element node is xs:anyType,
and all attribute and element nodes copied during node construction
retain their original types. If construction mode is
strip, the type of a constructed element node is
xs:untyped; all element nodes copied during node
construction receive the type xs:untyped, and all
attribute nodes copied during node construction receive the type
xs:untypedAtomic.]
-
[Definition: Ordering mode. Ordering
mode, which has the value ordered or
unordered, affects the ordering of the result sequence
returned by certain path expressions, union,
intersect, and except expressions, and
FLWOR expressions that have no order by clause.]
Details are provided in the descriptions of these expressions.
-
[Definition: Default order for empty
sequences. This component controls the processing of empty
sequences and NaN values as ordering keys in an
order by clause in a FLWOR expression, as described in
3.8.3 Order By and Return
Clauses.] Its value may be greatest or
least.
-
[Definition: Boundary-space
policy. This component controls the processing of boundary
whitespace by direct element constructors, as
described in 3.7.1.4 Boundary
Whitespace.] Its value may be preserve or
strip.
-
[Definition: Copy-namespaces
mode. This component controls the namespace bindings that are
assigned when an existing element node is copied by an element
constructor, as described in 3.7.1 Direct Element
Constructors. Its value consists of two parts:
preserve or no-preserve, and
inherit or no-inherit.]
-
[Definition: Base URI. This is an absolute
URI, used when necessary in the resolution of relative URIs (for
example, by the fn:resolve-uri function.)] The URI
value is whitespace normalized according to the rules for the
xs:anyURI type in [XML
Schema].
-
[Definition: Statically known documents.
This is a mapping from strings onto types. The string represents
the absolute URI of a resource that is potentially available using
the fn:doc function. The type is the static type of a call to
fn:doc with the given URI as its literal argument. ]
If the argument to fn:doc is a string literal that is
not present in statically known documents, then the
static type of
fn:doc is document-node()?.
Note:
The purpose of the statically known documents is to
provide static type information, not to determine which documents
are available. A URI need not be found in the statically known
documents to be accessed using fn:doc.
-
[Definition:
Statically known collections. This is a mapping from strings
onto types. The string represents the absolute URI of a resource
that is potentially available using the fn:collection
function. The type is the type of the sequence of nodes that would
result from calling the fn:collection function with
this URI as its argument.] If the argument to
fn:collection is a string literal that is not present
in statically known collections, then the static type of
fn:collection is node()*.
Note:
The purpose of the statically known collections is to
provide static type information, not to determine which collections
are available. A URI need not be found in the statically known
collections to be accessed using
fn:collection.
-
[Definition: Statically known
default collection type. This is the type of the sequence of
nodes that would result from calling the fn:collection
function with no arguments.] Unless initialized to some other value
by an implementation, the value of statically known default
collection type is node()*.
2.1.2 Dynamic
Context
[Definition: The dynamic context of
an expression is defined as information that is available at the
time the expression is evaluated.] If evaluation of an expression
relies on some part of the dynamic context that has not been
assigned a value, a dynamic error is raised [err:XPDY0002].
The individual components of the dynamic context are summarized
below. Further rules governing the semantics of these components
can be found in C.2 Dynamic Context
Components.
The dynamic context consists of all the
components of the static context, and the additional
components listed below.
[Definition:
The first three components of the dynamic context (context item, context
position, and context size) are called the focus of the
expression. ] The focus enables the processor to keep track of
which items are being processed by the expression.
Certain language constructs, notably the path expression
E1/E2 and the predicate E1[E2], create a new
focus for the evaluation of a sub-expression. In these constructs,
E2 is evaluated once for each item in the sequence
that results from evaluating E1. Each time
E2 is evaluated, it is evaluated with a different
focus. The focus for evaluating E2 is referred to
below as the inner focus, while the focus for evaluating
E1 is referred to as the outer focus. The inner
focus exists only while E2 is being evaluated. When
this evaluation is complete, evaluation of the containing
expression continues with its original focus unchanged.
-
[Definition: The context item is the
item currently being processed. An item is either an atomic value
or a node.][Definition: When the context item is a node,
it can also be referred to as the context node.] The context
item is returned by an expression consisting of a single dot
(.). When an expression E1/E2 or
E1[E2] is evaluated, each item in the sequence
obtained by evaluating E1 becomes the context item in
the inner focus for an evaluation of E2.
-
[Definition: The context position
is the position of the context item within the sequence of items
currently being processed.] It changes whenever the context item
changes. When the focus is defined, the value of the context
position is an integer greater than zero. The context position is
returned by the expression fn:position(). When an
expression E1/E2 or E1[E2] is evaluated,
the context position in the inner focus for an evaluation of
E2 is the position of the context item in the sequence
obtained by evaluating E1. The position of the first
item in a sequence is always 1 (one). The context position is
always less than or equal to the context size.
-
[Definition: The context size is the
number of items in the sequence of items currently being
processed.] Its value is always an integer greater than zero. The
context size is returned by the expression fn:last().
When an expression E1/E2 or E1[E2] is
evaluated, the context size in the inner focus for an evaluation of
E2 is the number of items in the sequence obtained by
evaluating E1.
-
[Definition: Variable values. This
is a set of (expanded QName, value) pairs. It contains the same
expanded
QNames as the in-scope variables in the static context for
the expression. The expanded QName is the name of the variable and
the value is the dynamic value of the variable, which includes its
dynamic
type.]
-
[Definition: Function
implementations. Each function in function signatures has a
function implementation that enables the function to map instances
of its parameter types into an instance of its result type.
For a user-defined function,
the function implementation is an XQuery expression. For a
built-in
function or external function, the function
implementation is implementation-dependent.]
-
[Definition: Current dateTime. This
information represents an implementation-dependent point
in time during the processing of a query, and includes an explicit timezone.
It can be retrieved by the fn:current-dateTime
function. If invoked multiple times during the execution of
a query,
this function always returns the same result.]
-
[Definition: Implicit timezone. This is the
timezone to be used when a date, time, or dateTime value that does
not have a timezone is used in a comparison or arithmetic
operation. The implicit timezone is an implementation-defined value of
type xs:dayTimeDuration. See [XML
Schema] for the range of legal values of a timezone.]
-
[Definition: Available documents.
This is a mapping of strings onto document nodes. The string
represents the absolute URI of a resource. The document node is the
root of a tree that represents that resource using the data model. The document node
is returned by the fn:doc function when applied to
that URI.] The set of available documents is not limited to the set
of statically known documents, and it may be
empty.
If there are one or more URIs in available documents that map to a
document node D, then the document-uri property of
D must either be absent, or must be one of these
URIs.
Note:
This means that given a document node $N, the
result of fn:doc(fn:document-uri($N)) is $N will
always be True, unless fn:document-uri($N) is an empty
sequence.
-
[Definition: Available
collections. This is a mapping of strings onto sequences of
nodes. The string represents the absolute URI of a resource. The
sequence of nodes represents the result of the
fn:collection function when that URI is supplied as
the argument. ] The set of available collections is not limited to
the set of statically known collections, and it
may be empty.
For every document node D that is in the target of
a mapping in available collections, or that is
the root of a tree containing such a node, the document-uri
property of D must either be absent, or must be a URI
U such that available documents contains a mapping
from U to D."
Note:
This means that for any document node $N retrieved
using the fn:collection function, either directly or
by navigating to the root of a node that was returned, the result
of fn:doc(fn:document-uri($N)) is $N will always be
True, unless fn:document-uri($N) is an empty sequence.
This implies a requirement for the fn:doc and
fn:collection functions to be consistent in their
effect. If the implementation uses catalogs or user-supplied URI
resolvers to dereference URIs supplied to the fn:doc
function, the implementation of the fn:collection
function must take these mechanisms into account. For example, an
implementation might achieve this by mapping the collection URI to
a set of document URIs, which are then resolved using the same
catalog or URI resolver that is used by the fn:doc
function.
-
[Definition: Default collection.
This is the sequence of nodes that would result from calling the
fn:collection function with no arguments.] The value
of default collection may be initialized by the
implementation.
2.2
Processing Model
XQuery is defined in terms of the data model and the expression
context.
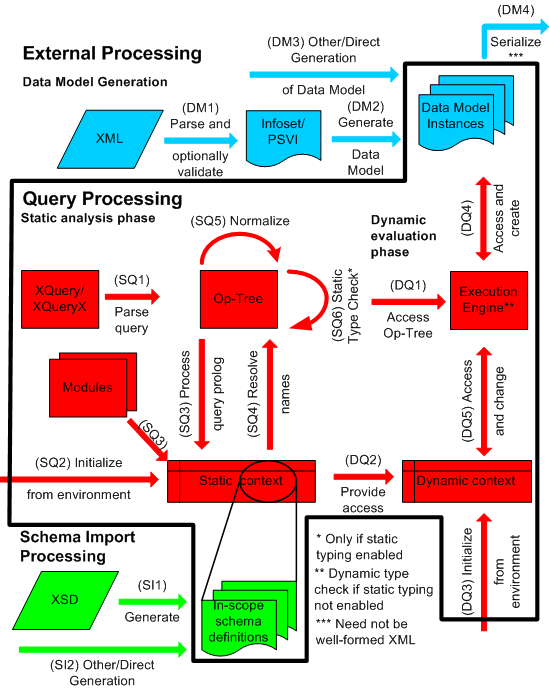
Figure 1: Processing Model Overview
Figure 1 provides a schematic overview of the processing steps
that are discussed in detail below. Some of these steps are
completely outside the domain of XQuery; in Figure 1, these are
depicted outside the line that represents the boundaries of the
language, an area labeled external processing. The external
processing domain includes generation of an XDM instance that represents the
data to be queried (see 2.2.1 Data Model
Generation), schema import processing (see 2.2.2 Schema Import
Processing) and serialization (see 2.2.4 Serialization). The area
inside the boundaries of the language is known as the query processing
domain, which includes the static analysis and
dynamic evaluation phases (see 2.2.3 Expression
Processing). Consistency constraints on the query processing domain
are defined in 2.2.5
Consistency Constraints.
2.2.1 Data Model Generation
Before a
query can be processed, its input data must be
represented as an XDM instance. This process occurs
outside the domain of XQuery, which is why Figure 1 represents it
in the external processing domain. Here are some steps by which an
XML document might be converted to an XDM instance:
-
A document may be parsed using an XML parser that generates an
XML Information Set (see [XML
Infoset]). The parsed document may then be validated against
one or more schemas. This process, which is described in [XML Schema], results in an abstract information
structure called the Post-Schema Validation Infoset (PSVI).
If a document has no associated schema, its Information Set is
preserved. (See DM1 in Fig. 1.)
-
The Information Set or PSVI may be transformed into an XDM instance by a
process described in [XQuery/XPath Data Model
(XDM)]. (See DM2 in Fig. 1.)
The above steps provide an example of how an XDM instance
might be constructed. An XDM instance might also be synthesized
directly from a relational database, or constructed in some other
way (see DM3 in Fig. 1.) XQuery is defined in terms of the
data model, but it
does not place any constraints on how XDM instances are
constructed.
[Definition: Each element node and
attribute node in an XDM instance has a type
annotation (referred to in [XQuery/XPath
Data Model (XDM)] as its type-name property.) The
type annotation of a node is a schema type that describes the relationship
between the string
value of the node and its typed value.] If the XDM instance was derived from a
validated XML document as described in Section 3.3
Construction from a PSVIDM, the type
annotations of the element and attribute nodes are derived from
schema validation. XQuery does not provide a way to directly access
the type annotation of an element or attribute node.
The value of an attribute is represented directly within the
attribute node. An attribute node whose type is unknown (such as
might occur in a schemaless document) is given the type annotation
xs:untypedAtomic.
The value of an element is represented by the children of the
element node, which may include text nodes and other element nodes.
The type
annotation of an element node indicates how the values in its
child text nodes are to be interpreted. An element that has not
been validated (such as might occur in a schemaless document) is
annotated with the schema type xs:untyped. An element
that has been validated and found to be partially valid is
annotated with the schema type xs:anyType. If an
element node is annotated as xs:untyped, all its
descendant element nodes are also annotated as
xs:untyped. However, if an element node is annotated
as xs:anyType, some of its descendant element nodes
may have a more specific type annotation.
2.2.2 Schema Import
Processing
2.2.3 Expression Processing
XQuery defines two phases of processing called the static analysis
phase and the dynamic evaluation phase (see Fig. 1).
During the static analysis phase, static errors, dynamic errors, or type errors may be raised.
During the dynamic evaluation phase, only dynamic errors or type errors may be raised.
These kinds of errors are defined in 2.3.1 Kinds of Errors.
Within each phase, an implementation is free to use any strategy
or algorithm whose result conforms to the specifications in this
document.
2.2.3.1 Static Analysis Phase
[Definition: The static analysis
phase depends on the expression itself and on the static context. The
static analysis phase does not depend on input data (other
than schemas).]
During the static analysis phase, the query is parsed into an
internal representation called the operation tree (step SQ1
in Figure 1). A parse error is raised as a static error [err:XPST0003]. The static context is
initialized by the implementation (step SQ2). The static context is then changed and
augmented based on information in the prolog (step SQ3). If
the Schema Import Feature is supported,
the in-scope
schema definitions are populated with information from imported
schemas. If the Module Feature is supported, the static
context is extended with function declarations and variable
declarations from imported modules. The static context is
used to resolve schema type names, function names, namespace
prefixes, and variable names (step SQ4). If a name of one of these
kinds in the operation tree is not found in the static context, a
static error
([err:XPST0008] or
[err:XPST0017]) is
raised (however, see exceptions to this rule in 2.5.4.3 Element Test and 2.5.4.5 Attribute Test.)
The operation tree is then normalized by making
explicit the implicit operations such as atomization and extraction of Effective Boolean
Values (step SQ5). The normalization process is described in
[XQuery 1.0 and XPath 2.0 Formal
Semantics].
Each expression is then assigned a static type (step SQ6). [Definition: The static type of an
expression is a type such that, when the expression is evaluated,
the resulting value will always conform to the static type.] If the
Static Typing Feature is supported,
the static types
of various expressions are inferred according to the rules
described in [XQuery 1.0 and XPath
2.0 Formal Semantics]. If the Static Typing Feature is not
supported, the static types that are assigned are implementation-dependent.
During the static analysis phase, if the Static
Typing Feature is in effect and an operand of an expression is
found to have a static type that is not appropriate for that
operand, a type
error is raised [err:XPTY0004]. If static type checking raises no
errors and assigns a static type T to an expression, then
execution of the expression on valid input data is guaranteed
either to produce a value of type T or to raise a dynamic error.
The purpose of the Static Typing Feature is to provide
early detection of type
errors and to infer type information that may be useful in
optimizing the evaluation of an expression.
2.2.3.2 Dynamic Evaluation Phase
[Definition: The dynamic
evaluation phase is the phase during which the value of an
expression is computed.] It occurs after completion of the
static
analysis phase.
The dynamic evaluation phase can occur only if no errors were
detected during the static analysis phase. If the Static
Typing Feature is in effect, all type errors are detected during static
analysis and serve to inhibit the dynamic evaluation phase.
The dynamic evaluation phase depends on the operation
tree of the expression being evaluated (step DQ1), on the input
data (step DQ4), and on the dynamic context (step DQ5), which in turn
draws information from the external environment (step DQ3) and the
static
context (step DQ2). The dynamic evaluation phase may create new
data-model values (step DQ4) and it may extend the dynamic context
(step DQ5)—for example, by binding values to variables.
[Definition: A dynamic type is
associated with each value as it is computed. The dynamic type of a
value may be more specific than the static type of the expression that computed
it (for example, the static type of an expression might be
xs:integer*, denoting a sequence of zero or more
integers, but at evaluation time its value may have the dynamic
type xs:integer, denoting exactly one integer.)]
If an operand of an expression is found to have a dynamic type that is not
appropriate for that operand, a type error is raised [err:XPTY0004].
Even though static typing can catch many type errors before an expression is
executed, it is possible for an expression to raise an error during
evaluation that was not detected by static analysis. For example,
an expression may contain a cast of a string into an integer, which
is statically valid. However, if the actual value of the string at
run time cannot be cast into an integer, a dynamic error will result. Similarly,
an expression may apply an arithmetic operator to a value whose
static type is
xs:untypedAtomic. This is not a static error, but at run
time, if the value cannot be successfully cast to a numeric type, a dynamic error will be
raised.
When the Static Typing Feature is in effect,
it is also possible for static analysis of an expression to raise a
type error, even
though execution of the expression on certain inputs would be
successful. For example, an expression might contain a function
that requires an element as its parameter, and the static analysis
phase might infer the static type of the function parameter to be
an optional element. This case is treated as a type error and inhibits
evaluation, even though the function call would have been
successful for input data in which the optional element is
present.
2.2.4
Serialization
[Definition: Serialization is the
process of converting an XDM instance into a sequence of
octets (step DM4 in Figure 1.) ] The general framework for
serialization is described in [XSLT 2.0
and XQuery 1.0 Serialization].
An XQuery implementation is not required to
provide a serialization interface. For example, an implementation
may only provide a DOM interface (see [Document
Object Model]) or an interface based on an event stream. In
these cases, serialization would be outside of the scope of this
specification.
[XSLT 2.0 and XQuery 1.0
Serialization] defines a set of serialization parameters
that govern the serialization process. If an XQuery implementation
provides a serialization interface, it may support (and may expose
to users) any of the serialization parameters listed (with default
values) in C.3
Serialization Parameters. An XQuery implementation that
provides a serialization interface must support some combination of
serialization parameters in which method = "xml" and
version = "1.0".
Note:
The data model
permits an element node to have fewer in-scope
namespaces than its parent. Correct serialization of such an
element node would require "undeclaration" of namespaces, which is
a feature of [XML Names 1.1]. An
implementation that does not support [XML
Names 1.1] is permitted to serialize such an element without
"undeclaration" of namespaces, which effectively causes the element
to inherit the in-scope namespaces of its parent.
2.2.5 Consistency Constraints
In order for XQuery to be well defined, the input XDM instance, the
static
context, and the dynamic context must be mutually
consistent. The consistency constraints listed below are
prerequisites for correct functioning of an XQuery implementation.
Enforcement of these consistency constraints is beyond the scope of
this specification. This specification does not define the result
of a query
under any condition in which one or more of these constraints is
not satisfied.
Some of the consistency constraints use the term data model
schema. [Definition: For a given node in an
XDM
instance, the data model schema is defined as the schema
from which the type annotation of that node was
derived.] For a node that was constructed by some process other
than schema validation, the data model schema consists
simply of the schema type definition that is represented by the
type
annotation of the node.
-
For every node that has a type annotation, if that type
annotation is found in the in-scope schema definitions (ISSD), then its
definition in the ISSD must be equivalent to its definition in the
data
model schema. Furthermore, all types that are derived by
extension from the given type in the data model schema must also be
known by equivalent definitions in the ISSD.
-
For every element name EN that is found both in an
XDM
instance and in the in-scope schema definitions (ISSD), all
elements that are known in the data model schema to be in the
substitution group headed by
EN must also be known in the ISSD to be in the substitution
group headed by EN.
-
Every element name, attribute name, or schema type name
referenced in in-scope variables or function
signatures must be in the in-scope schema
definitions, unless it is an element name referenced as part of
an ElementTest or an
attribute name referenced as part of an AttributeTest.
-
Any reference to a global element, attribute, or type name in
the in-scope
schema definitions must have a corresponding element, attribute
or type definition in the in-scope schema definitions.
-
For each mapping of a string to a document node in available
documents, if there exists a mapping of the same string to a
document type in statically known documents, the document node
must match the document type, using the matching rules in 2.5.4 SequenceType
Matching.
-
For each mapping of a string to a sequence of nodes in available
collections, if there exists a mapping of the same string to a
type in statically known collections, the
sequence of nodes must match the type, using the matching rules in
2.5.4 SequenceType
Matching.
-
The sequence of nodes in the default collection must match the
statically known default collection
type, using the matching rules in 2.5.4 SequenceType
Matching.
-
The value of the context item must match the context item static type, using
the matching rules in 2.5.4
SequenceType Matching.
-
For each (variable, type) pair in in-scope variables and the
corresponding (variable, value) pair in variable values such that the
variable names are equal, the value must match the type, using the
matching rules in 2.5.4
SequenceType Matching.
-
For each variable declared as external: If the
variable declaration includes a declared type, the external
environment must provide a value for the variable that matches the
declared type, using the matching rules in 2.5.4 SequenceType Matching.
If the variable declaration does not include a declared type, the
external environment must provide a type and a matching value,
using the same matching rules.
-
For each function declared as external: the function implementation must
either return a value that matches the declared result type, using
the matching rules in 2.5.4
SequenceType Matching, or raise an implementation-defined error.
-
For a given query, define a participating ISSD as the
in-scope
schema definitions of a module that is used in evaluating the
query. If two participating ISSDs contain a definition for the same
schema type, element name, or attribute name, the definitions must
be equivalent in both ISSDs. Furthermore, if two participating
ISSDs each contain a definition of a schema type T, the
set of types derived by extension from T must be
equivalent in both ISSDs. Also, if two participating ISSDs each
contain a definition of an element name E, the
substitution group headed by E must be equivalent in both
ISSDs.
-
In the statically known namespaces, the prefix
xml must not be bound to any namespace URI other than
http://www.w3.org/XML/1998/namespace, and no prefix
other than xml may be bound to this namespace URI.
2.3 Error Handling
2.3.1
Kinds of Errors
As described in 2.2.3
Expression Processing, XQuery defines a static analysis
phase, which does not depend on input data, and a dynamic
evaluation phase, which does depend on input data. Errors may
be raised during each phase.
[Definition: A static error is an error
that must be detected during the static analysis phase. A syntax
error is an example of a static error.]
[Definition: A dynamic error is an
error that must be detected during the dynamic evaluation phase and
may be detected during the static analysis phase. Numeric overflow
is an example of a dynamic error. ]
[Definition: A type error may be raised
during the static analysis phase or the dynamic evaluation phase.
During the static analysis phase, a type error occurs when the static type of an
expression does not match the expected type of the context in which
the expression occurs. During the dynamic evaluation phase, a
type error occurs
when the dynamic
type of a value does not match the expected type of the context
in which the value occurs.]
The outcome of the static analysis phase is either success
or one or more type
errors, static
errors, or statically-detected dynamic errors. The result of the dynamic
evaluation phase is either a result value, a type error, or a dynamic error.
If more than one error is present, or if an error condition
comes within the scope of more than one error defined in this
specification, then any non-empty subset of these errors may be
reported.
During the static analysis phase, if the Static
Typing Feature is in effect and the static type assigned to an expression
other than () or data(()) is
empty-sequence(), a static error is raised [err:XPST0005]. This catches
cases in which a query refers to an element or attribute that is
not present in the in-scope schema definitions, possibly because of a
spelling error.
Independently of whether the Static Typing Feature is in
effect, if an implementation can determine during the static analysis
phase that an expression, if evaluated, would necessarily raise
a type error or a
dynamic
error, the implementation may (but is not required to) report
that error during the static analysis phase. However, the
fn:error() function must not be evaluated during the
static
analysis phase.
[Definition: In addition to static errors, dynamic errors, and type errors, an XQuery
implementation may raise warnings, either during the
static
analysis phase or the dynamic evaluation phase. The
circumstances in which warnings are raised, and the ways in which
warnings are handled, are implementation-defined.]
In addition to the errors defined in this specification, an
implementation may raise a dynamic error for a reason beyond the scope
of this specification. For example, limitations may exist on the
maximum numbers or sizes of various objects. Any such limitations,
and the consequences of exceeding them, are implementation-dependent.
2.3.2 Identifying and Reporting
Errors
The errors defined in this specification are identified by
QNames that have the form err:XXYYnnnn, where:
-
err denotes the namespace for XPath and XQuery
errors, http://www.w3.org/2005/xqt-errors. This
binding of the namespace prefix err is used for
convenience in this document, and is not normative.
-
XX denotes the language in which the error is
defined, using the following encoding:
-
YY denotes the error category, using the following
encoding:
-
nnnn is a unique numeric code.
Note:
The namespace URI for XPath and XQuery errors is not expected to
change from one version of XQuery to another. However, the contents
of this namespace may be extended to include additional error
definitions.
The method by which an XQuery processor reports error
information to the external environment is implementation-defined.
An error can be represented by a URI reference that is derived
from the error QName as follows: an error with namespace URI
NS and local part LP
can be represented as the URI reference
NS#LP. For
example, an error whose QName is err:XPST0017 could be
represented as
http://www.w3.org/2005/xqt-errors#XPST0017.
Note:
Along with a code identifying an error, implementations may wish
to return additional information, such as the location of the error
or the processing phase in which it was detected. If an
implementation chooses to do so, then the mechanism that it uses to
return this information is implementation-defined.
2.3.3 Handling Dynamic Errors
Except as noted in this document, if any operand of an
expression raises a dynamic error, the expression also raises a
dynamic
error. If an expression can validly return a value or raise a
dynamic error, the implementation may choose to return the value or
raise the dynamic error. For example, the logical expression
expr1 and expr2 may return the value
false if either operand returns false, or
may raise a dynamic error if either operand raises a dynamic
error.
If more than one operand of an expression raises an error, the
implementation may choose which error is raised by the expression.
For example, in this expression:
($x div $y) + xs:decimal($z)
both the sub-expressions ($x div $y) and
xs:decimal($z) may raise an error. The implementation
may choose which error is raised by the "+"
expression. Once one operand raises an error, the implementation is
not required, but is permitted, to evaluate any other operands.
[Definition: In addition to its identifying
QName, a dynamic error may also carry a descriptive string and one
or more additional values called error values.] An
implementation may provide a mechanism whereby an
application-defined error handler can process error values and
produce diagnostic messages.
A dynamic error may be raised by a built-in function or operator. For
example, the div operator raises an error if its
operands are xs:decimal values and its second operand
is equal to zero. Errors raised by built-in functions and operators
are defined in [XQuery 1.0 and
XPath 2.0 Functions and Operators].
A dynamic error can also be raised explicitly by calling the
fn:error function, which only raises an error and
never returns a value. This function is defined in [XQuery 1.0 and XPath 2.0 Functions and
Operators]. For example, the following function call raises a
dynamic error, providing a QName that identifies the error, a
descriptive string, and a diagnostic value (assuming that the
prefix app is bound to a namespace containing
application-defined error codes):
fn:error(xs:QName("app:err057"), "Unexpected value", fn:string($v))
2.3.4
Errors and Optimization
Because different implementations may choose to evaluate or
optimize an expression in different ways, certain aspects of the
detection and reporting of dynamic errors are implementation-dependent, as
described in this section.
An implementation is always free to evaluate the operands of an
operator in any order.
In some cases, a processor can determine the result of an
expression without accessing all the data that would be implied by
the formal expression semantics. For example, the formal
description of filter expressions suggests that
$s[1] should be evaluated by examining all the items
in sequence $s, and selecting all those that satisfy
the predicate position()=1. In practice, many
implementations will recognize that they can evaluate this
expression by taking the first item in the sequence and then
exiting. If $s is defined by an expression such as
//book[author eq 'Berners-Lee'], then this strategy
may avoid a complete scan of a large document and may therefore
greatly improve performance. However, a consequence of this
strategy is that a dynamic error or type error that would be
detected if the expression semantics were followed literally might
not be detected at all if the evaluation exits early. In this
example, such an error might occur if there is a book
element in the input data with more than one author
subelement.
The extent to which a processor may optimize its access to data,
at the cost of not detecting errors, is defined by the following
rules.
Consider an expression Q that has an operand
(sub-expression) E. In general the value of E is
a sequence. At an intermediate stage during evaluation of the
sequence, some of its items will be known and others will be
unknown. If, at such an intermediate stage of evaluation, a
processor is able to establish that there are only two possible
outcomes of evaluating Q, namely the value V or
an error, then the processor may deliver the result V
without evaluating further items in the operand E. For
this purpose, two values are considered to represent the same
outcome if their items are pairwise the same, where nodes are the
same if they have the same identity, and values are the same if
they are equal and have exactly the same type.
There is an exception to this rule: If a processor evaluates an
operand E (wholly or in part), then it is required to
establish that the actual value of the operand E does not
violate any constraints on its cardinality. For example, the
expression $e eq 0 results in a type error if the
value of $e contains two or more items. A processor is
not allowed to decide, after evaluating the first item in the value
of $e and finding it equal to zero, that the only
possible outcomes are the value true or a type error
caused by the cardinality violation. It must establish that the
value of $e contains no more than one item.
These rules apply to all the operands of an expression
considered in combination: thus if an expression has two operands
E1 and E2, it may be evaluated using any samples
of the respective sequences that satisfy the above rules.
The rules cascade: if A is an operand of B and
B is an operand of C, then the processor needs to
evaluate only a sufficient sample of B to determine the
value of C, and needs to evaluate only a sufficient sample
of A to determine this sample of B.
The effect of these rules is that the processor is free to stop
examining further items in a sequence as soon as it can establish
that further items would not affect the result except possibly by
causing an error. For example, the processor may return
true as the result of the expression S1 =
S2 as soon as it finds a pair of equal values from the two
sequences.
Another consequence of these rules is that where none of the
items in a sequence contributes to the result of an expression, the
processor is not obliged to evaluate any part of the sequence.
Again, however, the processor cannot dispense with a required
cardinality check: if an empty sequence is not permitted in the
relevant context, then the processor must ensure that the operand
is not an empty sequence.
Examples:
-
If an implementation can find (for example, by using an index)
that at least one item returned by $expr1 in the
following example has the value 47, it is allowed to
return true as the result of the some
expression, without searching for another item returned by
$expr1 that would raise an error if it were
evaluated.
some $x in $expr1 satisfies $x = 47
-
In the following example, if an implementation can find (for
example, by using an index) the product element-nodes
that have an id child with the value 47,
it is allowed to return these nodes as the result of the path expression,
without searching for another product node that would
raise an error because it has an id child whose value
is not an integer.
For a variety of reasons, including optimization,
implementations are free to rewrite expressions into equivalent
expressions. Other than the raising or not raising of errors, the
result of evaluating an equivalent expression must be the same as
the result of evaluating the original expression. Expression
rewrite is illustrated by the following examples.
-
Consider the expression //part[color eq "Red"]. An
implementation might choose to rewrite this expression as
//part[color = "Red"][color eq "Red"]. The
implementation might then process the expression as follows: First
process the "=" predicate by probing an index on parts
by color to quickly find all the parts that have a Red color; then
process the "eq" predicate by checking each of these
parts to make sure it has only a single color. The result would be
as follows:
-
Parts that have exactly one color that is Red are returned.
-
If some part has color Red together with some other color, an
error is raised.
-
The existence of some part that has no color Red but has
multiple non-Red colors does not trigger an error.
-
The expression in the following example cannot raise a casting
error if it is evaluated exactly as written (i.e., left to right).
Since neither predicate depends on the context position, an
implementation might choose to reorder the predicates to achieve
better performance (for example, by taking advantage of an index).
This reordering could cause the expression to raise an error.
$N[@x castable as xs:date][xs:date(@x) gt xs:date("2000-01-01")]
To avoid unexpected errors caused by expression rewrite, tests
that are designed to prevent dynamic errors should be expressed
using conditional or
typeswitch expressions. Conditional
and
typeswitch expressions raise only
dynamic errors that occur in the branch that is actually selected.
Thus, unlike the previous example, the following example cannot
raise a dynamic error if @x is not castable into an
xs:date:
$N[if (@x castable as xs:date)
then xs:date(@x) gt xs:date("2000-01-01")
else false()]
2.4 Concepts
This section explains some concepts that are important to the
processing of XQuery expressions.
2.4.1
Document Order
An ordering called document order is defined among all
the nodes accessible during processing of a given query, which may
consist of one or more trees (documents or fragments).
Document order is defined in [XQuery/XPath
Data Model (XDM)], and its definition is repeated here for
convenience. [Definition: The node ordering that
is the reverse of document order is called reverse document
order.]
Document order is a total ordering, although the relative order
of some nodes is implementation-dependent.
[Definition: Informally, document
order is the order in which nodes appear in the XML
serialization of a document.] [Definition: Document order is stable, which
means that the relative order of two nodes will not change during
the processing of a given query, even if this order is implementation-dependent.]
Within a tree, document order satisfies the following
constraints:
-
The root node is the first node.
-
Every node occurs before all of its children and
descendants.
-
Attribute nodes immediately follow the element node with which
they are associated. The relative order of attribute nodes is
stable but implementation-dependent.
-
The relative order of siblings is the order in which they occur
in the children property of their parent node.
-
Children and descendants occur before following siblings.
The relative order of nodes in distinct trees is stable but
implementation-dependent,
subject to the following constraint: If any node in a given tree T1
is before any node in a different tree T2, then all nodes in tree
T1 are before all nodes in tree T2.
2.4.2
Atomization
The semantics of some XQuery operators depend on a process
called atomization. Atomization is applied to a
value when the value is used in a context in which a sequence of
atomic values is required. The result of atomization is either a
sequence of atomic values or a type error [err:FOTY0012]. [Definition: Atomization of a sequence
is defined as the result of invoking the fn:data
function on the sequence, as defined in [XQuery 1.0 and XPath 2.0 Functions and
Operators].]
The semantics of fn:data are repeated here for
convenience. The result of fn:data is the sequence of
atomic values produced by applying the following rules to each item
in the input sequence:
-
If the item is an atomic value, it is returned.
-
If the item is a node, its typed value is returned (err:FOTY0012 is
raised if the node has no typed value.)
Atomization is used in processing the following types of
expressions:
-
Arithmetic expressions
-
Comparison expressions
-
Function calls and returns
-
Cast expressions
-
Constructor expressions for various kinds of nodes
-
order by clauses in FLWOR expressions
2.4.3 Effective Boolean
Value
Under certain circumstances (listed below), it is necessary to
find the effective boolean value of a value. [Definition:
The effective boolean value of a value is defined as the
result of applying the fn:boolean function to the
value, as defined in [XQuery 1.0
and XPath 2.0 Functions and Operators].]
The dynamic semantics of fn:boolean are repeated
here for convenience:
-
If its operand is an empty sequence, fn:boolean
returns false.
-
If its operand is a sequence whose first item is a node,
fn:boolean returns true.
-
If its operand is a singleton value of type xs:boolean
or derived from xs:boolean, fn:boolean
returns the value of its operand unchanged.
-
If its operand is a singleton value of type xs:string,
xs:anyURI, xs:untypedAtomic, or a type
derived from one of these, fn:boolean returns
false if the operand value has zero length; otherwise
it returns true.
-
If its operand is a singleton value of any numeric type or derived from a numeric type,
fn:boolean returns false if the operand
value is NaN or is numerically equal to zero;
otherwise it returns true.
-
In all other cases, fn:boolean raises a type error
[err:FORG0006].
Note:
The effective
boolean value of a sequence that contains at least one node and
at least one atomic value may be nondeterministic in regions of a
query where ordering mode is
unordered.
The effective
boolean value of a sequence is computed implicitly during
processing of the following types of expressions:
-
Logical expressions (and, or)
-
The fn:not function
-
The where clause of a FLWOR expression
-
Certain types of predicates, such as a[b]
-
Conditional expressions (if)
-
Quantified expressions (some,
every)
Note:
The definition of effective boolean value is not used when
casting a value to the type xs:boolean, for example in
a cast expression or when passing a value to a
function whose expected parameter is of type
xs:boolean.
2.4.4
Input Sources
XQuery has a set of functions that provide access to input data.
These functions are of particular importance because they provide a
way in which an expression can reference a document or a collection
of documents. The input functions are described informally here;
they are defined in [XQuery 1.0
and XPath 2.0 Functions and Operators].
An expression can access input data either by calling one of the
input functions or by referencing some part of the dynamic context
that is initialized by the external environment, such as a
variable
or context
item.
The input functions supported by XQuery are as follows:
2.4.5 URI
Literals
In certain places in the XQuery grammar, a statically known
valid URI is required. These places are denoted by the grammatical
symbol URILiteral. For
example, URILiterals are used to specify namespaces and collations,
both of which must be statically known.
Syntactically, a URILiteral is identical to a StringLiteral: a sequence of zero
or more characters enclosed in single or double quotes. However, an
implementation MAY raise a static error [err:XQST0046] if the value
of a URILiteral is of nonzero length and is not in the lexical
space of xs:anyURI.
As in a string literal, any predefined entity reference
(such as &), character reference (such as
•), or EscapeQuot or EscapeApos (for example,
"") is replaced by its appropriate expansion. Certain
characters, notably the ampersand, can only be represented using a
predefined entity reference
or a character reference.
The URILiteral is subjected to whitespace normalization as
defined for the xs:anyURI type in [XML Schema]: this means that leading and trailing
whitespace is removed, and any other sequence of whitespace
characters is replaced by a single space (#x20) character.
Whitespace normalization is done after the expansion of character
references, so writing a newline (for example) as

 does not prevent its being normalized to a
space character.
The URILiteral is not automatically subjected to
percent-encoding or decoding as defined in [RFC3986]. Any process that attempts to resolve the
URI against a base URI, or to dereference the URI, may however
apply percent-encoding or decoding as defined in the relevant
RFCs.
Note:
The xs:anyURI type is designed to anticipate the
introduction of Internationalized Resource